Raising the Cost of Malicious AI-Powered Image Editing
[text2image diffusion gan attack deep-learning privacy image2image This is my reading note for Raising the Cost of Malicious AI-Powered Image Editing. This paper proposes a method to stop an image being edited by on diffusion model. The method is based on adverbial attack: learn a perturbation to the target image such that the model (encoder or diffusion) will generate noise or degraded image. However this method may not always work or may fall when the model changes.

Introduction
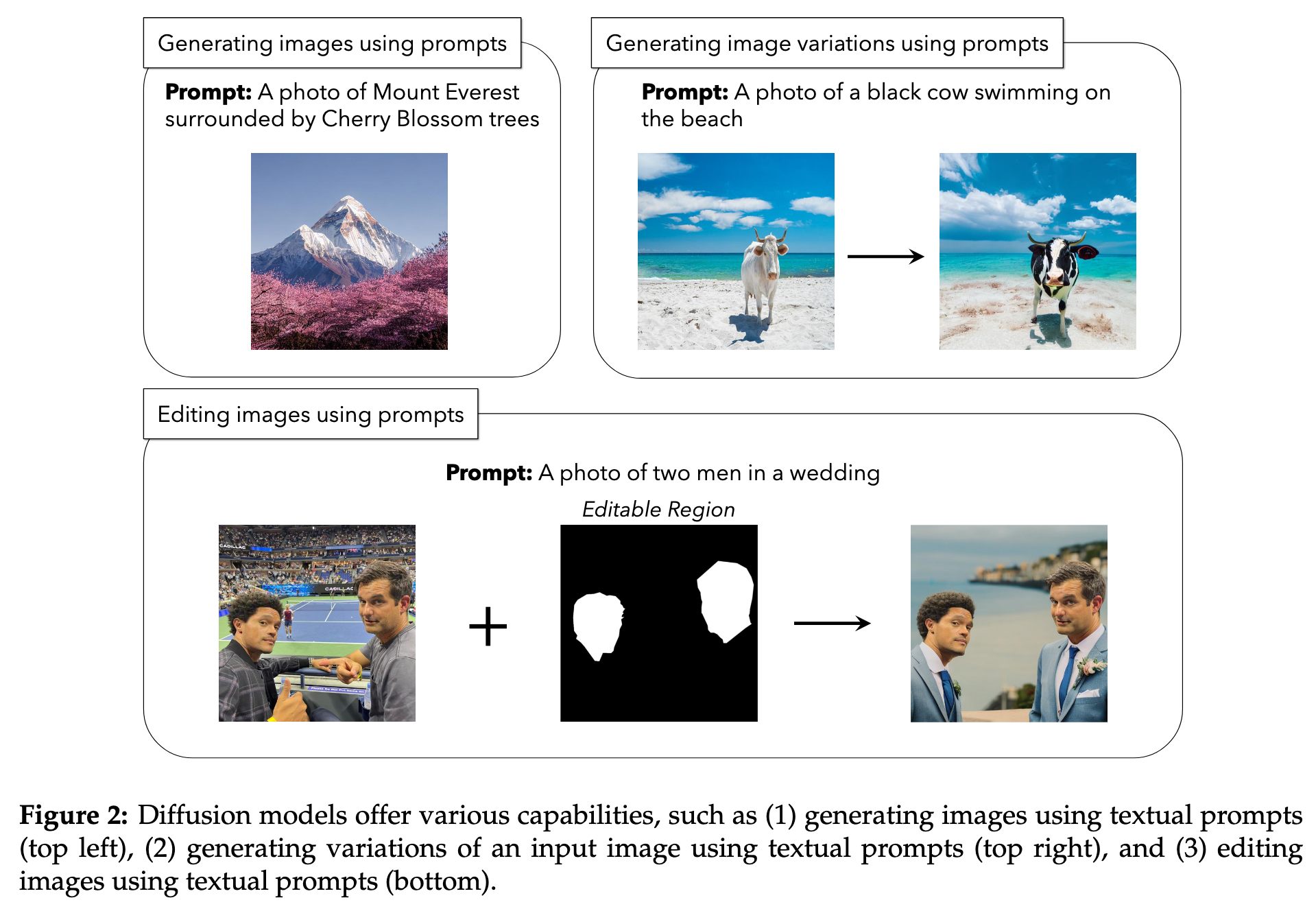
We present an approach to mitigating the risks of malicious image editing posed by large diffusion models. The key idea is to immunize images so as to make them resistant to manipulation by these mod- els. This immunization relies on injection of imperceptible adversarial perturbations designed to disrupt the operation of the targeted diffusion models, forcing them to generate unrealistic images. We provide two methods for crafting such perturbations, and then demonstrate their efficacy. (p. 1)
Related Work
Data misuse after model training
Recent advances in ML-powered image generation and editing have raised concerns about the potential misuse of personal data for generating fake images. (p. 9)
Deepfake detection
A line of work related to ours aims to detect fake images rather than prevent their generation. Deepfake detection methods include analyzing the consistency of facial expressions and iden- tifying patterns or artifacts in the image that may indicate manipulation, and training machine learning models to recognize fake images [KM18; ANY+18; NNN+19; ML21; RCV+19; DKP+19; LBZ+20; LYS+20; BCM+21]. While some deepfake detection methods are more effective than others, no single method is fool- proof. A potential way to mitigate this shortcoming could involve development of so-called watermarking methods [CKL+97; NHZ+22]. These methods aim to ensure that it is easy to detect that a given output has been produced using a generative model—such watermarking approaches have been recently developed for a related context of large language models [KGW+23]. Still, neither deepfake detection nor watermark- ing methods could protect images from being manipulated in the first place (p. 9)
Data misuse during model training
The abundance of readily available data on the Internet has played a significant role in recent breakthroughs in deep learning, but has also raised concerns about the potential misuse of such data when training models. Therefore, there has been an increasing interest in protection against unauthorized data exploitation, e.g., by designing unlearnable examples [HME+21; FHL+21]. These methods propose adding imperceptible backdoor signals to user data before uploading it online, so as to prevent models from fruitfully utilizing this data. However, as pointed out by Radiya-Dixit et al. [RHC+21], these methods can be circumvented, often simply by waiting until subsequently developed models can avoid being fooled by the planted backdoor signal. (p. 9)
Preliminaries
Diffusion
Adversarial Attacks
For a given computer vision model and an image, an adversarial example is an imperceptible perturbation of that image that manipulates the model’s behavior [SZS+14; BCM+13]. In image classification, for example, an adversary can construct an adversarial example for a given image x that makes it classified as a specific target label y_targ (different from the true label). This construction is achieved by minimizing the loss of a classifier fθ with respect to that image: (p. 4)
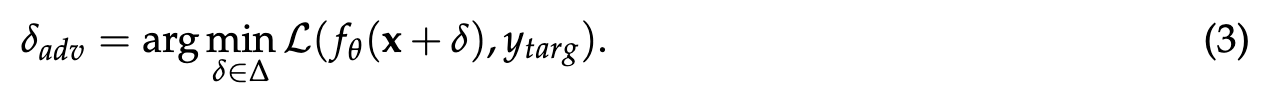
Adversarially Attacking Latent Diffusion Models
Specifically, we present two different methods to execute this strategy (see Figure 3): an encoder attack, and a diffusion attack. (p. 4)
Encoder attack
The key idea behind our encoder attack is now to disrupt this process by forcing the encoder to map the input image to some “bad” representation (p. 4)
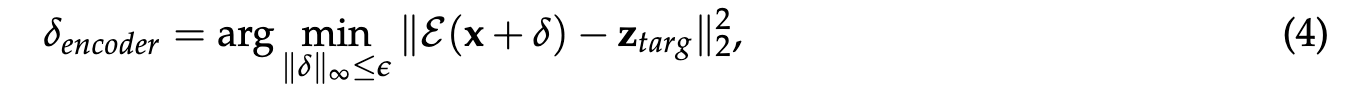
z_targ is some target latent representation (e.g., z_targ can be the representation, produced using encoder E, of a gray image) (p. 4)
Diffusion attack
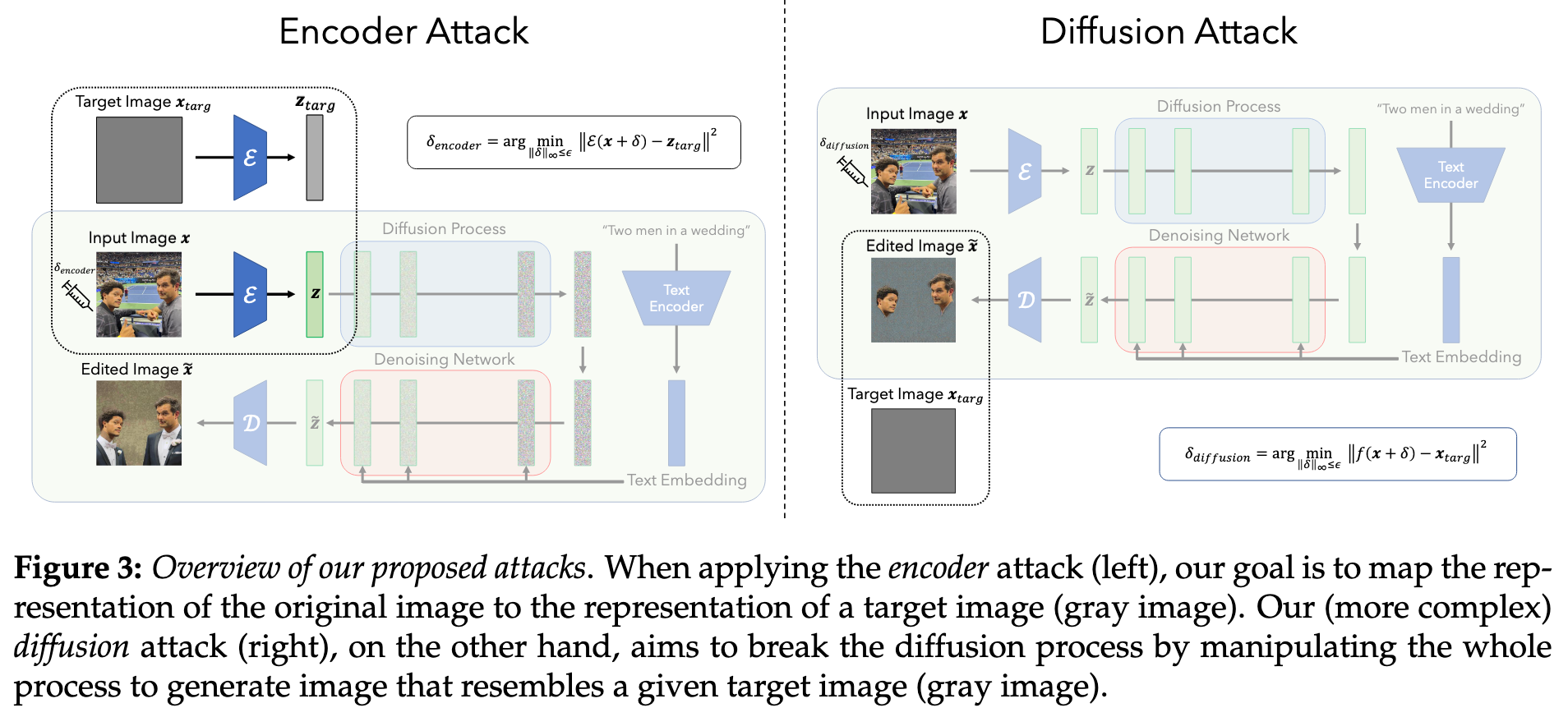
It turns out that we are able to do so by using a more complex attack, one where we target the diffusion process itself instead of just the encoder. In this attack, we perturb the input image so that the final image generated by the LDM is a specific target image (e.g., random noise or gray image) (p. 5)
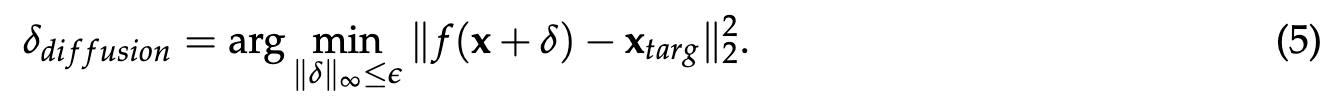
It is worth noting that this approach, although more powerful than the encoder attack, is harder to execute. Indeed, to solve the above problem (5) using PGD, one needs to backpropagate through the full diffusion process (which, as we recall from Section 2.1, includes repeated application of the denoising step). This causes memory issues even on the largest GPU we used7. To address this challenge, we backpropagate through only a few steps of the diffusion process, instead of the full process, while achieving adversarial perturbations that are still effective. (p. 5)
Results


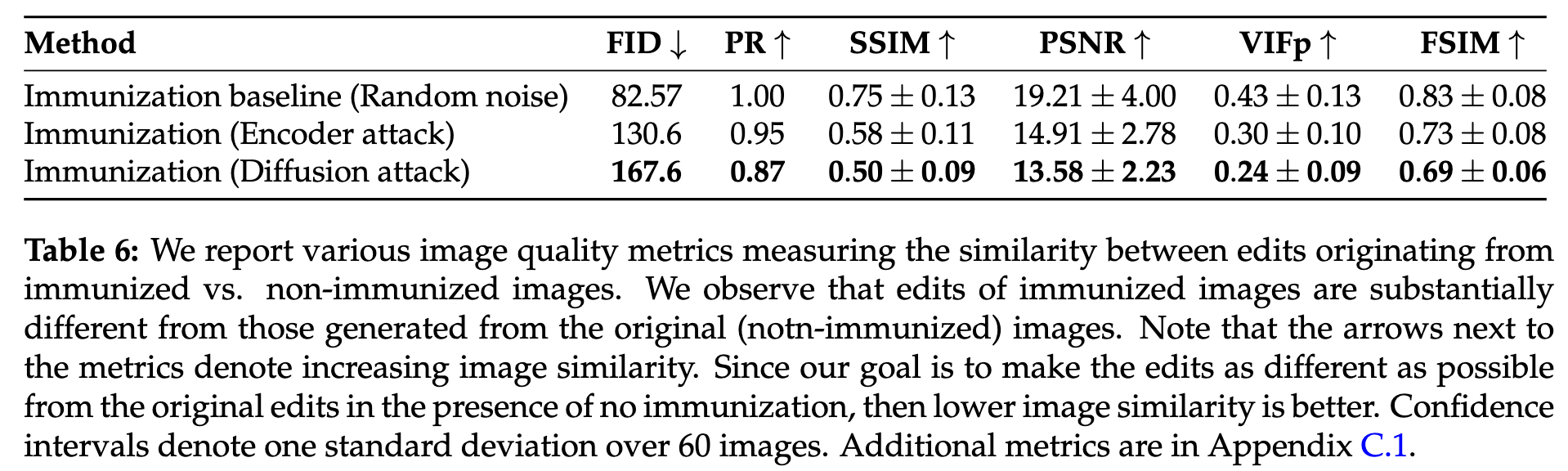
A Techno-Policy Approach to Mitigation of AI-Powered Editing
- (Lack of) robustness to transformations. One of the limitations of our immunization method is that the adversarial perturbation that it relies on may be ineffective after the immunized image is subjected to image transformations and noise purification techniques (p. 8)
- Forward-compatibility of the immunization. While the immunizing adversarial perturbations we produce might be effective at disrupting the current generation of diffusion-based generative models, they are not guaranteed to be effective against the future versions of these models. This can be accomplished by planting, when training such future models, the current immunizing adversarial perturbations as backdoors. (p. 8)