Tag: masked-language-modeling
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
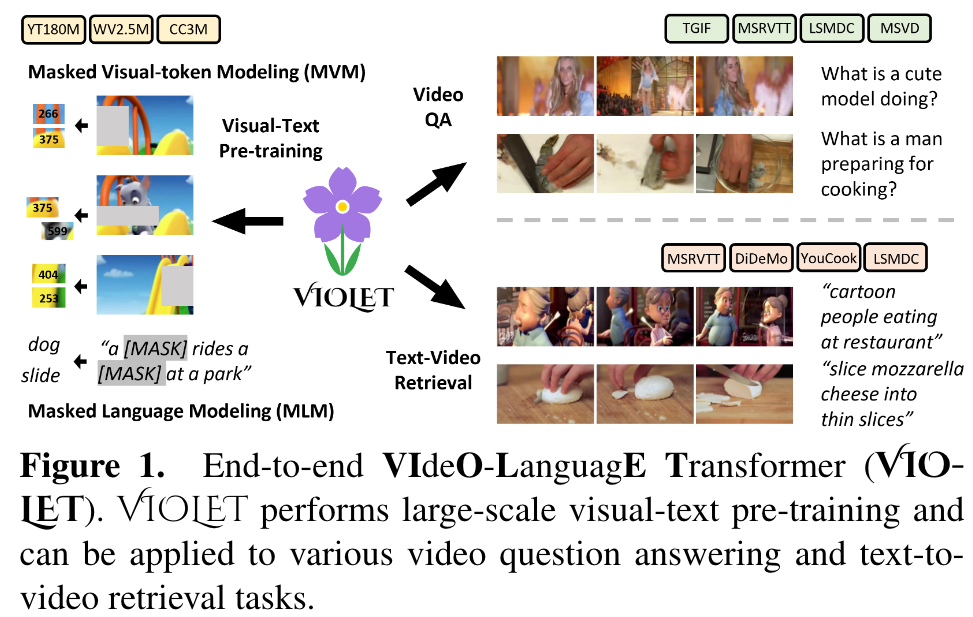
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Align before Fuse Vision and Language Representation Learning with Momentum Distillation (11 Oct 2023)
This is my reading note for Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. The paper proposes a multi modality model which is trained base on contrast loss, mask language modeling and image-text match. To handle noisy pairs of text and image, it track moving average of model and distill to the final model.
- MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks (24 Sep 2023)
This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.
- Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone (22 Sep 2023)
This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- CoCa Contrastive Captioners are Image-Text Foundation Models (31 Jul 2023)
This is my reading note for CoCa: Contrastive Captioners are Image-Text Foundation Models. The paper proposes a multi modality model, especially it models the problem as image caption as well as text alignment problem. The model contains three component: a vision encoder, a text decoder (which generates text embedding ) and a multi modality decoder , which generate caption given image and text embedding.
- FLAVA A Foundational Language And Vision Alignment Model (30 Jul 2023)
This is my reading note for FLAVA: A Foundational Language And Vision Alignment Model. This paper proposes a multi modality model. Especially, the model not only work across modality, but also on each modality and joint modality. To do that, it contains loss functions for both within modality but also across modality. It also proposes to use the same architecture for vision encoder, Text encoder as well as multi -modality encoder.
- Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey (21 Jul 2023)
This is my reading note for Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey. It provides an OK review for multimodality pre-trained models without diving too much into details.
- Vision-Language Intelligence Tasks, Representation Learning, and Large Models (20 Jul 2023)
This is my reading note for Vision-Language Intelligence: Tasks, Representation Learning, and Large Models. It is yet another review paper for pre-trained vision-language model. Check my reading note for another review paper in Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey