Florence-2 Advancing a Unified Representation for a Variety of Vision Tasks
[object-detection transformer multimodal deep-learning dataset florence seq2seq git coca flamingo This is my reading note for Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. This paper proposes to unify different vision tasks by formulating them as visual grounded text generation problem where vision task is specified as input text prompt. To this end, it annotates a large image dataset with different annotations.
Introduction
We introduce Florence-2, a novel vision foundation model with a unified, prompt-based representation for a variety of computer vision and vision-language tasks. (p. 1)
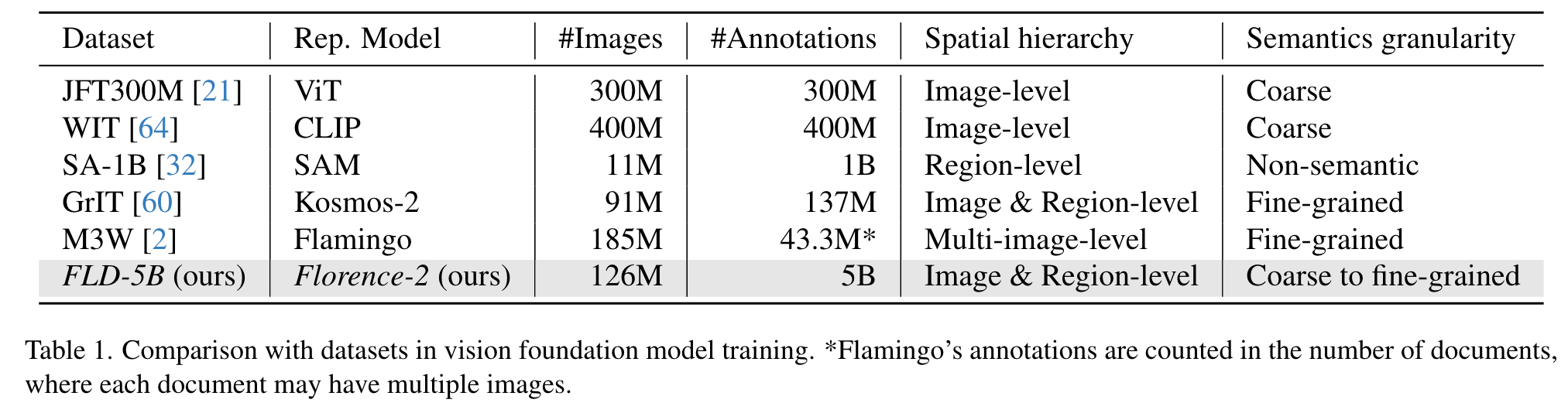
Our data engine, instead of relying on labor-intensive manual annotation, autonomously generates a comprehensive visual dataset called FLD-5B, encompassing a total of 5.4B annotations for 126M images. This engine consists of two efficient processing modules. The first module uses specialized models to collaboratively and autonomously annotate images, moving away from the traditional single and manual annotation approach. Multiple models work together to reach a consensus, reminiscent of the wisdom of crowds concept [33, 80, 89], ensuring a more reliable and unbiased image understanding. The second module iteratively refines and filters these automated annotations using well-trained foundational models. (p. 2)
our model employs a sequence-to-sequence (seq2seq) architecture [17,19,66,76], which integrates an image encoder and a multi-modality encoder-decoder. (p. 2)
All annotations in the dataset FLD-5B, are uniformly standardized into textual outputs, facilitating a unified multi-task learning approach with consistent optimization with the same loss function as the objective. The outcome is a versatile vision foundation model, Florence-2, capable of performing a variety of tasks, such as object detection, captioning, and grounding, all within a single model governed by a uniform set of parameters. Task activation is achieved through textual prompts, reflecting the approach used by Large Language Models (LLMs) [65]. (p. 2)
Related Work
Techniques for fusing vision and language embeddings vary:
- GIT [78] concatenates vision and text tokens as decoder input and designs a casual attention mask,
- CoCa [92] uses attentional poolers with learnable queries to select task-specific vision representations which are then cross-attended via the decoder,
- and Flamingo [2] pools a fixed number of vision tokens with a Perceiver Resampler and adds new learnable cross-attention layers to the decoder while freezing the pre-trained vision encoder and text decoder (p. 14)
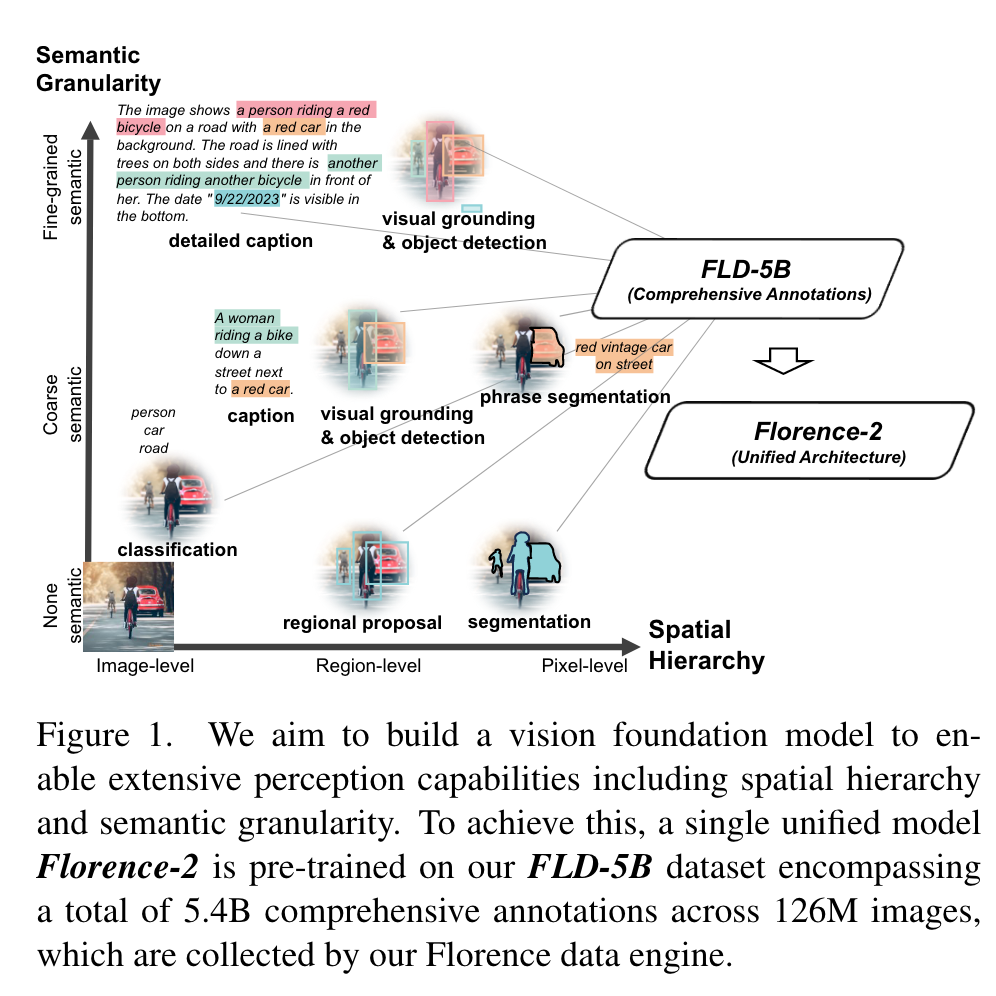
Comprehensive Multitask Learning
- Image-level understanding Exemplar tasks include image classification, captioning, and visual question answering. (p. 3)
- Region/pixel-level recognition Tasks include object detection, segmentation, and referring expression comprehension. (p. 3)
- Fine-grained visual-semantic alignment It involves locating the image regions that correspond to the text phrases, such as objects, attributes, or relations. (p. 3)
Proposed Method
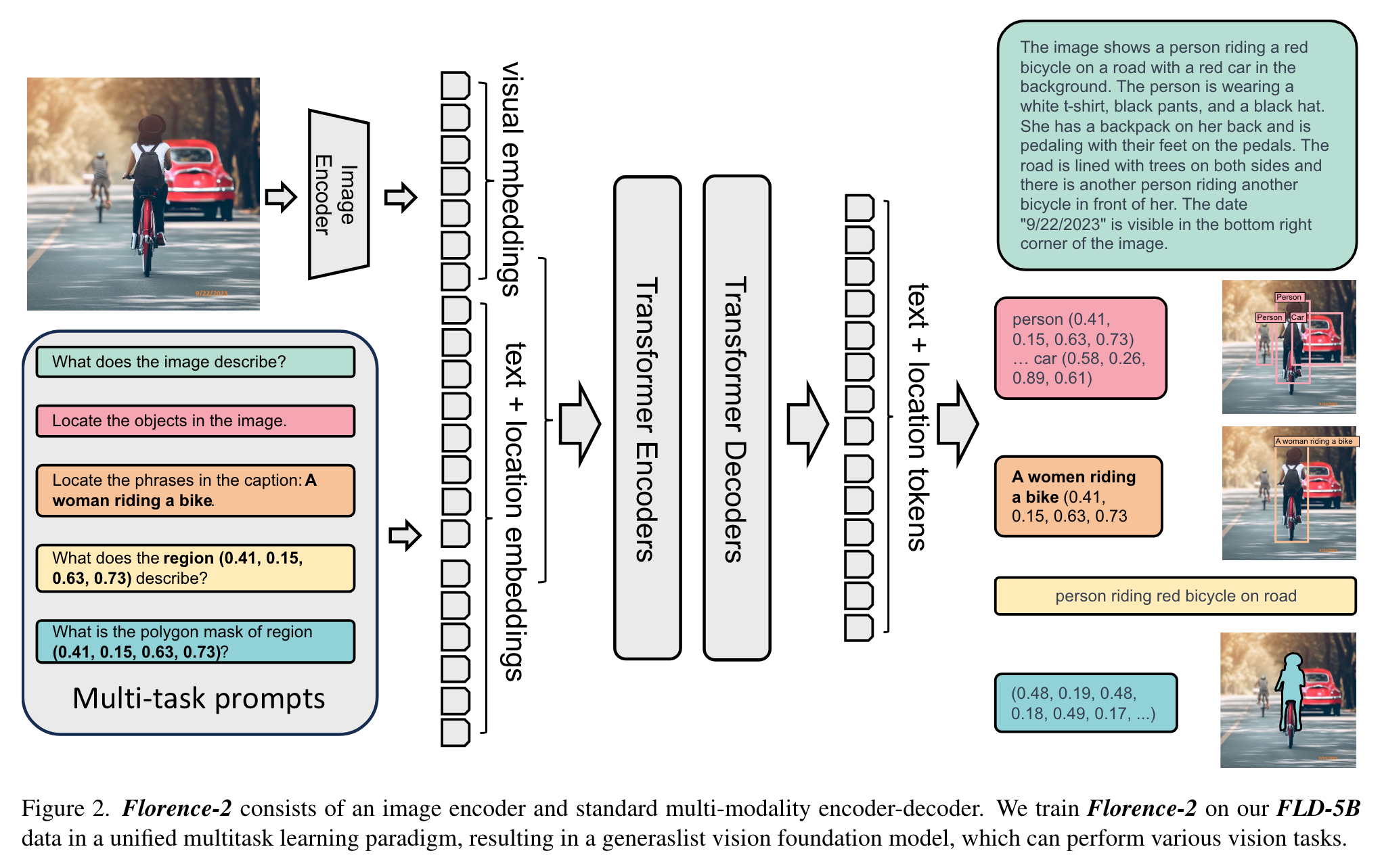
The model takes images coupled with task-prompt as task instructions, and generates the desirable results in text forms. (p. 4)
Task formulation. we formulate each task as a translation problem: Given an input image and a task-specific prompt, we generate the corresponding output response. (p. 4). For region, we create 1, 000 bins, similar to [10, 11, 55, 79], and represent regions using formats tailored to task requirements: (p. 4)
Vision encoder. We employ DaViT [20] as the vision encoder. (p. 4)
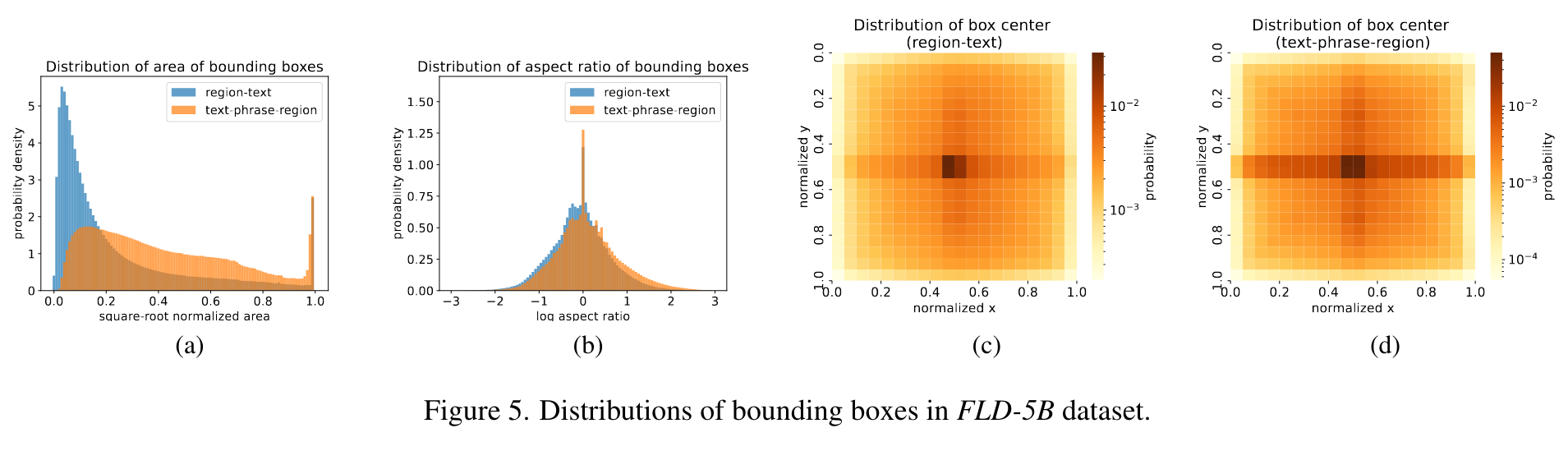
Data
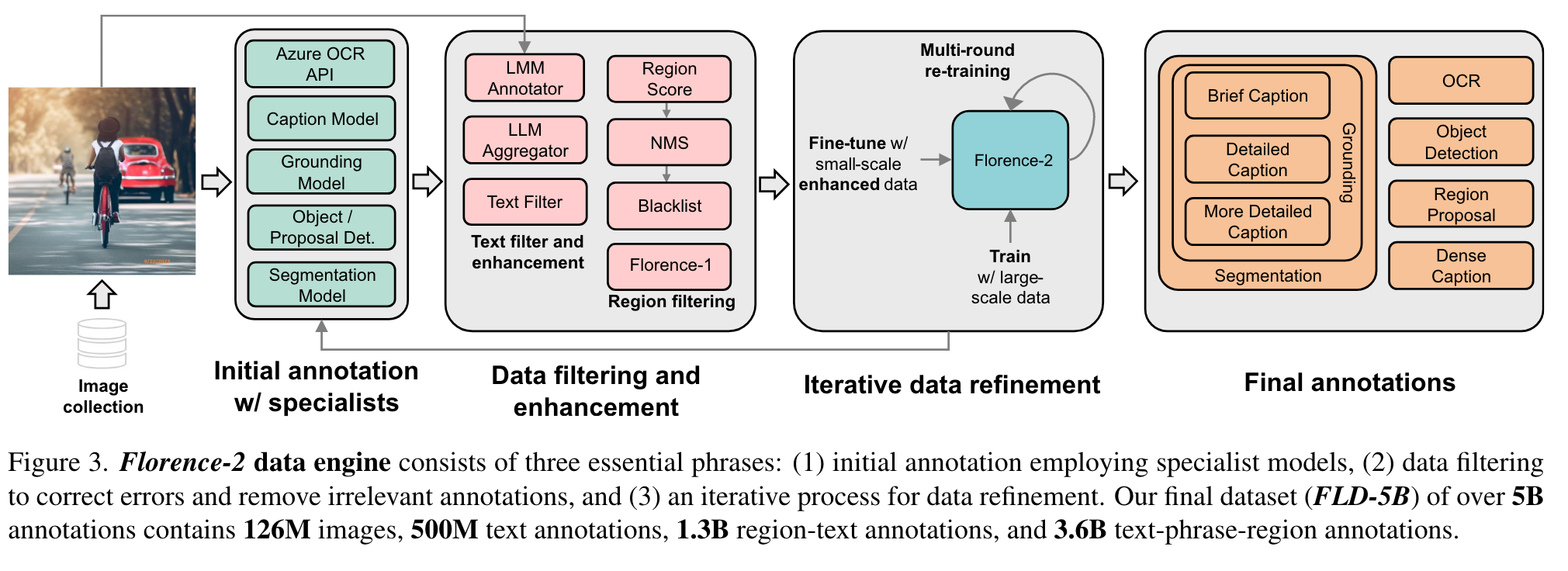
Data Annotation
Data filtering and enhancement
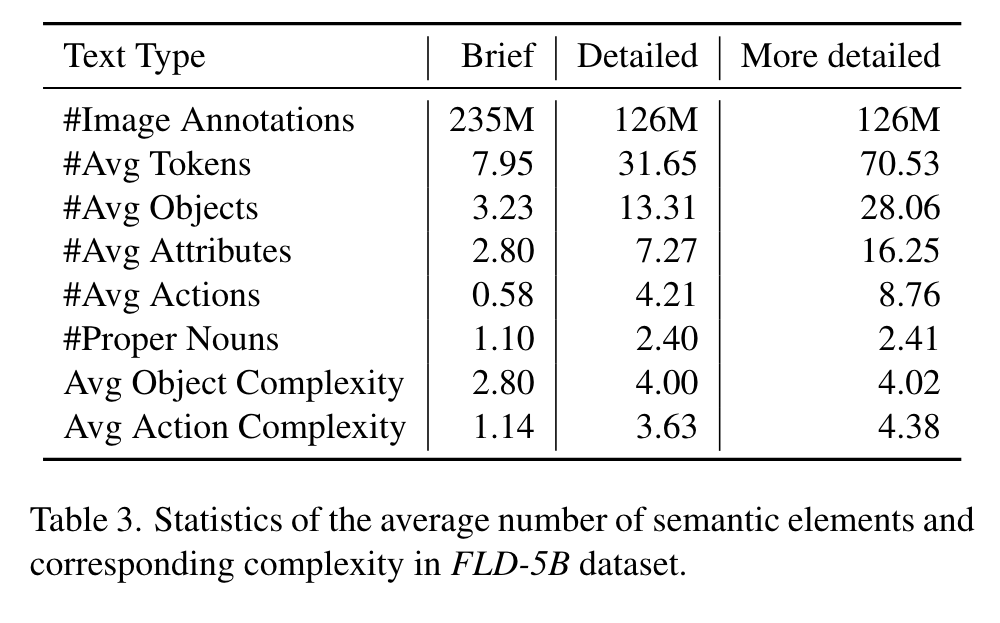
First, pertaining to textual annotations, we are inspired by DiHT [63] and develop a parsing tool based on SpaCy [28] to extract objects, attributes, and actions. We filter out texts containing excessive objects, as they tend to introduce noise and may not accurately reflect the actual content in the corresponding images. Additionally, we assess the complexity of the actions and objects by measuring their degree of node in the dependency parsing tree. We retain texts with a certain minimum action and object complexity to ensure the richness of visual concepts in the images. Second, in relation to the region annotations, specifically bounding boxes, we remove the noisy boxes under a confidence score threshold. Complementing this, we also employ non-maximum suppression to reduce redundant or overlapping bounding boxes. (p. 5)
Iterative data refinement
Using our filtered initial annotations, we trained a multitask model that processes sequences of data. Upon evaluating this model against our training images, we discerned a marked enhancement in its predictions, particularly in instances where original labels were marred by inaccuracies or extraneous noise, such as in alt-texts. (p. 5)
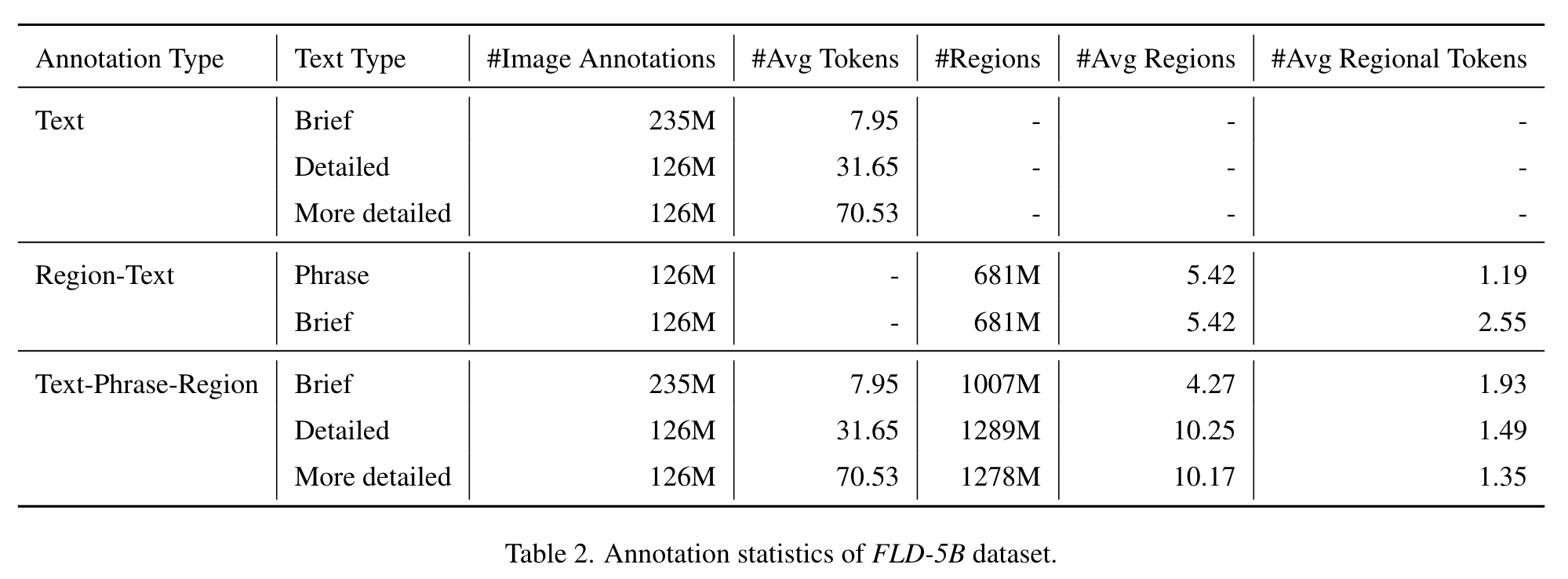
Annotation-specific Variations
Text
Text annotations categorize images using three types of granularities: brief, detailed, and more detailed. For the detailed text, prompts including existing image annotations like the brief text and region-text annotations, are fed to large language models (LLMs) or large multimodal models (LMMs) to generate comprehensive descriptions. Due to the high cost of the large models, only a small set of detailed text and more detailed text are generated. These are used to fine-tune the caption specialist, developing a detailed description specialist for further annotations. (p. 6)
Region-text pairs
Text regions are labeled using Azure AI Services’ OCR API [1], while visual objects are initially annotated with a DINO object detector [97] trained on public datasets. Textual annotations for the visual object regions are further enriched by brief text generated from an image-to-text model with cropped image regions (p. 6)
Text-phrase-region triplets
Text-phrase-region triplets consist of a descriptive text of the image, noun phrases in this text related to image objects, and region annotations for these objects. The text includes brief, detailed, and more detailed text generated earlier. For each text, the Grounding DINO model [50] identifies noun phrases and creates bounding boxes for them. Additionally, the SAM model [32] generates segmentation masks for each box, offering more precise object localization. During data filtering, a confidence score threshold is applied to both noun phrases and bounding boxes to ensure relevance. A blacklist is also used to exclude irrelevant noun phrases like pronouns and abstract concepts. (p. 6)
Experiment

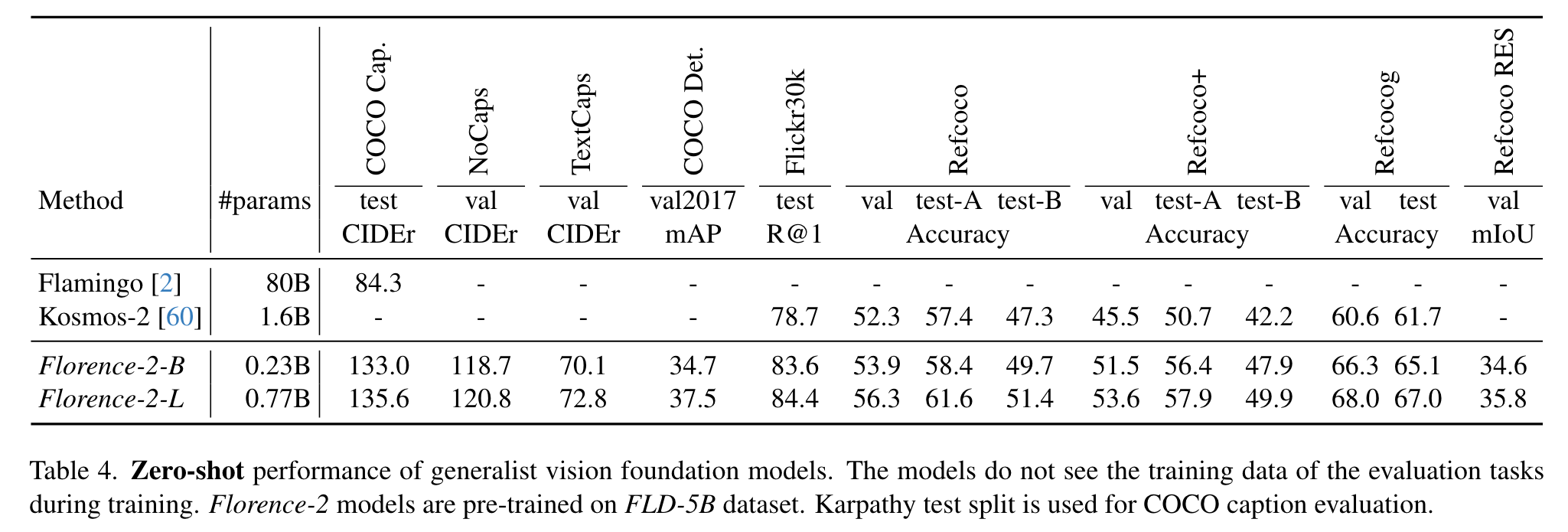
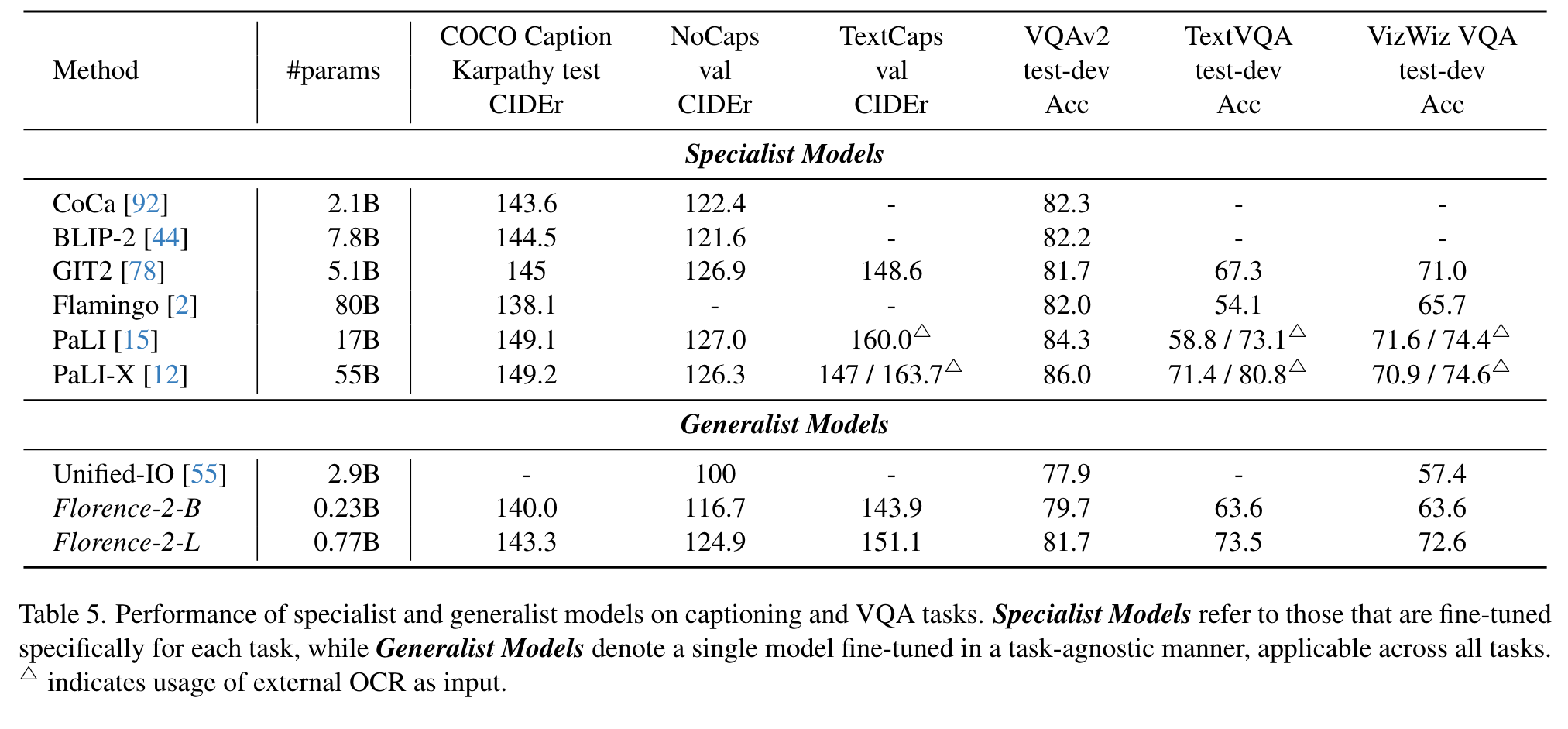
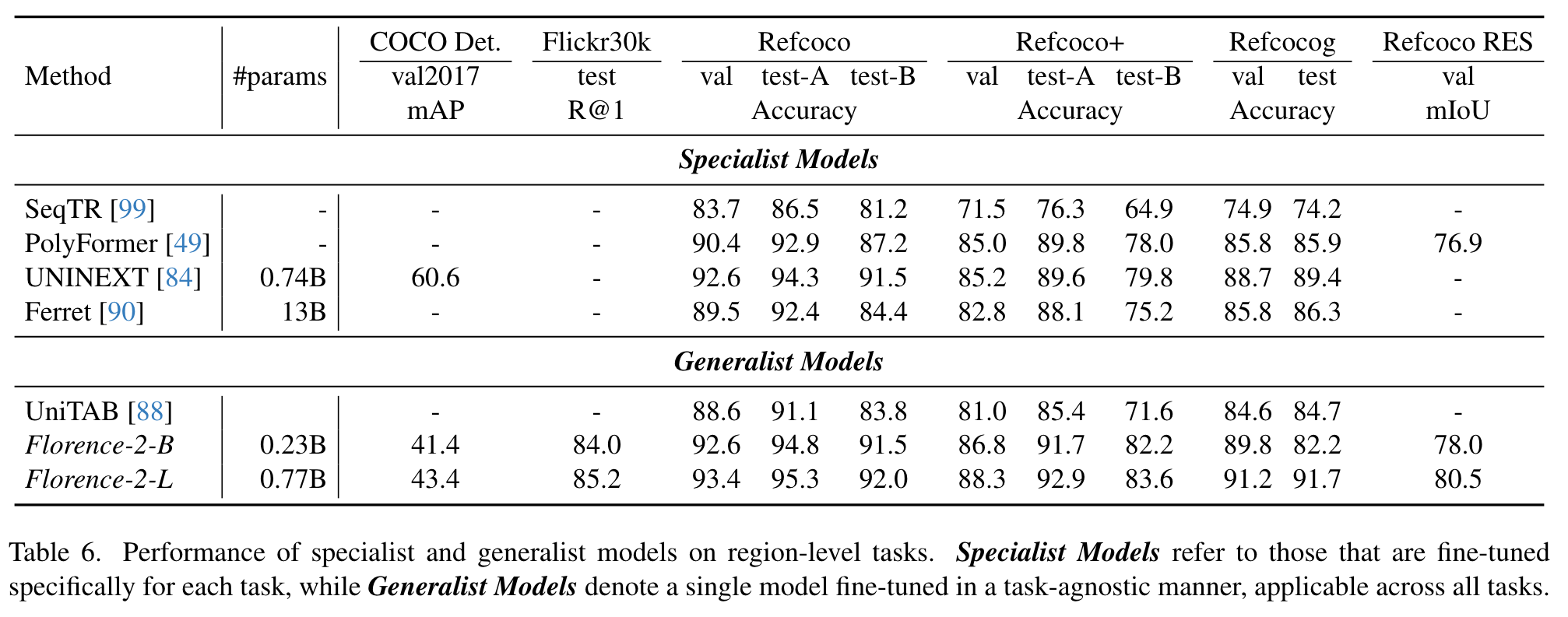
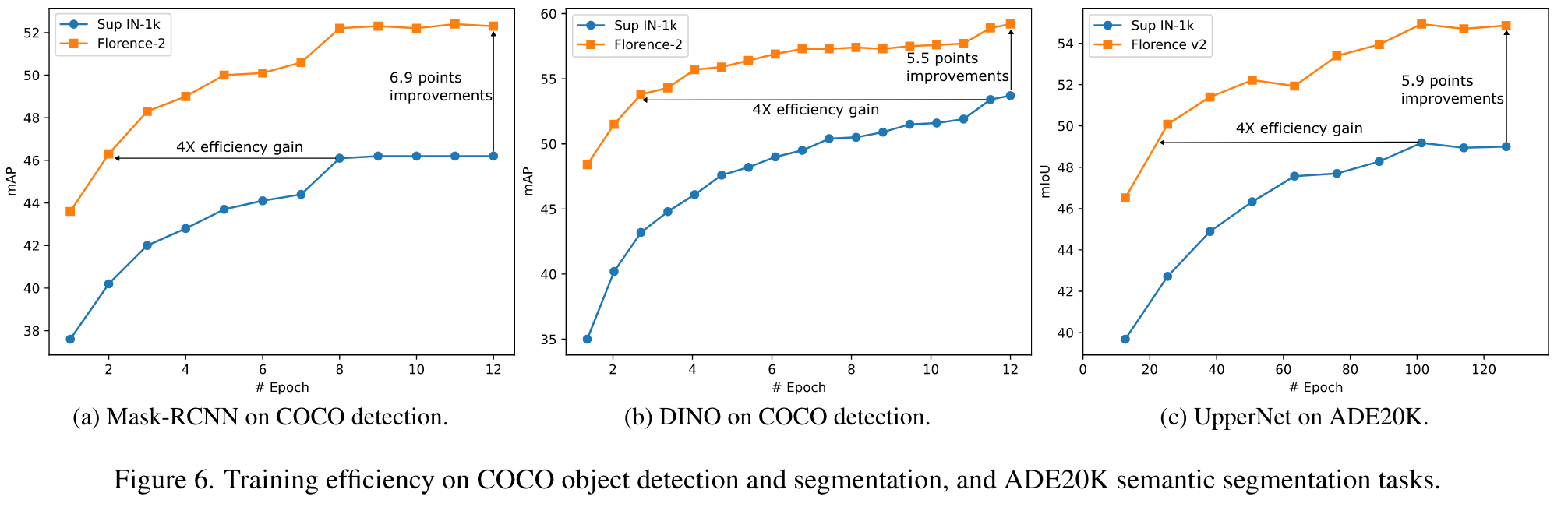
Ablation
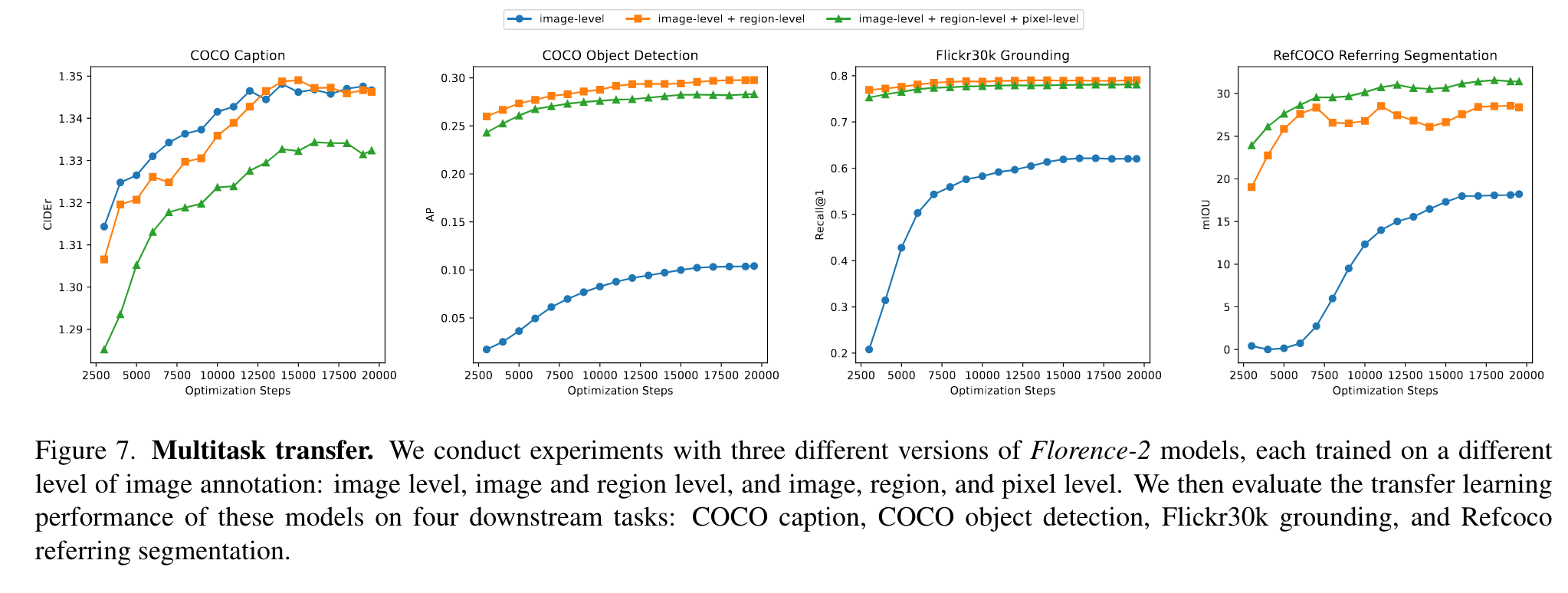
The results are shown in Figure 7. The results demonstrate that Image-Region-Pixel Model, pre-trained on all three levels of tasks, consistently demonstrated competitive performance across the four downstream tasks. (p. 12)