Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
[attention bert masked-language-modeling clip meter multimodal deep-learning transformer image-text-matching fiber swin-transformer glip roberta This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
Introduction
Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. we present a two-stage pre- training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. (p. 1)
Recently, it has also been shown that tasks such as image classification and object detection (OD), which have been traditionally viewed as vision-only tasks, can benefit from being cast as VL tasks [ (p. 1)

 %%Two streams method%%
%%Two streams method%%
Instead of having a few dedicated transformer layers on top of the image and text encoders for fusion (e.g., as is commonly done in previous work [40, 8, 16, 29, 38]), we propose to directly insert cross-attention modules into the image and text backbones. Additionally, we support the ability to switch between a dual encoder (for fast image retrieval) and a fusion encoder (for VQA and captioning) readily, by switching on or off the cross-attention modules (p. 2)
Specifically:
- During coarse-grained pre-training, FIBER takes low-resolution (384×384) images as input, and is pre-trained with image-text matching, masked language modeling, and image-text contrastive losses, The pre-trained model can then be directly finetuned for VQA and image captioning tasks (p. 3)
- During fine-grained pre-training, FIBER uses the coarse pre-trained model as initialization, in addition to randomly initialized parameters for the OD head. At this stage, the model takes high- resolution (800×1,333) images as input, and is pre-trained with bounding box localization loss and word-region alignment loss, (p. 3)
Related Work
Convolution networks or vision transformers [15] are used as the image backbone, with additional transformer layers for modeling multimodal fusion (p. 3)

UniT [23] proposes a multimodal multi-task framework with a unified transformer (p. 4)
Proposed Method
Fusion in the Backbone
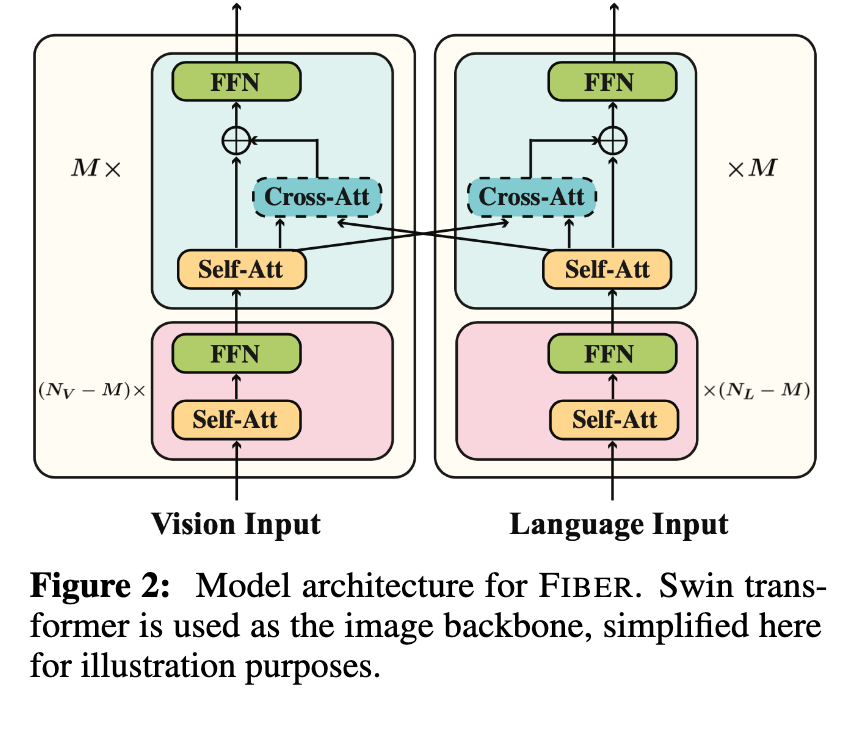
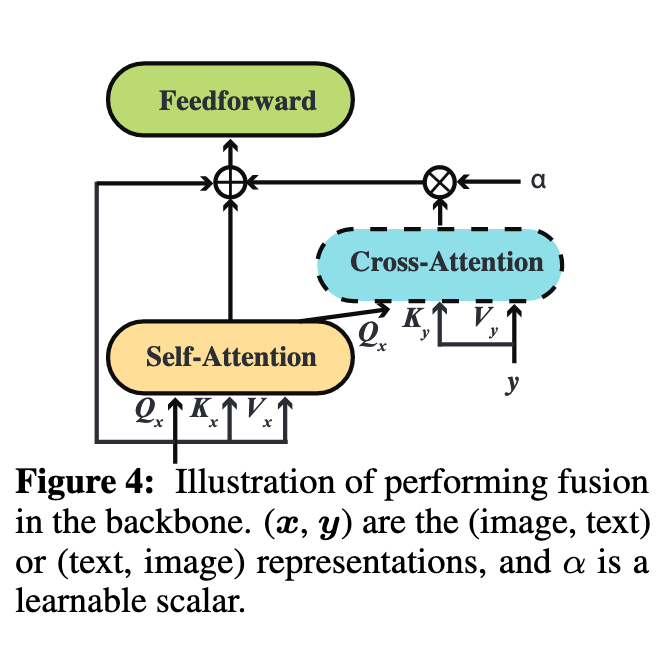
The architecture of FIBER is shown in Figure 2. Different from models that stack a modality fusion module on top of the vision or language backbones [8, 16], we insert multimodal fusion inside the backbones, and include a gating mechanism for the cross-modal layers (shown in Figure 4) (p. 4)
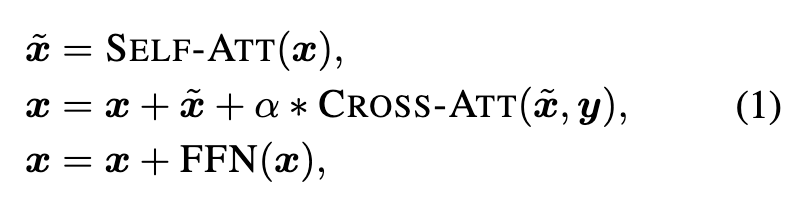
By inserting cross-attention layers with the gating mechanism, we enable cross-modal interactions without affecting the original computational flow of the backbones at the beginning of model training. Also, we can easily switch off the interactions by setting α to 0, and the backbones can be used in the dual-encoder setting. (p. 5)
Coarse-to-Fine Pre-training
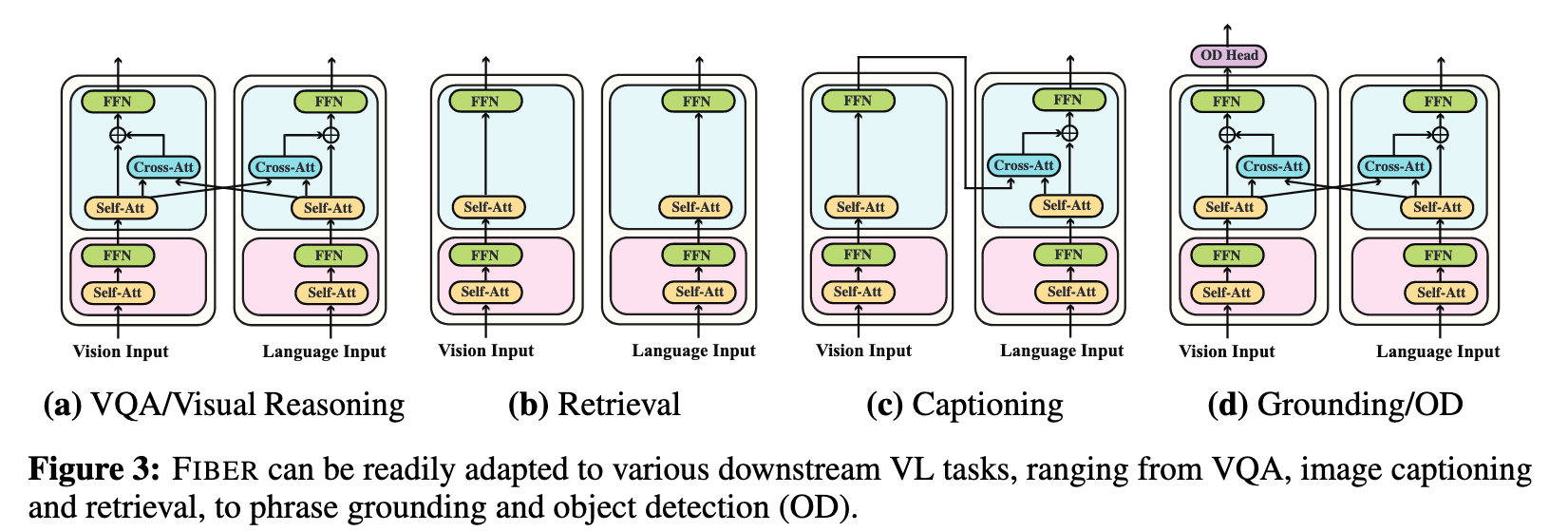
We divide VL tasks into two categories based on whether or not we need to generate region-level outputs on the image side (p. 5)
Coarse-grained Pre-training
For tasks like VQA and captioning, it has been demonstrated [36, 16, 74] that masked language modeling (MLM), image-text matching (ITM), and image-text con- trastive (ITC) objectives are helpful for ViT-based VLP models. Following previous work, we use all the three objectives during pre-training. (p. 5)
- For ITC, the inserted cross-attention modules are switched off, so FIBER functions as a dual encoder. Given a batch of N image-caption pairs, we first compute their representations with our vision and language encoders independently without modality fusion, and then maximize the similarities between N positive image-text pairs while minimizing the similarities between the rest N2 − N negative pairs, via a contrastive loss. (p. 5)
- For MLM and ITM, the inserted cross-attention modules are switched on, so FIBER now functions as a fusion encoder. For MLM, we randomly mask 15% of the input tokens and the model is trained to reconstruct the original tokens. For image-text matching, the model is given an image-text pair and predicts whether they are matched. Following VLMo [74], we sample global hard negatives based on the similarities computed from the above ITC loss. (p. 5)
Fine-grained Pre-training
We use a Swin Transformer [47] as our image encoder, which provides hierarchical representations of the image while having linear complexity in the size of the image. We combine these multi-scale representations using an FPN [43] for object detection training. Once the text-aware image features are extracted by the Swin backbone and image-aware text features are extracted using RoBERTa [46], the image features after the FPN are fed to a DynamicHead [12] which predicts a set of regions (p. 5)
We follow GLIP [38] by substituting the classification head with the grounding score S_GROUNDING. The localization loss is composed of two parts: a centerness loss and GIoU loss, which are used to supervise the box prediction (p. 6)
Adaptation to Downstream Tasks
- For VL classification tasks such as VQA: The final layer representations of the two modalities are concatenated together to generate the final outputs for tasks such as VQA and visual reasoning (p. 6)
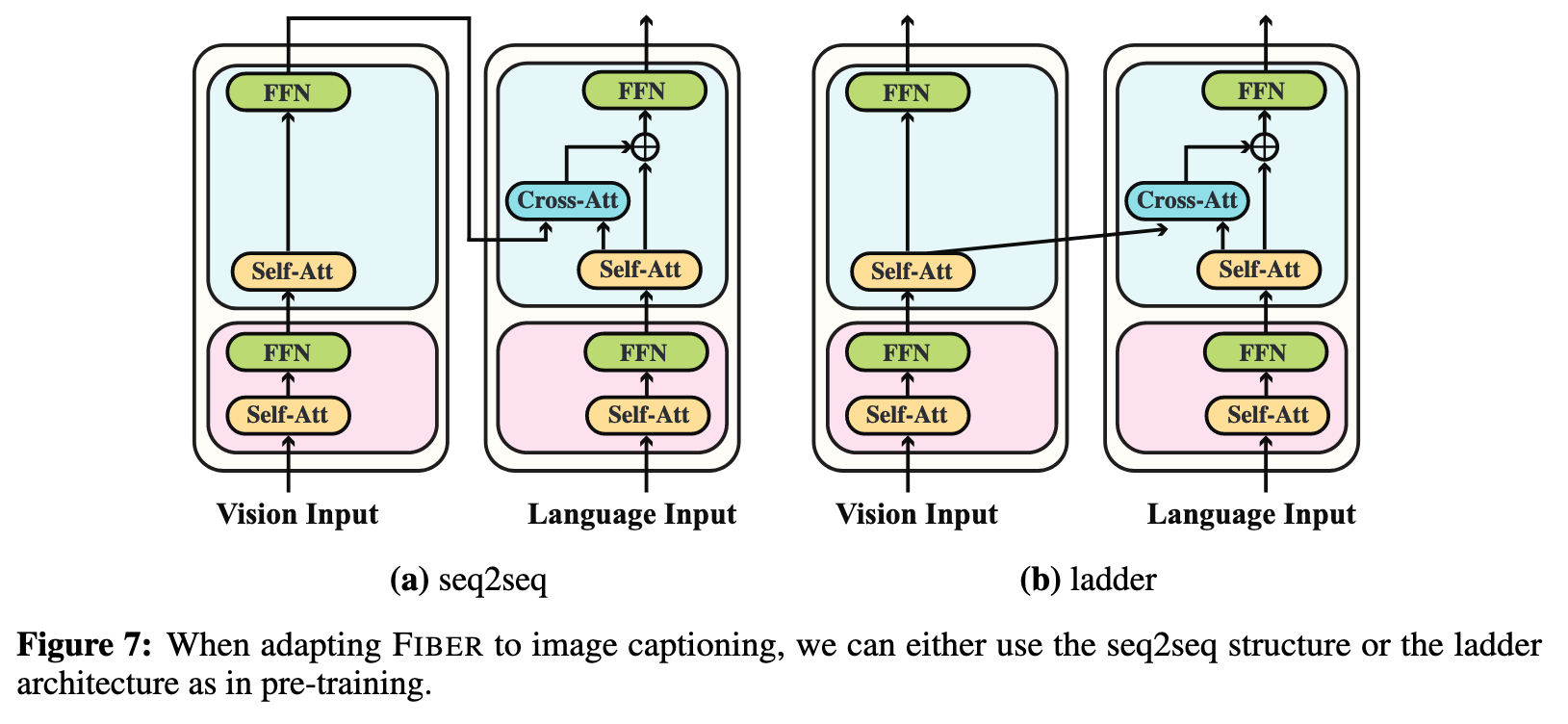
- For captioning: we adapt FIBER by only keeping the image-to-text cross-attentions and using causal masks in the decoding side. The representations of the final image encoding layer are fed into the cross-attention modules. In this way, the model is turned into a seq2seq model (p. 6)
Experiments


Ablation Study
In Appendix A.2 and A.3, we have provided detailed ablations that guided our architecture design, including ablations on fusion strategies, pre-training objectives, architecture for captioning, and additional results on open-ended VQA, and detailed few-shot ODinW results. Due to the space limit, these ablations and additional results are only provided in the Appendix. Some important observations are summarized below. (i) Co-attention works similarly to merged attention for fusion in the backbone. (ii) Adding a gating parameter in co-attention allows the addition of fusion in more layers, and also gives better performance than merged attention. (iii) Adding co-attention in the last 6 layers provides a balance between performance and efficiency. (iv) MLM, ITM with hard negative mining, and ITC are all important pre-training objectives for training FIBER-style models. (p. 10)
Ablation Study on the Fusion Strategies
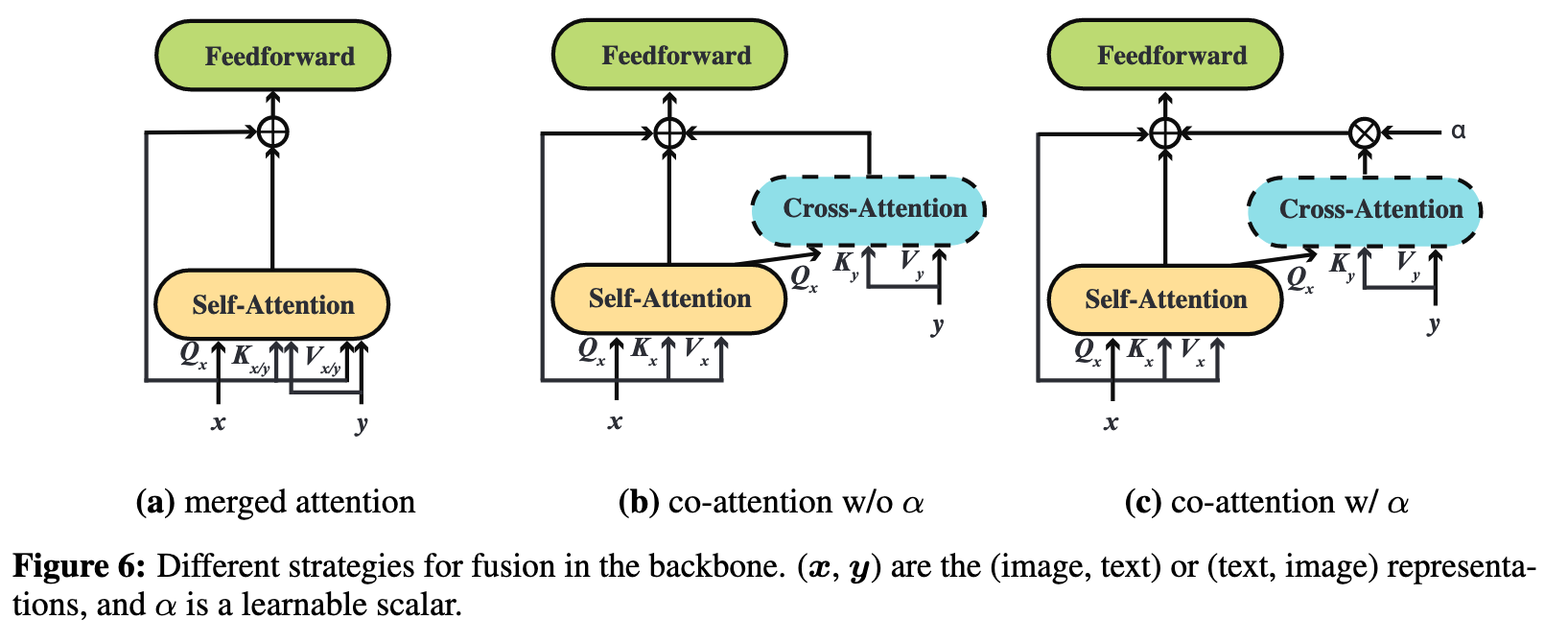
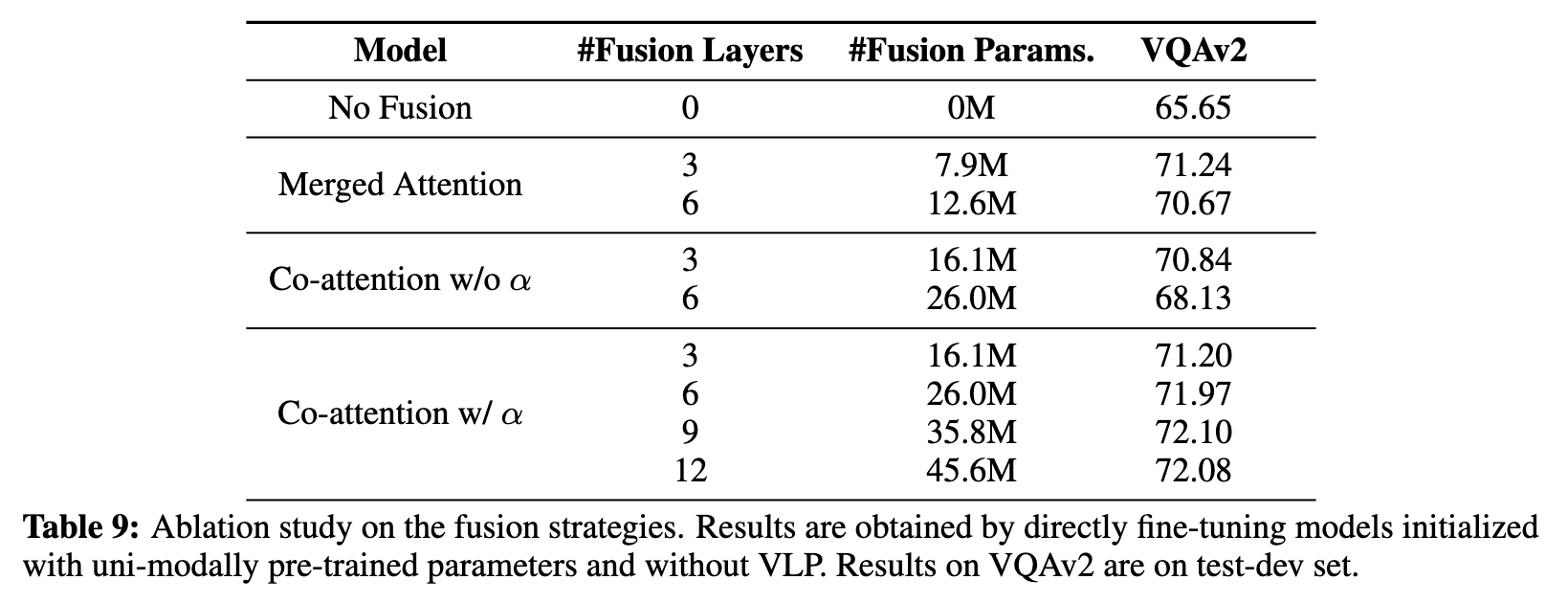
We can see that merged attention and co-attention achieve comparable performance without α. For both strategies, increasing the number of fusion layers can lead to performance drop. However, after introducing α, we can see significant improvements of co-attention, indicating the importance of having an explicit controlling/gating mechanism for fusion in the backbone. (p. 17)
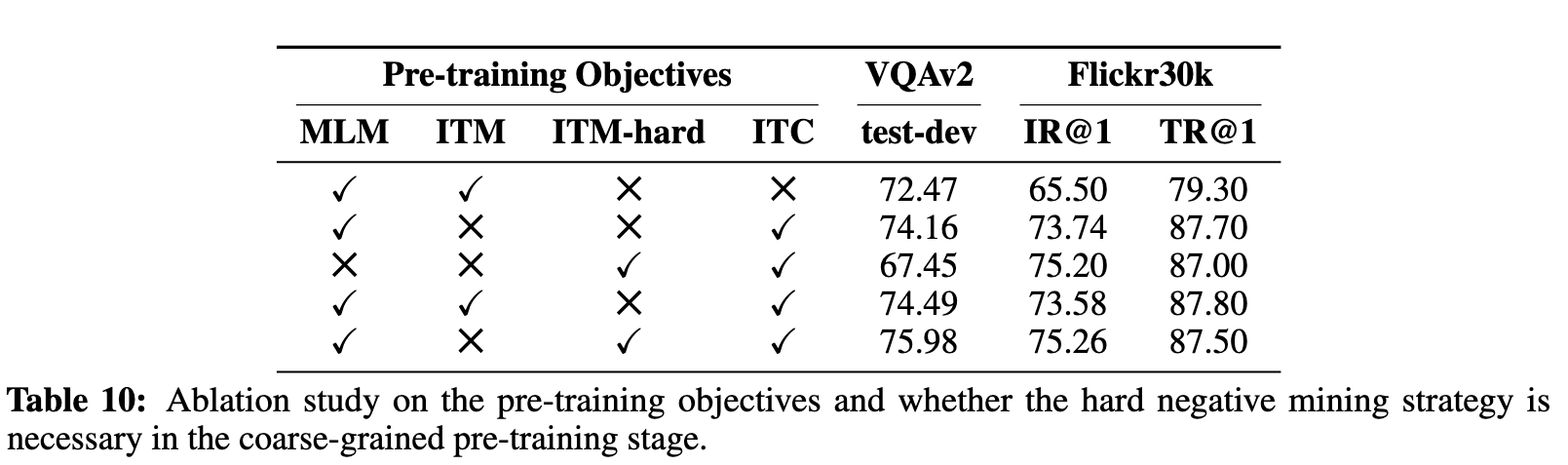
Ablation Study on Pre-training Objectives


As shown in Table 10, we can see that removing any of the pre-training objectives can lead to performance drop, and hard negative mining can bring improvements on both VQA and retrieval tasks. Masked language modeling is most effective for VQA, while removing it will not hurt the retrieval performance (p. 18)
Ablation Study on the Two-Stage Pre-training
As shown in Table 11, we see gains across both tasks when utilizing the coarse-grained pre-training. S (p. 18)
Ablation Study on Different Backbones
As shown in Table 12, we can see that RoBERTa and Swin Transformer perform slightly better than BERT and CLIP-ViT before VLP, which is consistent with previous findings in METER [16]. Note that while CLIP-ViT has the potential to perform better than Swin Transformer after VLP, it is hard to be adapted for region-level tasks such as object detection. Therefore, pairing Swin Transformer with RoBERTa is the optimal configuration in our settings. (p. 18)