HyperDreamBooth HyperNetworks for Fast Personalization of Text-to-Image Models
[style-drop fast-composer diffusion taming-encoder hyper-dreambooth personalize custom-diffusion textual-inversion deep-learning instant-booth dreambooth dream-artist image2image sv-dff This is my reading note for HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models. This paper improves DreamBooth by applying LORA to improve speed.

Introduction
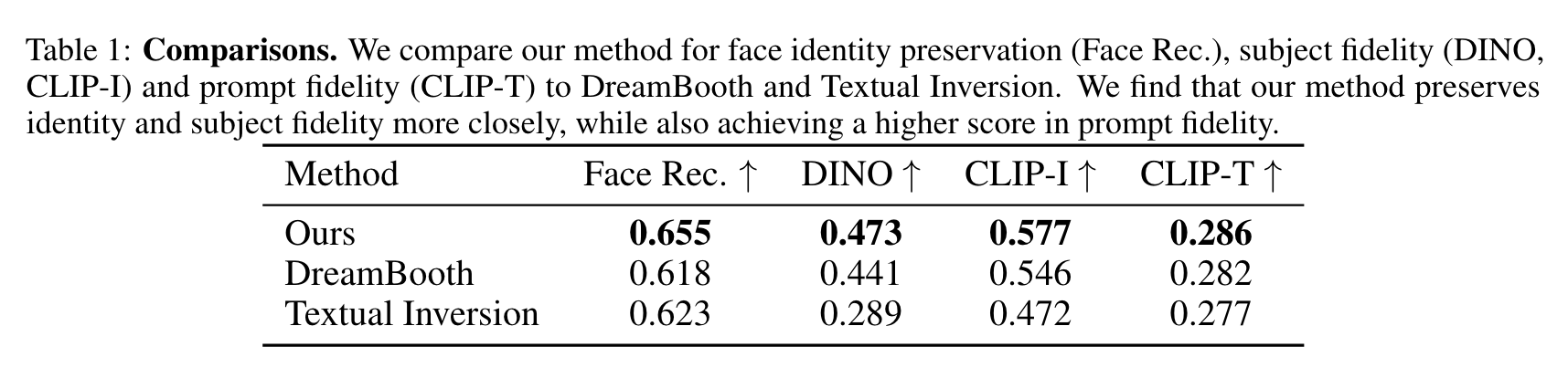
To overcome these challenges, we propose HyperDreamBooth—a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person’s face in various contexts and styles, with high subject details while also preserving the model’s crucial knowledge of diverse styles and semantic modifications. (p. 1)
One of the key properties of works such as DreamBooth [25], is the ability to implant a new subject into the model without damaging the model’s prior. Another key feature of this type of method is that subject’s essence and details are conserved even when applying vastly different styles. (p. 2)
DreamBooth has some shortcomings: size and speed. For size, the original DreamBooth paper finetunes all of the weights of the UNet and Text Encoder of the diffusion model, which amount to more than 1GB for Stable Diffusion. In terms of speed, notwithstanding inference speed issues of diffusion models, training a DreamBooth model takes about 5 minutes for Stable Diffusion (1,000 iterations of training). (p. 2)
Two contributions from the proposed method:
- Lighweight DreamBooth (LiDB) - a personalized text-to-image model, where the customized part is roughly 100KB of size. This is achieved by training a DreamBooth model in a low- dimensional weight-space generated by a random orthogonal incomplete basis inside of a low-rank adaptation [16] weight space. (p. 2)
- New HyperNetwork architecture that leverages the Lightweight DreamBooth configuration and generates the customized part of the weights for a given subject in a text-to-image diffusion model. These provide a strong directional initialization that allows us to further finetune the model in order to achieve strong subject fidelity within a few iteration. Our method is 25x faster than DreamBooth while achieving similar performances. (p. 2)
Related Work
Personalization of Generative Models
Pivotal tuning [23] proposes to finetune a GAN with an inverted latent code. The work of [21] proposes to finetune StyleGAN using around 100 face images to obtain a personalized generative prior. HyperNetworks were introduced as an idea of using an auxiliary neural network to predict network weights in order to change the functioning of a specific neural network (p. 3)
T2I Personalization via Finetuning
- Textual Inversion [11] proposes to optimize an input text embedding on the few subject images and use that optimized text embedding to generate subject images (p. 3)
- DreamBooth [25] proposes to optimize the entire T2I network weights to adapt to a given subject resulting in higher subject fidelity in output images. (p. 3)
- CustomDiffusion [19] proposes to only optimize cross-attention layers.
- SVDiff [14] proposes to optimize singular values of weights. LoRa [2, 16] proposes to optimize low-rank approximations of weight residuals (p. 3)
- Styledrop proposes to use adapter tuning [15] and finetunes a small set of adapter weights for style personalization.
- DreamArtist [10] proposes a one-shot personalization techniques by employing a positive-negative prompt tuning strategy. (p. 4)
Fast T2I Personalization
The works of [12] and [31] propose to learn encoders that predicts initial text embeddings following by complete network finetuning for better subject fidelity. (p. 4)
InstantBooth [27] and Taming Encoder [17] create a new conditioning branch for the diffusion model, which can be conditioned using a small set of images, or a single image, in order to generate personalized outputs in different styles. Both methods need to train the diffusion model, or the conditioning branch, to achieve this task (p. 4)
FastComposer [32] proposes to use image encoder to predict subject-specific embeddings and focus on the problem of identity blending in multi- subject generation. The work of [5] propose to guide the diffusion process using face recognition loss to generate specific subject images. In such guidance techniques, it is usually difficult to balance diversity in recontextualizations and subject fidelity while also keeping the generations within the image distribution. Face0 [29] proposes to condition a T2I model on face embeddings so that one can generate subject-specific images in a feedforward manner without any test-time optimization. Celeb-basis [34] proposes to learn PCA basis of celebrity name embeddings which are then used for efficient personalization of T2I models. In contrast to these existing techniques, we propose a novel hypernetwork based approach to directly predict low-rank network residuals for a given subject. (p. 4)
Preliminaries
At a high-level, DreamBooth optimizes all the diffusion network weights θ on a few given subject images while also retaining the generalization ability of the original model with class-specific prior preservation loss (p. 4)
That is, for a layer l with weight matrix $W \in R^{n×m}$, LoRa proposes to finetune the residuals ∆W. For diffusion models, LoRa is usually applied for the cross and self-attention layers of the network [2]. A key aspect of LoRa is the decomposition of ∆W matrix into low-rank matrices $A \in R^{n×r}$ and $B \in R^{r×m}$: ∆W = AB (p. 4)
Proposed Method
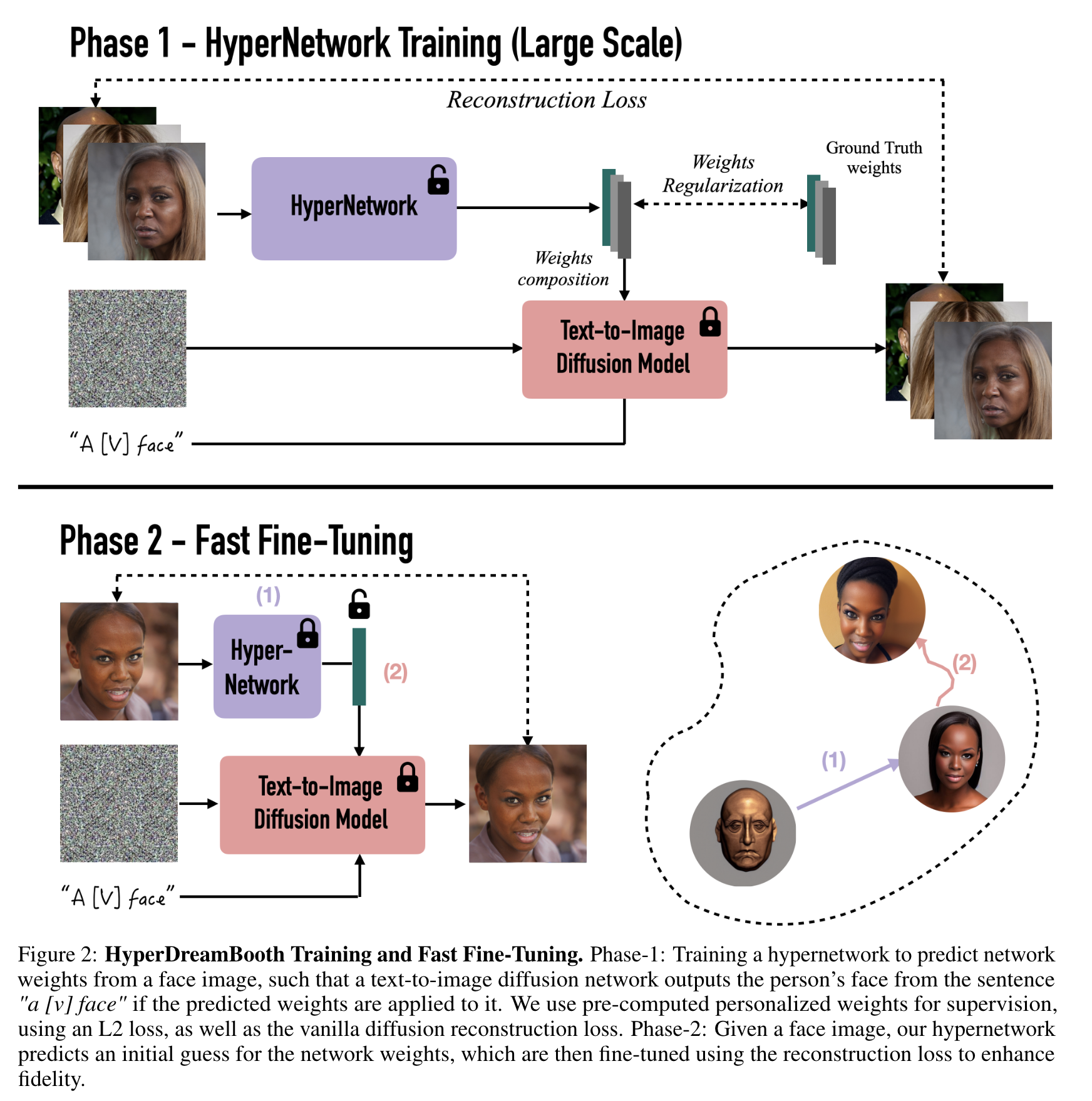
Lightweight DreamBooth (LiDB)
The core idea behind Lightweight DreamBooth (LiDB) is to further decompose the weight-space of a rank-1 LoRa residuals. where the aux layers are randomly initialized with row-wise orthogonal vectors and are frozen; and the train layers are learned (p. 5)

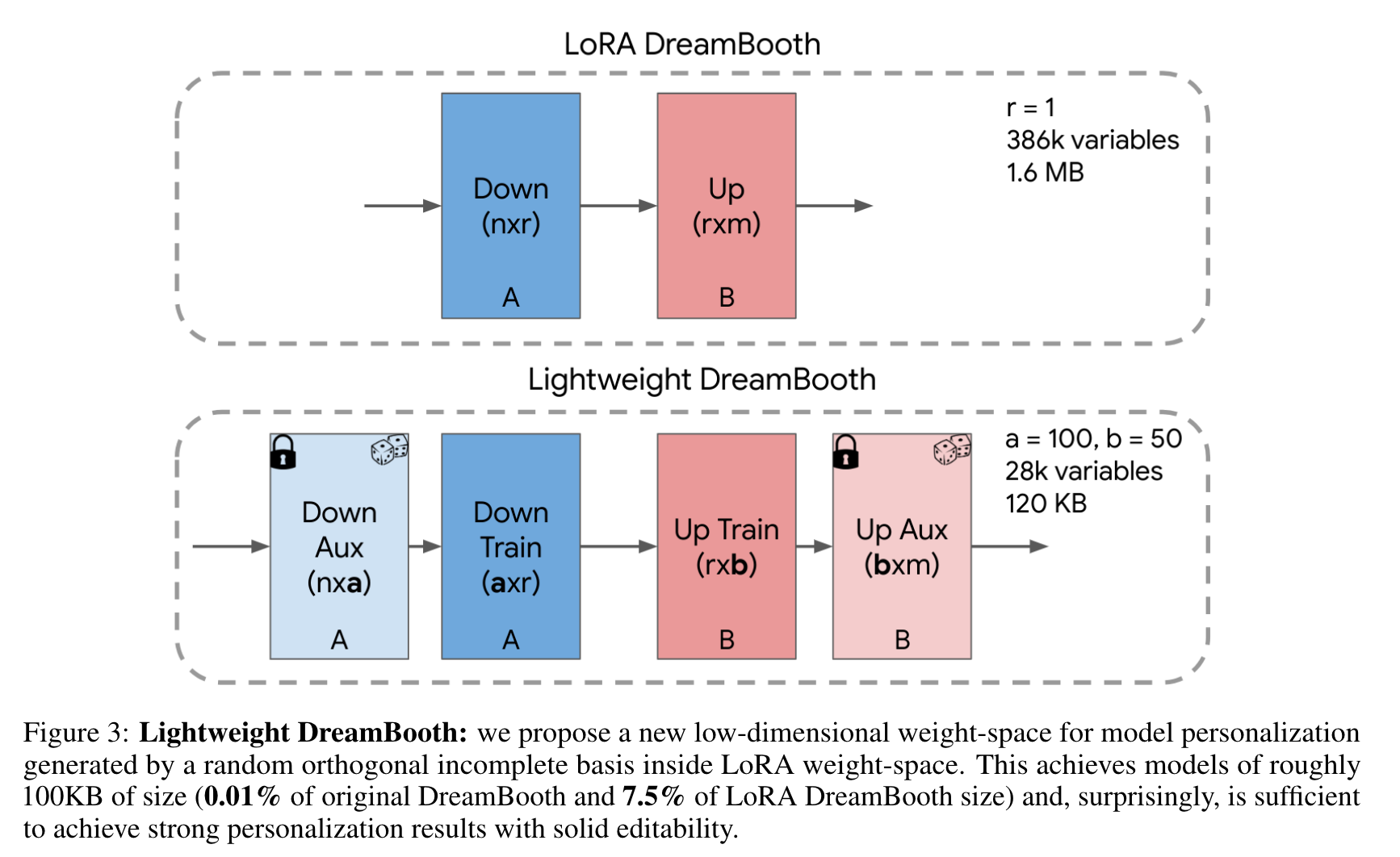
HyperNetwork for Fast Personalization of Text-to-Image Models
the HyperNetwork Hη with η parameters takes the given image x as input and predicts the LiDB low-rank residuals ˆ θ = Hη(x). The HyperNetwork is trained on a dataset of domain-specific images with a vanilla diffusion denoising loss and a weight-space loss: (p. 6)
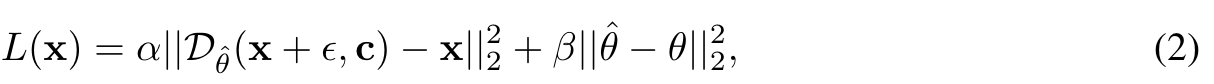
HyperNetwork Architecture. Concretely, as illustrated in Fig. 4, we separate the HyperNetwork architecture into two parts: a ViT image encoder and a transformer decoder. (p. 6)
Iterative Prediction. We find that the HyperNetwork achieves better and more confident predictions given an iterative learning and prediction scenario [4], where intermediate weight predictions are fed to the HyperNetwork and the network’s task is to improve that initial prediction. (p. 6)
Rank-Relaxed Fast Finetuning
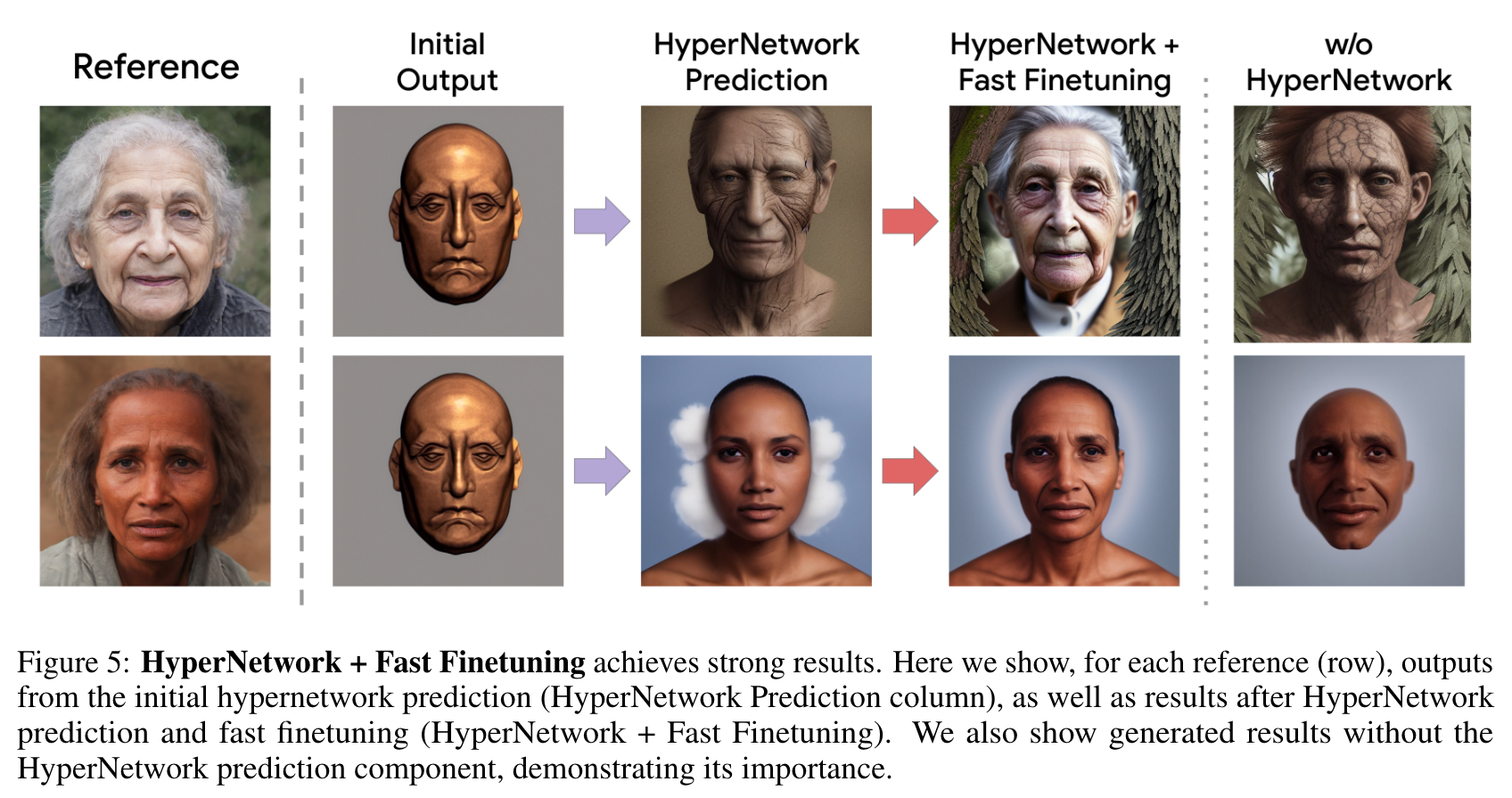
Experiments