DiffusionDet Diffusion Model for Object Detection
[mask-rcnn diffusion object-detection retina-net diffusion-det deep-learning resnet detr sparse-rcnn transformer r-cnn swin-transformer cascade-rcnn faster-rcnn This is my reading note for DiffusionDet: Diffusion Model for Object Detection. This paper formulates the object detection problem as a diffusion process: recover object bounding box from noisy estimation. The initial estimation could be from purely random Gaussian noise. One benefit of this method is that it could automatically handle different number of bounding boxes
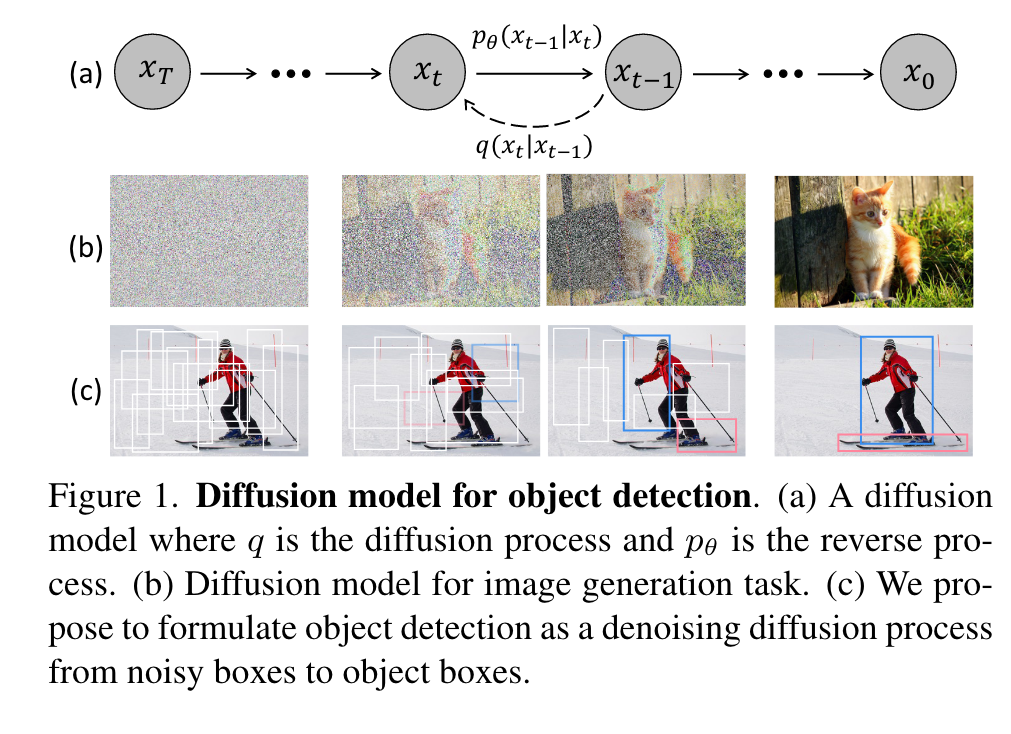
Introduction
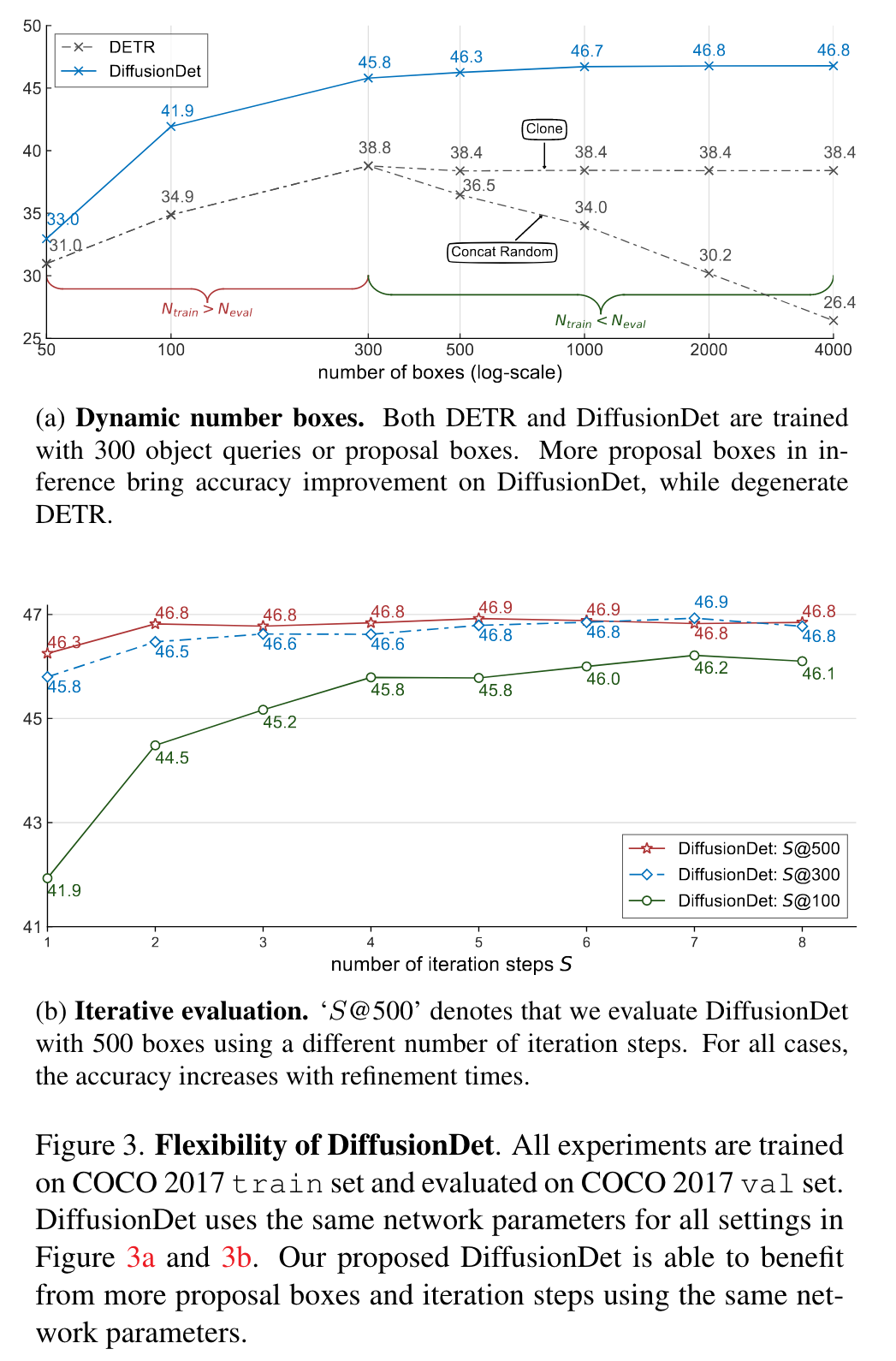
We propose DiffusionDet, a new framework that formulates object detection as a denoising diffusion process from noisy boxes to object boxes. During the training stage, object boxes diffuse from ground-truth boxes to random distribution, and the model learns to reverse this noising process. In inference, the model refines a set of randomly generated boxes to the output results in a progressive way. Our work possesses an appealing property of flexibility, which enables the dynamic number of boxes and iterative evaluation. (p. 1)
While these works achieve a simple and effective design, they still have a dependency on a fixed set of learnable queries. (p. 1)
At the training stage, Gaussian noise controlled by a variance schedule [38] is added to ground truth boxes to obtain noisy boxes. Then these noisy boxes are used to crop [36, 74] features of Region of Interest (RoI) from the output feature map of the backbone encoder, e.g., ResNet [37], Swin Transformer [60]. Finally, these RoI features are sent to the detection decoder, which is trained to predict the ground-truth boxes without noise. (p. 2)
As a probabilistic model, DiffusionDet has an attractive superiority of flexibility, i.e., we can train the network once and use the same network parameters under diverse settings in the inference stage, mainly including:
- Dynamic number of boxes. Leveraging random boxes as object candidates, we decouple the training and evaluation stage of DiffusionDet, i.e., we can train DiffusionDet with N_train random boxes while evaluating it with Neval random boxes, where the N_eval is arbitrary and does not need to be equal to N_train.
- Iterative evaluation. Benefited by the iterative denoising property of diffusion models, DiffusionDet can reuse the whole detection head in an iterative way, further improving its performance. (p. 2)
Related Work
Object detection
Most modern object detection approaches perform box regression and category classification on empirical object priors, such as proposals [27, 74], anchors [56, 72, 73], points [94, 96, 113]. Recently, Carion et al. proposed DETR [10] to detect objects using a fixed set of learnable queries. (p. 2)
Diffusion model for perception tasks.
Some pioneer works tried to adopt the diffusion model for image segmentation tasks [1, 5, 6, 13, 31, 47, 98], for example, Chen et al. [13] adopted Bit Diffusion model [14] for panoptic segmentation [49] of images and videos. (p. 3)
Proposed Method
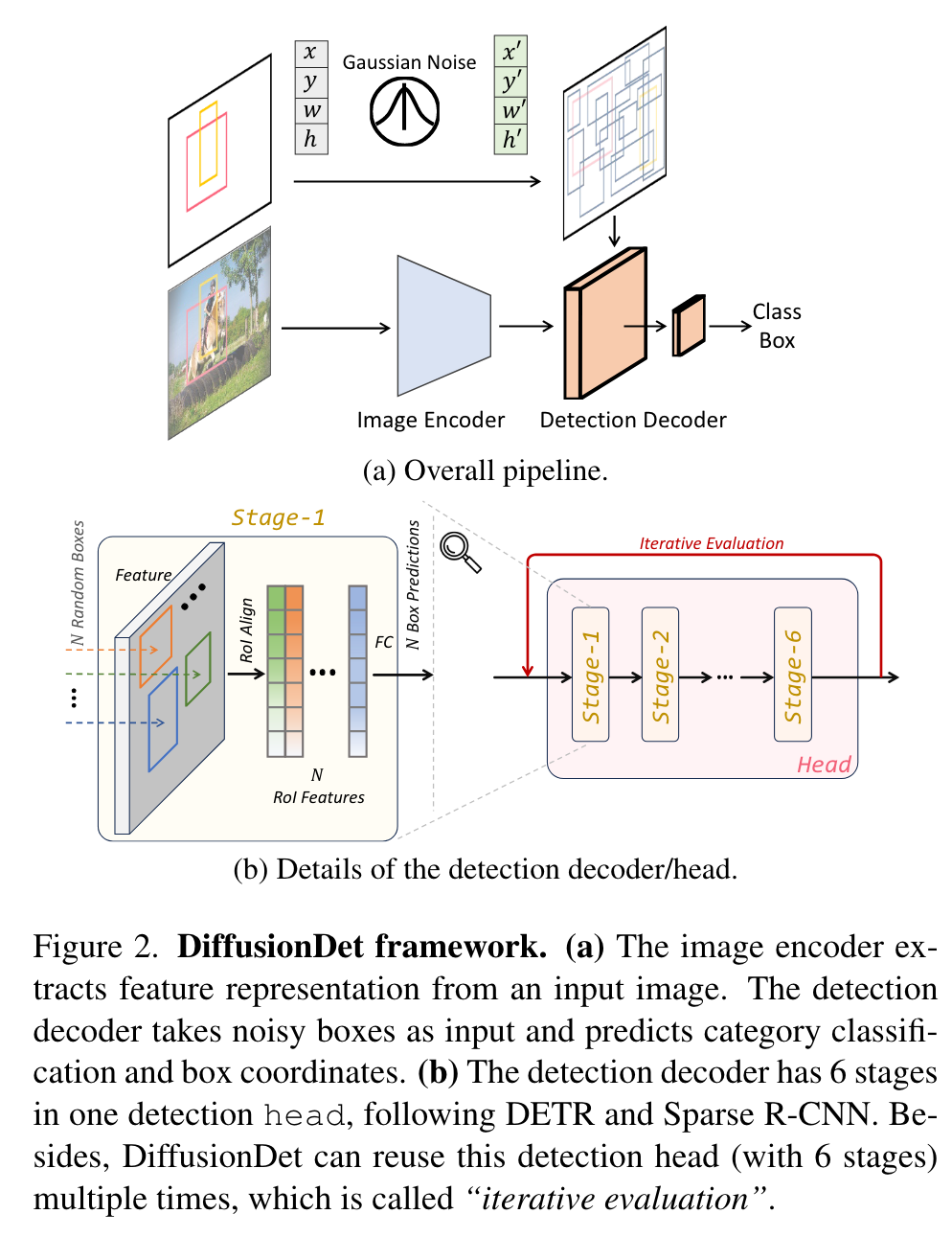
Architecture
we propose to separate the whole model into two parts, image encoder and detection decoder, where the former runs only once to extract a deep feature representation from the raw input image x, and the latter takes this deep feature as condition, instead of the raw image, to progressively refine the box predictions from noisy boxes zt. (p. 3)
Detection decoder
Borrowed from Sparse R-CNN [91], the detection decoder takes as input a set of proposal boxes to crop RoI-feature [36, 74] from feature map generated by image encoder, and sends these RoI-features to detection head to obtain box regression and classification results. For DiffusionDet, these proposal boxes are disturbed from ground truth boxes at training stage and directly sampled from Gaussian distribution at evaluation stage. Following [10, 91, 115], our detection decoder is composed of 6 cascading stages (Figure 2b). The differences between our decoder and the one in Sparse R-CNN are that (1) DiffusionDet begins from random boxes while Sparse R-CNN uses a fixed set of learned boxes in inference; (2) Sparse RCNN takes as input pairs of the proposal boxes and its corresponding proposal feature, while DiffusionDet needs the proposal boxes only; (3) DiffusionDet can re-use the detector head in an iterative way for evaluation and the parameters are shared across different steps, each of which is specified to the diffusion process by timestep embedding [38], which is called iterative evaluation, while Sparse R-CNN uses the detection decoder only once in the forward pass. (p. 4)
Training
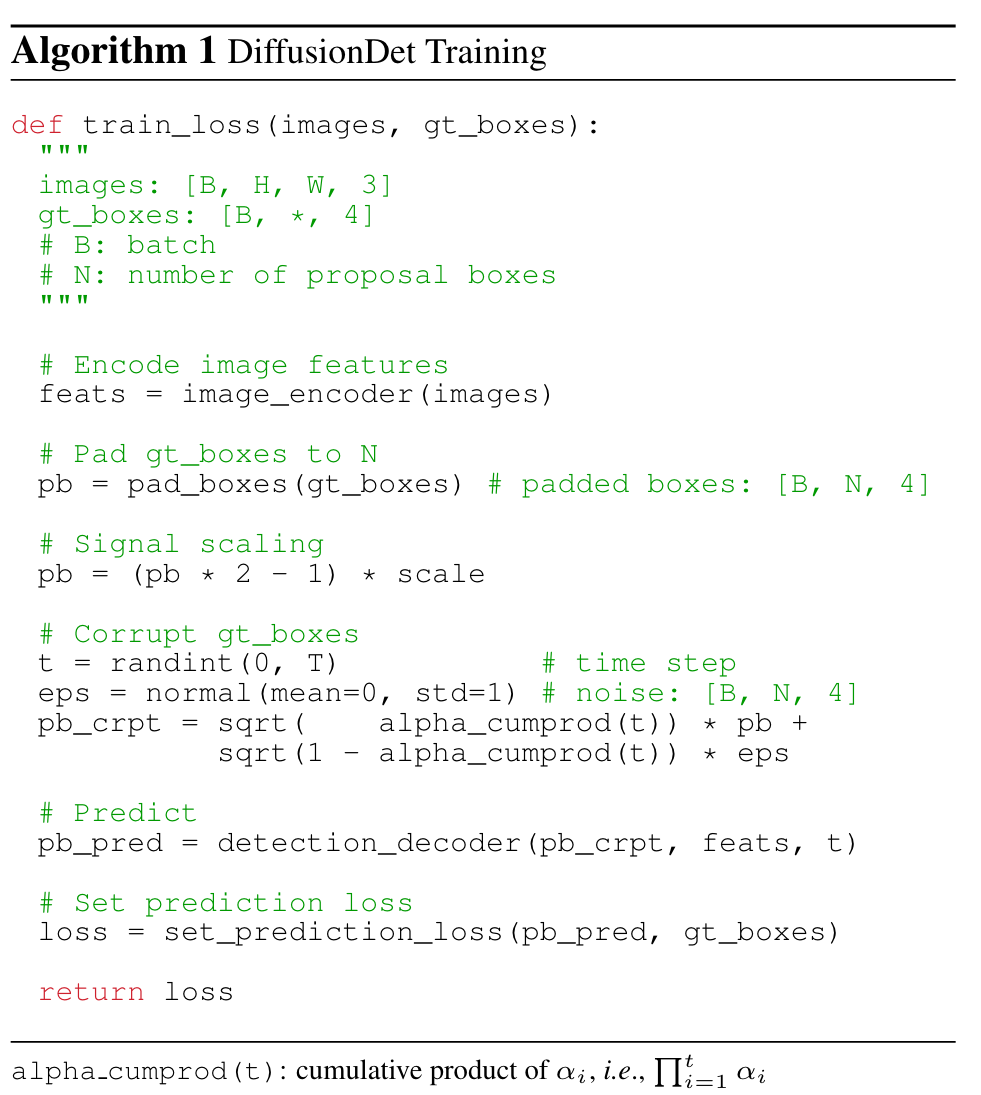
Ground truth boxes padding
we first pad some extra boxes to original ground truth boxes such that all boxes are summed up to a fixed number N_train. (p. 4)
Box corruption
We add Gaussian noises to the padded ground truth boxes. The noise scale is controlled by αt (in Eq. (1)), which adopts the monotonically decreasing cosine schedule for α_t in different time step t, as proposed in [67]. Notably, the ground truth box coordinates need to be scaled as well since the signal-to-noise ratio has a significant effect on the performance of diffusion model [13]. We observe that object detection favors a relatively higher signal scaling value than image generation task [14, 16, 38]. (p. 4)
Training losses
The detection detector takes as input N_train corrupted boxes and predicts N_train predictions of category classification and box coordinates. We apply set prediction loss [10, 91, 115] on the set of N_train predictions. We assign multiple predictions to each ground truth by selecting the top k predictions with the least cost by an optimal transport assignment method [18, 25, 26, 99]. (p. 4)
Inference

Starting from boxes sampled in Gaussian distribution, the model progressively refines its predictions, as shown in Algorithm 2. (p. 4)
Sampling step
In each sampling step, the random boxes or the estimated boxes from the last sampling step are sent into the detection decoder to predict the category classification and box coordinates. After obtaining the boxes of the current step, DDIM [85] is adopted to estimate the boxes for the next step. (p. 5)
Box renewal
After each sampling step, the predicted boxes can be coarsely categorized into two types, desired and undesired predictions. The desired predictions contain boxes that are properly located at corresponding objects, while the undesired ones are distributed arbitrarily. Directly sending these undesired boxes to the next sampling iteration would not bring a benefit since their distribution is not constructed by box corruption in training. To make inference better align with training, we propose the strategy of box renewal to revive these undesired boxes by replacing them with random boxes. Specifically, we first filter out undesired boxes with scores lower than a particular threshold. Then, we concatenate the remaining boxes with new random boxes sampled from a Gaussian distribution. (p. 5)
Experiment
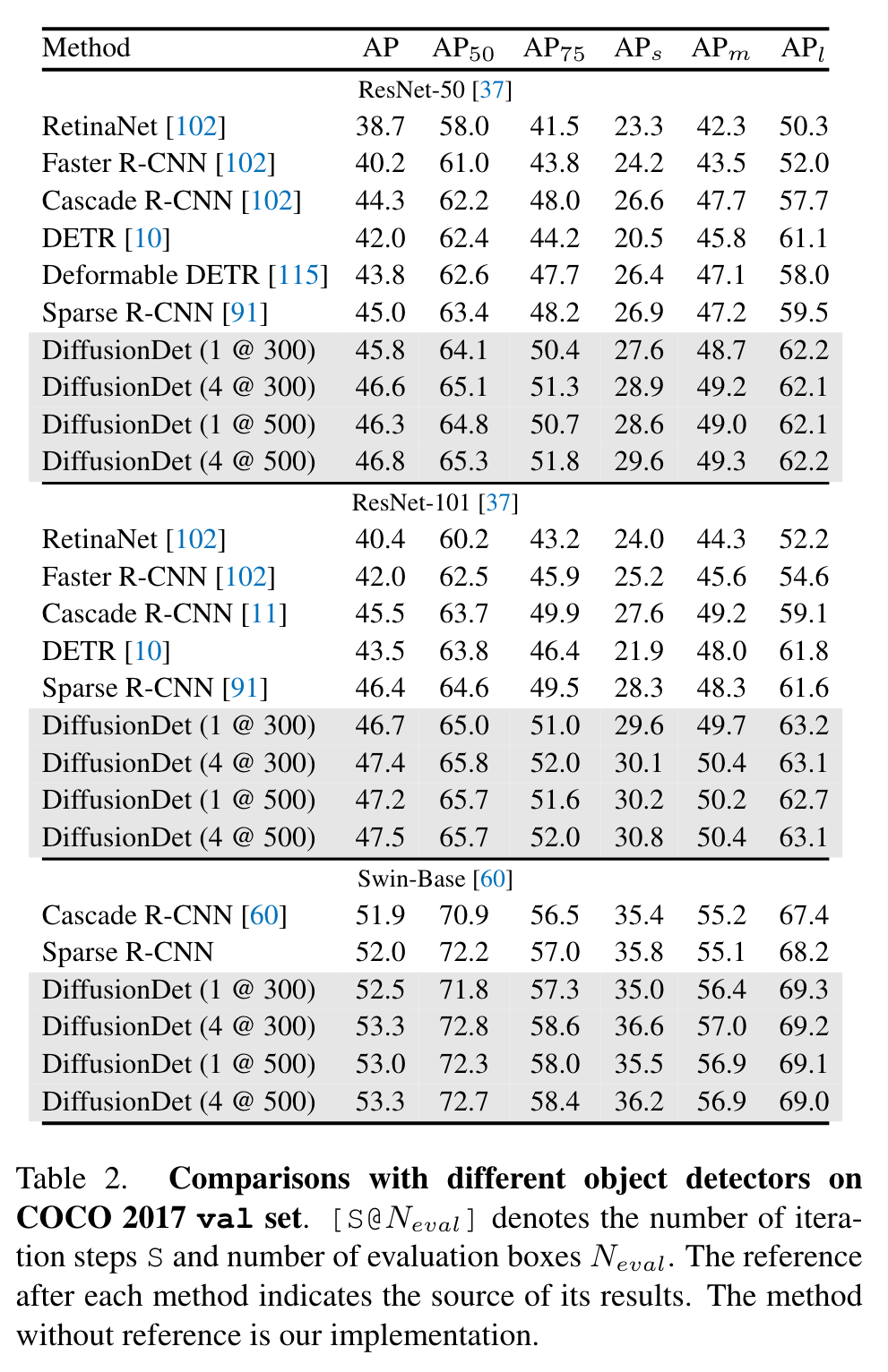
Our current model is still lagging behind behind some well developed works like DINO [108] since it uses some more advanced components such as deformable attention [115], wider detection head. Some of these techniques are orthogonal to DiffusionDet and we will explore to incorporate these to our current pipeline for further improvement. (p. 7)
Ablation Study
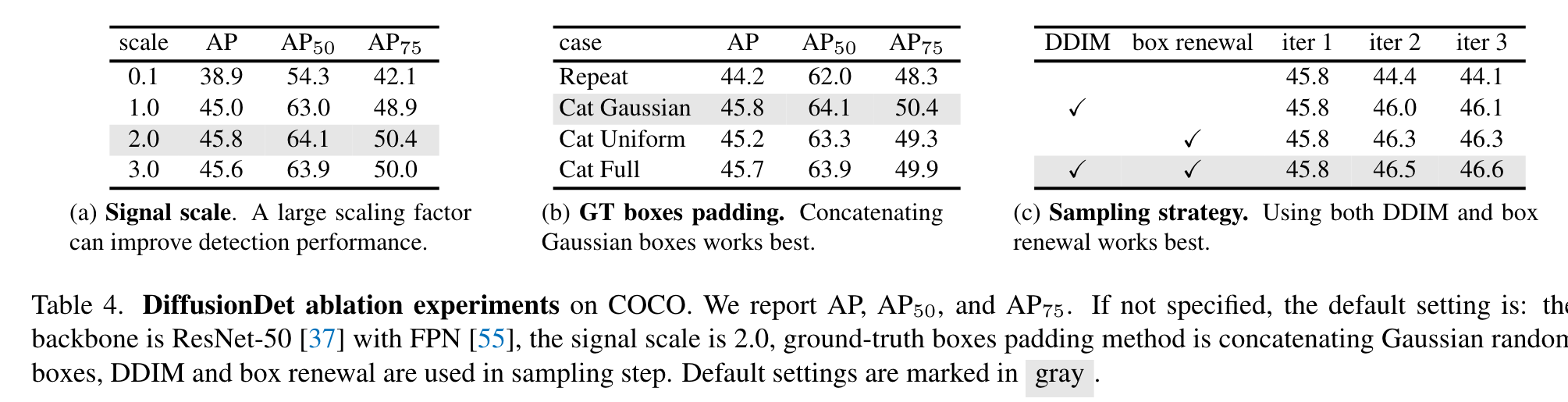
Signal scaling
The signal scaling factor controls the signal-to-noise ratio (SNR) of the diffusion process. We study the influence of scaling factors in Table 4a. Results demonstrate that the scaling factor of 2.0 achieves optimal AP performance, outperforming the standard value of 1.0 in image generation task [14, 38] and 0.1 used for panoptic segmentation [13]. We explain that it is because one box only has four representation parameters, i.e., center coordinates (cx, cy) and box size (w, h), which is coarsely analogous to an image with only four pixels in image generation. The box representation is more fragile than the dense representation, e.g., 512 × 512 mask presentation in panoptic segmentation [14]. Therefore, DiffusionDet prefers an easier training objective with an increased signal-to-noise ratio compared to image generation and panoptic segmentation. (p. 8)
GT boxes padding strategy
We study different padding strategies in Table 4b, including (1) repeating original ground truth boxes evenly until the total number reaches pre-defined value N_train; (2) padding random boxes that follow Gaussian distribution; (3) padding random boxes that follow uniform distribution; (4) padding boxes that have the same size as the whole image, which is the default initialization of learnable boxes in [91]. Concatenating Gaussian random boxes works best for DiffusionDet (p. 8)
Sampling strategy
We found that the AP of DiffusionDet degrades with more iteration steps when neither DDIM nor box renewal is adopted. (p. 8)
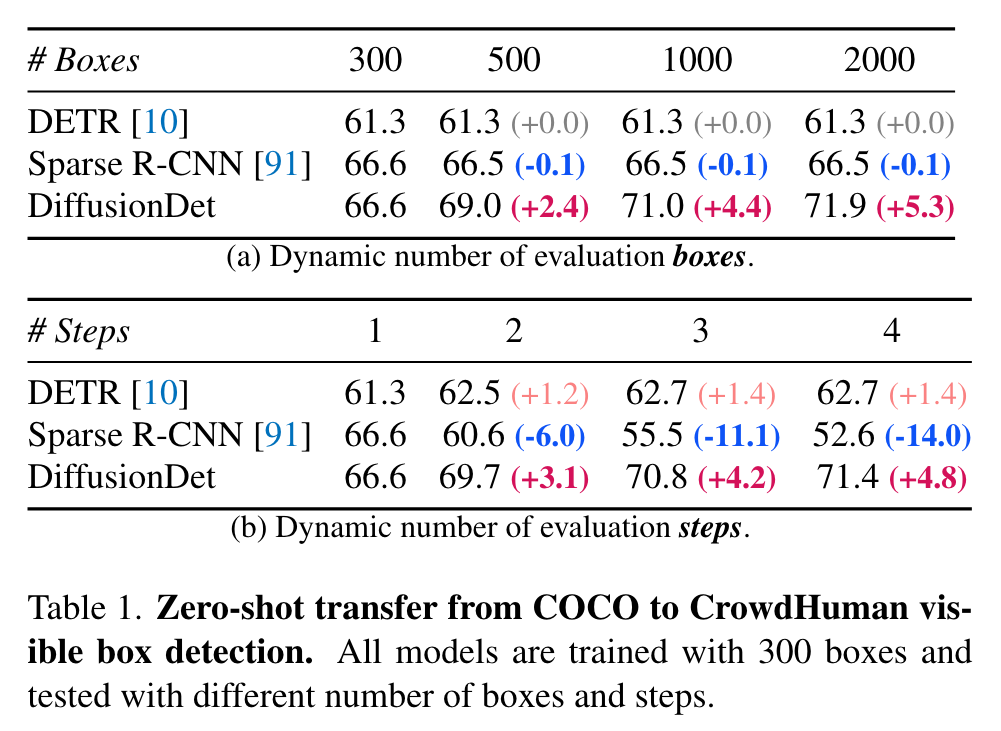
Matching between N_train and N_eval
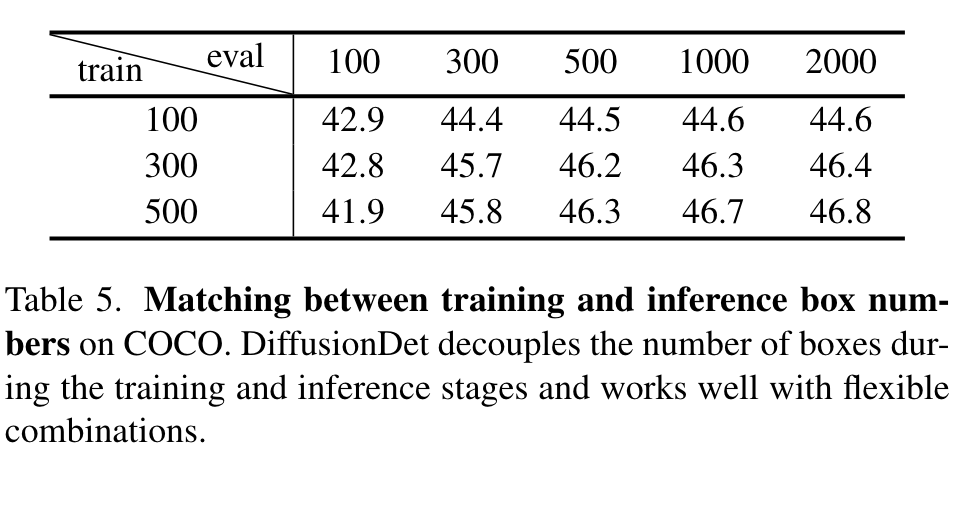
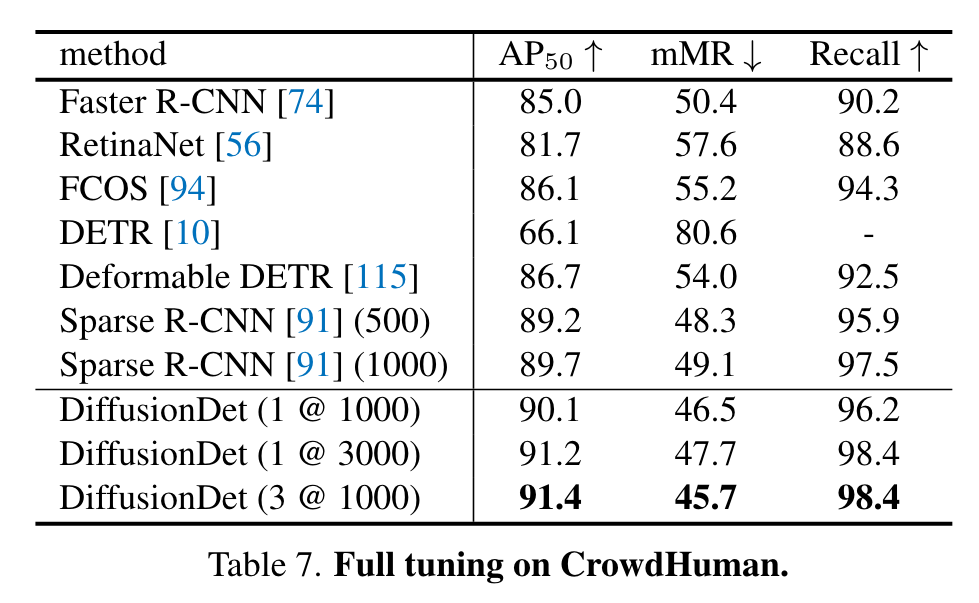
First, no matter how many random boxes DiffusionDet uses for training, the accuracy increases steadily with the Neval until the saturated point at around 2000 random boxes. Second, DiffusionDet tends to perform better when the Ntrain and Neval matches with each other. (p. 8)
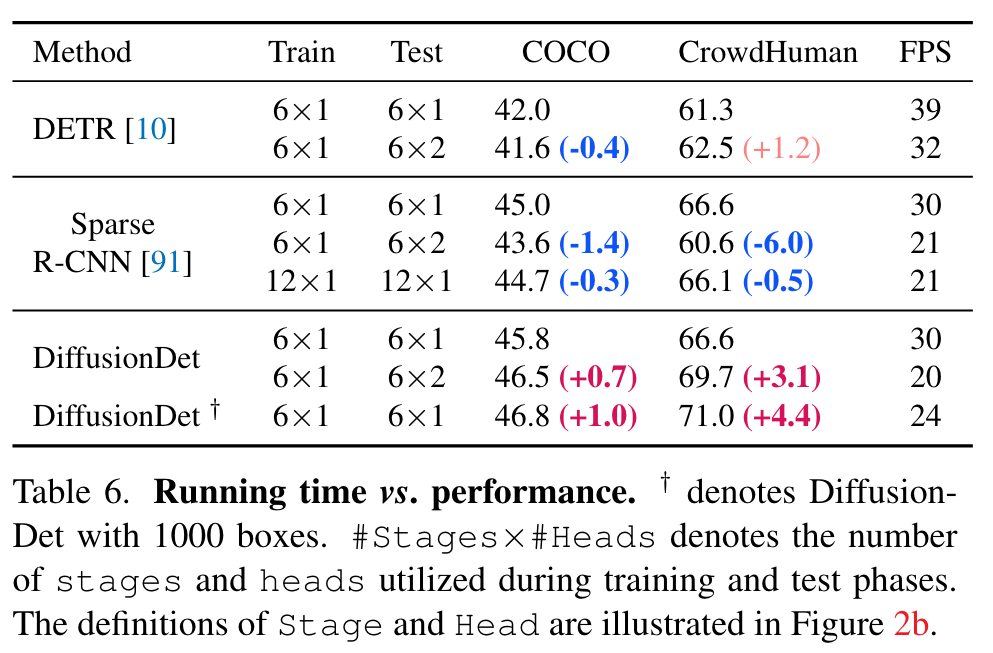
Running time vs. accuracy
The model is evaluated on a single NVIDIA A100 GPU with a mini-batch size of 1. First, our findings indicate that DiffusionDet with a single iteration step and 300 evaluation boxes demonstrate a comparable speed to Sparse R-CNN, achieving 30 and 31 frames per second (FPS), respectively. (p. 8)
Random Seed
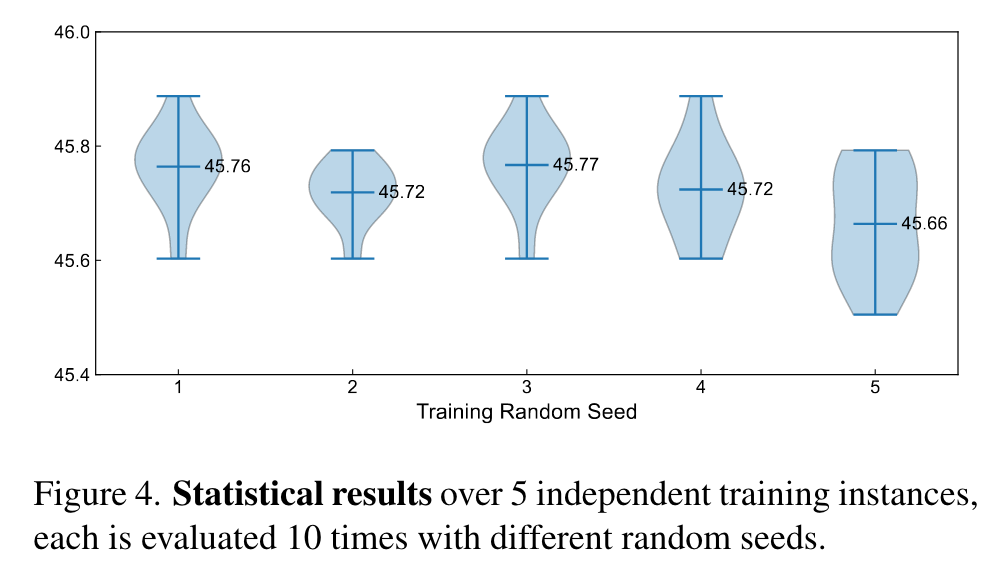
As shown in Figure 4, most evaluation results are distributed closely to 45.7 AP. Besides, the performance differences among different model instances are marginal, demonstrating that DiffusionDet is robust to the random boxes and produces reliable results. (p. 1)