DiffBIR Towards Blind Image Restoration with Generative Diffusion Prior
[super-resolution restoration diffusion text2image deep-learning image2image This is my reading note on DiffBIR Towards Blind Image Restoration with Generative Diffusion Prior. This paper proposes a two stage method for restore degraded images: stage 1 is trained neural network to recover image degradation; stage 2 is a pretrained diffusion model to restore the details in the image recovered from stage 1.

Introduction
According to the problem settings, existing BIR methods can be roughly grouped into three research topics, namely blind image super-resolution (BSR), zero-shot image restoration (ZIR) and blind face restoration (BFR). (p. 1)
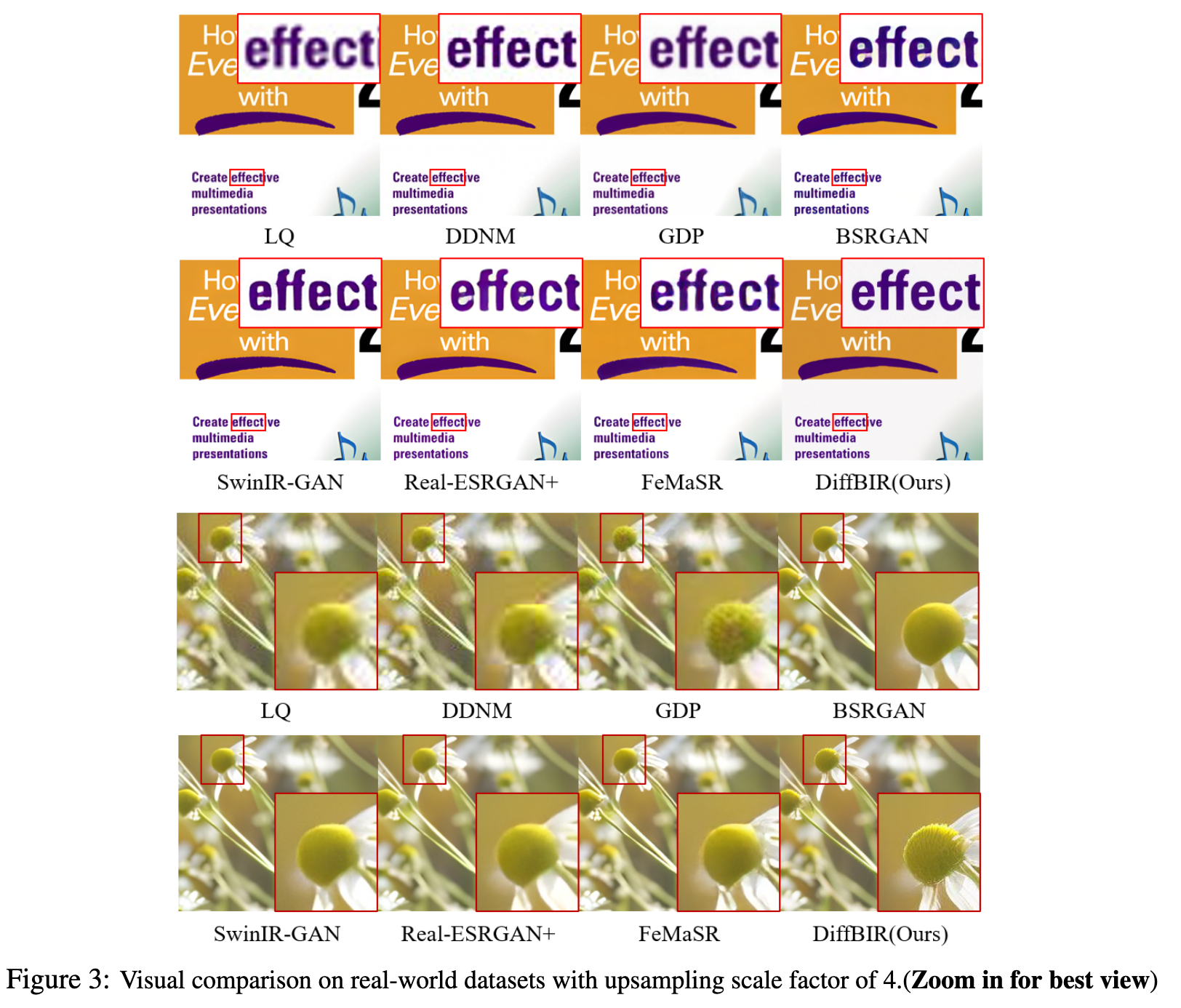
- According to the recent BSR survey [37], the most popular solutions may be BSRGAN [64] and Real-ESRGAN [55]. They formulate BSR as a supervised large-scale degradation overfitting problem. To simulate real-world degradations, a degradation shuffle strategy and high-order degradation modeling are proposed separately. Then the adversarial loss [31; 17; 56; 41; 49] is incorporated for learning the reconstruction process in an end-to-end manner. (p. 1). SwinIR-GAN [36] uses the new prevailing backbone Swin Transformer [38] to achieve better image restoration performance. FeMaSR [6] formulates SR as a feature-matching problem based on pre-trained VQ-GAN [15]. Although BSR methods can be useful to remove degradations in the real world, they are not good at generating realistic details. In addition, they typically assume the low-quality image input is downsampled by some certain scales (e.g. ×4/ × 8), which is limited for BIR problem. (p. 3)
- The second group ZIR is a newly emerged direction. Representative works are DDRM [26], DDNM [57], and GDP [16]. They incorporate the powerful diffusion model as the additional prior, thus having greater generative ability than GAN-base methods. With a proper degradation assumption, they can achieve impressive zero-shot restoration on classic IR tasks. However, the problem setting of ZIR is not in accordance with BIR. Their methods can only deal with clearly defined degradations (linear or non-linear), but cannot generalize well to unknown degradations. In other words, they can achieve realistic reconstruction on general images, but not on general degradations (p. 2)
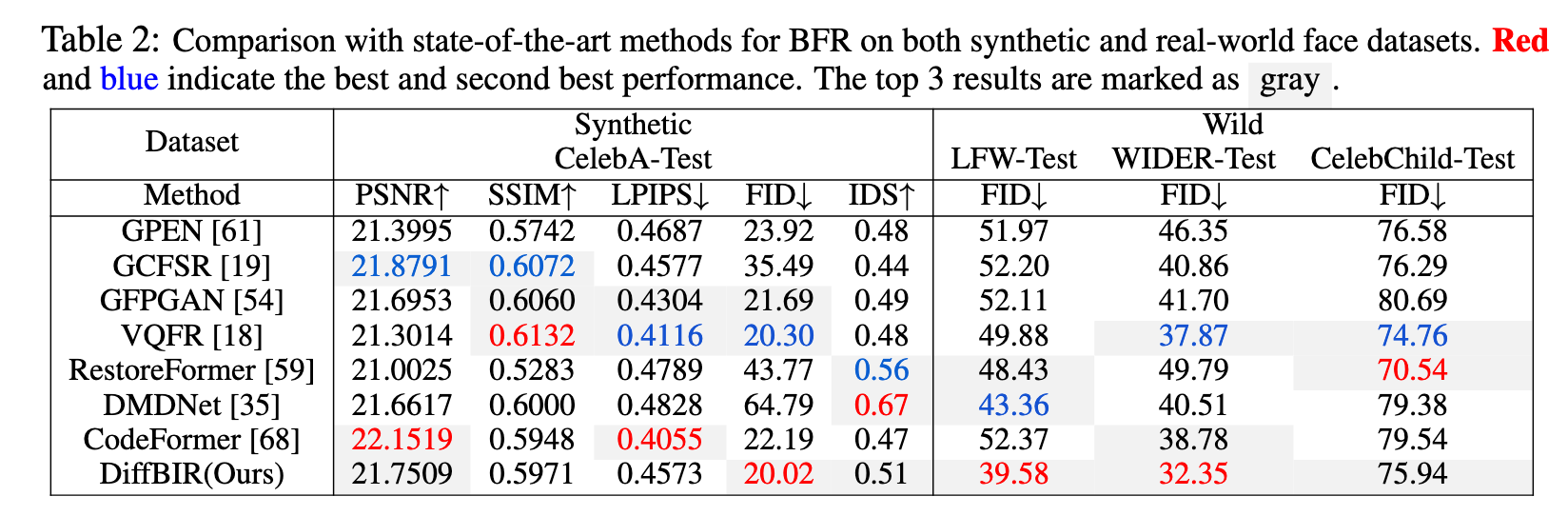
- The third group is BFR, which focuses on human face restoration. State-of-the-art methods can refer to CodeFormer [68] and VQFR [18]. They have a similar solution pipeline as BSR methods, but are different in the degradation model and generation network. Due to a smaller image space, these methods can utilize VQGAN and Transformer to achieve surprisingly good results on real-world face images. (p. 2)
According to the above analysis, we can see that existing BIR methods cannot achieve (1) realistic image reconstruction on (2) general images with (3) general degradations, simultaneously. Therefore, we desire a new BIR method to overcome these limitations. (p. 3)
Specifically, DiffBIR (1) adopts an expanded degradation model that can generalize to real-world degradations, (2) utilizes the well-trained Stable Diffusion as the prior to improve generative ability, (3) introduces a two-stage solution pipeline to ensure both realness and fidelity. (p. 3)
- First, to increase generalization ability, we combine the diverse degradation types in BSR and the wide degradation ranges in BFR to formulate a more practical degradation model. This helps DiffBIR to handle diverse and extreme degradation cases.
- Second, to leverage Stable Diffusion, we introduce an injective modulation sub-network – LAControlNet that can be optimized for our specific task. Similar to ZIR, the pre-trained Stable Diffusion is fixed during finetuning to maintain its generative ability.
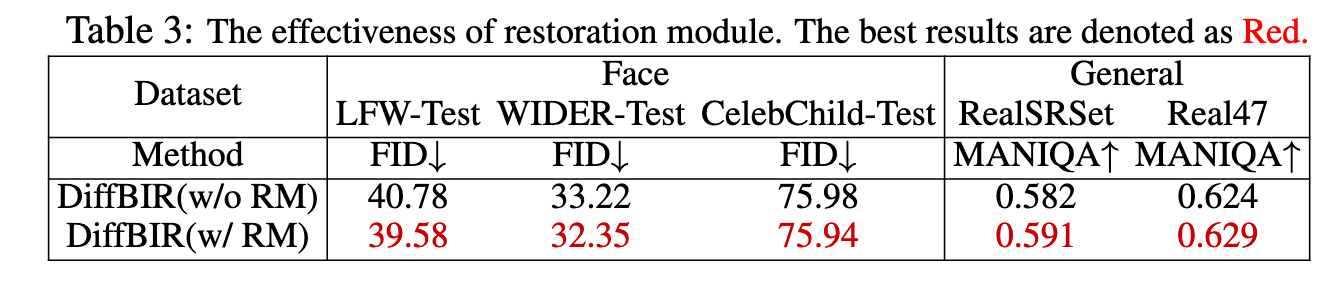
- Third, to realize faithful and realistic image reconstruction, we first apply a Restoration Module (i.e., SwinIR) to reduce most degradations, and then finetune the Generation Module (i.e., LAControlNet) to generate new textures. Without this pipeline, the model may either produce over-smoothed results (remove Generation Module) or generate wrong details (remove Restoration Module).
- In addition, to meet users’ diverse requirements, we further propose a controllable module that could achieve continuous transition effects between restoration result in stage one and generation result in stage two. This is achieved by introducing the latent image guidance during the denoising process without re-training. The gradient scale that applies to the latent image distance can be tuned to trade off realness and fidelity. (p. 3)
Proposed Method
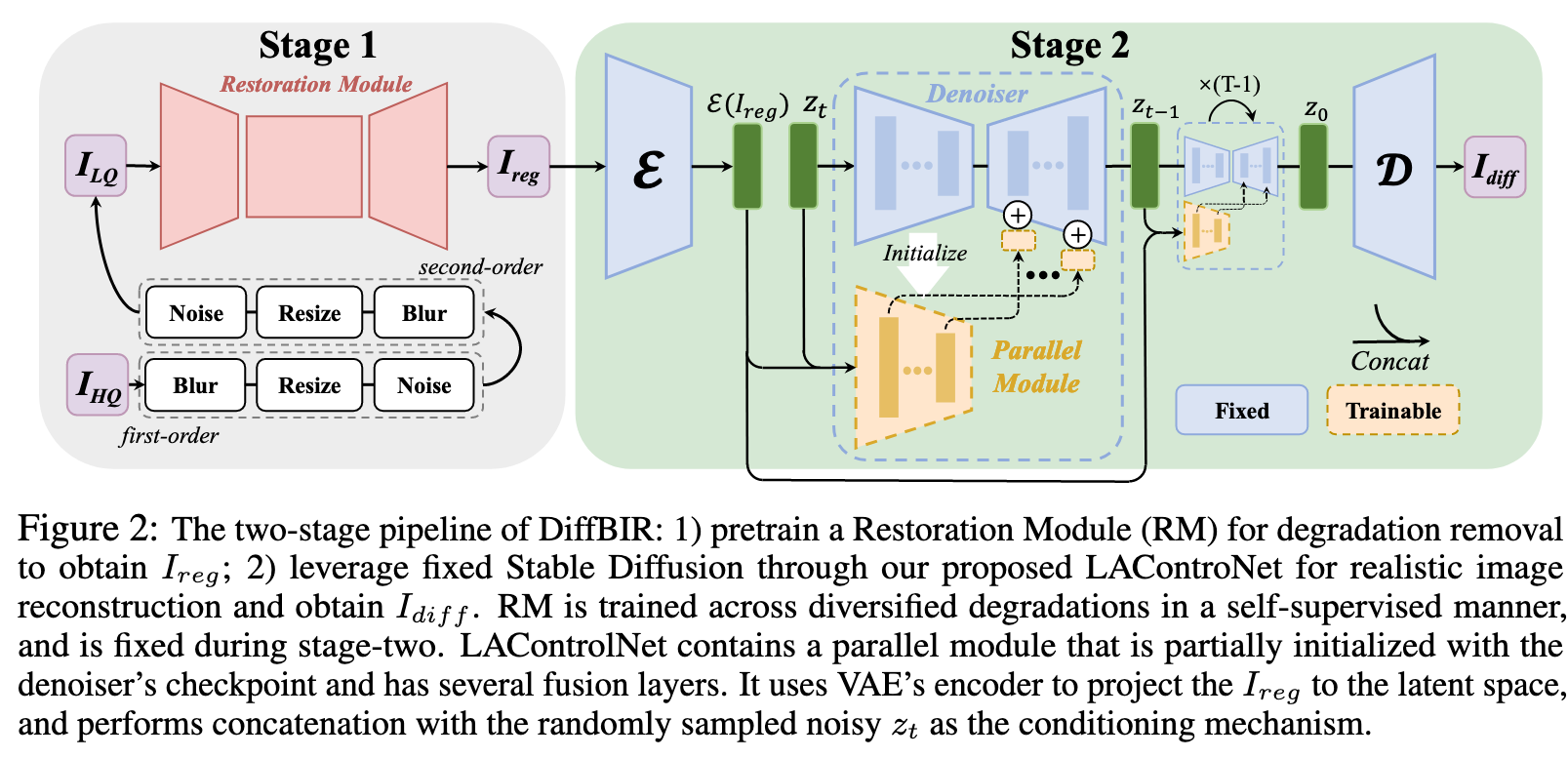
Pretraining for Degradation Removal
Degradation Module. In order to better cover the degradation space of the LQ images, we employ a comprehensive degradation model that considers diversified degradation and high-order degradation. Among all degradations, blur, resize, and noise are the three key factors in real-world scenarios [64]. Our diversified degradation involves blur: isotropic Gaussian and anisotropic Gaussian kernels; resize: area resize, bilinear interpolation and bicubic resize; noise: additive Gaussian noise, Poisson noise, and JPEG compression noise. Regarding high-order degradation, we follow [55] to use the second-order degradation, which repeats the classical degradation model: blur-resize-noise process twice. (p. 5)
Restoration Module. To build a robust generative image restoration pipeline, we adopt a conservative yet feasible solution by first removing most of the degradations (especially the noise and compression artifacts) in the LQ images, and then use the subsequent generative module to reproduce the lost information. This design will promote the latent diffusion model to focus more on textures/details generation without the distraction of noise corruption, and achieve more realistic/sharp results without wrong details (see Section 4.3). We modify SwinIR [36] as our restoration module. Specifically, we utilize the pixel unshuffle [50] operation to downsample the original low-quality input ILQ with a scale factor of 8. Then, a 3 × 3 convolutional layer is adopted for shallow feature extraction. All the subsequent transformer operations are performed in low resolution space, which is similar to latent diffusion model. The deep feature extraction adopts several Residual Swin Transformer Blocks (RSTB), and each RSTB has several Swin Transformer Layers (STL). The shallow and deep features will be added for maintaining both low-frequency and high-frequency information. For upsampling the deep features back to the original image space, we perform nearest interpolation for three times, and each interpolation is followed by one convolutional layer as well as one Leaky ReLU activation layer. We optimize the parameters of the restoration module by minimizing the L2 pixel loss (p. 5)
Recover Details with Diffusion
Although stage-one could remove most degradations, the obtained I_reg is often over-smoothed and still far from the distribution of high-quality natural images. We then leverage the pre-trained Stable Diffusion for image reconstruction with our obtained I_reg-I_HQ pairs (p. 5)
Then, we concatenate the condition latent E(Ireg) with the randomly sampled noisy zt as the input for the parallel module. Since this concatenation operation will increase the channel number of the first convolutional layer in the parallel module, we initialize the newly added parameters to zero, where all other weights are initialized from the pre-trained UNet denoiser checkpoints. The outputs of the parallel module are added to the original UNet decoder. (p. 5)
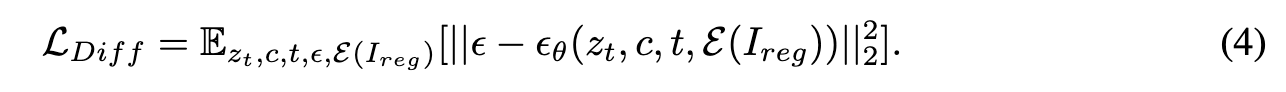

Without finetuning tends to generate unrealistic content (i.e., a bird with one leg missing). and ControlNet tends to output results with color shifts.
Latent Image Guidance for Fidelity-Realness Trade-off
The above guidance could iteratively force spatial alignment and color consistency between latent features, and guide the generated latent to preserve the content of the reference latent.


Experiment Result