InternVideo General Video Foundation Models via Generative and Discriminative Learning
[multimodal video deep-learning constrast-loss transformer encoder-decoder masked-video-prediction intern-video This is my reading note for InternVideo: General Video Foundation Models via Generative and Discriminative Learning. This paper propose to train a multi-modality model for video by utilizes both masked video prediction and contrast loss. However, this paper uses a encoder-decoder for masked video prediction and the other video encoder for contrast loss
Introduction
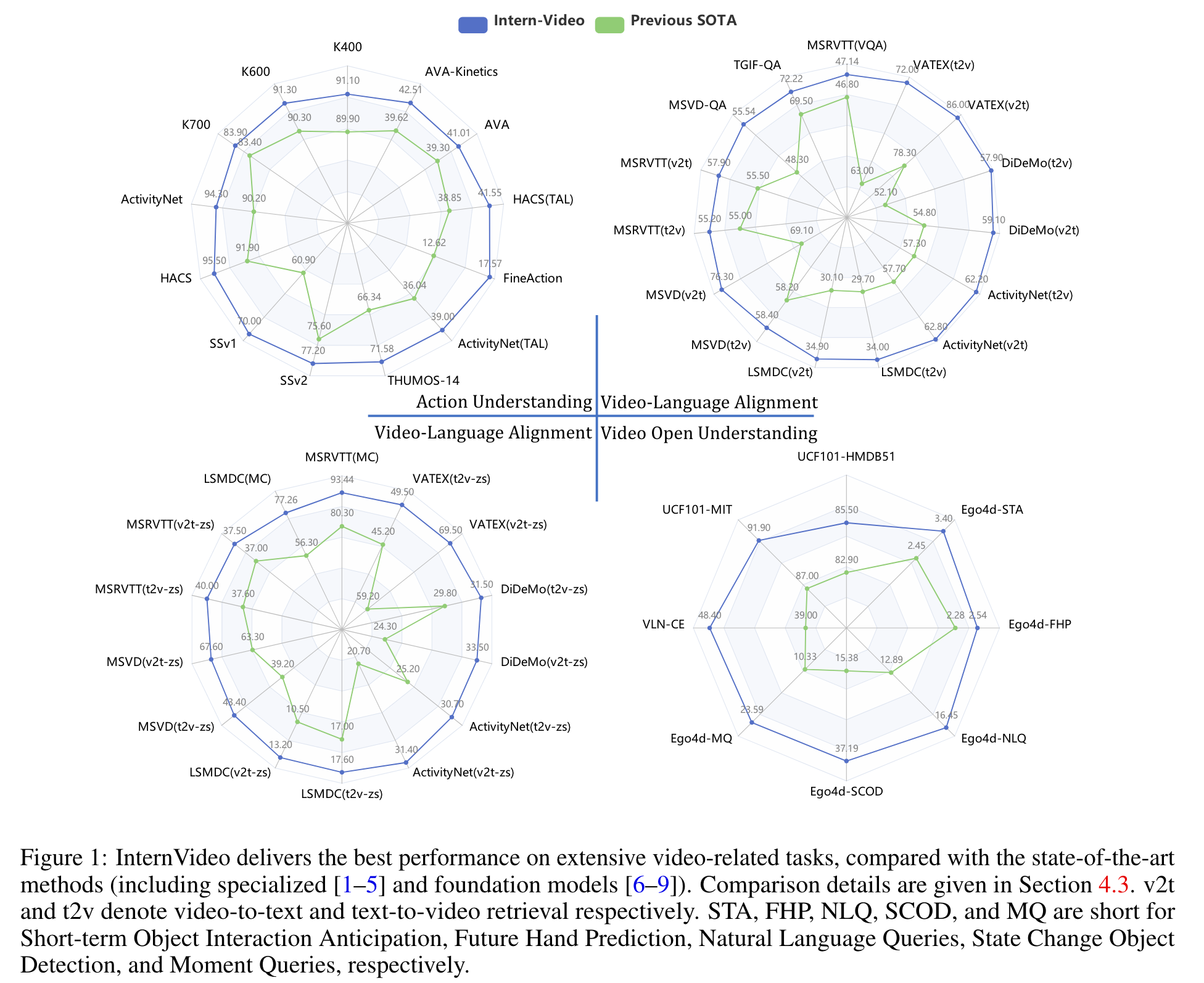
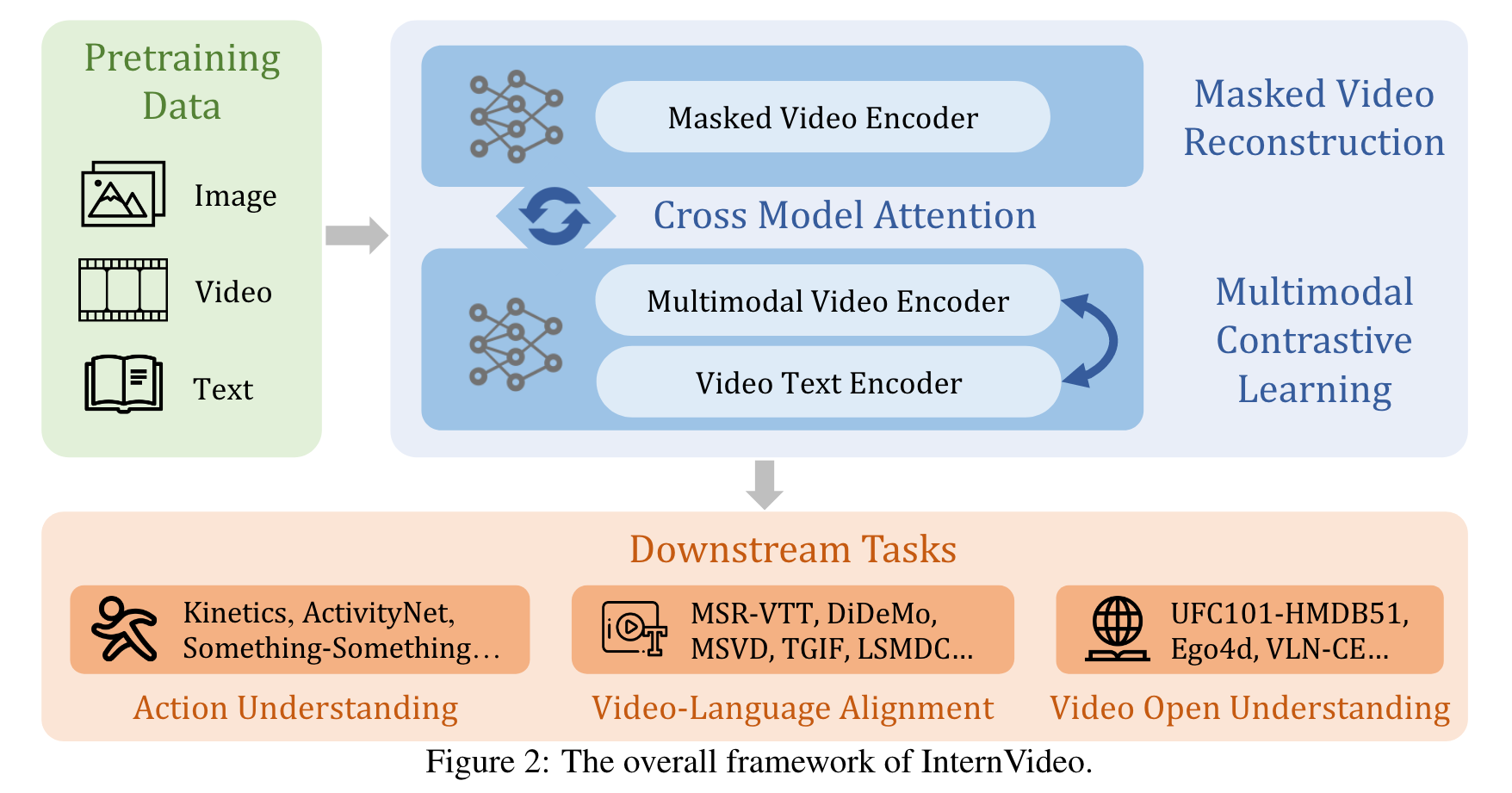
To fill the gap, we present general video foundation models, InternVideo, by taking advantage of both generative and discriminative self-supervised video learning. Specifically, In- ternVideo efficiently explores masked video modeling and video-language contrastive learning as the pretraining objectives, and selectively coordinates video representations of these two comple- mentary frameworks in a learnable manner to boost various video applications. (p. 2)
Proposed Method
In structure, InternVideo adopts the vision transformer (ViT) [28] and its variant UniformerV2 [56], along with extra local spatiotemporal modeling modules for multi-level representation interaction. (p. 4)
Self-Supervised Video Pretraining
According to [13, 23], video masked modeling produces features that excel at action discrimination, e.g., action recognition and temporal action localization, and video-language contrastive learning is able to understand videos with semantics from text without annotations. We employ two transformers with different structures for better leveraging these two optimization targets. (p. 5)
Video Masked Modeling
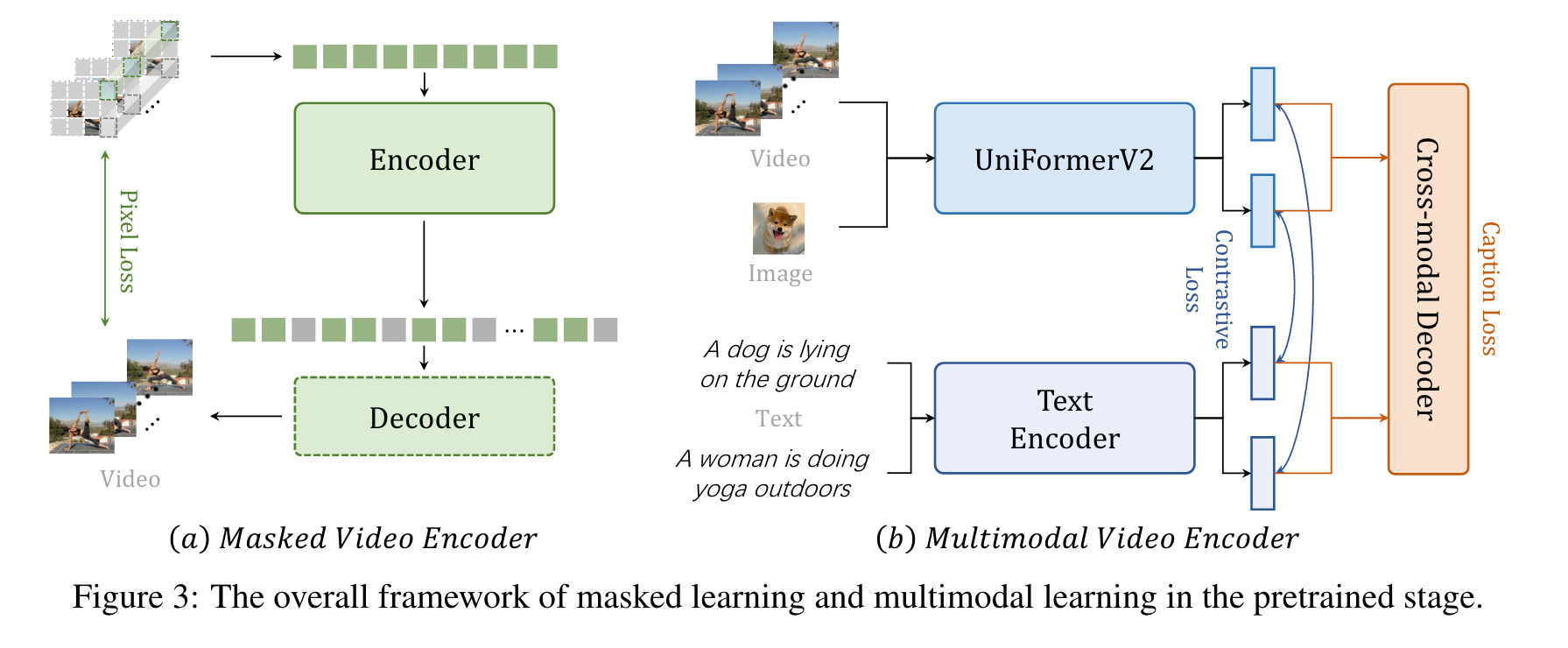
VideoMAE conducts a video reconstruction task with highly masked video inputs, using an asymmetric encoder-decoder architecture. The used encoder and decoder are both ViTs. The channel number of the decoder is half of that of the encoder, with 4 blocks by default. Specifically, we divide the temporal strided downsampled video inputs into non-overlapping 3D patches and project them linearly into cube embeddings. Then we apply tube masking with notably high ratios (e.g. 90%) to these embeddings and input them into the asymmetric encoder-decoder architecture to perform the masked video modeling pretraining. To characterize spatiotemporal interaction globally, we employ joint space-time attention [58, 59] in ViT, making all visible tokens globally interact with each other. It is computationally tractable as only a few tokens are preserved for calculation. (p. 5)
Video-Language Contrastive Learning
We conduct both video/image-text contrastive learning and video captioning tasks for pretraining, as given in Figure 3 (b). For training efficiency, we build our multimodal structure based on the pretrained CLIP [13]. Instead of directly employing a vanilla ViT, we use our proposed UniformerV2 [56] as the video encoder for better and more efficient temporal modeling. Moreover, we adopt an extra transformer decoder for cross-modal learning. First, video and text are separately encoded. Then a contrastive loss is utilized to align the embedding space of video and text features. In the fusing stage, we apply a caption decoder as a cross-modality fuser, which uses cross attention for a captioning pretext. This align-before-fuse paradigm not only ensures the modalities can be aligned into the same single embedding space, which is beneficial for tasks like retrieval but also gifts the model with the ability to combine different modalities and can be beneficial for tasks like question answering. The introduction of a caption decoder both extends the potential of the original CLIP and improves the robustness of multimodality features. (p. 5)
Cross-Model Interaction
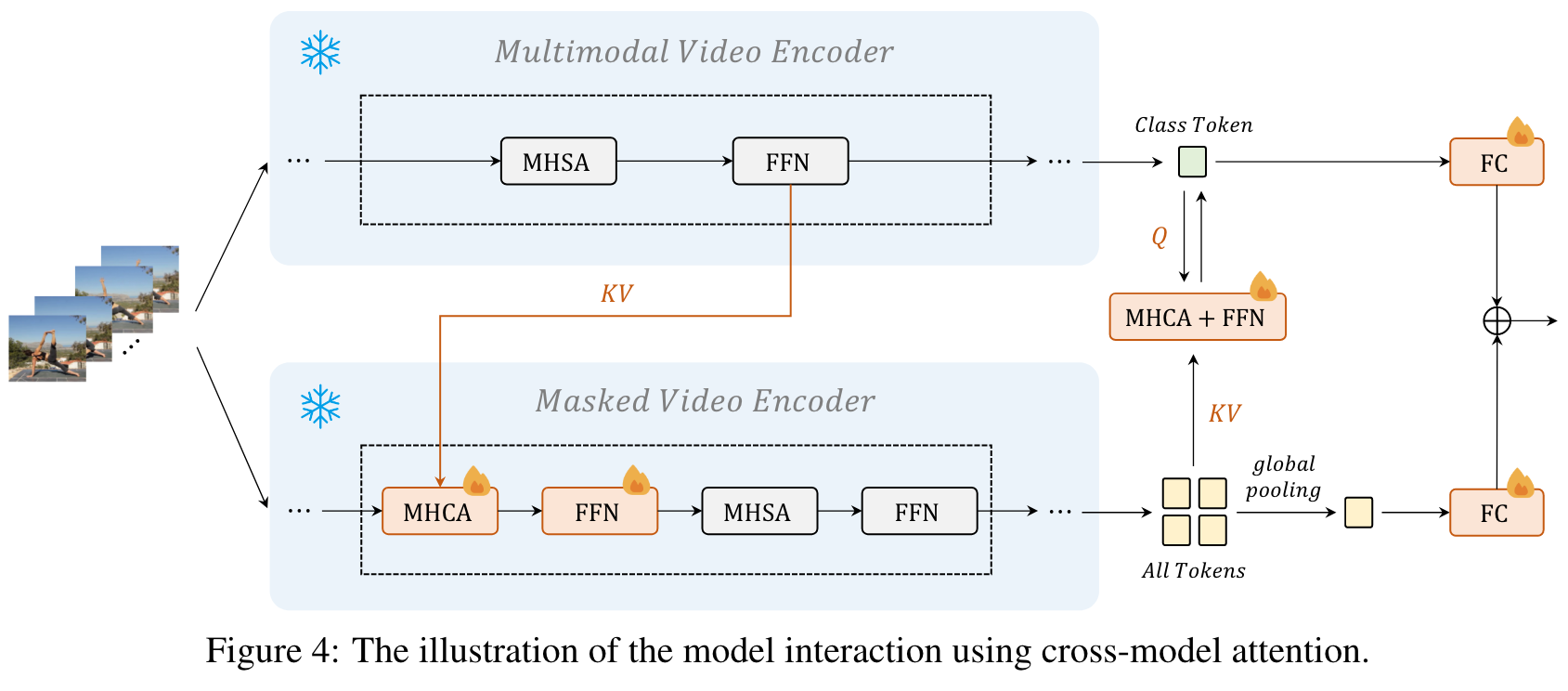
To learn a unified video representation based on both video masked modeling and video-language contrastive learning, we conduct cross-representation learning with added cross-model attention modules, as shown in Figure 4. Regarding optimizing both models at the same time is computing-intensive, we freeze both backbones except the classification layers and the query tokens in the multimodal video encoder, only updating newly added components. (p. 7)
Experiment
Limitations: Its devise can hardly process long-term video tasks, as well as high-order ones, e.g. anticipating plots from the seen parts of a movie (p. 13)