Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks
[vfa simvlm multimodal blip coca imglish deep-learning florence vinvl transformer flamingo albef This is my reading note for Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks. The paper proposes a multi modality model which models image data as foreign language and propose only to use masked language models as the pre-train tasks.
Introduction
Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multi- way Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked “language” modeling on images (Imglish), texts (English), and image-text pairs (“parallel sentences”) in a unified manner. (p. 1)
In this work, we advance the convergence trend for vision-language pretraining from the following three aspects. (p. 2)
For vision-language modeling, there are various ways to apply Transformers due to the different natures of downstream tasks. For example, the dual-encoder architecture is used for efficient retrieval [RKH+21], encoder-decoder networks for generation tasks [WYY+21], and the fusion-encoder architecture for image-text encoding [KSK21]. However, most foundation models have to manually convert the end-task formats according to the specific architectures. Moreover, the parameters are usually not effectively shared across modalities. In this work, we adopt Multiway Transformers [WBDW21] for general-purpose modeling, i.e., one unified architecture shared for various downstream tasks. The modular network also comprehensively considers modality-specific encoding and cross-modality fusion. (p. 2)
Second, the pretraining task based on masked data modeling has been successfully applied to various modalities, such as texts [DCLT19], images [BDPW22, PDB+22], and image-text pairs [BWDW22]. Current vision-language foundation models usually multitask other pretraining objectives (such as image-text matching), rendering scaling-up unfriendly and inefficient. In contrast, we only use one pretraining task, i.e., mask-then-predict, to train a general-purpose multimodal foundation model. By regarding the image as a foreign language (i.e., Imglish), we handle texts and images in the same manner without fundamental modeling differences. Consequentially, image-text pairs are utilized as “parallel sentences” in order to learn the alignments between modalities. We also show that the simple yet effective method learns strong transferable representations, achieving state-of-the-art performance on both vision and vision-language tasks. The prominent success demonstrates the superiority of generative pretraining [DCLT19, BDPW22]. (p. 2)
Third, scaling up the model size and data size universally improves the generalization quality of foundation models, so that we can transfer them to various downstream tasks. (p. 2)
BEIT-3: A General-Purpose Multimodal Foundation Model
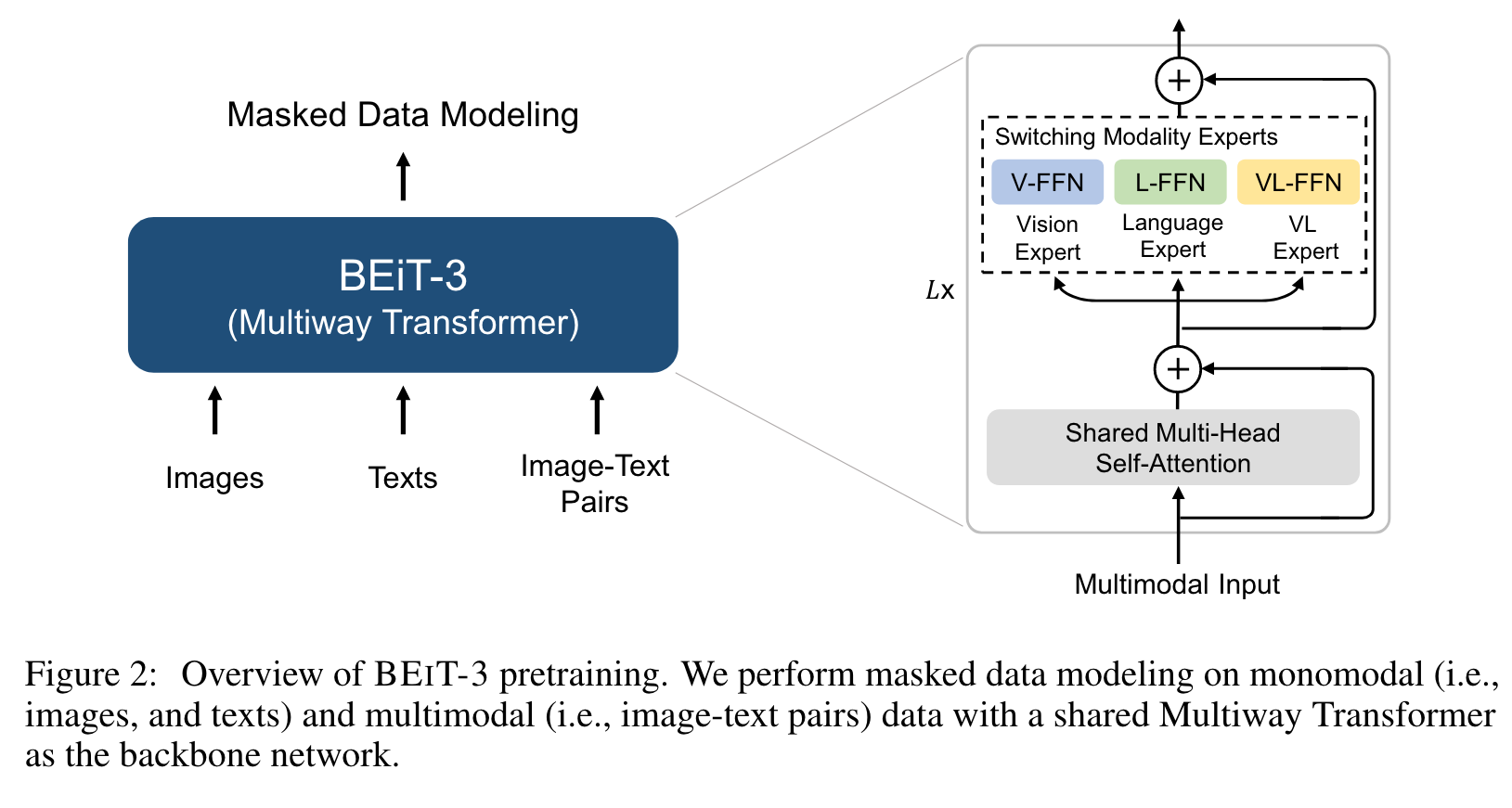
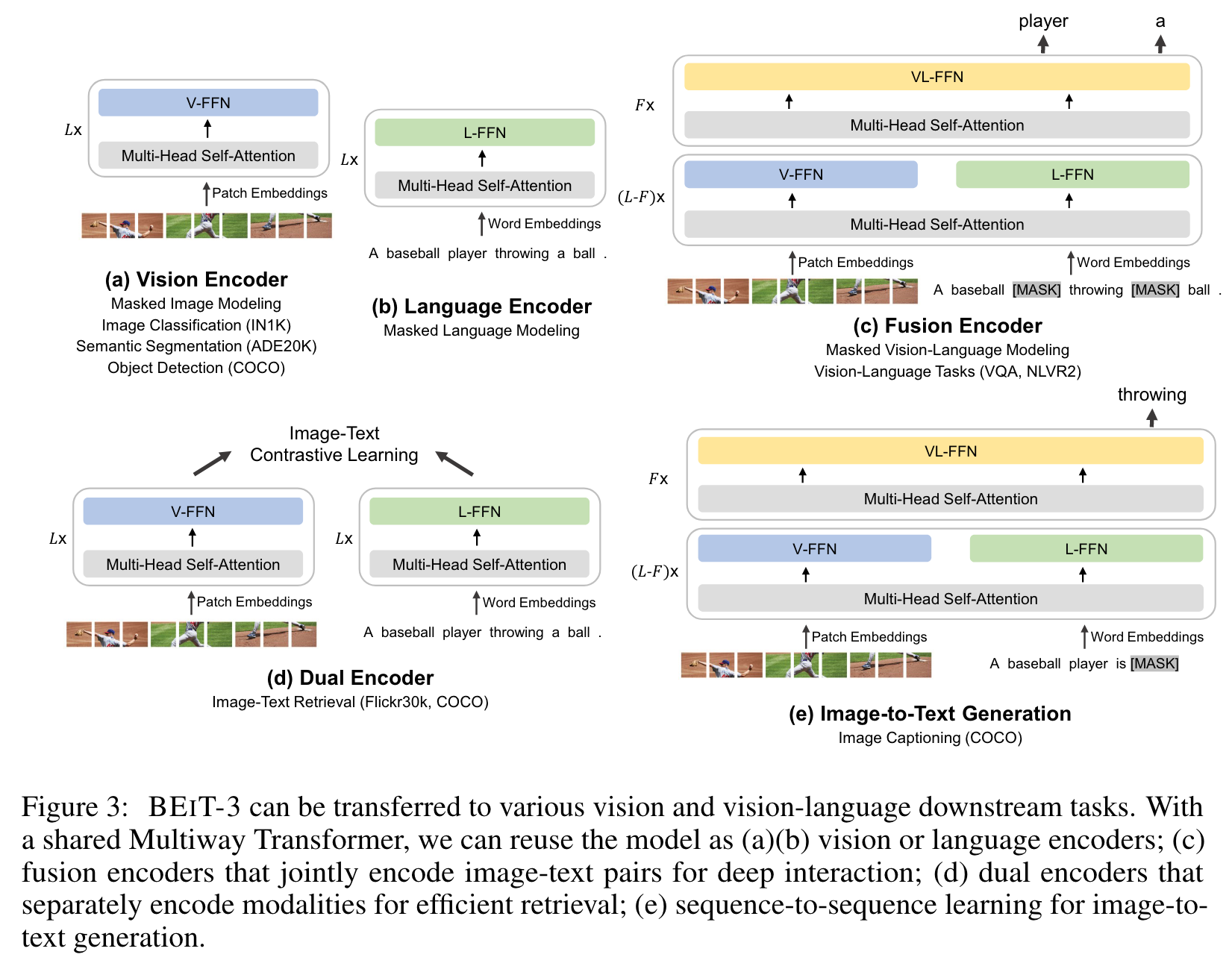
Backbone Network: Multiway Transformers
We use Multiway Transformers [WBDW21] as the backbone model to encode different modalities. As shown in Figure 2, each Multiway Transformer block consists of a shared self-attention module, and a pool of feed-forward networks (i.e., modality experts) used for different modalities. We route each input token to the experts depending on its modality. In our implementation, each layer contains a vision expert and a language expert. Moreover, the top three layers have vision-language experts designed for fusion encoders (p. 3)
Using a pool of modality experts encourages the model to capture more modality-specific information. The shared self-attention module learns the alignment between different modalities and enables deep fusion for multimodal (such as vision-language) tasks. (p. 3)

Pretraining Task: Masked Data Modeling
We pretrain BEIT-3 via a unified masked data modeling [BWDW22] objective on monomodal (i.e., images, and texts) and multimodal data (i.e., image-text pairs). During pretraining, we randomly mask some percentage of text tokens or image patches and train the model to recover the masked tokens. The unified mask-then-predict task not only learns representations but also learns the alignment of different modalities. (p. 4)
We randomly mask 15% tokens of monomodal texts and 50% tokens of texts from image-text pairs. For images, we mask 40% of image patches using a block-wise masking strategy as in BEIT [BDPW22, PDB+22]. (p. 4)
We show that a much smaller pretraining batch size can be used with the mask-then-predict task. In comparison, contrastive-based mod- els [RKH+21, JYX+21, YCC+21, YWV+22] usually need a very large batch size2 for pretraining, which brings more engineering challenges, such as GPU memory cost. (p. 4)
 %% end annotations %%
%% end annotations %%
%% Import Date: 2023-09-25T19:55:52.973-07:00 %%