Tag: video
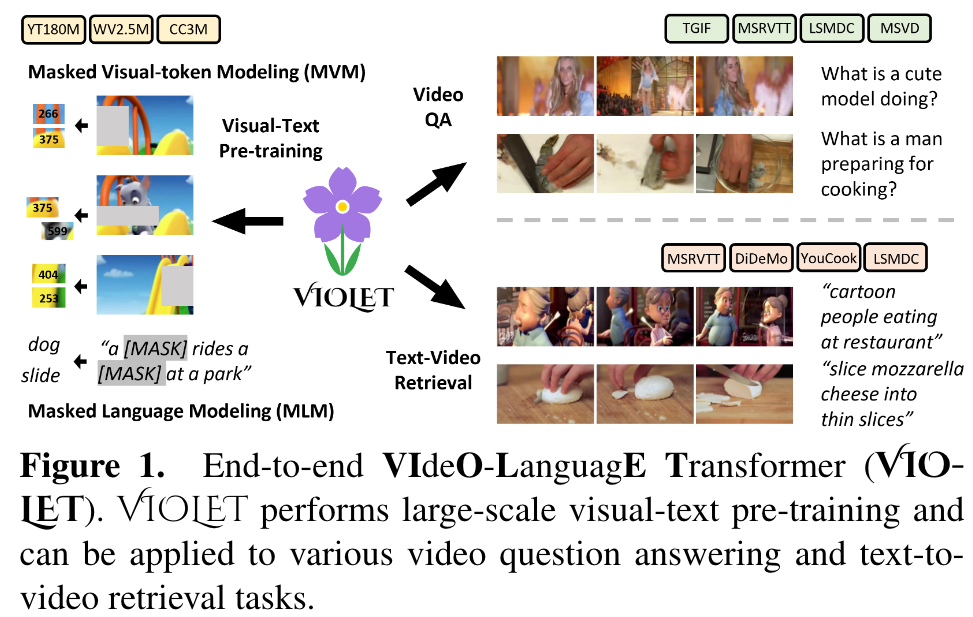
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Florence A New Foundation Model for Computer Vision (24 Oct 2023)
This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
- Video-ChatGPT Towards Detailed Video Understanding via Large Vision and Language Models (26 Sep 2023)
This is my reading note for ideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. The paper extends chatGPT to understand the video. It’s based on LLAVA and CLIP. One of the key contribution is that is spatially and temporal pool the per frame visual feature from the clip visual encoder and finally concatenate them as features a video.
- VideoChat Chat-Centric Video Understanding (25 Sep 2023)
This is my reading note for VideoChat: Chat-Centric Video Understanding. The papers extends chatGPT to understand the video. To this end.it develops a video backbone based on BLIP2
- MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks (24 Sep 2023)
This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.
- Rerender A Video Zero-Shot Text-Guided Video-to-Video Translation (18 Sep 2023)
This is my reading note on Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation. The paper proposes a method to edit a video given style mentioned in prompt. The method performed diffusion to edit key frames and then propagate the edited key frames to other frames using optical flow. For key frame editing, several attention based constraint is applied to reserve details and consistency, including shape aware, style aware, pixel aware and fidelity aware.
- InternVideo General Video Foundation Models via Generative and Discriminative Learning (06 Aug 2023)
This is my reading note for InternVideo: General Video Foundation Models via Generative and Discriminative Learning. This paper propose to train a multi-modality model for video by utilizes both masked video prediction and contrast loss. However, this paper uses a encoder-decoder for masked video prediction and the other video encoder for contrast loss
- X-CLIP End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval (04 Jul 2023)
This is my reading note for X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. This paper proposes a method on extending clip to video data. it mostly studied how to aggregate the similarity score from the frame level to video level.