Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training
[transformer multimodal deep-learning diht clip distillation concept-distillation cat hard-negative-mining noise-contrast-estimation nce infor-nce mixup align albef This is my reading note for Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training. This paper proposes several methods to improve image-text model pre-training: 1) filtering the dataset according complexity, action and text spotting (CAT); 2) concept distillation (object category and attributes); 3) hard negative mining for contrast pairs.
Introduction
In this paper we improve the following three aspects of the contrastive pre-training pipeline: dataset noise, model initialization and the training objective. First, we propose a straightforward filtering strategy titled Complexity, Action, and Textspotting (CAT) that significantly reduces dataset size, while achieving improved performance across zero-shot visionlanguage tasks. Next, we propose an approach titled Concept Distillation to leverage strong unimodal representations for contrastive training that does not increase training complexity while outperforming prior work. Finally, we modify the traditional contrastive alignment objective, and propose an importance-sampling approach to up-sample the importance of hard-negatives without adding additional complexity. (p. 1)
On the other hand, momentum-based approaches [41] to reduce noise are infeasible for large-scale training due to their increased compute and memory requirements. To this end, we provide a scalable and effective approach titled Complexity, Action and Text-spotting (CAT) filtering. CAT is a filtering strategy to select only informative text-image pairs from noisy web-scale datasets. (p. 1)
However, due to the increased noise in image-text data, fine-tuning the entire model undermines the benefits of the warm-start. One can alternatively use model freezing strategies like locked-image tuning [89], but they are unable to adapt to the complex queries present in multimodal problems (e.g., cross-modal retrieval) and the models perform poorly on retrieval benchmarks (see Section 4.2). We propose an entirely different approach, concept distillation (CD), to leverage strong pre-trained vision models. The key idea behind concept distillation is to train a linear classifier on the image encoder to predict the distilled concepts from a pre-trained teacher model, inspired by results in weakly supervised large-scale classification [49, 71]. (p. 2)
Finally, we revisit the training objective: almost all prior work has utilized noise-contrastive estimation via the InfoNCE loss [55], shortcomings have been identified in the standard InfoNCE formulation [12, 30]. We demonstrate that by using a model-based importance sampling technique to emphasize harder negatives, one can obtain substantial improvements in performance. (p. 2)
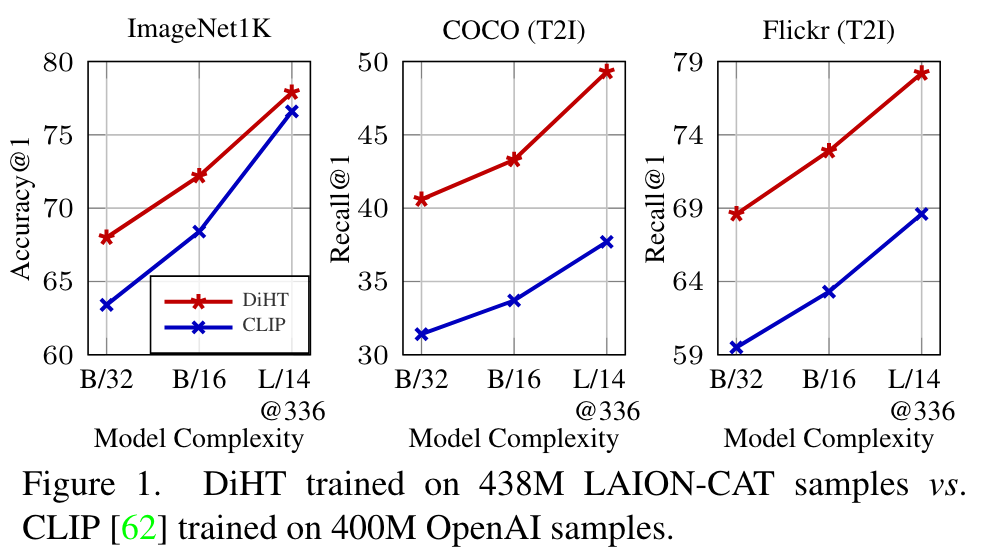
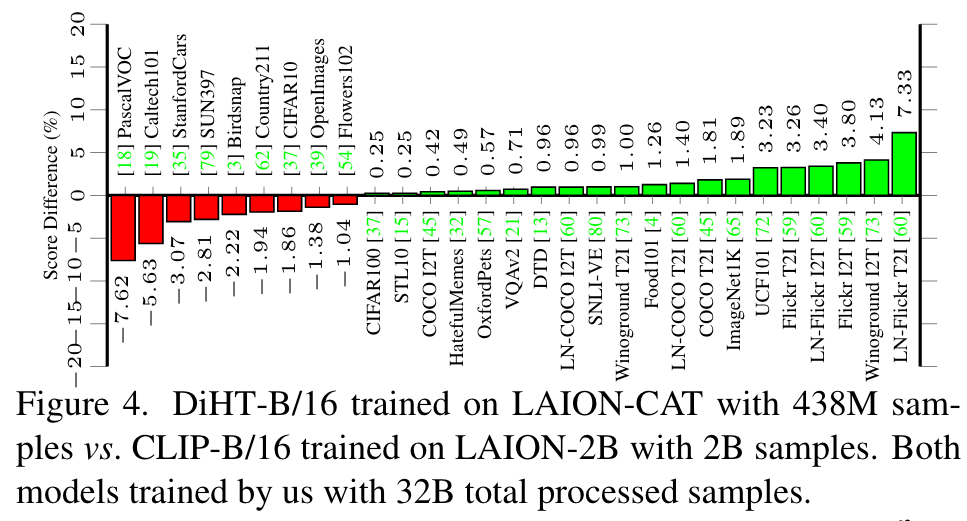
Specifically, with the ViTB/16 [17] architecture, we improve zero-shot performance on 20 out of 29 tasks, over CLIP training on the LAION2B dataset [27, 66], despite training on a subset that is 80% smaller, see Figure 4. (p. 2)
Related Work
used CLIP-based scores to filter down a large dataset (p. 2)
Distillation from pre-trained visual models
Several approaches use self-distillation to improve performance with lower computational overhead [23,82,88]. For vision and language pre-training, [2,31,41] use soft-labels computed using embeddings from a moving average momentum model with the goal to reduce the adverse effects of noisy image-text pairs in the training data. Our concept distillation approach is a cheaper and more effective alternative, since it does not require us to run the expensive teacher model throughout the training2 while retaining the most useful information from the visual concepts. (p. 2)
Another approach to take advantage of pre-trained visual models is to use them to initialize the image encoder, and continue pre-training either by locking the image encoder [58, 89] or fine-tuning [58]. However, these approaches lack the ability to align complex text to a fully trained image encoder, and thus perform poorly on multimodal tasks, e.g. cross-modal retrieval (see Section 4.3). (p. 2)
Contrastive training with hard negatives
Several lines of work have studied the shortcomings of the original InfoNCE objective [55], specifically, the selection and importance of negative samples. Chuang et al. [12] present a debiasing approach to account for false negatives at very large batch sizes, typical in large-scale pretraining. Kalantidis et al. [30] present a MixUp approach to improve the quality of hard negative samples for unsupervised alignment. Using model-specific hard negatives in the training objective is proven to reduce the estimation bias of the model as well [90]. (p. 3)
Proposed Method
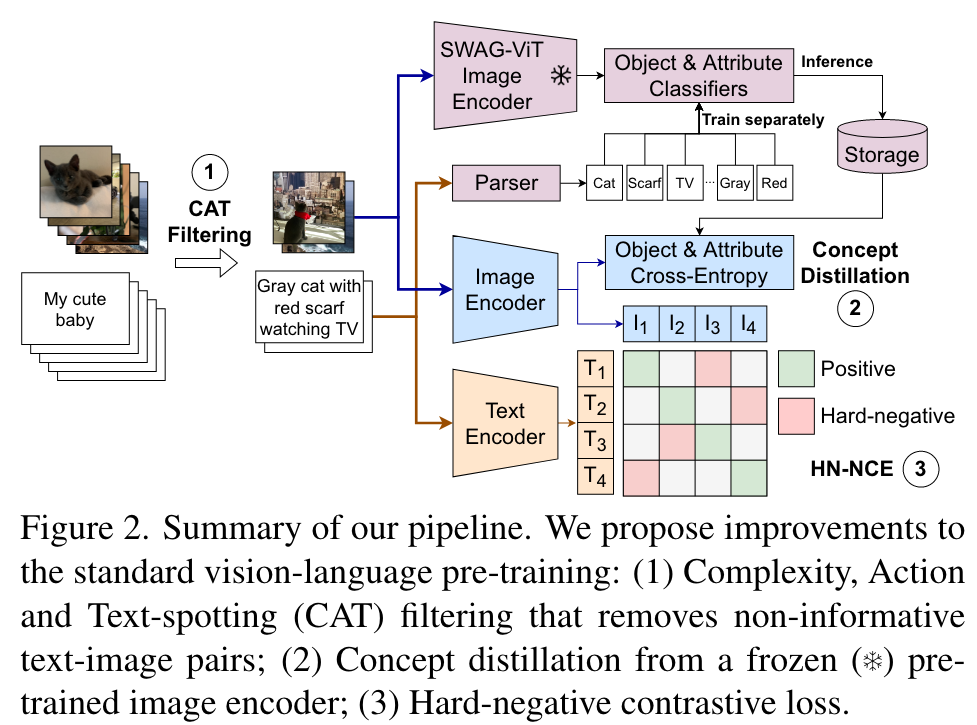
Complexity, Action, and Text (CAT) filtering
Our complexity, action, and text spotting (CAT) filtering is a combination of two filters: a caption complexity filter that removes image-caption pairs if a caption is not sufficiently complex, and an image filter that removes pairs if the image contains text matching the caption to prevent polysemy during alignment. (p. 3)
Filtering captions via complexity & actions
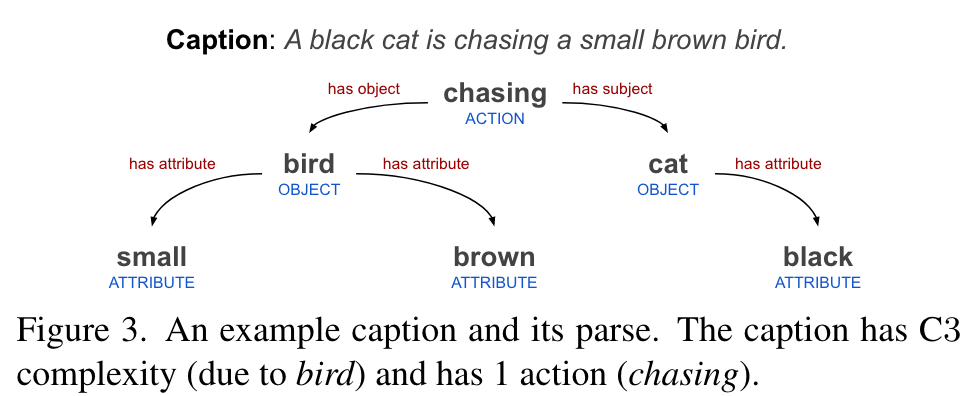
Our motivation is to decrease such noise by simply selecting captions that possess sufficient complexity, so that the training distribution matches the target tasks. To this end, we build a fast rule-based parser that extracts objects, attributes and action relations (see Figure 3 for an example) from text and we use the resulting semantic graph to estimate the complexity of the image captions. Specifically, we define the complexity of a caption as the maximum number of relations to any object present in the parse graph. We only retain samples that at least have a C1 caption complexity. (p. 3)
Filtering images via text-spotting
We remove image-text pairs with a text spotting confidence of at least 0.8 and at least 5 predicted characters matching the caption in a sliding window. (p. 3)
Concept distillation
Specifically, we add two auxiliary linear classifiers on top of the encoded image embeddings x to predict (i) objects and (ii) visual attributes and use the teacher model to generate the pseudo-labels for training them. These classifiers are trained jointly with the contrastive loss. (p. 3)
We parse image captions using a semantic parser that extracts objects and attributes from text (Section 3.1) and use these as pseudo-labels. We then train the linear classifiers on the teacher model embeddings with a soft-target cross-entropy loss [20], after square-root upsampling low frequency concepts [49]. It is important to freeze the backbone of the teacher model to make sure we retain the advantages of using a stronger model for distillation. (p. 3)
we then use these trained linear classifiers to generate two softmax probability vectors – p_obj for objects, and p_attr for attributes, respectively. To minimize the storage overhead, we further sparsify them by retaining only the top-k predicted class values and re-normalizing them to generate the final pseudo-labels. During multimodal training, we use the cross-entropy loss with these pseudo-label vectors as targets. (p. 4)
Multimodal alignment with hard negatives
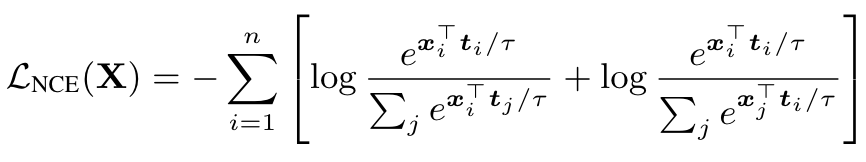
when learning from large scale noisy datasets, uniform sampling as applied in noise contrastive estimation can often provide negative samples that are not necessarily discriminative, necessitating very large batch sizes. Robinson et al. [63] propose an importance-sampling approach to reweight negative samples within a batch so that “harder” negatives are upsampled in proportion to their difficulty. (p. 4)
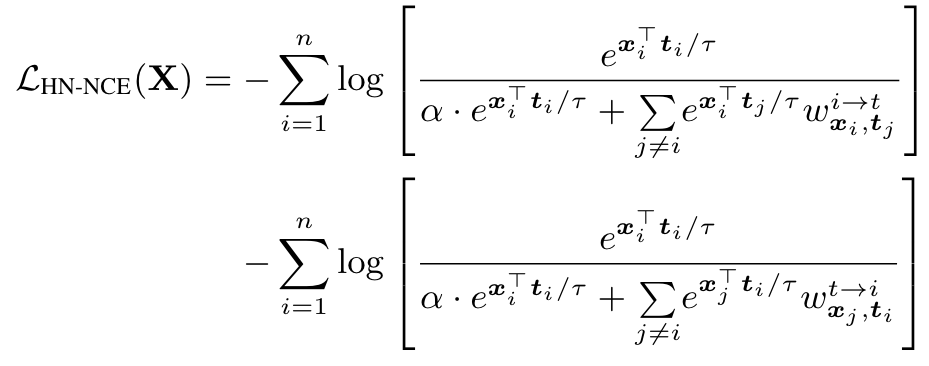
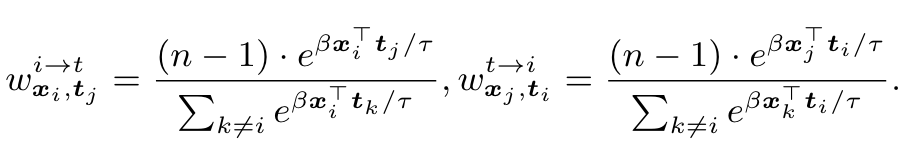
Training objective
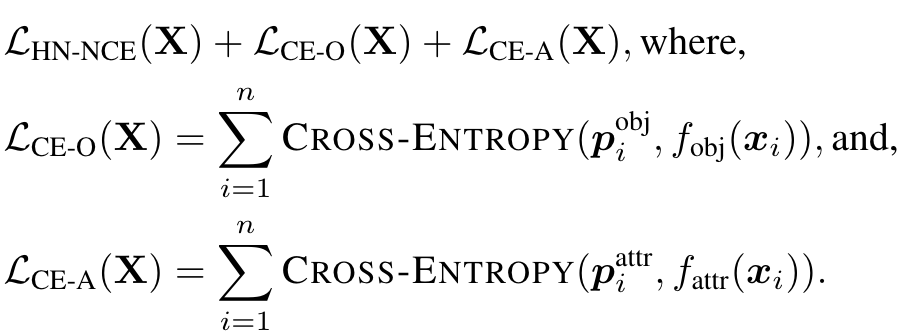
Experiments
Zero-shot benchmarks
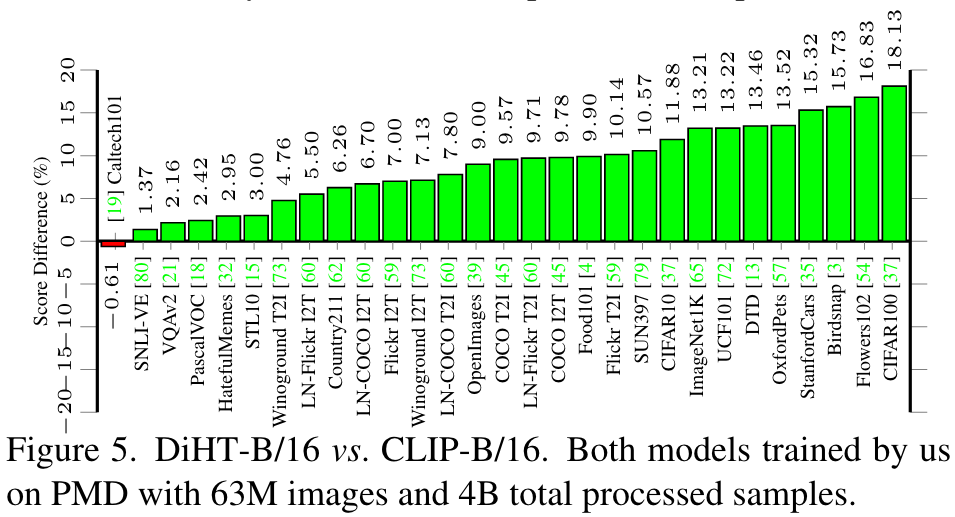
Comparison with zero-shot state of the art
Note that Florence [87] utilizes a more recent and powerful Swin-H Vision Transformer architecture [46] with convolutional embeddings [78], and a unified contrastive objective [84]. (p. 7)
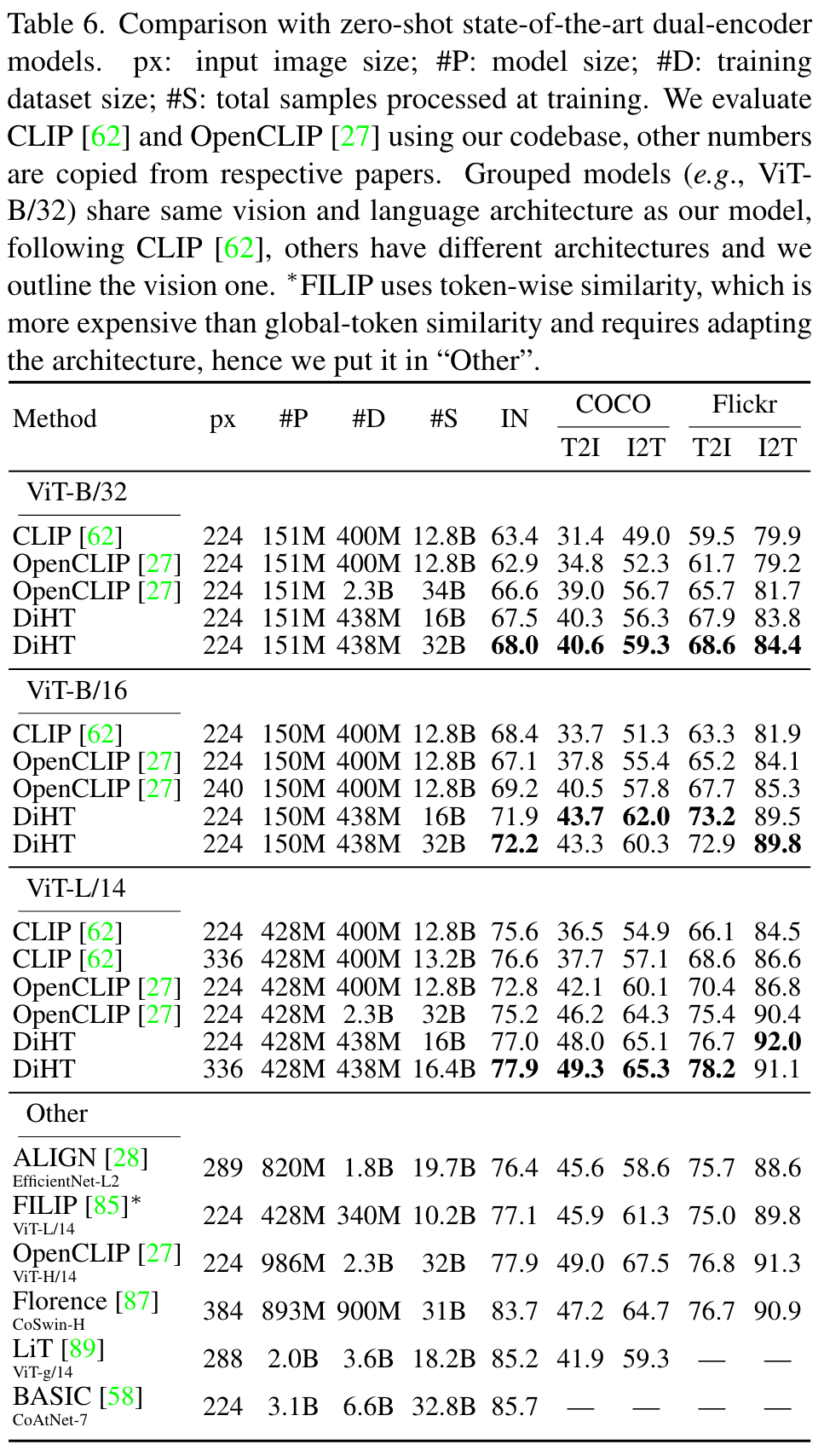
Few-shot linear probing
We present an alternate approach to do few-shot classification with prompt-based initialization. The key idea of our approach is to initialize the classifier with the zero-shot text prompts for each class, but to also ensure that the final weights do not drift much from the prompt using projected gradient descent (PGD) [5]. (p. 7)
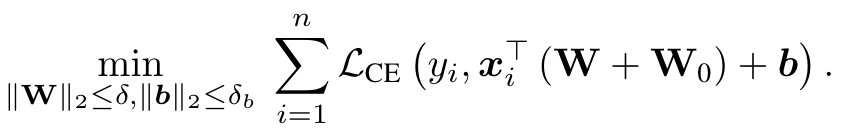
Here W_0 ∈ R_{d×nc} denotes the prompt initialization from the text encoder. (p. 8)
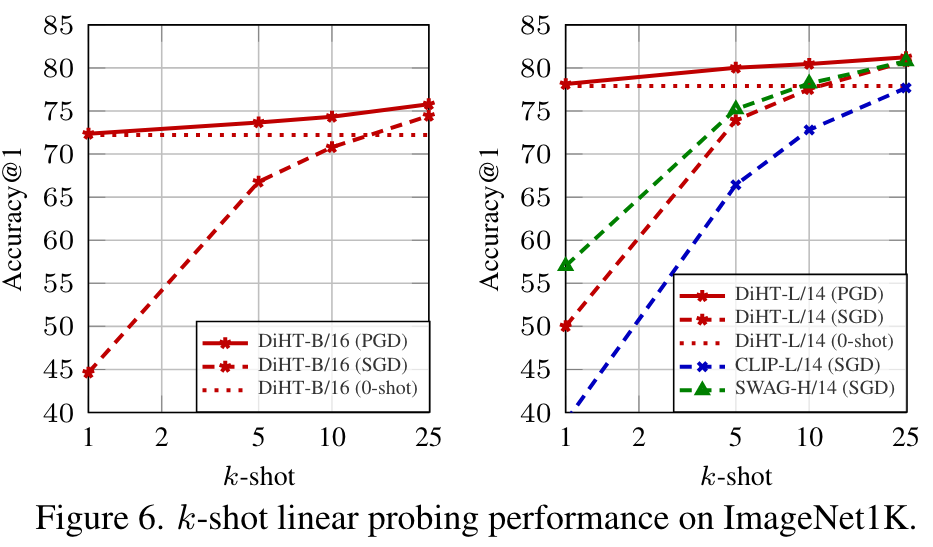
Ablation
Effect of dataset filtering
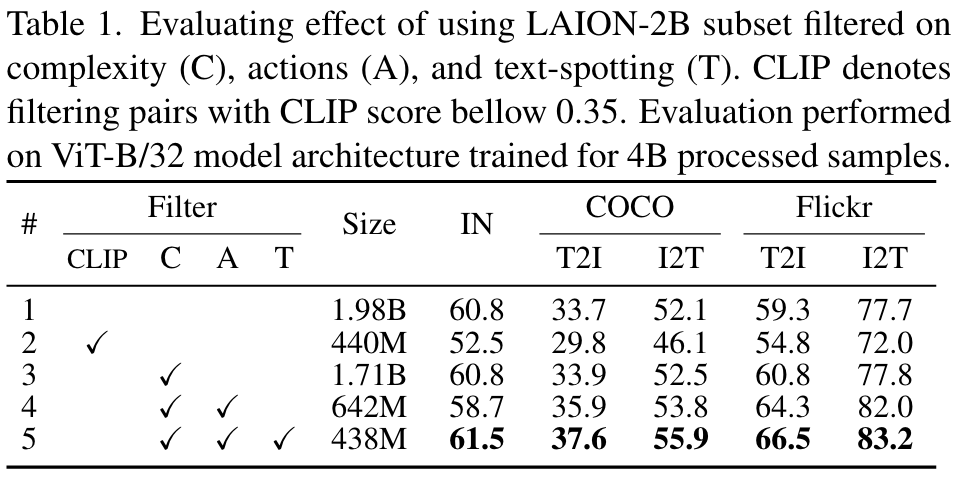
We apply our filters, as well as filtering based on CLIP [62] alignment score (<0.35), and ablate the baseline performance, without distillation or hard negative contrastive training, in Table 1 for ViT-B/32 model architecture. (p. 5)
We also compare with filtering based on CLIP score in row (2), which was selected such that the dataset size is comparable to ours, and show that it is too strict and removes plenty of useful training pairs, thus hurting the performance. (p. 5)
We ran small scale experiments with several complexity filters (see Table A.3) and we found that CAT with minimum complexity C1 performed the best. (p. 13)
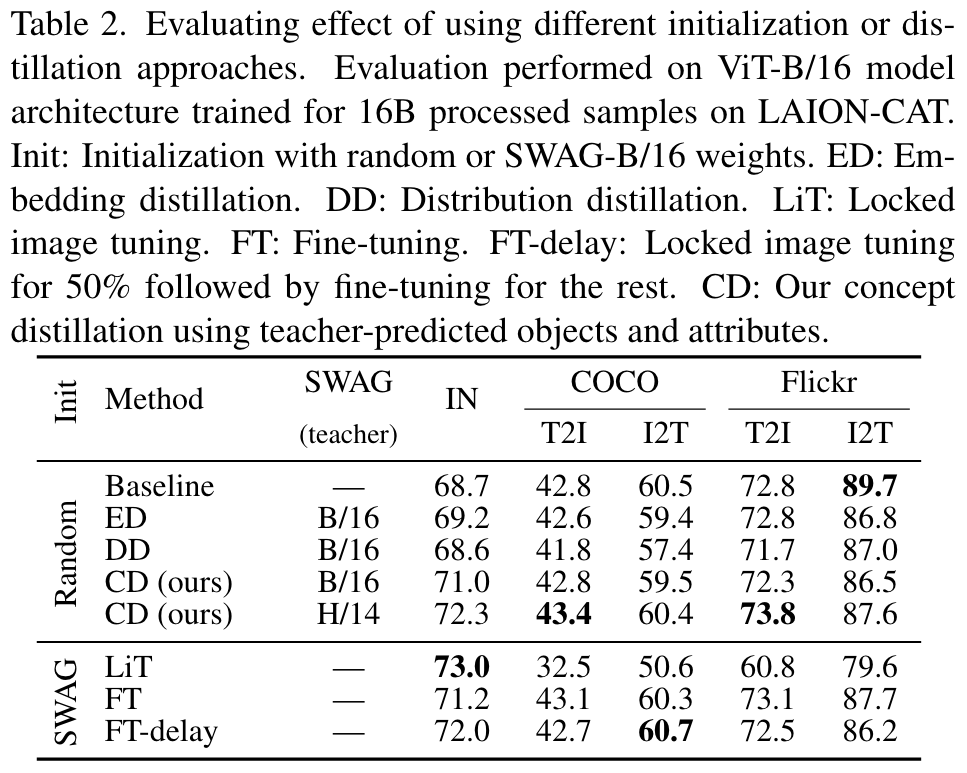
Effect of distillation approach
We follow [89] and explore three finetuning options as baselines: (i) locked-image tuning (LiT) where the image encoder is locked, and only the text encoder is trained, (ii) fine-tuning (FT) where the image encoder is trained with a learning rate scaled by 0.01 compared to the text encoder, (iii) fine-tuning with delay (FTdelay) where the image encoder is locked for half of the pre-training epochs following (i), and then fine-tuned for the rest following (ii). Results of these setups are ablated in Table 2 (lower section). LiT vs. FT is a trade-off between strong performance on image recognition tasks (as measured with ImageNet1K) and better image-text alignment (as measured by COCO and Flickr). Locking the image encoder makes the alignment very hard to achieve, but fine-tuning it hurts its original image recognition power. (p. 6)
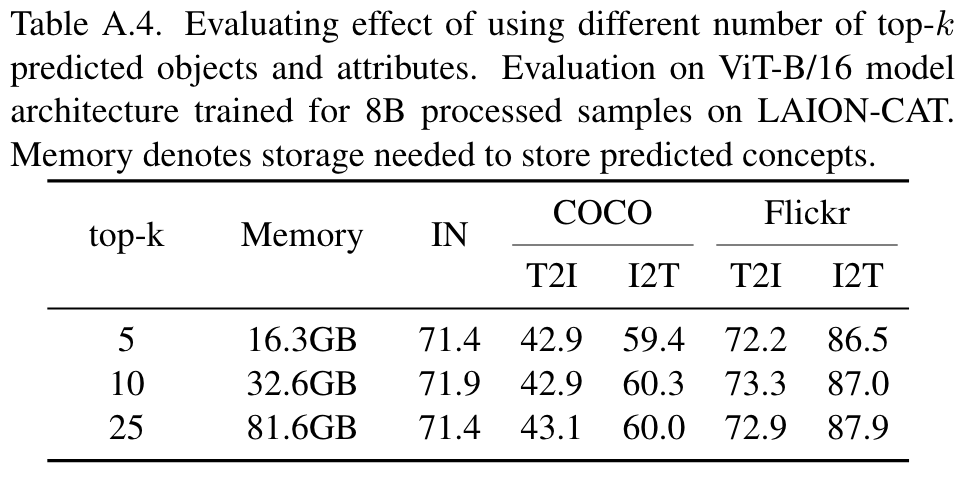
In Table A.4, we show that our concept distillation approach is quite robust to the choice of the number of predicted objects and attributes. For k = 10 strong accuracy is achieved with a small increase in dataset memory. (p. 13)
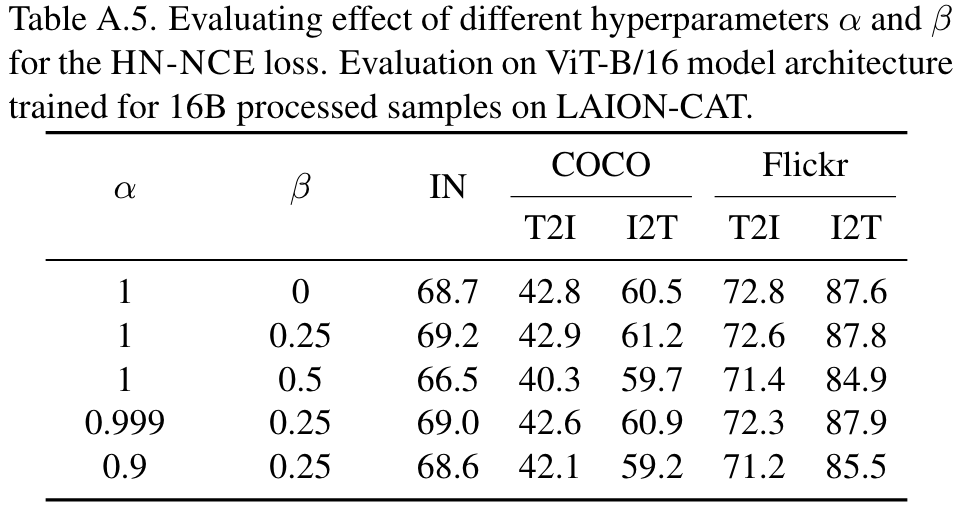
Effect of hard negative contrastive training
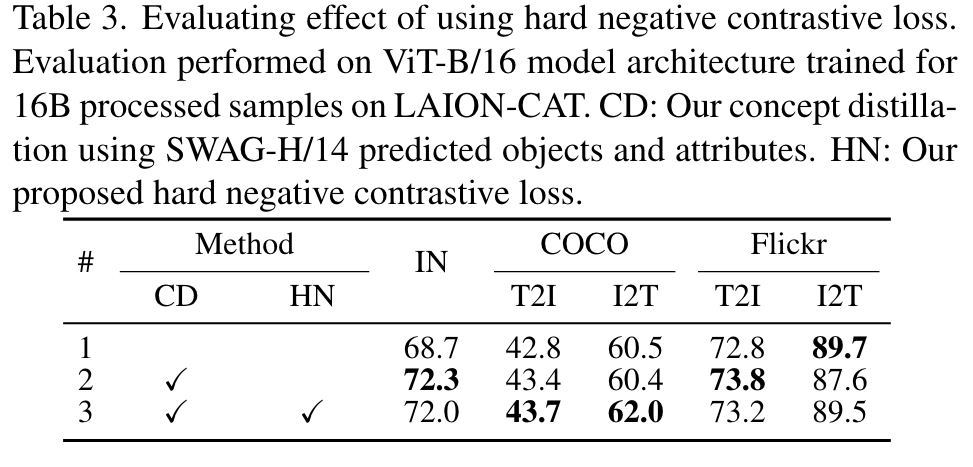
Effect when pre-training on PMD
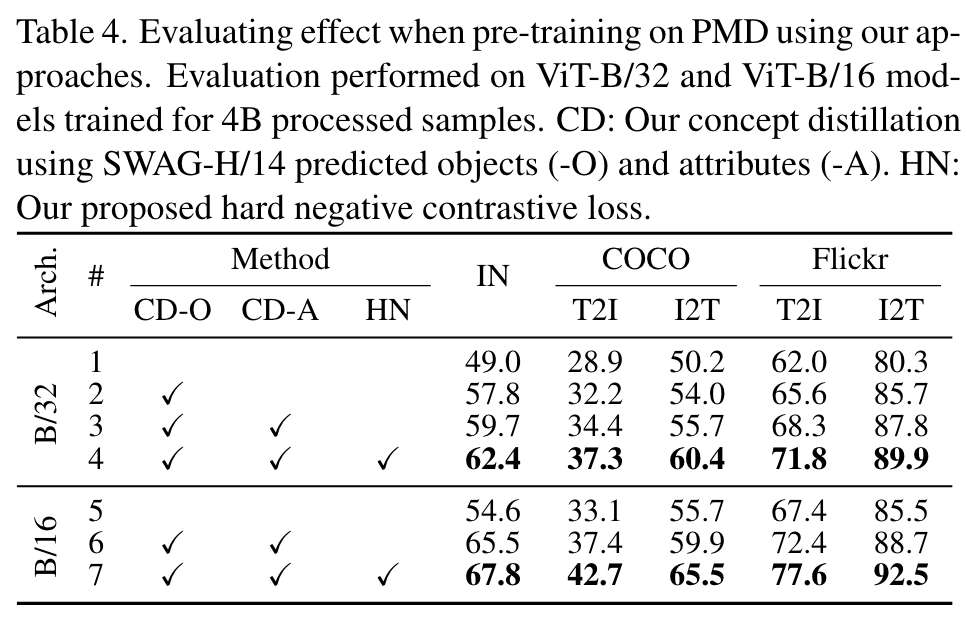
Concept distillation
The teacher model is built by training linear classifiers which predict objects and attributes - on top of a frozen SWAG [71] backbone. SWAG is trained in a weakly supervised manner by predicting hashtags from Instagram images (p. 12)