GPT-Fathom Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond
[deep-learning llm review dataset exported gpt gpt4 gpt3.5 fathom claude llama sft rlhf This is my reading note for GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond. This paper evaluates several LLMs and found 1) openAI’s GPT significantly outperformed all other competitors and Claude 2 is #2; 2) techniques like SFT and RLHF benefits smaller models most; 3) as the model evolves, some metric may slightly degrade.
Introduction
We systematically evaluate 10+ leading LLMs as well as OpenAI’s legacy models on 20+ curated benchmarks across 7 capability categories, all under aligned settings (p. 1)
Different settings and prompts may lead to very different evaluation results, which may easily skew the observations. Yet, many existing LLM leaderboards reference scores from other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. LLMs are known to be sensitive to the evaluation setting and the formatting of prompt (Liang et al., 2023). (p. 2)
Related Work
Benchmarks constantly play a pivotal role in steering the evolution of AI and, of course, directing the advancement of LLMs as well. There are many great existing LLM evaluation suites. By comparing GPT-Fathom with previous works, we summarize the major difference as follows:
- HELM (Liang et al., 2023) primarily uses answer-only prompting (without CoT) and has not included the latest leading models such as GPT-4 (as of the time of writing);
- Open LLM Leaderboard (Beeching et al., 2023) focuses on open-source LLMs, while we jointly consider leading closed-source and open-source LLMs;
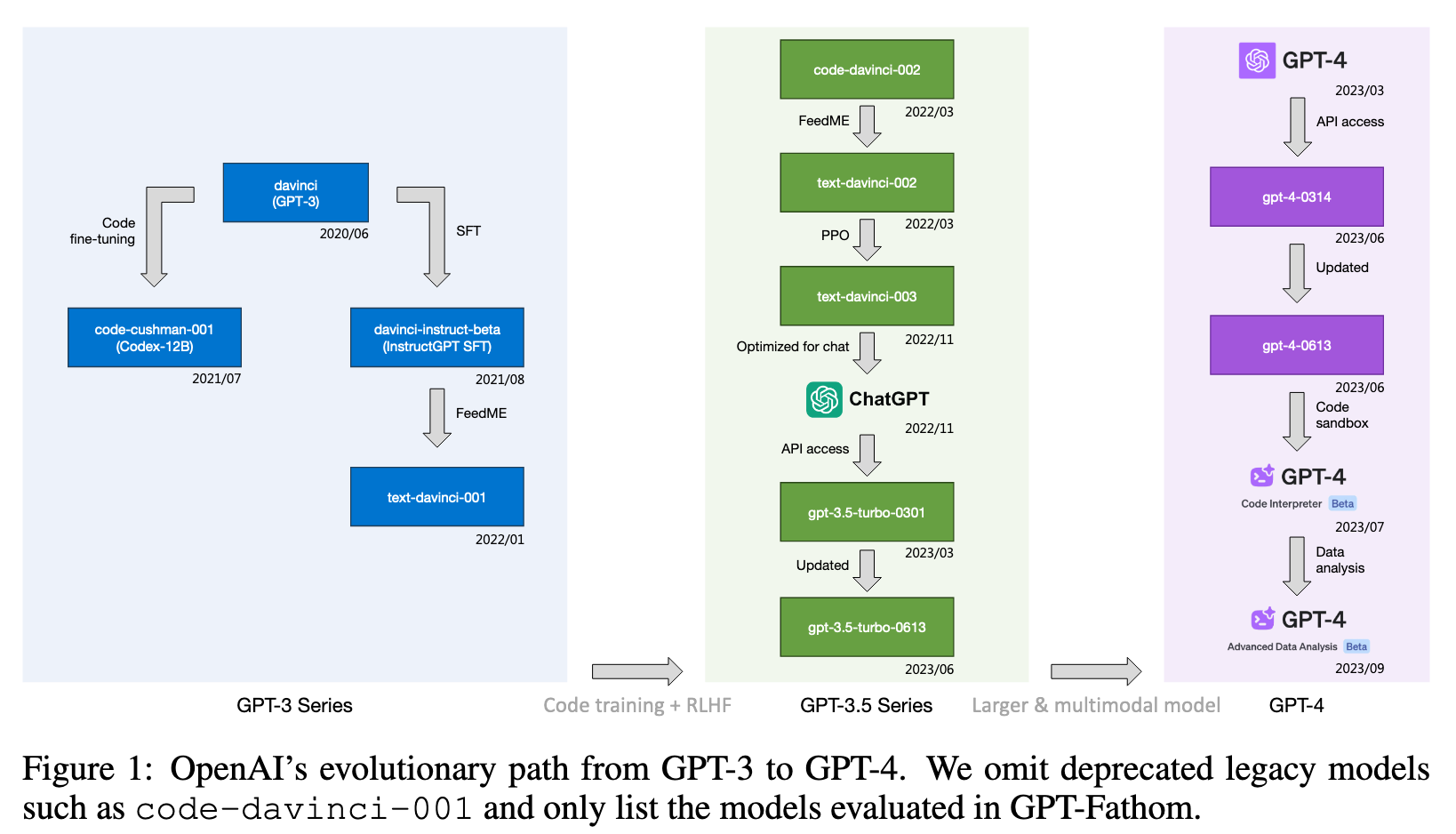
- OpenCompass (Contributors, 2023) evaluates latest open-source and closedsource LLMs (all released after 2023/03), while we cover both leading LLMs and OpenAI’s earlier models to decipher the evolutionary path from GPT-3 to GPT-4;
- InstructEval (Chia et al., 2023) is designed for evaluating instruction-tuned LLMs, while we evaluate both base and SFT / RLHF models;
- AlpacaEval (Li et al., 2023) evaluates on simple instruction-following tasks as a quick and cheap proxy of human evaluation, while we provide systematic evaluation of various aspects of LLM capabilities;
- Chatbot Arena (Zheng et al., 2023) evaluates human user’s dialog preference with a Elo rating system, while we focus on automatic and reproducible evaluation over popular benchmarks;
- Chain-of-Thought Hub (Fu et al., 2023) focuses on evaluating the reasoning capability of LLMs with CoT prompting, while we support both CoT and answer-only prompting settings and evaluate various aspects of LLM capabilities. (p. 2)
Method
Knowledge
- Question Answering, which directly tests whether the LLM knows some facts by asking questions. We adopt Natural Questions5 (Kwiatkowski et al., 2019), WebQuestions (Berant et al., 2013) and TriviaQA (Joshi et al., 2017) as our benchmarks;
- Multi-subject Test, which uses human exam questions to evaluate LLMs. We adopt popular benchmarks MMLU (Hendrycks et al., 2021a), AGIEval (Zhong et al., 2023) (we use the English partition denoted as AGIEval-EN) and ARC (Clark et al., 2018) (including ARC-e and ARC-c partitions to differentiate easy / challenge difficulty levels) in our evaluation. (p. 4)
Reasoning
- Commonsense Reasoning, which evaluates how LLMs perform on commonsense tasks (which are typically easy for humans but could be tricky for LLMs). We adopt popular commonsense reasoning benchmarks LAMBADA (Paperno et al., 2016), HellaSwag (Zellers et al., 2019) and WinoGrande (Sakaguchi et al., 2021) in our evaluation;
- Comprehensive Reasoning, which aggregates various reasoning tasks into one single benchmark. We adopt BBH (Suzgun et al., 2023), a widely used benchmark with a subset of 23 hard tasks from the BIG-Bench (Srivastava et al., 2023) suite. (p. 4)
Comprehension
which requires LLMs to first read the provided context and then answer questions about it. (p. 4)
Multilingual
Beyond pure multilingual tasks like translation (which we plan to support in the near future), we view multilingual capability as an orthogonal dimension, i.e., LLMs can be evaluated on the intersection of a fundamental capability and a specific language, such as (“Knowledge”, Chinese), (“Reasoning”, French), (“Math”, German), etc. (p. 4)
Safety
This category scrutinizes LLM’s propensity to generate content that is truthful, reliable, non-toxic and non-biased, thereby aligning well with human values. To this end, we currently have two sub-categories (and plan to support more benchmarks in the future): 1) Truthfulness, we employ TruthfulQA8 (Lin et al., 2022), a benchmark designed to evaluate LLM’s factuality; 2) Toxicity, we adopt RealToxicityPrompts (Gehman et al., 2020) to quantify the risk of generating toxic output. (p. 4)
EXPERIMENTS
OpenAI vs. non-OpenAI LLMs
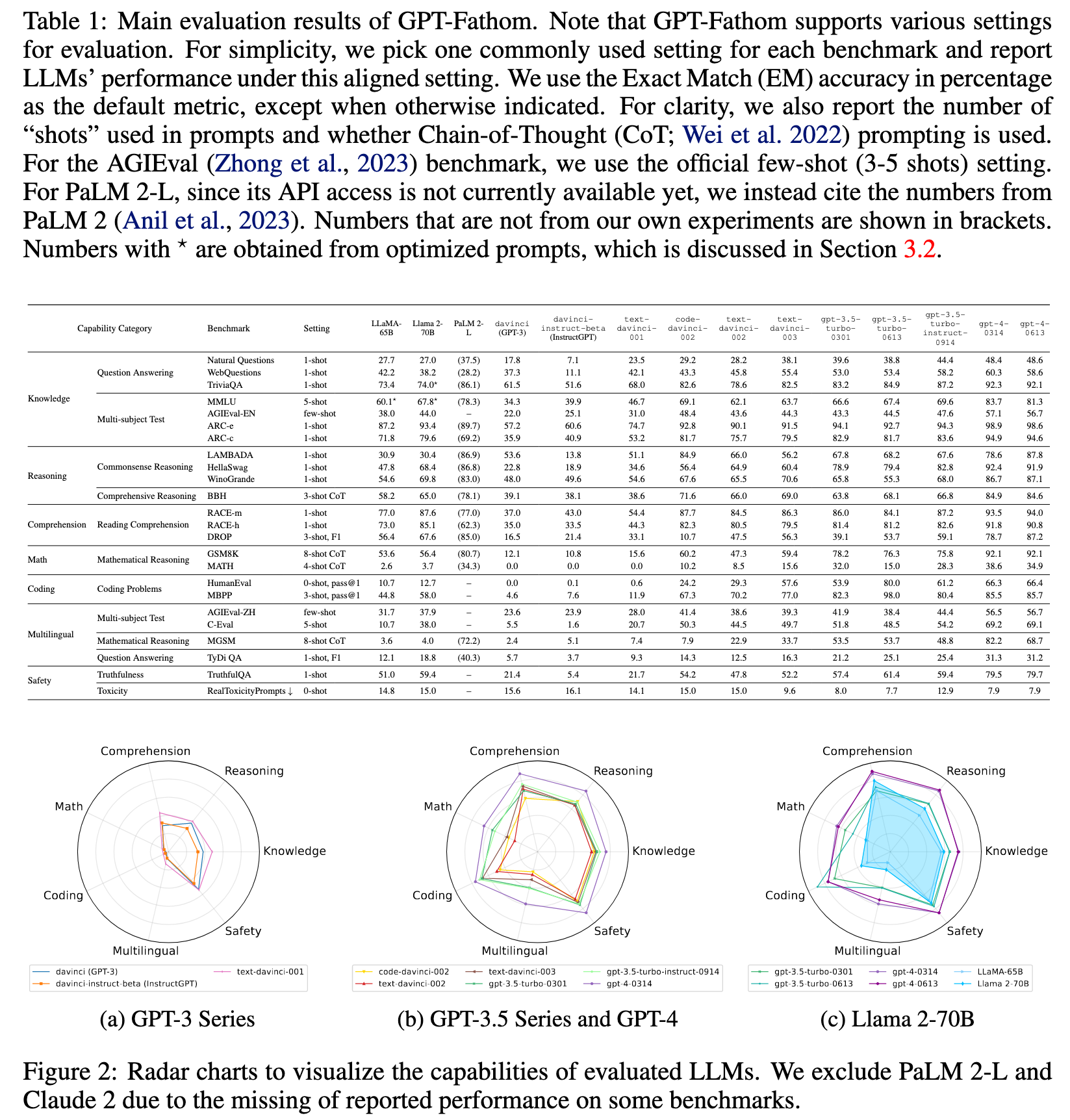
The overall performance of GPT-4, which is OpenAI’s leading model, is crushing the competitors on most benchmarks. As described in Anil et al. (2023), PaLM 2 is pretrained on multilingual data across hundreds of languages, confirming the remarkable multilingual performance achieved by PaLM 2-L that beats GPT-4. (p. 6)
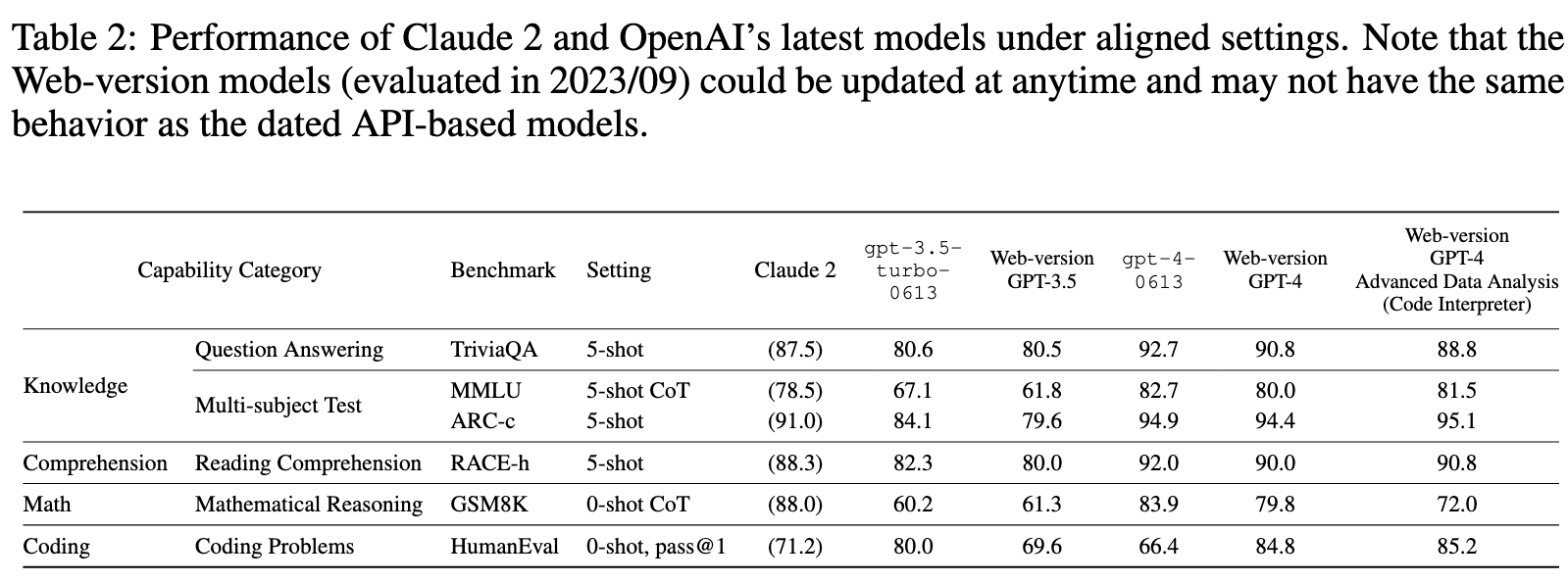
Table 2 indicates that Claude 2 indeed stands as the leading non-OpenAI model. Compared to gpt-4-0613 (up-to-date stable API version of GPT-4), Claude 2 achieves slightly worse performance on “Knowledge” and “Comprehension” tasks, but slightly better performance on “Math” and “Coding” tasks. (p. 7)
Closed-source vs. open-source LLMs
Compared to LLaMA, Llama 2 is trained on 40% more pretraining data with doubled context length (Touvron et al., 2023b). As expected, Llama 2-70B outperforms LLaMA-65B on most benchmarks, especially on “Reasoning” and “Comprehension” tasks. (p. 7)
OpenAI API-based vs. Web-version LLMs
We observe that the dated API models gpt-3.5-turbo-0613 and gpt-4-0613, consistently perform slightly better than their front-end counterparts, i.e., Web-version GPT-3.5 (serving ChatGPT) and Web-version GPT-4. (p. 7)
Seesaw phenomenon of LLM capabilities
By comparing the performance of OpenAI API models dated in 2023/03 and 2023/06, we note the presence of a so-called “seesaw phenomenon”, where certain capabilities exhibit improvement, while a few other capabilities clearly regress. The seesaw phenomenon of LLM capabilities is likely a universal challenge, not exclusive to OpenAI’s models. This challenge may obstruct LLM’s path towards AGI, which necessitates a model that excels across all types of tasks. (p. 7)
Impacts of pretraining with code data
This suggests that incorporating code data into LLM pretraining could universally elevate its potential, particularly in the capability of reasoning. (p. 8)
Impacts of SFT and RLHF
SFT boosts the performance of LLaMA-65B on MMLU (Touvron et al., 2023a), while all SFT models within the extensive Llama2-70B family on the Open LLM Leaderboard (Beeching et al., 2023) show only marginal improvements on MMLU. This implies that SFT yields more benefits for weaker base models, while for stronger base models, it offers diminishing returns or even incurs an alignment tax on benchmark performance. (p. 8)
SFT and RLHF can effectively distill the capability of pass@100 into pass@1, signifying a transfer from inherent problem-solving skills to one-take bug-free coding capability (p. 8)
Impacts of the number of “shots”
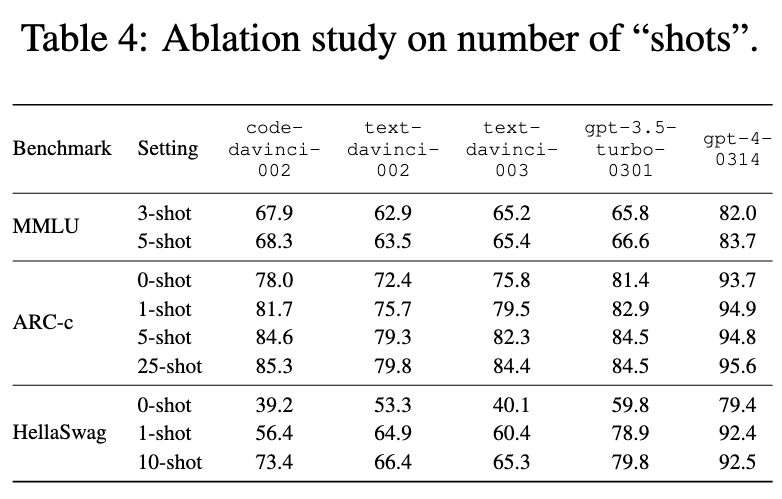
As expected, performance generally improves with an increased number of “shots”, however, the improvement rate quickly shrinks beyond 1-shot, particularly for stronger models. (p. 9)
Impacts of CoT prompting
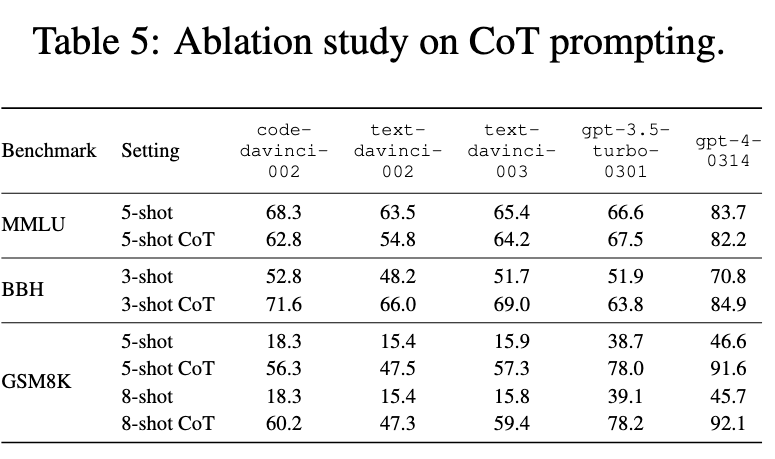
As illustrated in Table 5, the influence of CoT prompting varies across benchmarks. On tasks that are knowledge-intensive, like MMLU, CoT has minimal or even slightly negative impact on performance. However, for reasoning-intensive tasks, such as BBH and GSM8K, CoT prompting markedly enhances LLM performance. (p. 9)
Prompt sensitivity
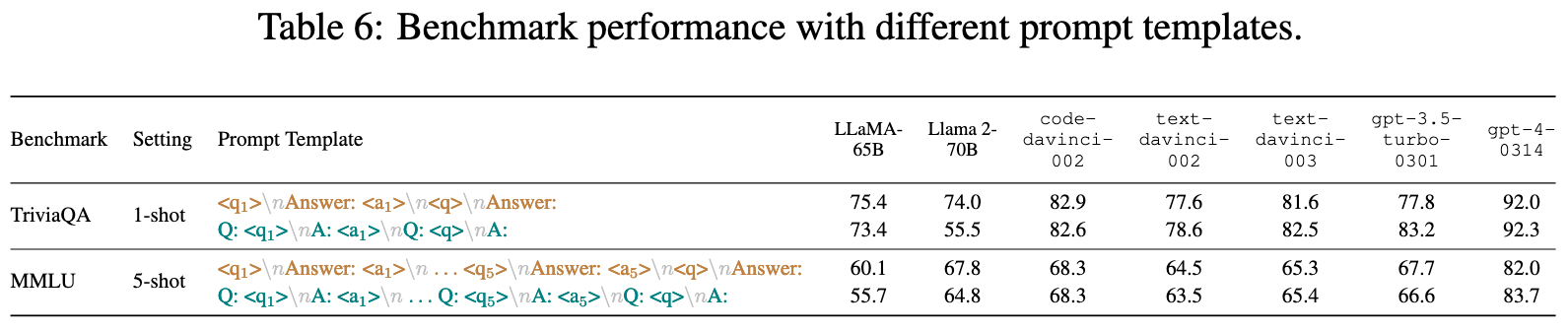
We observe that open-source models LLaMA-65B and Llama 2-70B exhibit greater prompt sensitivity. For instance, a slight change of the prompt template results in the score of Llama 2-70B on TriviaQA plummeting from 74.0 to 55.5. (p. 9)
Sampling variance
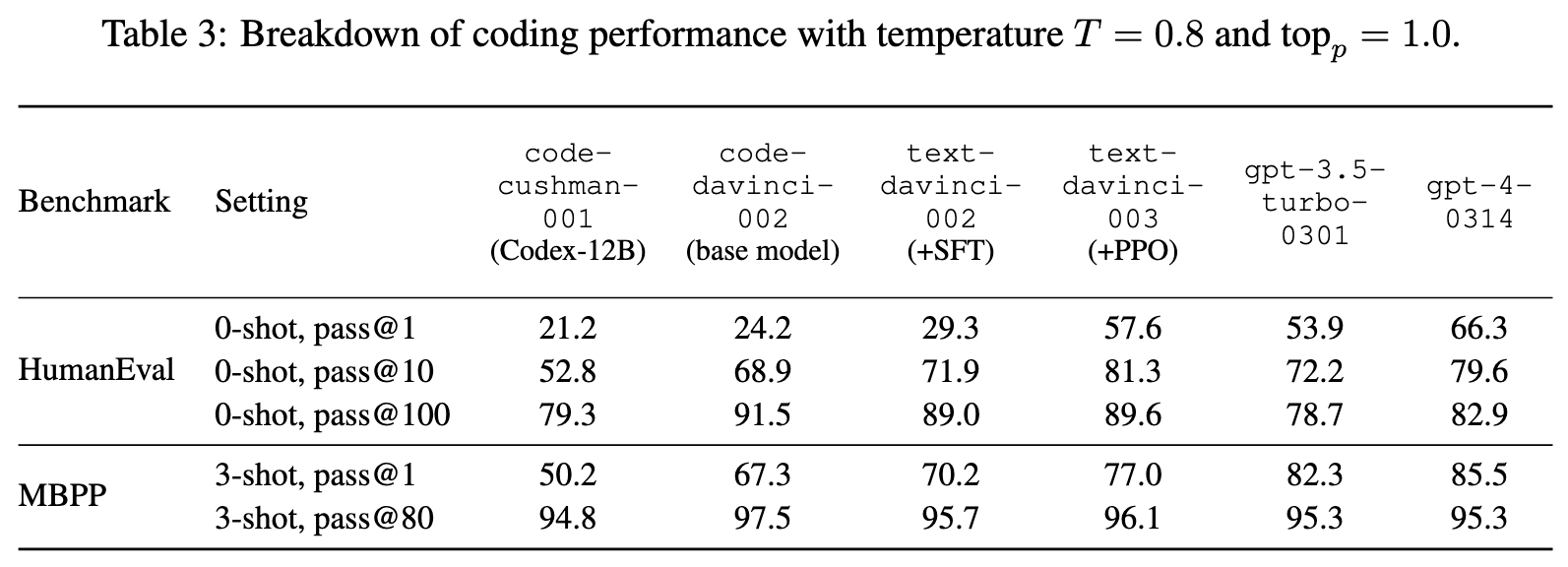
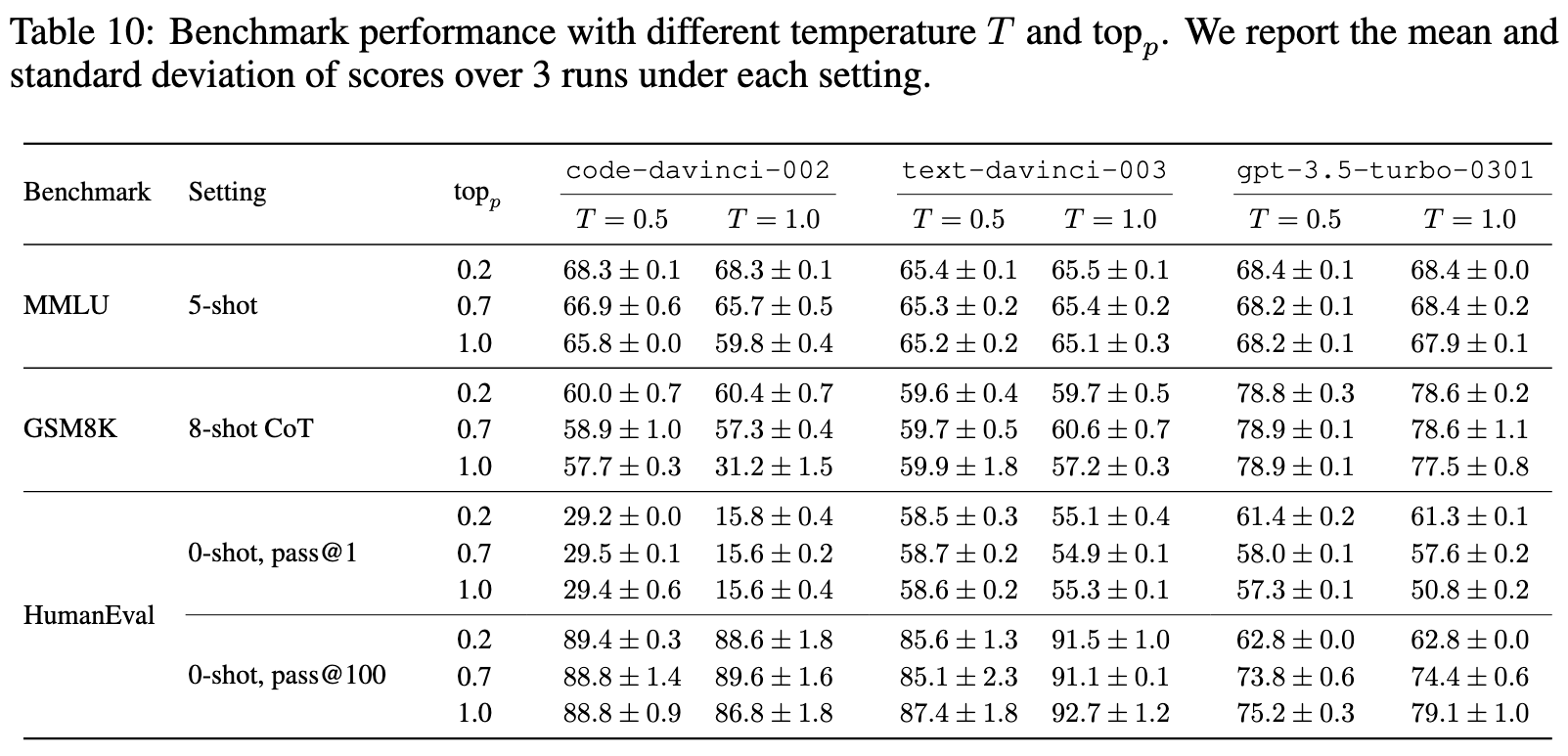
The decoding process of LLMs is repeatedly sampling the next token from the LLM output distribution. Various hyperparameters, including the temperature T and the nucleus sampling (Holtzman et al., 2020) parameter topp, can be adjusted to modify the sampling behavior. In our evaluations, we set topp = 1.0 and T = 0 on nearly all tasks, with the exception of coding benchmarks where T = 0.8. (p. 9)
As expected, a higher temperature T introduces greater variance in benchmark scores, since the output becomes less deterministic. Notably, LLMs (especially base models) tend to underperform with a higher temperature T . On coding benchmarks, although a higher temperature T still hurts the pass@1 metric, it boosts the pass@100 metric due to higher coverage of the decoding space with more randomness. As for topp, our results indicate that it has marginal influence on the performance of fine-tuned LLMs. (p. 10)