DreamBooth Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
[dalle-2 imagen diffusion personalize deep-learning dreambooth image2image This is my reading note on DreamBooth. Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images.
Introduction

Given as input just a few images of a subject, we fine-tune a pretrained text-toimage model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. (p. 1)
Recently developed large text-to-image models achieve a remarkable leap in the evolution of AI, by enabling high-quality and diverse synthesis of images based on a text prompt written in natural language [56, 51]. One of the main advantages of such models is the strong semantic prior learned from a large collection of image-caption pairs. (p. 2)
While the synthesis capabilities of these models are unprecedented, they lack the ability to mimic the appearance of subjects in a given reference set, and synthesize novel renditions of those same subjects in different contexts. The main reason is that the expressiveness of their output domain is limited; even the most detailed textual description of an object may yield instances with different appearances. Furthermore, even models whose text embedding lies in a shared language-vision space [49] cannot accurately reconstruct the appearance of given subjects but only create variations of the image content (Figure 2). (p. 2)

Related Work
For example, image composition techniques [64, 13, 38] aim to clone a given subject into a new background such that the subject melds seamlessly into the scene. However, these techniques are quite limited in their ability to adapt the correct lighting from the background, cast proper shadows, or fit the background content in a semantically aware manner. The challenge is even greater when the requirement is to synthesize the subject in novel articulations and views that were not seen in the few given images of the subject. (p. 3)
Text-driven image manipulation has recently achieved significant progress using GANs [22, 9, 29–31], which are known for their high-quality generation, in parallel with the advent of CLIP [49], which consists of a semantically rich joint image-text representations. (p. 3)
- Bau et al. [7] further demonstrated how to use masks provided by the user, to localize the text-based editing and restrict the change to a specific spatial region. However, while GAN-based image editing approaches succeed on highly-curated datasets [42], e.g., human faces, they struggle over diverse datasets with many subject types.
- To obtain more expressive generation capabilities, Crowson et al. [14] use VQ-GAN [18], trained over diverse data, as a backbone.
-
Other works [4, 32] exploit the recent Diffusion models [25, 58, 60, 25, 59, 54, 44, 61, 55, 57], which achieve state-of-the-art generation quality over highly diverse datasets, often surpassing GANs [15].
1. Kim et al. [32] show how to perform global changes, whereas Avrahami et al. [4] successfully perform local manipulations using user-provided masks for guidance. 2. While most works that require only text (i.e., no masks) are limited to global editing [14, 34], Bar-Tal et al. [5] proposed a text-based localized editing technique without using masks, showing impressive results. While most of these editing approaches allow modification of global properties or local editing of a given image, none of them enables generating novel renditions of a given subject in new contexts. [(p. 3)](zotero://open-pdf/library/items/VJJH4UP6?page=3&annotation=VMH8KTN6)
Recent large text-to-image models such as Imagen [56], DALL-E2 [51], Parti [66], and CogView2 [17] demonstrated unprecedented semantic generation. These models do not provide fine-grained control over a generated image and use text (p. 3) guidance only. Specifically, given text descriptions, it is hard or impossible to preserve the identity of a subject consistently across different images, since modifying the context in the prompt also modifies the appearance of the subject. (p. 4)
- Liu et al. [39] propose a modification to classifier guidance that allows for guidance of diffusion models using images and text, allowing for semantic variations of an image, although the identity of the subject often varies.
- To overcome subject modification, several works [43, 3] assume that the user provides a mask to restrict the area in which the changes are applied.
- Recent work of prompt-toprompt [23] allows for local and global editing without any input mask requirements, but does not address the problem of synthesizing a given subject in novel contexts. (p. 4)
Inversion of diffusion models Inversion of diffusion models, the problem of finding a noise map and a conditioning vector that correspond to a generated image, is a challenging task and a possible avenue of tackling subject-driven novel image generation. Due to the asymmetry between the backward and forward diffusion steps, a naive addition of noise to an image followed by denoising, may yield a completely different image.
- Choi et al. [12] tackle inversion by conditioning the denoising process on noised low-pass filter data from the target image.
- Dhariwal et al. [15] show that deterministic DDIM sampling [59] can be inverted to extract a latent noise map that will produce a given real image.
- Ramesh et al. [51] use this method to generate cross-image interpolations or semantic image editing using CLIP latent vectors. These methods fall short of generating novel samples of a subject while preserving fidelity.
- The concurrent work of Gal et al. [20]proposes a textual inversion method that learns to represent visual concepts, like an object or a style, through new pseudo-words in the embedding space of a frozen text-to-image model. Their approach searches for the optimal embedding that can represent the concept, hence, is limited by the expressiveness of the textual modality and constrained to the original output domain of the model. In contrast, we fine-tune the model in order to embed the subject within the output domain of the model, enabling the generation of novel images of the subject while preserving key visual features that form its identity. (p. 4)
Casanova et al. [10] propose a method to condition GANs on instances, such that variations of an instance can be generated. Generated subjects share features with the conditioning instance, but are not identical and thus cannot solve the problem tackled in our work. Nitzan et al. [45] propose MyStyle to finetune a face synthesis GAN on a specific identity, in order to build a personalized prior. While MyStyle requires around 100 images to learn an adequate prior and it is constrained to the face domain, our approach can reconstruct the identity of different types of subjects (objects, animals, etc.) in new contexts with only 3-5 casually captured images. (p. 4)
Proposed Method
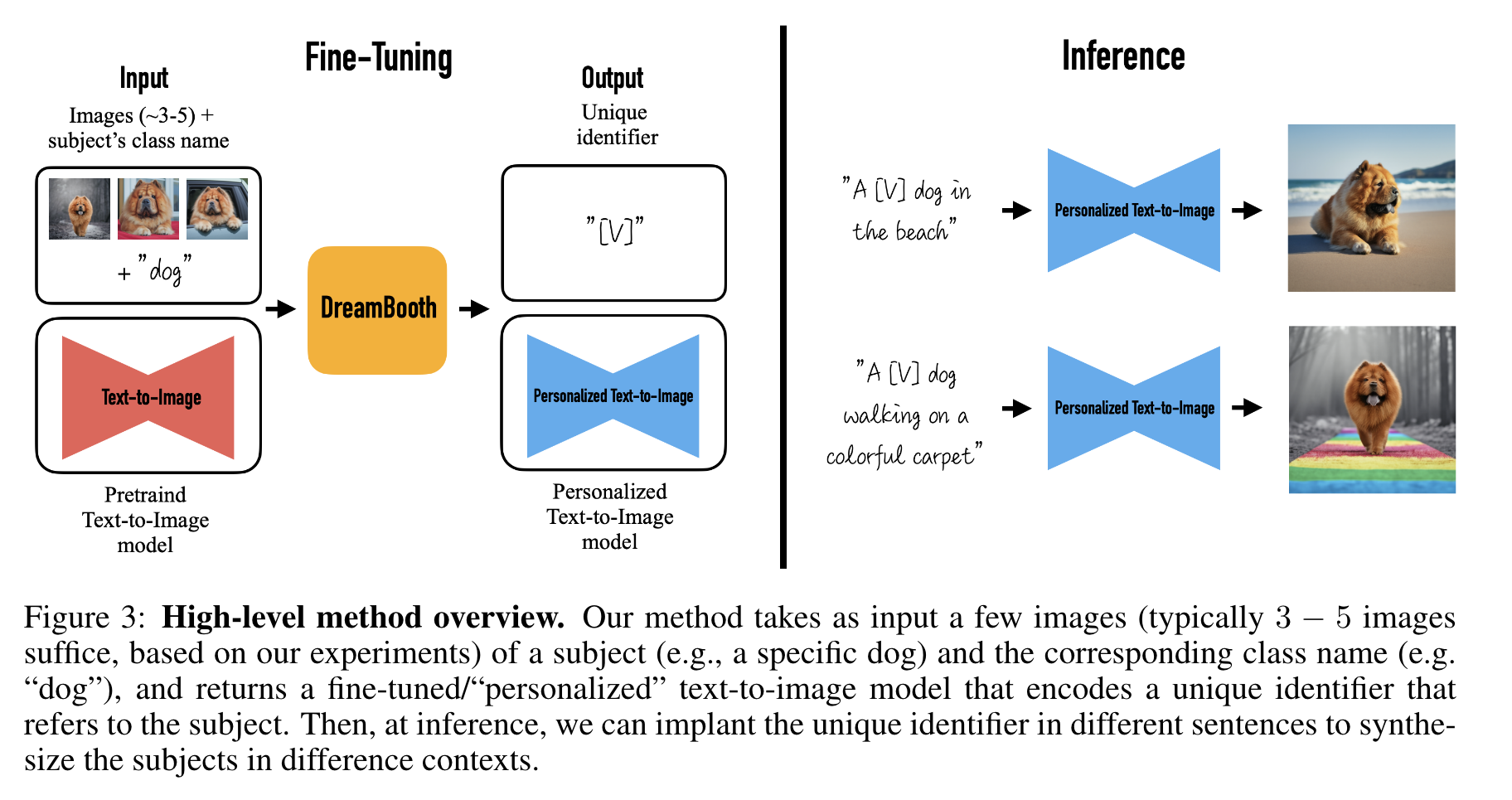
Given only a few (3-5) casually captured images of a specific subject, without any textual description, our objective is to generate new images of the subject with high detail fidelity and with variations guided by text prompts. (p. 5)
In order to accomplish this, our first task is to implant the subject instance into the output domain of themodel and to bind the subject with a unique identifier. We present our method to design the identifier below as well as a new approach to supervise a fine-tuning process of the model such that it re-uses its prior for our subject instance. A key problem is that fine-tuning on a small set of images showing our subject is prone to overfitting on the given images. In addition, language drift [35, 40] is a common problem in language models, and manifests itself in text-to-image diffusion models as well: the model can forget how to generate other subjects of the same class, and lose the embedded knowledge on the diversity and natural variations of instances belonging to that class. For this, we present an autogenous class-specific prior preservation loss, where we alleviate overfitting and prevent language drift by encouraging the diffusion model to keep generating diverse instances of the same class as our subject. (p. 5)
To enhance the details preservation, we find that the super-resolution components of the model should also be fine-tuned. However, if they are fine-tuned to generate our subject instance in a naive manner they are not able to replicate important details of the instance. (p. 5)
Representing the Subject with a Rare-token Identifier
Designing Prompts for Few-Shot Personalization Our goal is to “implant” a new (key, value) pair into the diffusion model’s “dictionary” such that, given the key for our subject, we are able to generate fully-novel images of this specific subject with meaningful semantic modifications guided by a text prompt. (p. 6)

We opt for a simpler approach and label all input images of the subject “a [identifier] [class noun]”, where [identifier] is a unique identifier linked to the subject and [class noun] is a coarse class descriptor of the subject (e.g. cat, dog, watch, etc.). The class descriptor can be obtained using a classifier. We specifically use a class descriptor in the sentence in order to tether the prior of the class to our unique subject. We found that using only a unique identifier, without a class noun, as a key for our subject increased training time and decreased performance. In essence, we want to leverage the diffusion model’s prior of the specific class and entangle it with the embedding of our subject’s unique identifier. (p. 6)
A naive way of constructing an identifier for our subject is to use an existing word. For example, using the words like “unique” or “special”. One problem is that existing English words tend to have a stronger prior due to occurrence in the training set of text-to-image diffusion models. We generally find increased training time and decreased performance when using such generic words to index our subject, since the model has to both learn to disentangle them from their original meaning and to re-entangle them to reference our subject. This approach can also fail by entangling the meaning of the word with the appearance of our object, for example in the extreme case if the identifier chosen is the adjective “blue” and our subject is grey, colors will be entangled at inference and we will sample a mix of grey and blue subjects (as well as mixes of both). This (p. 6) motivates the need for an identifier that has a weak prior in both the language model and the diffusion model. A hazardous way of doing this is to select random characters in the English language and concatenate them to generate a rare identifier (e.g. “xxy5syt00”). In reality, the tokenizer might tokenize each letter separately, and the prior for the diffusion model is strong for these letters. Specifically, if we sample the model with such an identifier before fine-tuning we will get pictorial depictions of the letters or concepts that are linked to those letters. We often find that these tokens incur the same weaknesses as using common English words to index the subject. (p. 7)
Rare-token Identifiers In a nutshell, our approach is to find relatively rare tokens in the vocabulary, andthen invert these rare tokens into text space. In order to do this, we first perform a rare-token lookup in thevocabulary and obtain a sequence of rare token identifiers f (Vˆ ), where f is a tokenizer; a function that maps character sequences to tokens and Vˆ is the decoded text stemming from the tokens f (Vˆ ). This sequence canbe of variable length k with k being a hyperparameter of our method. We find that relatively short sequencesof k = {1, …, 3} work well. Then, by inverting the vocabulary using the de-tokenizer on f (Vˆ ) we obtain a sequence of characters that define our unique identifier Vˆ . We observe that using uniform random samplingwithout replacement of tokens that correspond to 3 or fewer Unicode characters (without spaces) and usingtokens in the T5-XXL tokenizer range of {5000, …, 10000} works well. (p. 7)
Class-specific Prior Preservation Loss
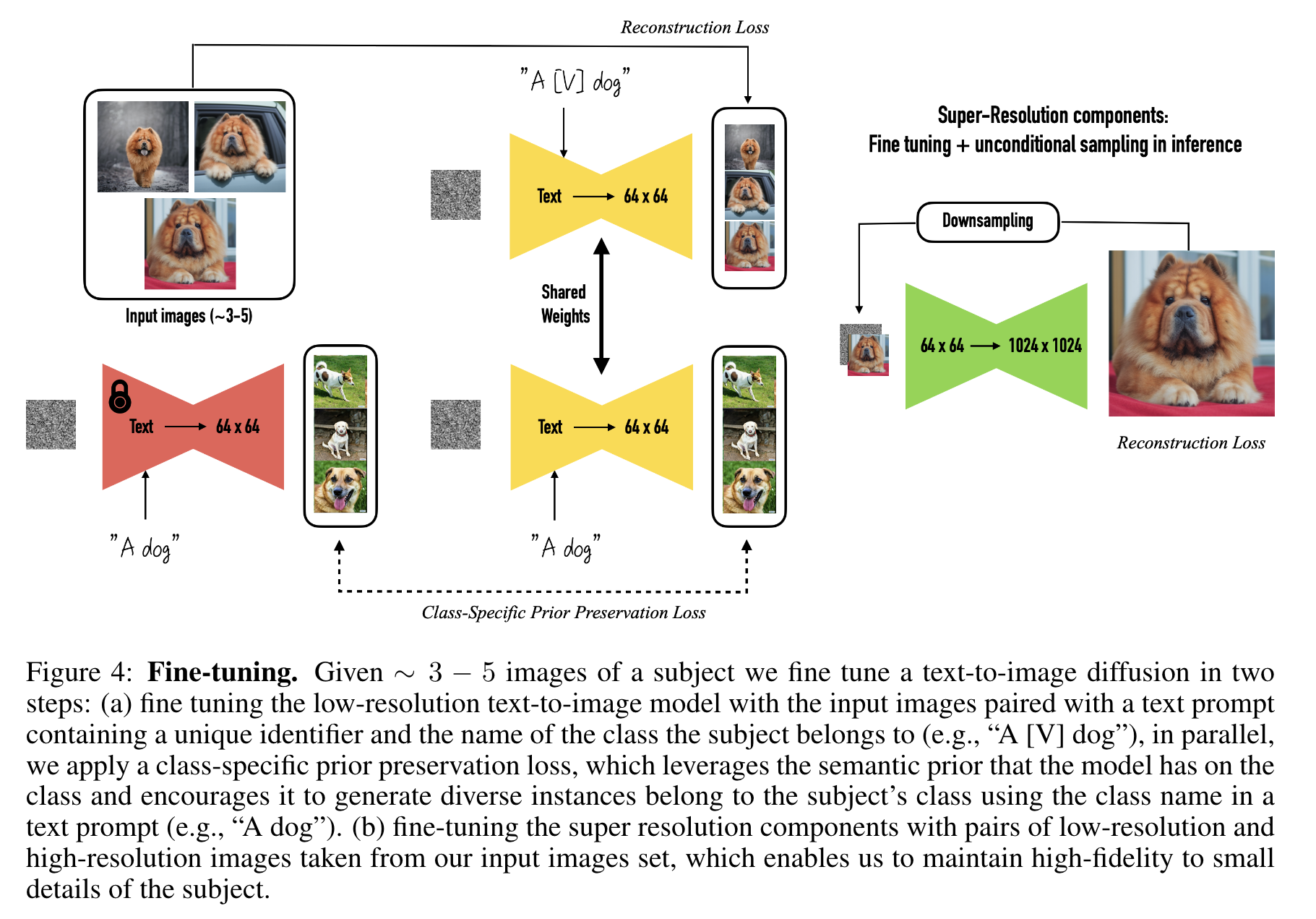
Few-shot Personalization of a Diffusion Model Given a small set of images depicting the target subject $X_s := {x^i_s; i \in {0, \dots, N }}$, and with the same conditioning vector cs obtained from the text prompt “a[identifier] [class noun]”, we fine-tune the text-to-image model using the classic denoising loss presented in Equation 1, with the same hyperparameters as the original diffusion model. Two key issues arise with such a naive fine-tuning strategy: Overfitting and Language-drift. (p. 7)
Issue-1: Overfitting Since our input image set is quite small, fine-tuning the large image generation modelscan overfit to both the context and the appearance of the subject in the given input images (e.g., subject pose). (p. 7). In our experience, the best results that achieve maximum subject fidelity are achieved by fine-tuning all layers of the model. Nevertheless, this includes fine-tuning layers that are conditioned on the text embeddings, which gives rise to the problem of language drift. (p. 7)
Issue-2: Language Drift The phenomenon of language drift has been an observed problem in the languagemodel literature [35, 40], where a language model that is pre-trained on a large text corpus and later finetuned for a specific task progressively loses syntactic and semantic knowledge of the language as it learns to improve in the target task. (p. 7). Since our text prompt contains both the [identifier] and [class noun], when a diffusion model is fine-tuned on a small set of subject images, we observe that it slowly forgets how to generate subjects of the same class and progressively forgets the class-specific prior and can not generate different instances of the class in question. (p. 7)
Prior-Preservation Loss We propose an autogenous class-specific prior-preserving loss to counter both theoverfitting and language drift issues. In essence, our method is to supervise the model with its own generated samples, in order for it to retain the prior once the few-shot fine-tuning begins. Specifically, we generate data $x_{pr} = \hat{x}(z_{t1} , c_{pr})$ by using the ancestral sampler on the frozen pre-trained diffusion model with random initial noise $z_{t1} \sim N (0, I)$ and conditioning vector cpr := Γ(f (”a [class noun]”)). (p. 7)


Personalized Instance-Specific Super-Resolution
We find that if SR networks are used without fine-tuning, the generated output can contain artifacts since the SR models might not be familiar with certain details or textures of the subject instance, or the subject instance might have hallucinated incorrect features, or missing details. (p. 8)
We find that fine-tuning the 64×64 → 256×256 SR model is essential for most subjects, and fine-tuning the 256×256 → 1024 × 1024 model can benefit some subject instances with high levels of fine-grained detail. (p. 8)

Experiment Results



Limitation
Our method has several limitations, which we demonstrate in Figure 17, grouped into three main failure modes.
- The first is related to not being able to accurately generate the prompted context. For example, in Figure 17 we observe that when we prompt the model with “a [V] backpack in the ISS” and “a [V] backpack on the moon” it is not able to generate the desired contexts. Possible reasons are that the generative (p. 15) model does not have a strong prior for these contexts, or that representing both the subject and the context together is a difficult task for the model.
- The second failure mode is context-appearance entanglement, where the appearance of the subject changes due to the prompted context. In Figure 17 we show examples of a backpack that changes colors due to the desired context being rare (“a [V] backpack in the Bolivian Salt Flats”) or entangling the color of the context with that of the subject (“a [V] backpack on top of blue fabric”).
- Third, we also observe overfitting to the real images that happens when the prompt is similar to the original setting in which the subject was seen. (p. 16) %% end annotations %%

%% Import Date: 2023-09-02T11:30:53.398-07:00 %%