CoVLM Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding
[object-detection llm multimodal deep-learning composition relationship fast-rcnn detr co-vlm bag-of-words yolox clip flava blip blip2 kosmos flamingo visual-grounding This is my reading note for CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding. This paper proposes a vision language model to improve the capabilities of modeling composition relationship of objects across visual and text. To do that, it interleaves between language model generating special tokens and vision object detector detecting objects from image.
Introduction
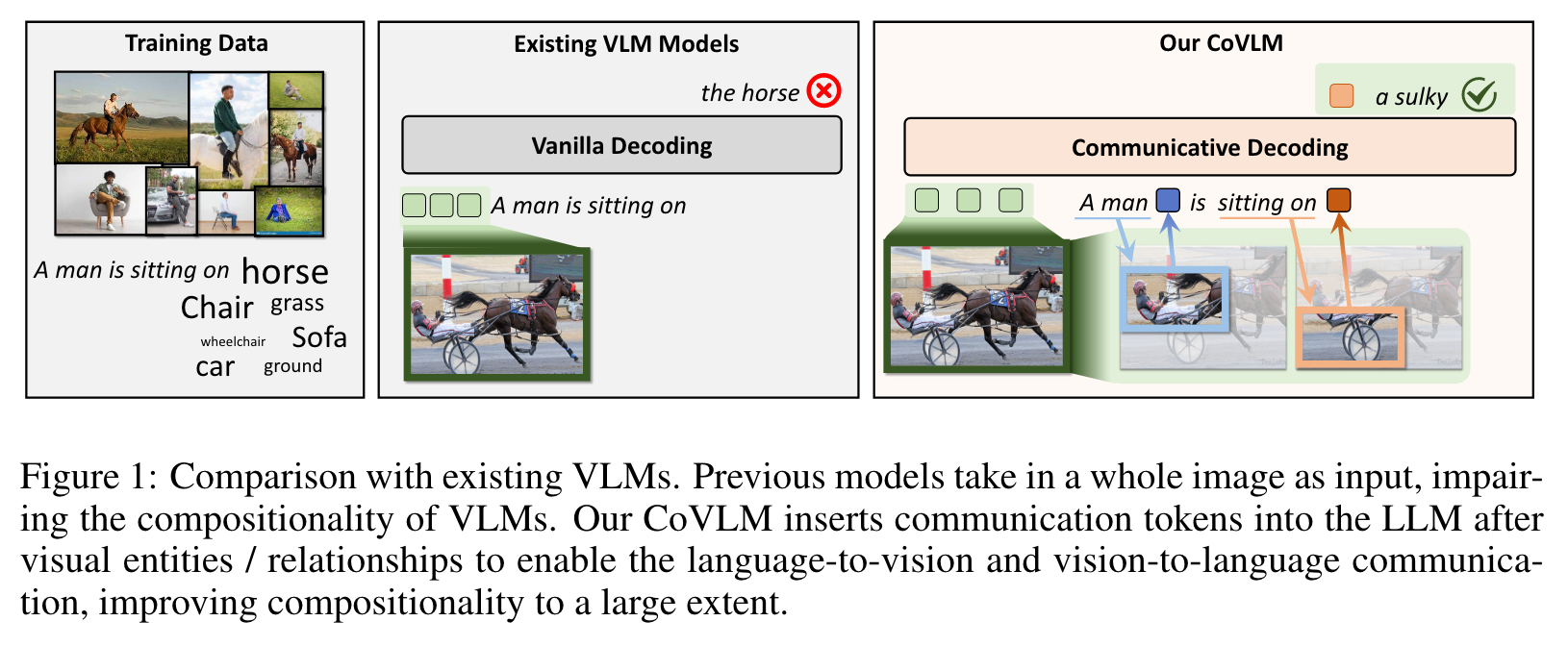
However, current large visionlanguage foundation models (VLMs) fall short of such compositional abilities due to their “bag-of-words” behaviors and inability to construct words that correctly represent visual entities and the relations among the entities. To this end, we propose CoVLM, which can guide the LLM to explicitly compose visual entities and relationships among the text and dynamically communicate with the vision encoder and detection network to achieve vision-language communicative decoding. (p. 1)
A communication token is generated by the LLM following a visual entity or a relation, to inform the detection network to propose regions that are relevant to the sentence generated so far. The proposed regions-of-interests (ROIs) are then fed back into the LLM for better language generation contingent on the relevant regions. The LLM is thus able to compose the visual entities and relationships through the communication tokens. The vision-to-language and language-to-vision communication are iteratively performed until the entire sentence is generated. (p. 1)
A remarkable ability of human beings resides in compositional reasoning: the capacity to construct an endless number of novel combinations from a finite set of known components, i.e., “infinite use of finite means” (Chomsky, 1965; 1957; Montague, 1970). (p. 1)
Current Vision-Language Models (VLMs), however, tend to fall short of such compositional abilities (Ma et al., 2023; Cascante-Bonilla et al., 2023; Doveh et al., 2022; Zhao et al., 2023). As noted by recent works, deficiency of compositionality in these VLMs is likely due to the hypothesis that they behave like “bag-of-words” (Yuksekgonul et al., 2022) that they merely memorize by rote the frequent co-occurrences of words, but fail to construct words that could correctly represent objects and the relations between objects. (p. 2)
- First, they feed one single image as a whole into LLMs and generate language descriptions based on the holistic image embedding. (p. 2)
- Second, these methods disregard the interaction between the sentence parts and the ingredients in the images. The generation of a new word by the LLM is not linked to a specific visual entity or relationship but is contingent on previous words and holistic image feature instead. (p. 2)
RELATED WORKS
VISION-LANGUAGE MODEL (VLM)
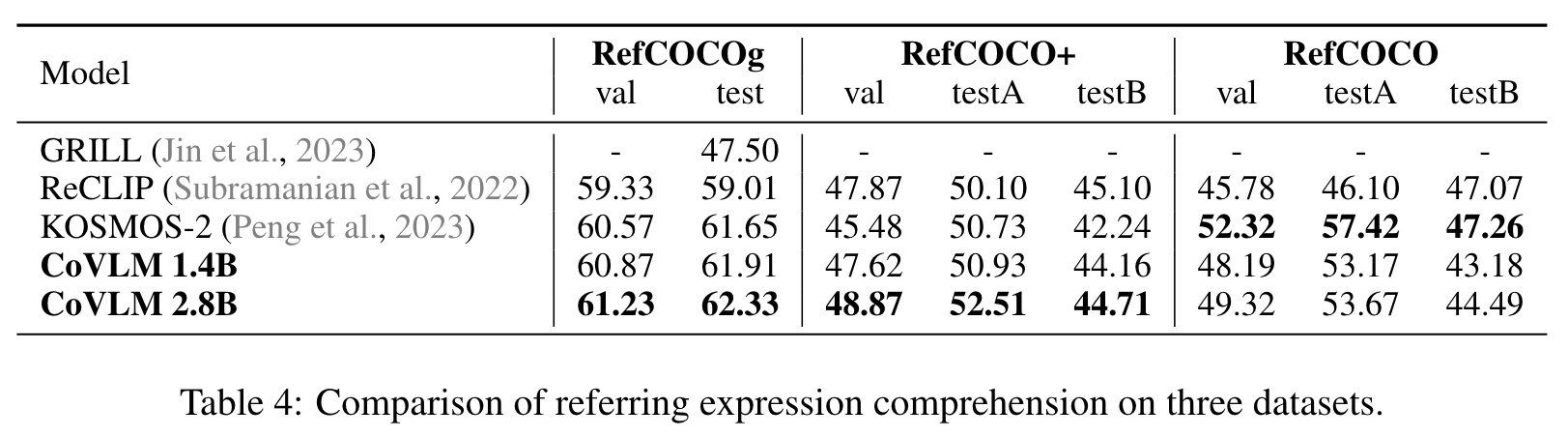
However, the vision-language communication of these VLMs is one-way and one-time, merely using language instructions to generate segmentations, or input segmented regions into the LLMs. KOSMOS-2 (Peng et al., 2023) infuses location tokens after visual entities into the language generation process. However, the communication is purely from the language system to the image for segmentation, while the grounded visual regions are not fed back to the language system. (p. 3)
COMPOSITIONALITY IN VISION AND LANGUAGE
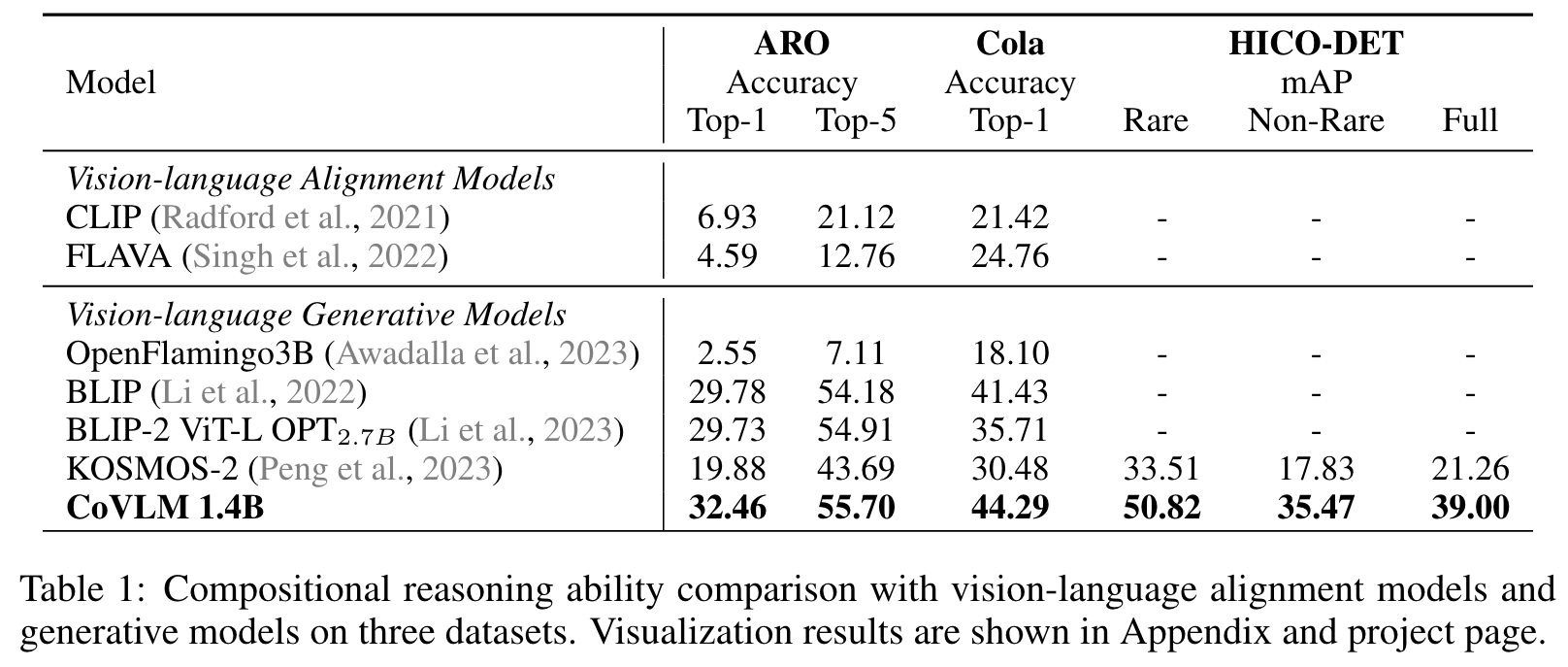
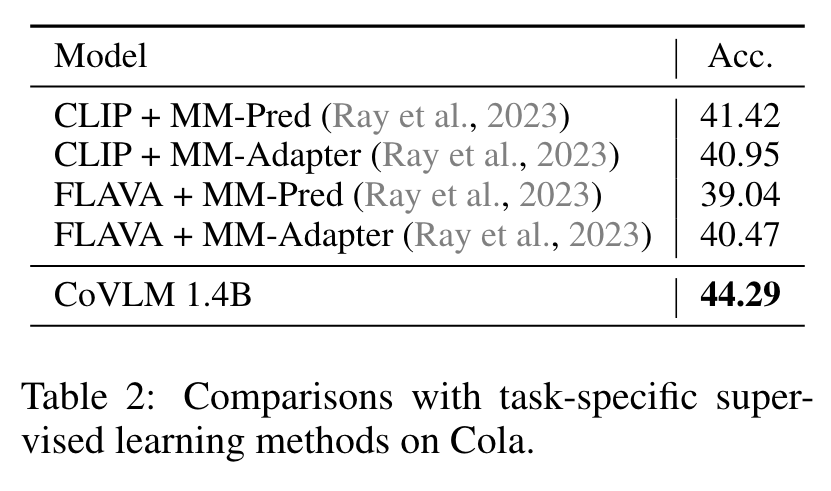
Specifically, the Attribution, Relation, and Order (ARO) benchmark (Yuksekgonul et al., 2022) is a benchmark to systematically evaluate the ability of VLMs to understand different types of relationships, attributes, and order. Recently, VL-Checklist (Zhao et al., 2023) is a framework to evaluate VLM’s abilities of recognizing objects, attributes, and relations. Cola (Ray et al., 2023) analyzes VLMs’ compositional ability in detail and propose a text-to-image retrieval benchmark to compose objects with their relations. (p. 3)
Proposed Method
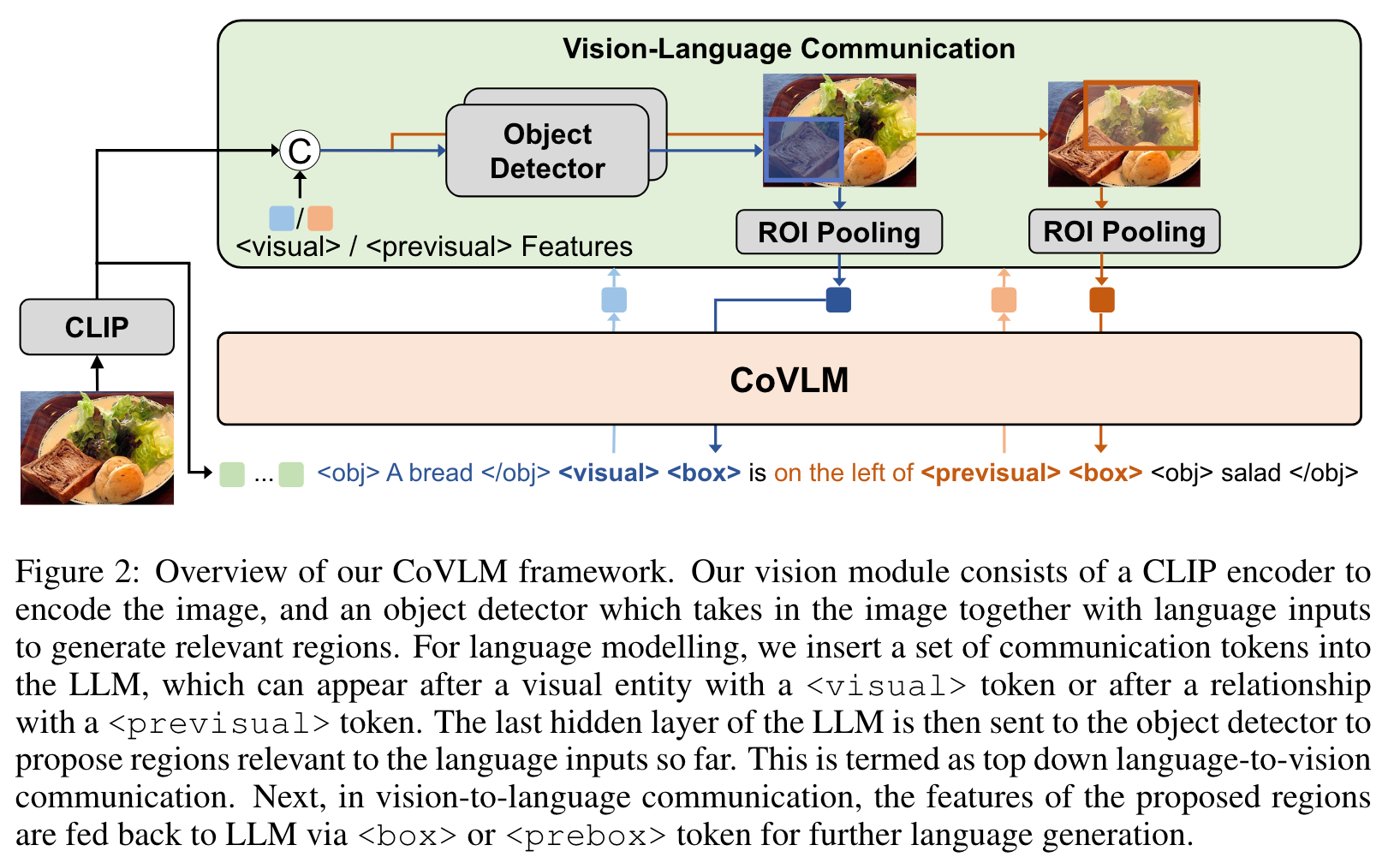
For LLM, we use a pre-trained Pythia model (Biderman et al., 2023) that can handle language tokens as inputs and outputs, as well as visual embeddings and special tokens which are mapped to the same embedding space as the language tokens, to constitute the LLM representations. The vision module consists of an image encoder that produces features to feed into the LLM, and a detection network that proposes region proposals that are relevant to previous language inputs. Topdown language-to-vision communication is achieved by concatenating the last hidden state of the LLM-encoded features to the image embeddings, and input them into the detection network, which proposes relevant regions conditioned on the LLM representations. Bottom-up vision-to-language communication extracts the features of the relevant regions, and concatenates the features back into LLM for further language generation. (p. 4)
VISION MODULE
Detection Network. Our detection network is similar to the YOLOX (Ge et al., 2021). The detection network takes as inputs two things: 1) the image embeddings of the whole image (N × N × D, where N is the patch size and D is the embedding dim); 2) the last hidden state of the LLM so far (1 × D). The LLM embedding is expanded and concatenated to the same dim as the image embedding, yielding a final multi-modal embedding of size N × N × 2D, and send to the detection network. The detection network outputs N × N ×4 bounding boxes and N × N confidence scores. After non-maximum suppression, we keep a set of bounding boxes as regions of interest (ROIs). To extract the embeddings of one ROI, we extract the features of all patches that are covered by the ROI, and average pool to yield a box embedding of size D. We choose the cropped image features of m bounding boxes with top scores. (p. 5)
LANGUAGE MODELS
we also devise a set of special communication tokens to facilitate compositional vision-language modeling and communication (p. 5)
<obj>,</obj>: these two tokens enclose a set of language tokens referring to a visual entity<visual>: this token is for switching to the vision module after a visual entity token v1 is captured by LLM, so the vision module could attend to the visual entity<box>: this token receives the feedback from the vision module, concatenating the image features of detected v1 back into the LLM<previsual>: this token is for switching to the vision module after a relation r to a previous visual entity v1 is detected (and before the visual entity v2 that is in relation r to v1 is generated).<prebox>: this token switches back from the vision module after potential regions of v2 are detected, and concatenating the features to better generate the language description of v2. (p. 5)
MODEL PRE-TRAINING
Pre-training data. We create a large-scale grounded image-text dataset which consists of over 97M image-text pairs from the pre-training data of BLIP-2 (Li et al., 2023). We apply a grounding pipeline to the image-text pair to associate the text spans in the caption to their corresponding visual entities in the image. (p. 6)
- Step-1: Generating bounding-box-word pairs. We use GroundingDINO (Liu et al., 2023c) to detect objects in the image and link the bounding box of the object to words in the text. We keep bounding boxes whose highest similarities are higher than 0.35 and extract the words whose similarities are higher than 0.25 as the words that correspond to a bounding box. Non-maximum suppression algorithm is applied to eliminate bounding boxes that have a high overlap with other bounding boxes linked to the same word. (p. 6)
- Step-2: Expanding grounded words to grounded expressions. In practice, we observe that GroundingDINO often fail to link the whole referring expressions to an object in the image. For example, for the expression “man with a hat on his head”, GroundingDINO will only link “man” to the person in the image, but not the whole expression. This will limit the model’s ability to understand complicated expressions. Inspired by KOSMOS-2 (Peng et al., 2023), we apply spaCy (Honnibal et al., 2020) to obtain each word’s dependency relation in the sentence, and expand a grounded word to a grounded expression by recursively traversing the dependency tree of that word and concatenate eligible children words based on the linguistic rules. (p. 6)
- Step-3: Assigning bounding boxes to the special communication tokens. Given the expressions and their associated bounding boxes in a grounded image-text pair, we can now insert the special communication tokens into the text and assign the bounding boxes to them. For a given expression with a single bounding box, the resulted input sequence for that expression is either in the form of
<obj>expression</obj><visual><box>or<previsual><prebox><obj>expression</obj>depending on the position of the expression in the sentence. If it is the first expression in the sentence, we use the form with a trailing<visual>token. Otherwise, we randomly select one from these two available forms. (p. 6)
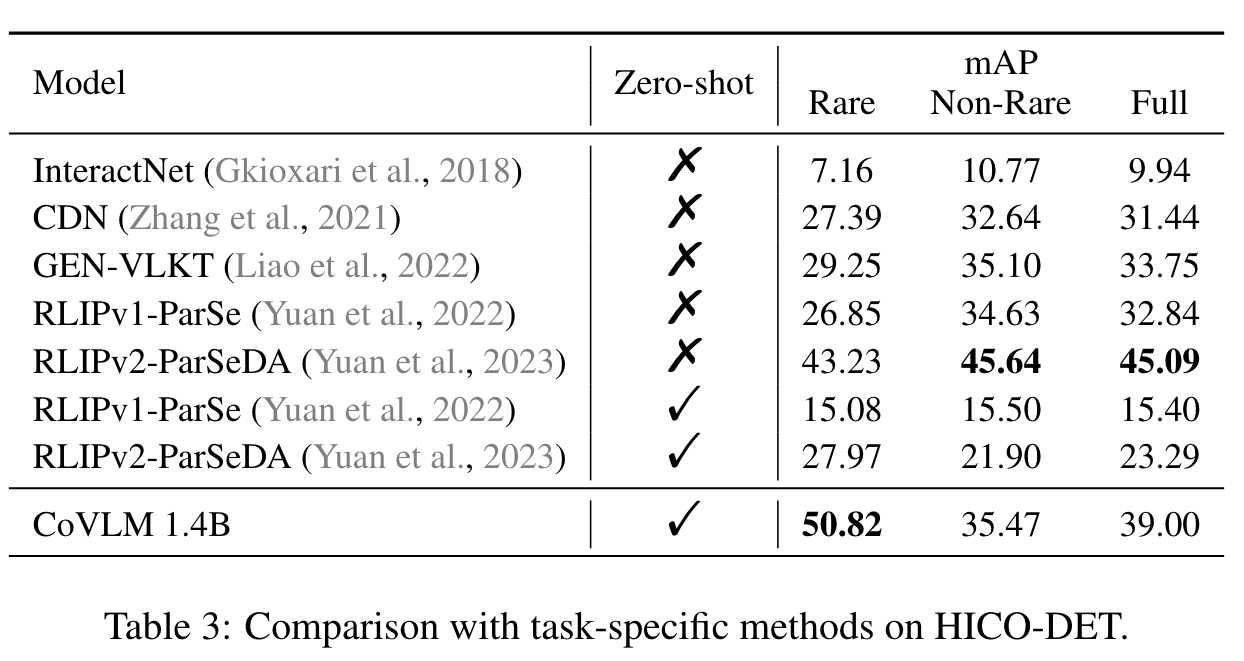
Experiment