Language Is Not All You Need Aligning Perception with Language Models
[llm multimodal deep-learning kosmos magneto xpos relative-position-encoding gpt flamingo This is my reading note for Language Is Not All You Need: Aligning Perception with Language Models. This paper proposes a multimodal LLM which feeds the visual signal as a sequence of embedding, then combines with text embedding and trains in a GPT like way.
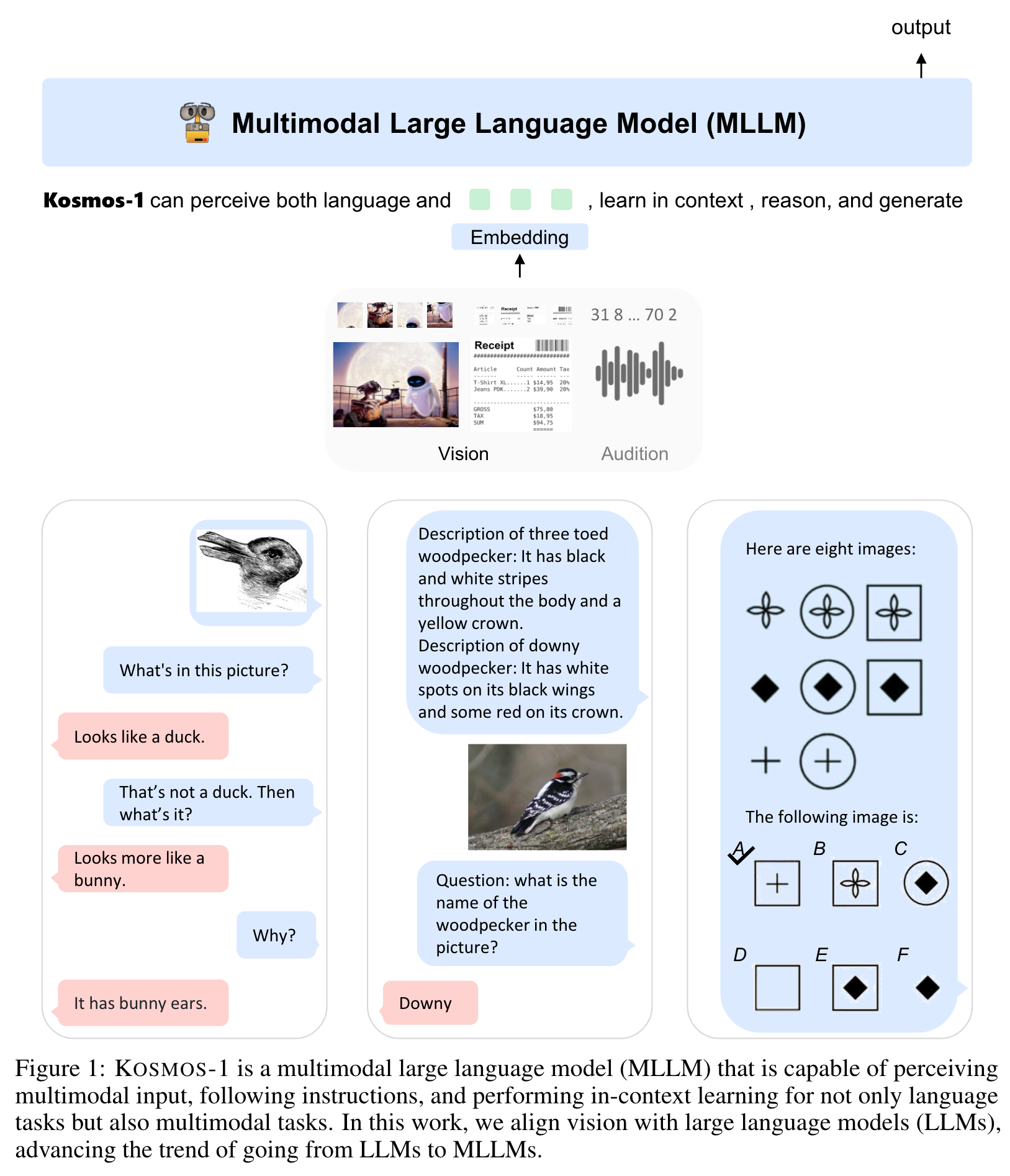
Introduction
Specifically, we train KOSMOS-1 from scratch on web-scale multi- modal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. The goal is to align perception with LLMs, so that the models are able to see and talk (p. 4)

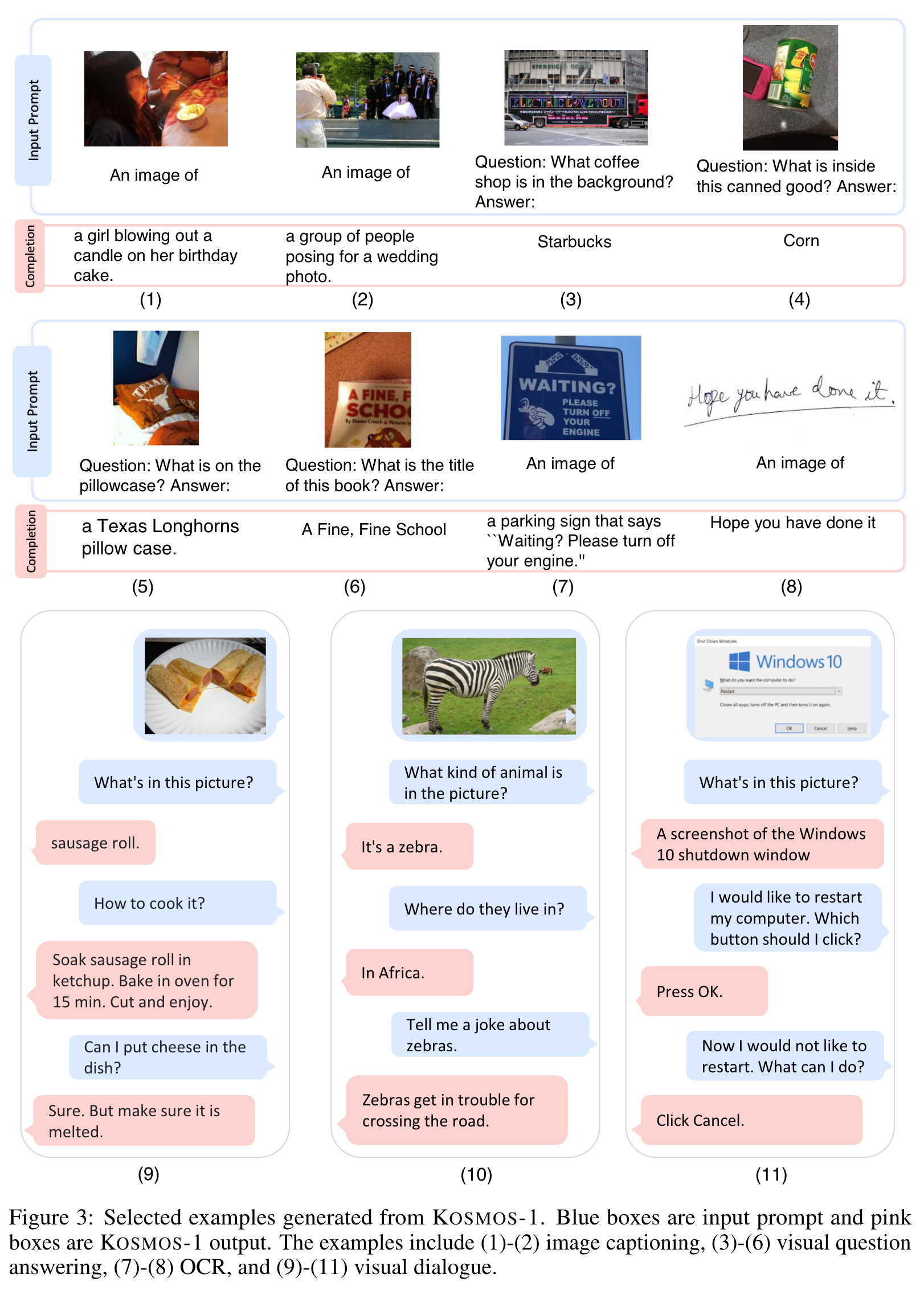
Proposed Method
As shown in Figure 1, KOSMOS-1 is a multimodal language model that can perceive general modalities, follow instructions, learn in context, and generate outputs. Given the previous context, the model learns to generate texts in an auto-regressive manner. Specifically, the backbone of KOSMOS-1 is a Transformer-based causal language model. Apart from text, other modalities are embedded and fed into the language model (p. 5)
Input Representation
The Transformer decoder perceives general modalities in a unified way. For input format, we flatten input as a sequence decorated with special tokens. Specifically, we use <s> and </s> to denote start- and end-of-sequence. The special tokens <image> and </image> indicate the beginning and end of encoded image embeddings. (p. 5)
Multimodal Large Language Models (MLLMs)
MAGNETO We use MAGNETO [WMH+22], a Transformer variant, as the backbone architecture. MAGNETO has better training stability and superior performance across modalities. It introduces an extra LayerNorm to each sublayer (i.e., multi-head self-attention, and feed-forward network). The method has a theoretically derived initialization method [WMD+22] to improve the optimization fundamentally, which allows us to effectively scale up the models without pain. (p. 6)
XPOS We employ XPOS [SDP+22] relative position encoding for better long-context modeling. The method can better generalize to different lengths, i.e., training on short while testing on longer sequences. Moreover, XPOS optimizes attention resolution so that the position information can be captured more precisely. The method XPOS is efficient and effective in both interpolation and extrapolation settings. (p. 6)
Training Objective
Moreover, cross-modal pairs and inter- leaved data learn to align the perception of general modalities with language models. (p. 6)
Model Training
We then extract the text and images from the HTML of each selected web page. For each document, we limit the number of images to five to reduce noise and redundancy. We also randomly discard half of the documents that only have one image to increase the diversity. (p. 7)
We freeze the parameters of the CLIP model except for the last layer during training. (p. 7)
In order to better align KOSMOS-1 with human instructions, we perform language-only instruction tuning [LHV+23, HSLS22]. Specifically, we continue-train the model with the instruction data in the format of (instructions, inputs, and outputs). The instruction data is language-only, which is mixed with training corpora. The tuning process is conducted as language modeling. Notice that instructions and inputs are not accounted for in the loss (p. 7)
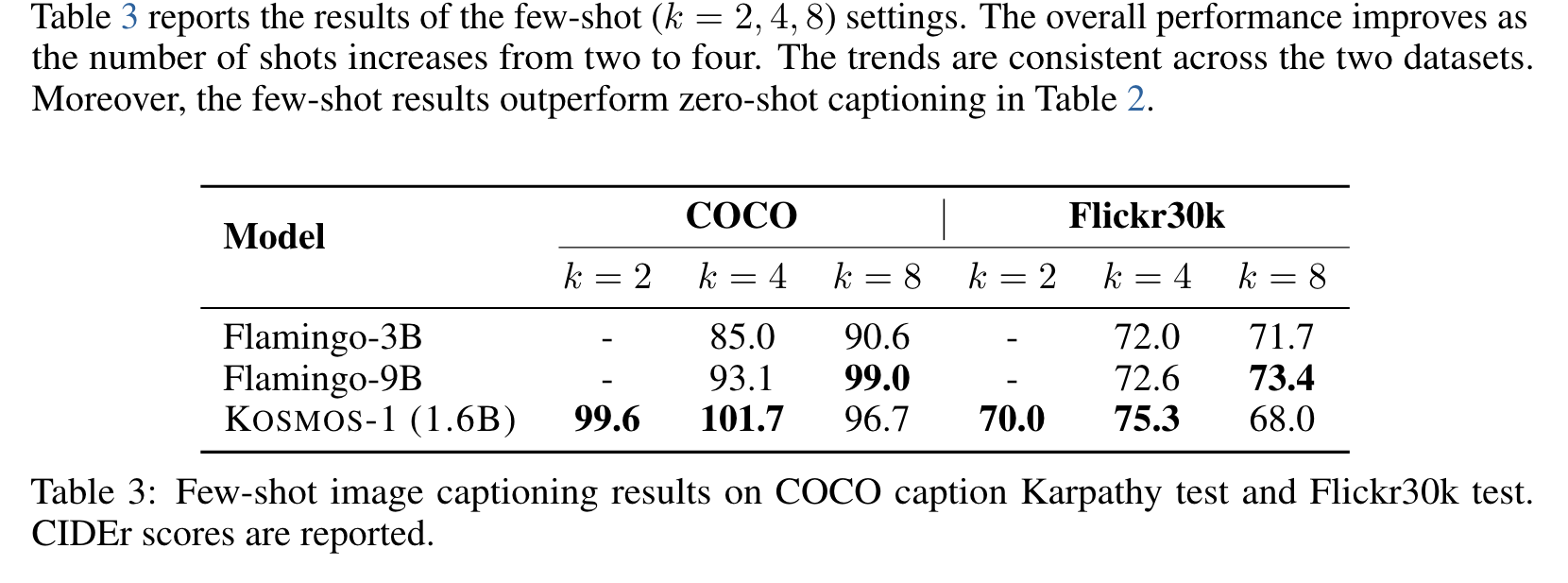
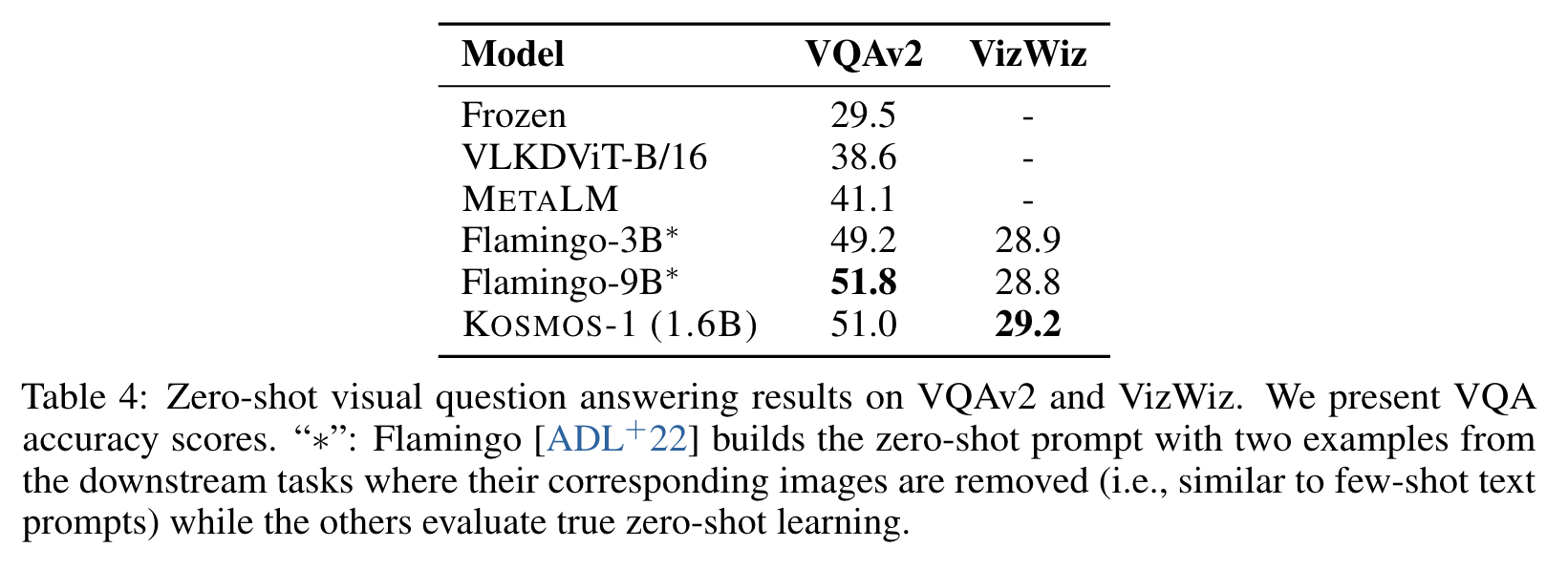
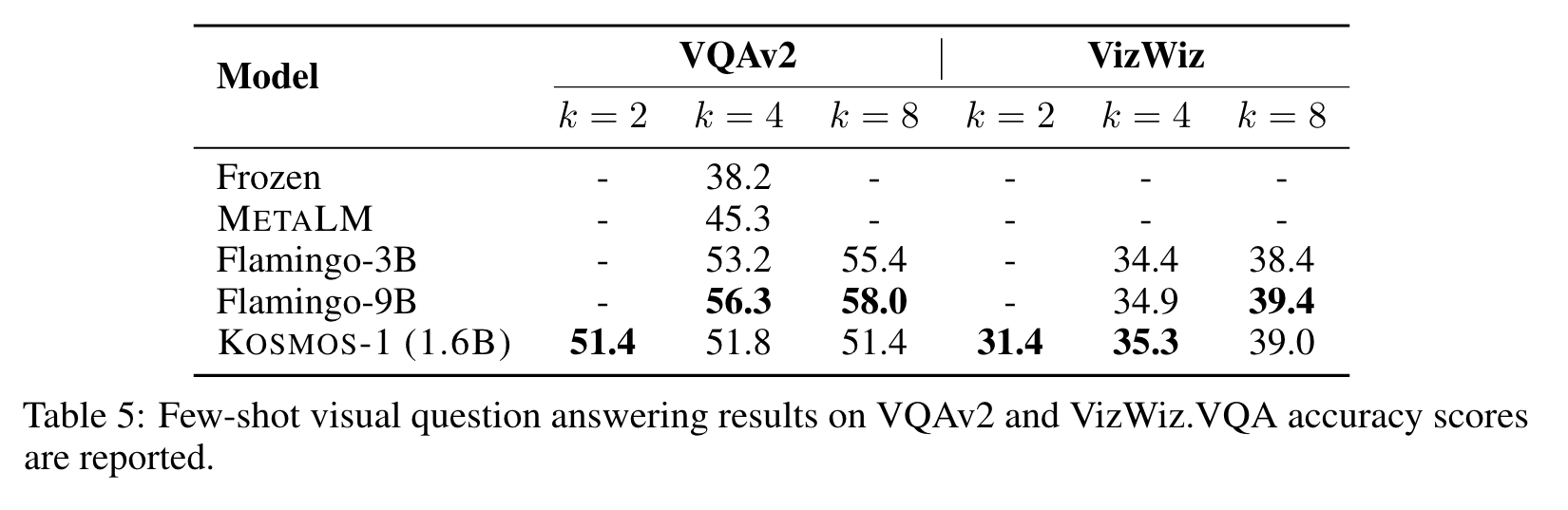
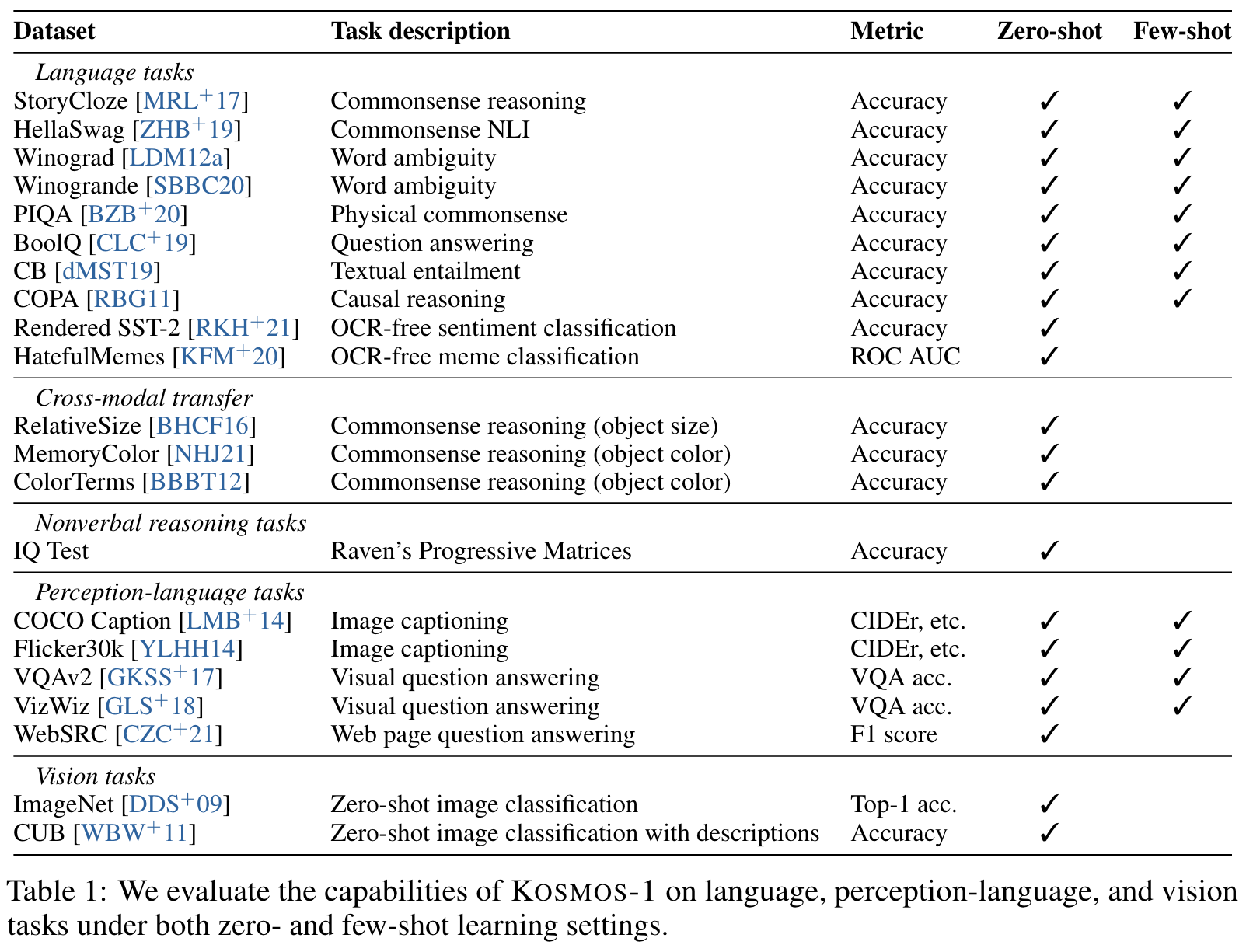
Experiment