InstructDiffusion A Generalist Modeling Interface for Vision Tasks
[segment multimodal text2image diffusion object-detection deep-learning image2image This is my reading note for InstructDiffusion: A Generalist Modeling Interface for Vision Tasks. This paper formulated many vision tasks like segmentation and key point detection as text guided image edit task, and thus can be modeled by diffusion based image edit model. To to that, this paper collects a dataset of different vision tasks, each item contains source image, vision task as text prompt and target image as vision results.

Introduction
We present InstructDiffusion, a unifying and generic framework for aligning computer vision tasks with human instructions. Unlike existing approaches that integrate prior knowledge and pre-define the output space (e.g., categories and coordinates) for each vision task, we cast diverse vision tasks into a human-intuitive image-manipulating process whose output space is a flexible and interactive pixel space. (p. 1)
In this paper, we take advantage of the DDPM and propose a novel approach to address these challenges by treating all computer vision tasks as image generation, specifically instructional image editing tasks. (p. 2)
We mainly focus on three types of output formats: 3channel RGB images, binary masks, and keypoints. We propose a unified representation that encodes masks and keypoints into 3-channel images to handle various image understanding tasks. Then we use a post-processing module to extract the commonly used output format for evaluation. (p. 2)
Related Work
Vision Language Foundation Models
The pioneering works, CLIP [55] and ALIGN [26], are trained with contrastive loss, showing impressive generalization capabilities for downstream tasks by aligning pairs of images and texts in a cross-modal shared embedding space. Subsequent efforts extend the image-text contrastive method to a broader spectrum, such as the image-text-label space proposed in UniCL [88] and a wider range of tasks as well as modalities supported in Florence [94] and INTERN [62]. However, contrastive-based methods lack the ability to generate language, which limits their application in open-ended tasks such as captioning or visual question answering. (p. 2)
Mostly, these models cast a wide range of open-ended vision tasks as text prediction problems, mapping visual input content to language semantics to enable general-purpose visual and language understanding. BEIT3 [77] unifies the pretraining task in a masked data modeling manner. CoCa [92] and BLIP [34, 35] unifies contrastive learning and generative learning. Flamingo [2] accepts arbitrarily interleaved visual data and text as input and generates text in an open-ended manner by learning on a broad diversity of vision language tasks. LLaVA [43] exploits visual instruction tuning by converting image-text pairs into an instruction-following format. GLIP v2 [95] and Kosmos v2 [54] leverage grounded image-text pairs to further unlock the grounding capability of multimodal large language models (p. 3)
Vision Generalist Models
Currently, there are two major interfaces for output unification: language-like generation and image-resembling generation. Most existing attempts for vision generalists take inspiration from sequence-to-sequence models in the NLP field and model a sequence of discrete tokens through next token prediction [10, 20, 59, 74, 76]. Pix2Seq v2 [11] unifies object detection, instance segmentation, keypoint detection, and image captioning by quantizing the continuous image coordinates for the first three tasks. Unified IO [46] further unifies dense structure outputs such as images, segmentation masks, and depth maps using a vector quantization variational auto-encoder (VQ-VAE) [70]. (p. 3)
As quantization inevitably introduces information loss during discretization, another direction of unification aims to explore the image itself as a natural interface for vision generalists [5, 78]. Painter [78] formulates the dense prediction task as a masked image inpainting problem and demonstrates in-context capability in vision tasks such as depth estimation, semantic segmentation, instance segmentation, keypoint detection, and image restoration. Recently, PromptDiffusion [79] also exploits in-context visual learning with a text-guided diffusion model [60] and integrates the learning of six different tasks, i.e., image-to-depth, image-to-HED, image-to-segmentation and vice versa. Our work also examines image-resembling generation. (p. 3)
Method
By leveraging the Denoising Diffusion Probabilistic Model (DDPM), we treat all computer vision tasks as human intuitive image manipulation processes with outputs in a flexible and interactive pixel space. Several existing multimodal models, such as Flamingo [2] and BLIP2 [34], inherently produce natural language as their target output, thereby restricting their capabilities to visual question answering and image captioning. In contrast, our approach posits that formulating various vision tasks, including segmentation, keypoint detection, and image synthesis as image-resembling generation processes, is more intuitive, straightforward, and readily assessable for human evaluation. (p. 3)
Unified Instructional for Vision Tasks
The unified modeling interface for all tasks is referred to as Instructional Image Editing. By denoting the training set as {x^i}, each training data xi can be represented in the form of {c^i, s^i, t^i}, where c^i signifies the control instruction, while s^i and t^i represent the source and target images, respectively. Within this context, our method aims to generate a target image t^i that adheres to the given instruction c^i when provided with an input source image s^i . (p. 3)
To enhance the diversity of instructions, we first manually write 10 instructions for each task. Then we use GPT4 to rewrite and expand the diversity of these instructions, thereby mimicking user input to the system. Subsequently, one instruction is chosen at random during the training process. (p. 4)
Training Data Construction
To ensure the accuracy and relevance of the data, we search in Google by utilizing the keyword ”photoshop request”. This approach enables us to amass a substantial dataset comprising over 23,000 data triplets, which further aids in refining our understanding of user requirements and reduces the domain gap between training and inference. (p. 5)
In order to guarantee the quality of the training data, we further utilize image quality assessment tools to eliminate substandard data. Specifically, we apply Aesthetics Score and GIQA [18] as image quality evaluation metrics, specifically utilizing LAION-Aesthetics-Predictor [61] for Aesthetics Score and constructing a KNN-GIQA model on LAION-600M [61] images for calculating GIQA scores. We exclude two categories of data: i) target images with low-quality scores, and ii) a significant discrepancy in quality scores between the source image and its corresponding target image. Our findings indicate that this data-filtering process is of vital importance. (p. 5)

Unified Framework
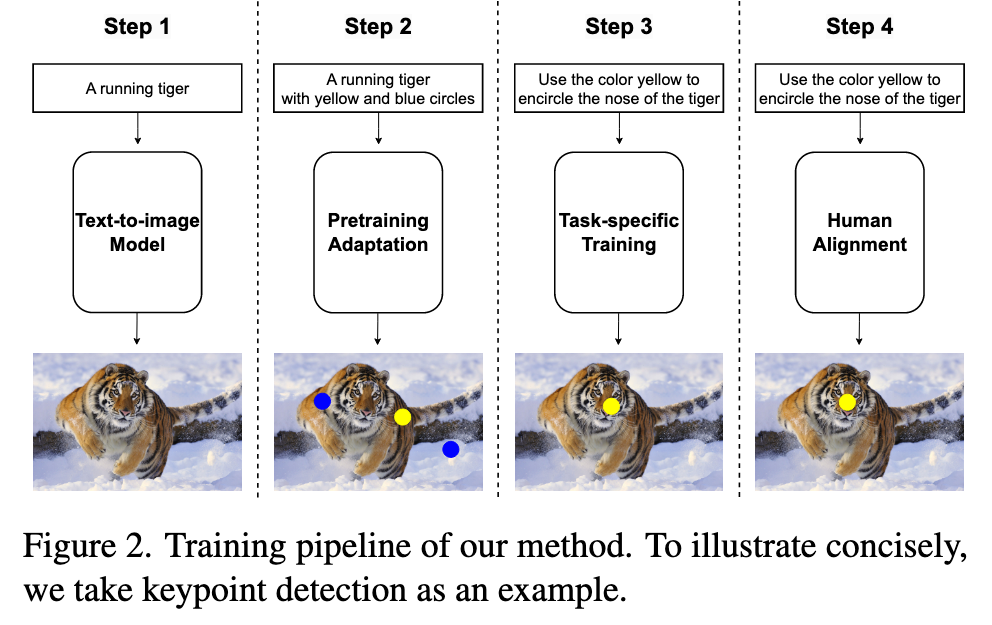
Our training procedure comprises three stages: pretraining adaptation, task-specific training, and instruction tuning. (p. 5)
Pretraining adaptation
However, our desired images might encompass segmentation masks or keypoint indicators, which substantially deviate from typical natural images. Consequently, our preliminary phase involves fine-tuning the stable diffusion model and adjusting the diffusion output distribution. (p. 5)
Since we require diffusion models to be capable of generating images “with a foreground mask” or “with some special mark”, we employ existing segmentation or keypoint detection datasets to produce such data. The remaining challenge lies in the development of suitable captions that accurately depict these images while maintaining the intrinsic text-to-image generation capability. This is achieved by augmenting the original image caption with a suffix, such as ”with a few different color patches here and there” or ”surrounded with a red circle.” By fine-tuning the diffusion model with these modified image captions, we can theoretically empower the model to generate any images within the desired output domain. (p. 5)
Task-specific training
In the second stage, our goal is to further fine-tune the diffusion model, enhancing its comprehension of various instructions for different tasks. We follow InstructPix2Pix [6] and inject source images by concatenating them with the noise input, subsequently expanding the input channels of the first layer. (p. 5)
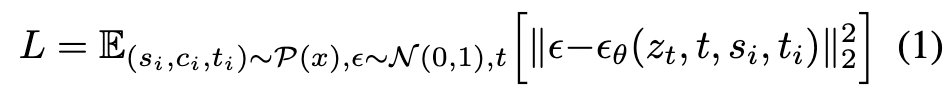
Human alignment
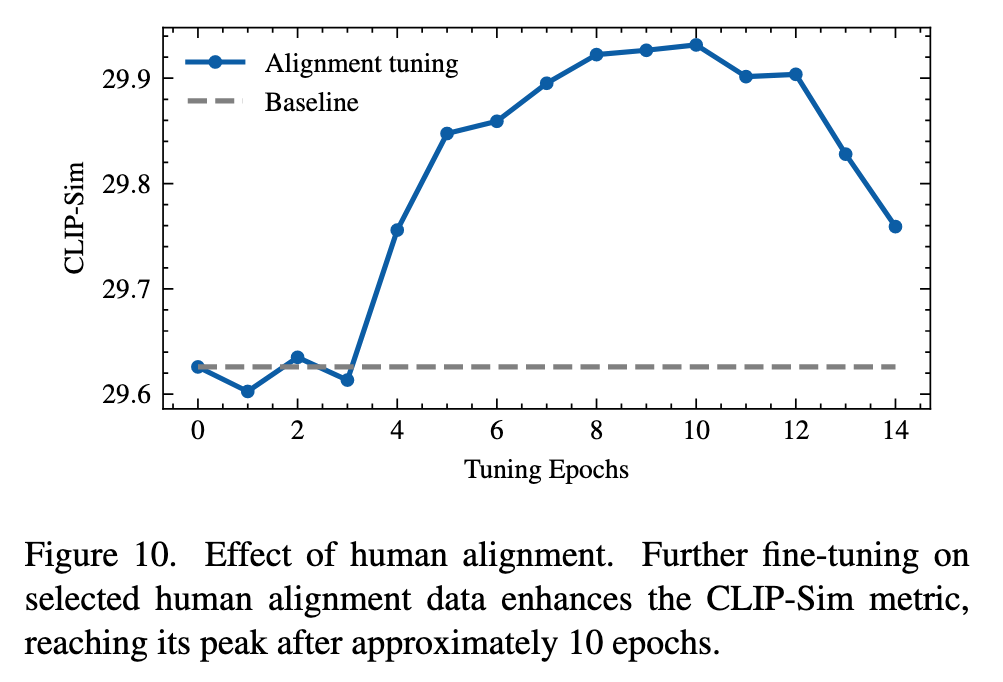
To further improve the quality of editing, we have followed the idea of instruction tuning [81] from Large Language Models. In LLM literature, instruction tuning [81] is used to teach the model to solve a task following the instruction. However, we conduct instruction tuning differently from that in LLM. For each sample in the benchmark, we generate different editing results using 20 different sampling classifier-free guidance [23]. Then, we ask subjects to select the best 0-2 edited images to formulate the instruction-tuning dataset. The whole dataset contains 1, 000 images. We use this dataset to further fine-tune our model for about 10 epochs. (p. 6)
Experiment
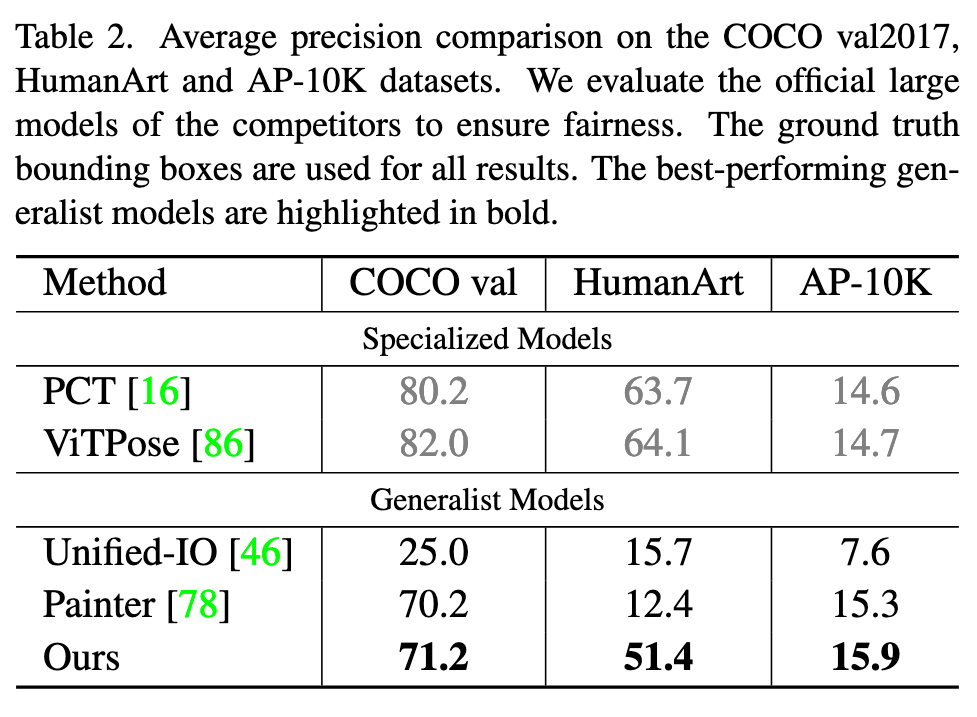

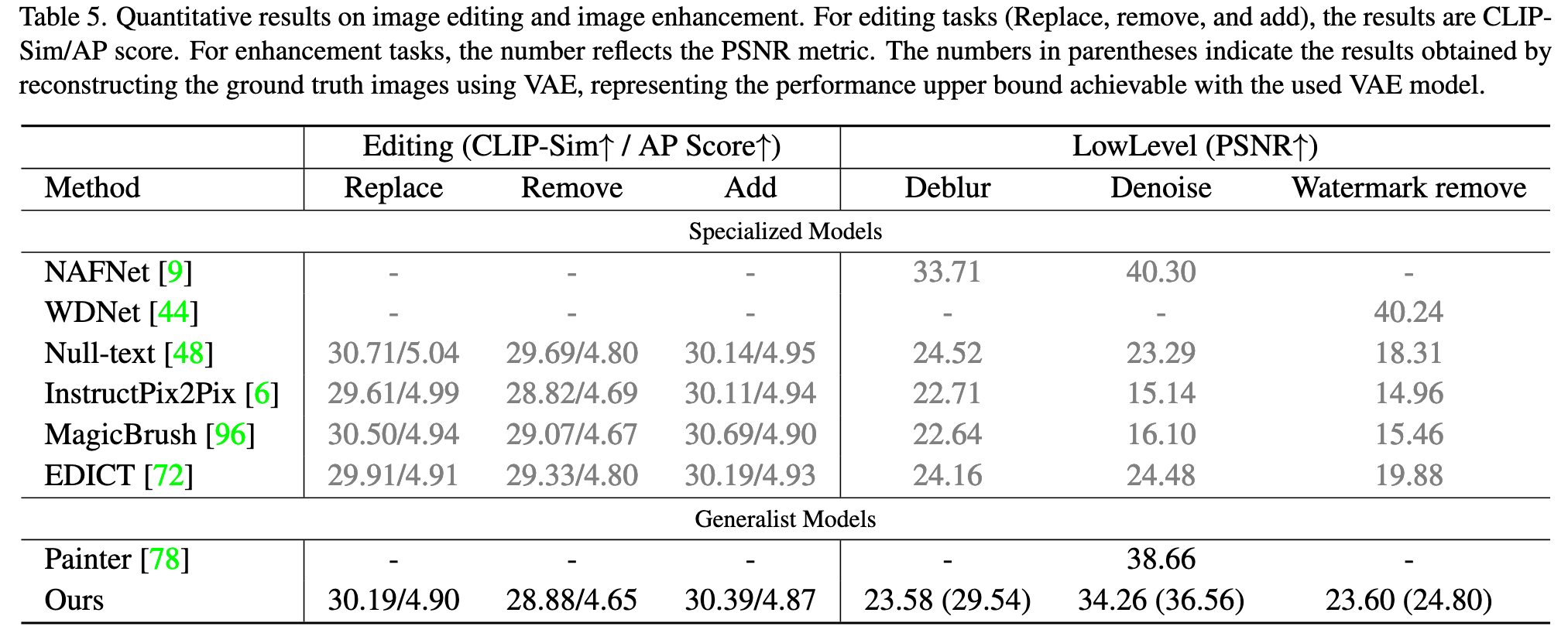

Ablation Study
The Benefit of Highly Detailed Instruction
Unlike previous unified models like Pix2seq [10] and Unified-IO [46], which simply treat natural language as task indicators, our approach employs detailed descriptions for each task as instructions. Such detailed instructions enable the model to understand comprehensively and then prioritize accurate execution instead of simple instructions that favor mimicking. (p. 10)
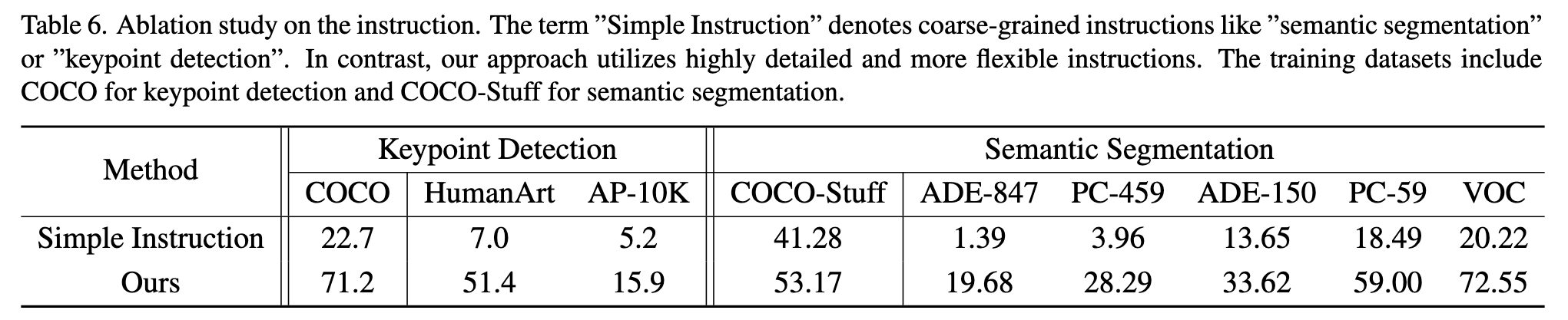
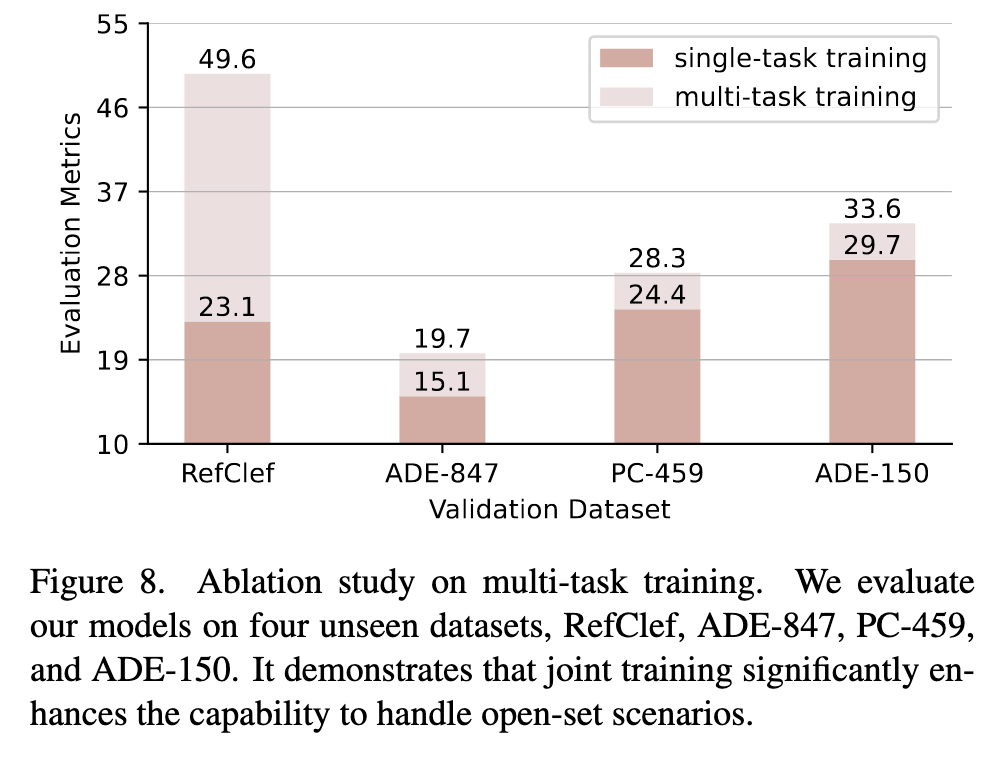
The Benefit of Multi-task Training
It is evident that our jointly trained model performs significantly better in open-domain testing scenarios compared to the specific models. (p. 11)

The Benefit of Human Alignment
Generalization Capability to Unseen Tasks
