ConvNets Match Vision Transformers at Scale
[transformer deep-learning convolution nfnet log-log vit This is my reading note for ConvNets Match Vision Transformers at Scale. This paper shows that given same scale of data and same amount of train resources, CNN could perform similarly as transformer. A similarly observation was reported in # Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
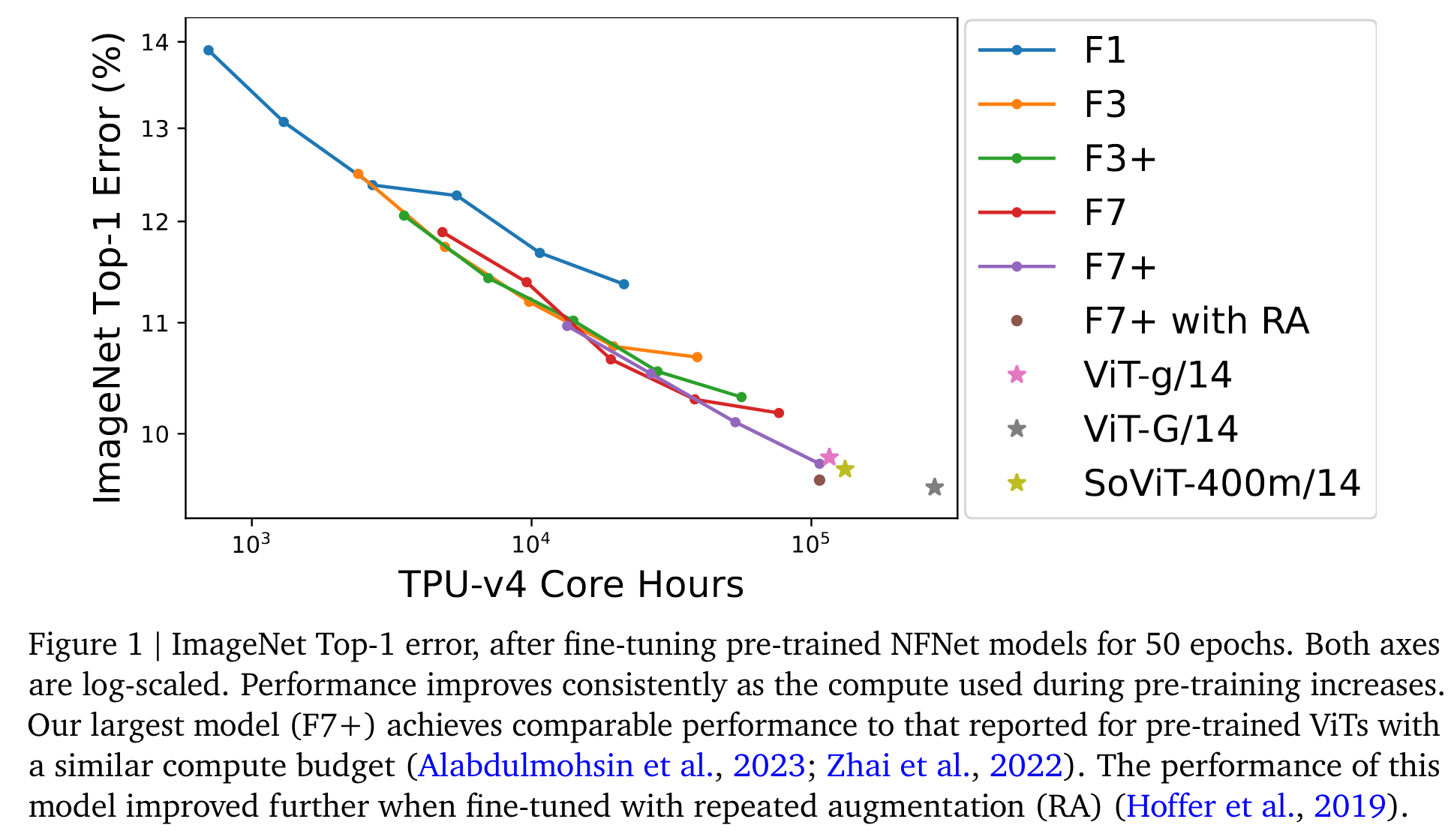
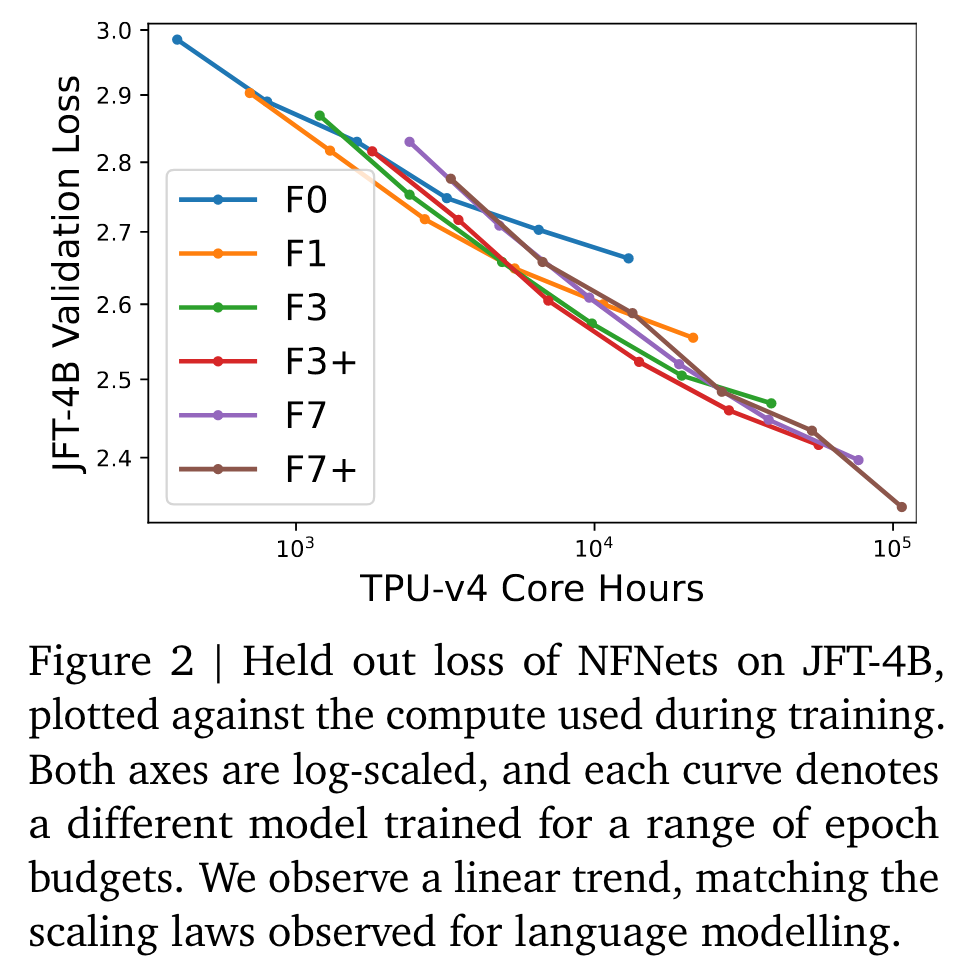
We observe a log-log scaling law between held out loss and compute budget. After fine-tuning on ImageNet, NFNets match the reported performance of Vision Transformers with comparable compute budgets. Our strongest fine-tuned model achieves a Top-1 accuracy of 90.4%. (p. 1)
Pre-trained NFNets obey scaling laws
We evaluate the scaling properties of the NFNet model family (Brock et al., 2021), a pure convolutional architecture published concurrently with the first ViT papers, and the last ConvNet to set a new SOTA on ImageNet. (p. 1)
We found that a reliable rule of thumb is to scale the model size and the number of training epochs at the same rate, as previously observed for language modelling by Hoffmann et al. (2022). We note that the optimal epoch budget was greater than 1 for overall compute budgets greater than roughly 5k TPU-v4 core hours. (p. 2)
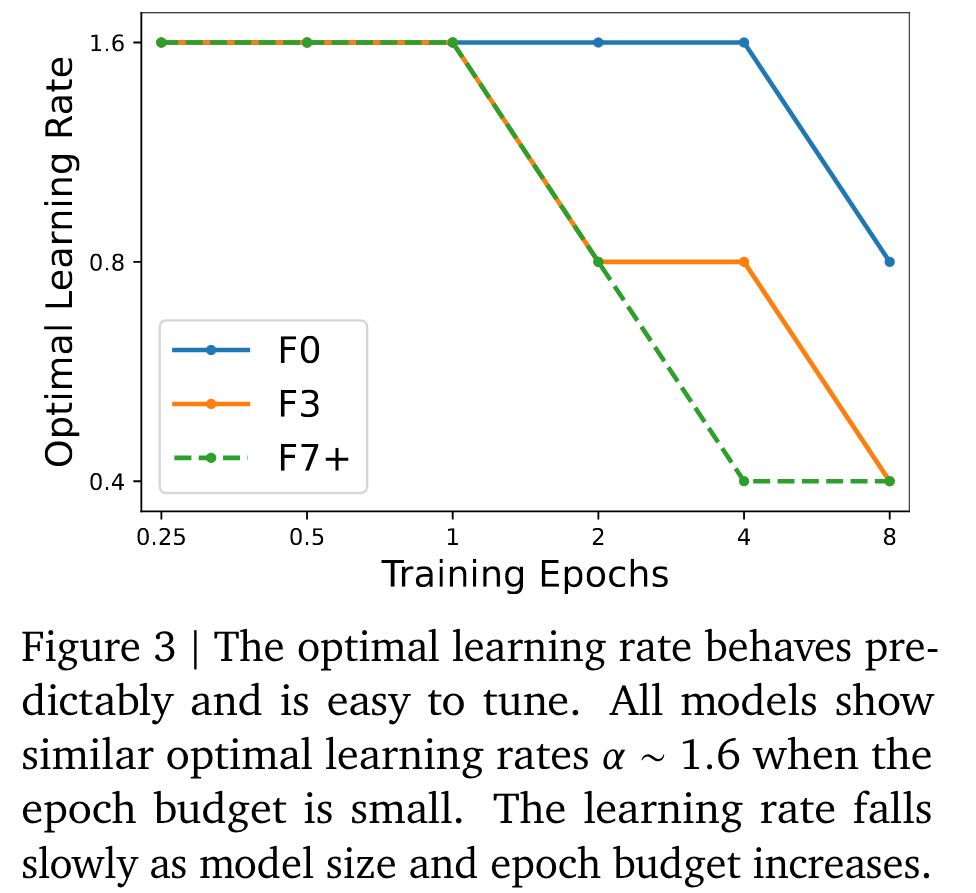
We find that all models in the NFNet family show a similar optimal learning rate 𝛼 ≈ 1.6 for small epoch budgets. However the optimal learning rate falls as the epoch budget rises, and for large models the optimal learning rate falls more quickly. (p. 2)
Fine-tuned NFNets are competitive with Vision Transformers on ImageNet
Despite the substantial differences between the two model architectures, the performance of pre-trained NFNets at scale is remarkably similar to the performance of pre-trained Vision Transformers. (p. 3)
Finally, we note that the pre-trained checkpoints achieving the lowest validation loss on JFT-4B did not always achieve the highest Top-1 accuracy on ImageNet after fine-tuning. In particular, we found that, under a fixed pre-training compute budget, the fine-tuning regime consistently favoured slightly larger models and slightly smaller epoch budgets. Intuitively, larger models have more capacity and are therefore better able to adapt to the new task. In some cases, slightly larger learning rates (during pre-training) also achieved better performance after fine-tuning. (p. 4) %% end annotations %%
%% Import Date: 2023-11-07T20:31:38.766-08:00 %%