FreeU Free Lunch in Diffusion U-Net
[text2image diffusion deep-learning image2image This is my reading note for FreeU: Free Lunch in Diffusion U-Net. The paper analyzed the cause of artifact from diffusion model. The paper should that the backbone (U-Net) captures the global or low frequency information and skip connection capture the fine detail or high frequency information.it also shows that the high frequency information causes artifacts. As a results, this paper proposes increasing weight of half channel of U-Net and suppress the low frequency information from the skip connection

Introduction
We initially investigate the key contributions of the U-Net architecture to the denoising process and identify that its main backbone primarily contributes to denoising, whereas its skip connections mainly introduce high-frequency features into the decoder module, causing the network to overlook the backbone semantics. Capitalizing on this discovery, we propose a simple yet effective method—termed “FreeU” — that enhances generation quality without additional training or finetuning. Our key insight is to strategically re-weight the contributions sourced from the U-Net’s skip connections and backbone feature maps, to leverage the strengths of both components of the U-Net architecture. (p. 1)

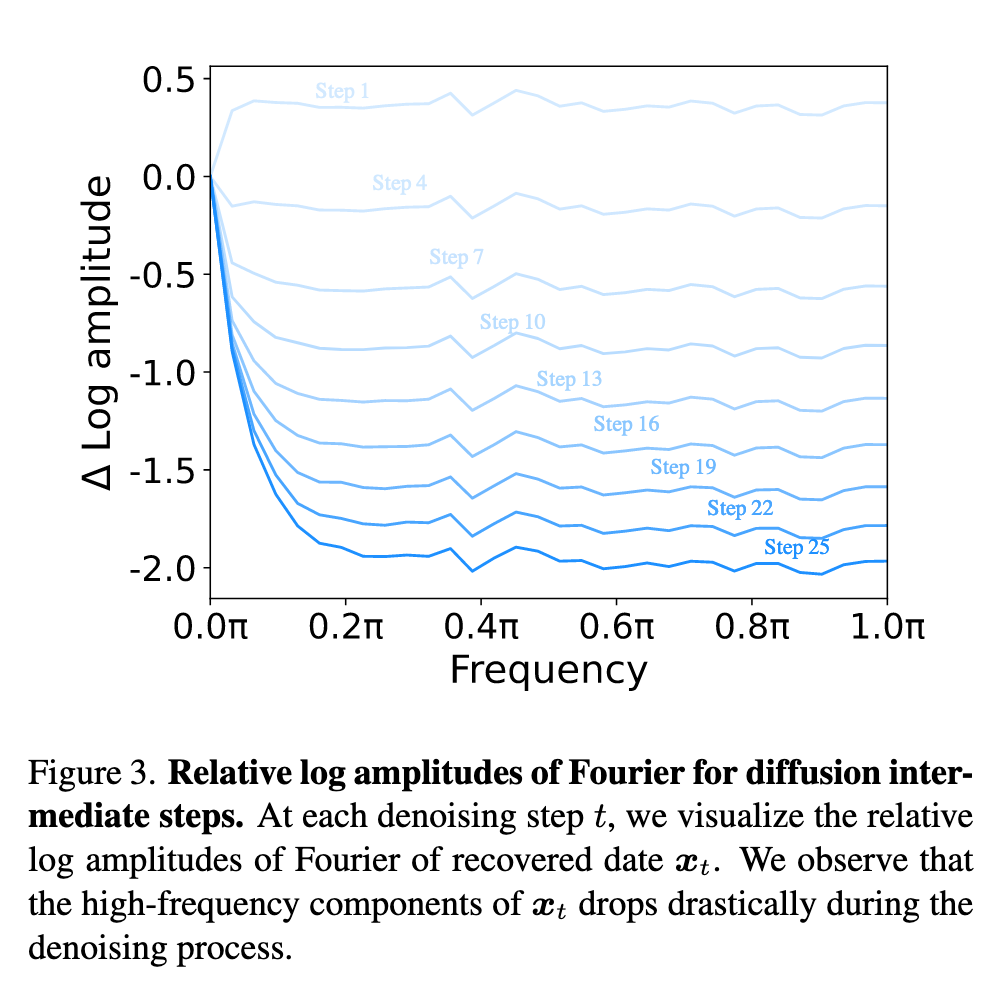
Evident from Fig. 2 is the gradual modulation of lowfrequency components, exhibiting a subdued rate of change, while their high-frequency components display more pronounced dynamics throughout the denoising process. (p. 3)
This can be intuitively explained: 1) Low-frequency components inherently embody the global structure and characteristics of an image, encompassing global layouts and smooth color. These components encapsulate the foundational global elements that constitute the image’s essence and representation. Its rapid alterations are generally unreasonable in denoising processes. Drastic changes to these components could fundamentally reshape the image’s essence, an outcome typically incompatible with the objectives of denoising processes. 2) Conversely, high-frequency components contain the rapid changes in the images, such as edges and textures. These finer details are markedly sensitive to noise, often manifesting as random high-frequency information when noise is introduced to an image. Consequently, denoising processes need to expunge noise while upholding indispensable intricate details. (p. 3)
In each stage of the U-Net decoder, the skip features from the skip connection and the backbone features are concatenated together. Our investigation reveals that the main backbone of the U-Net primarily contributes to denoising. Conversely, the skip connections are observed to introduce high-frequency features into the decoder module. These connections propagate fine-grained semantic information to make it easier to recover the input data. However, an unintended consequence of this propagation is the potential weakening of the backbone’s inherent denoising capabilities during the inference phase. This can lead to the generation of abnormal image details, as illustrated in the first row of Fig. 1. (p. 3)
During the inference stage, we instantiate two specialized modulation factors designed to balance the feature contributions from the U-Net architecture’s primary backbone and skip connections. The first, termed the backbone feature factors, aims to amplify the feature maps of the main backbone, thereby bolstering the denoising process. However, we find that while the inclusion of backbone feature scaling factors yields significant improvements, it can occasionally lead to an undesirable oversmoothing of textures. To mitigate this issue, we introduce the second factor, skip feature scaling factors, aiming to alleviate the problem of texture oversmoothing. (p. 3)
Proposed Method
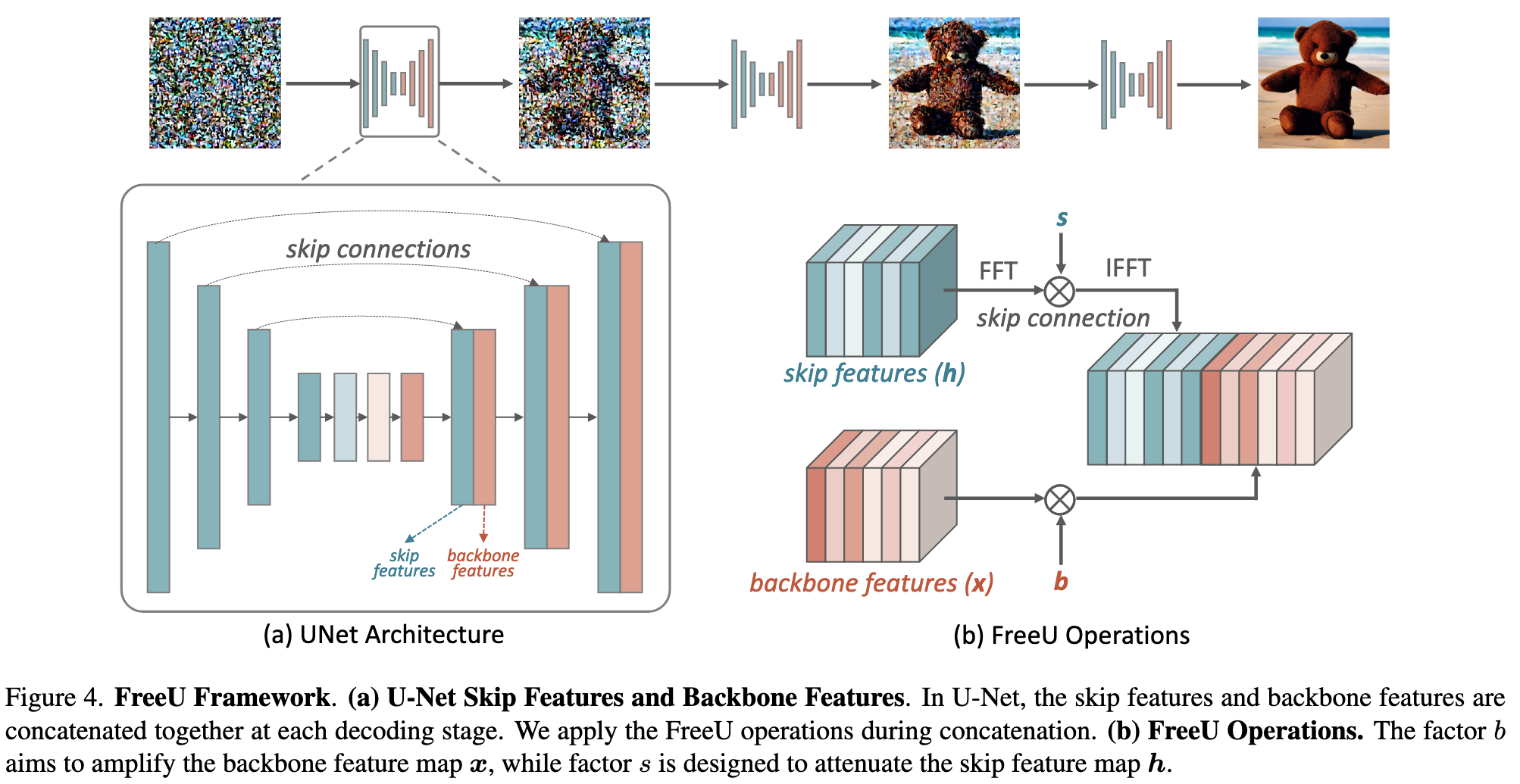
How does diffusion U-Net perform denoising?

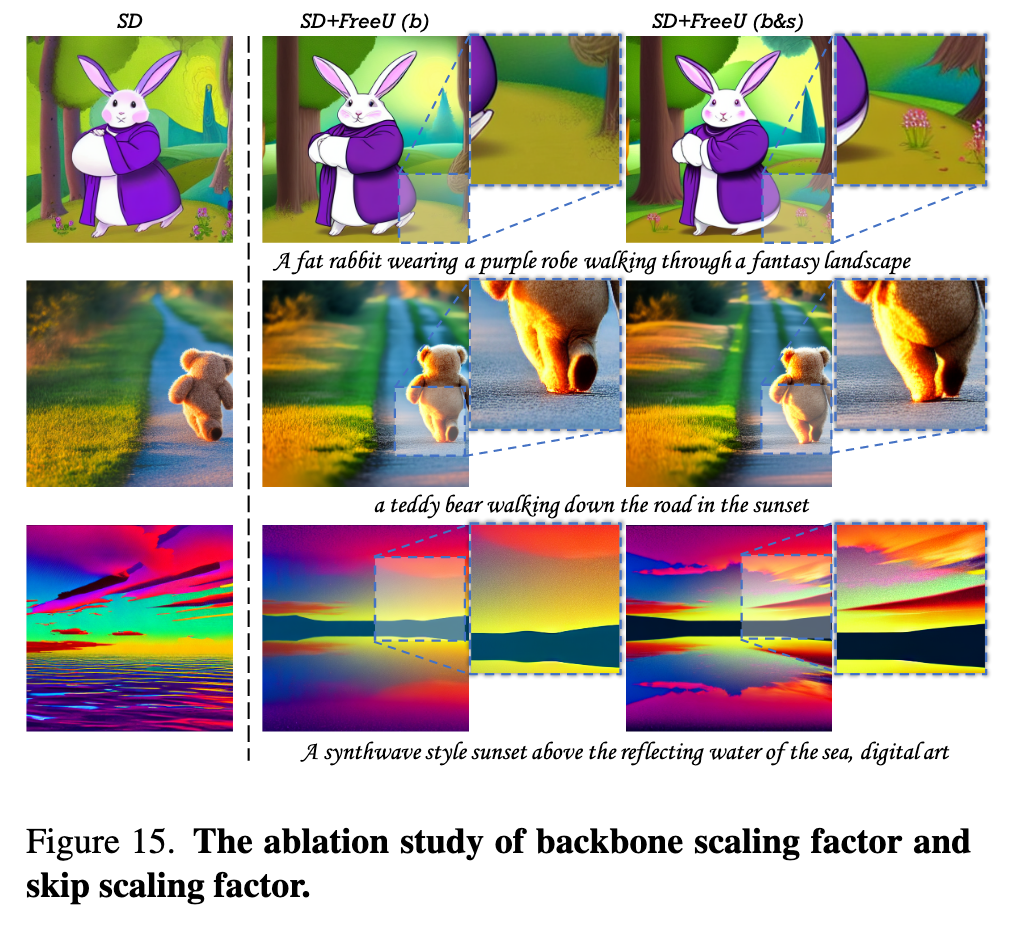
The backbone of U-Net. As shown in Fig. 5, it is evident that elevating the scale factor b of the backbone distinctly enhances the quality of generated images. Conversely, variations in the scaling factor s, which modulates the impact of the lateral skip connections, appear to exert a negligible influence on the quality of the generated images. (p. 5)
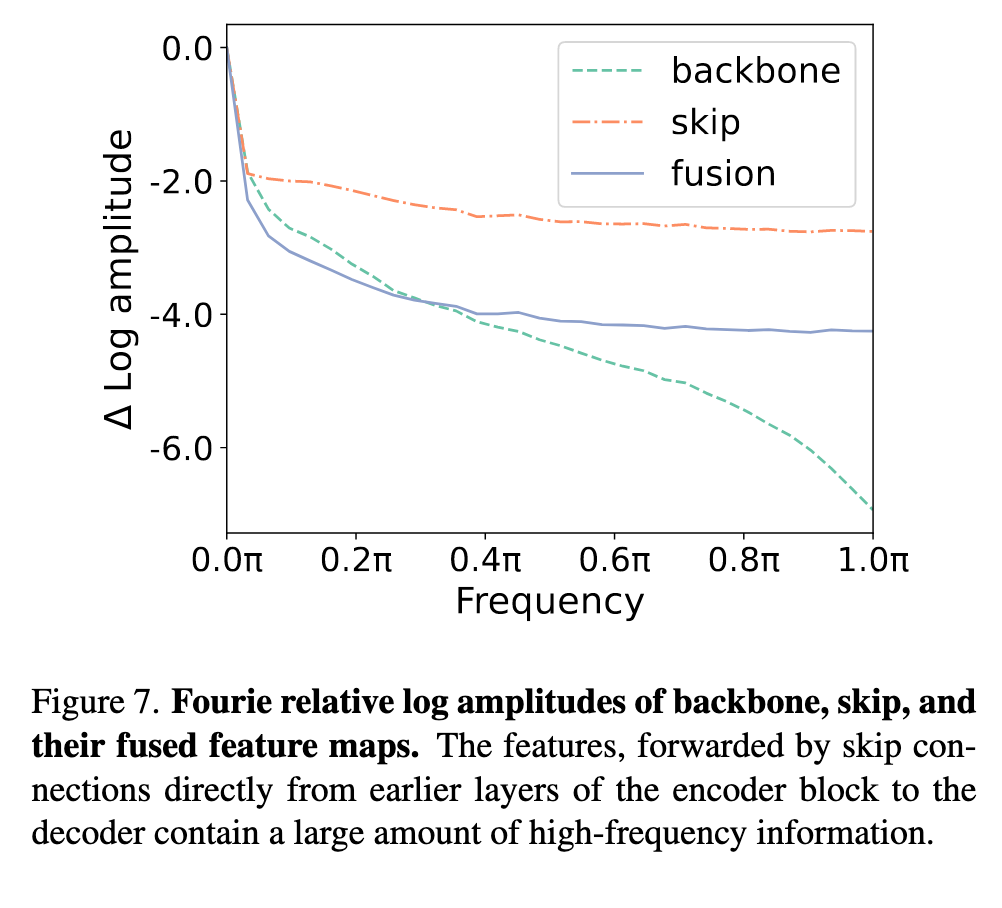
The skip connections of U-Net. Our conjecture, grounded in this observation, posits that during the training of the U-Net architecture, the presence of these high-frequency features may inadvertently expedite the convergence toward noise prediction within the decoder module. Thereby, this observation prompts pertinent questions about the counterbalancing roles played by the backbone and the skip connections in the composite denoising performance of the U-Net framework. (p. 5)
Free lunch in diffusion U-Net
For backbone features, upon experimental investigation, we discern that indiscriminately amplifying all channels of xl through multiplication with bl engenders an oversmoothed texture in the resulting synthesized images. The reason is the enhanced U-Net compromises the image’s high-frequency details while denoising. Consequently, we confine the scaling operation to the half channels of xl as follows: (p. 5)
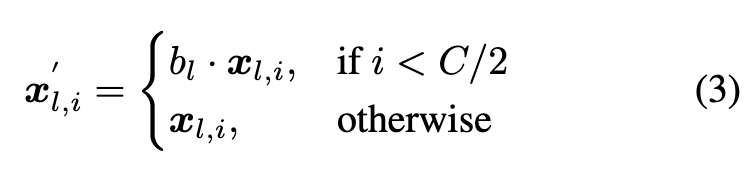
we further employ spectral modulation in the Fourier domain to selectively diminish lowfrequency components for the skip features. (p. 5)
Experiment
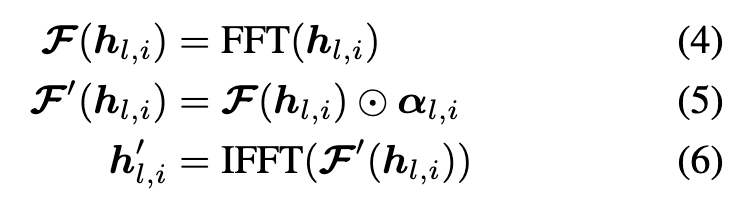
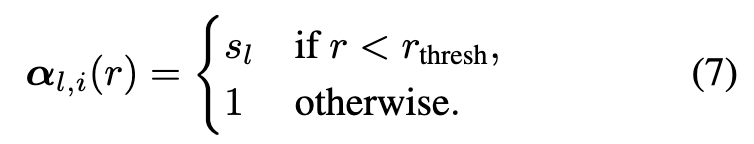


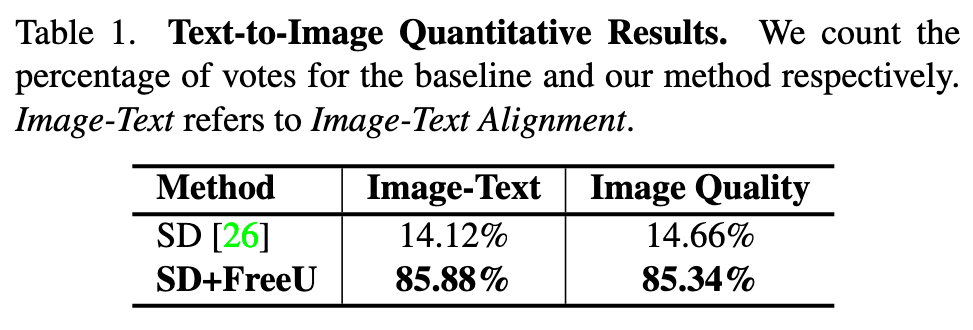



Ablation study
These visualizations illustrate that FreeU exerts a discernible influence in reducing high-frequency information at each step of the denoising process, which indicates FreeU’s capacity to effectively denoising. (p. 10)