Link-Context Learning for Multimodal LLMs
[multimodal llm deep-learning bad context This is my meeting note for Link-Context Learning for Multimodal LLMs. It presents a demo of how to use positive and negative example to tell L L m to recognize novel concept.
Introduction

Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to “learn to learn” from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes “reasoning from cause and effect” to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. (p. 1)
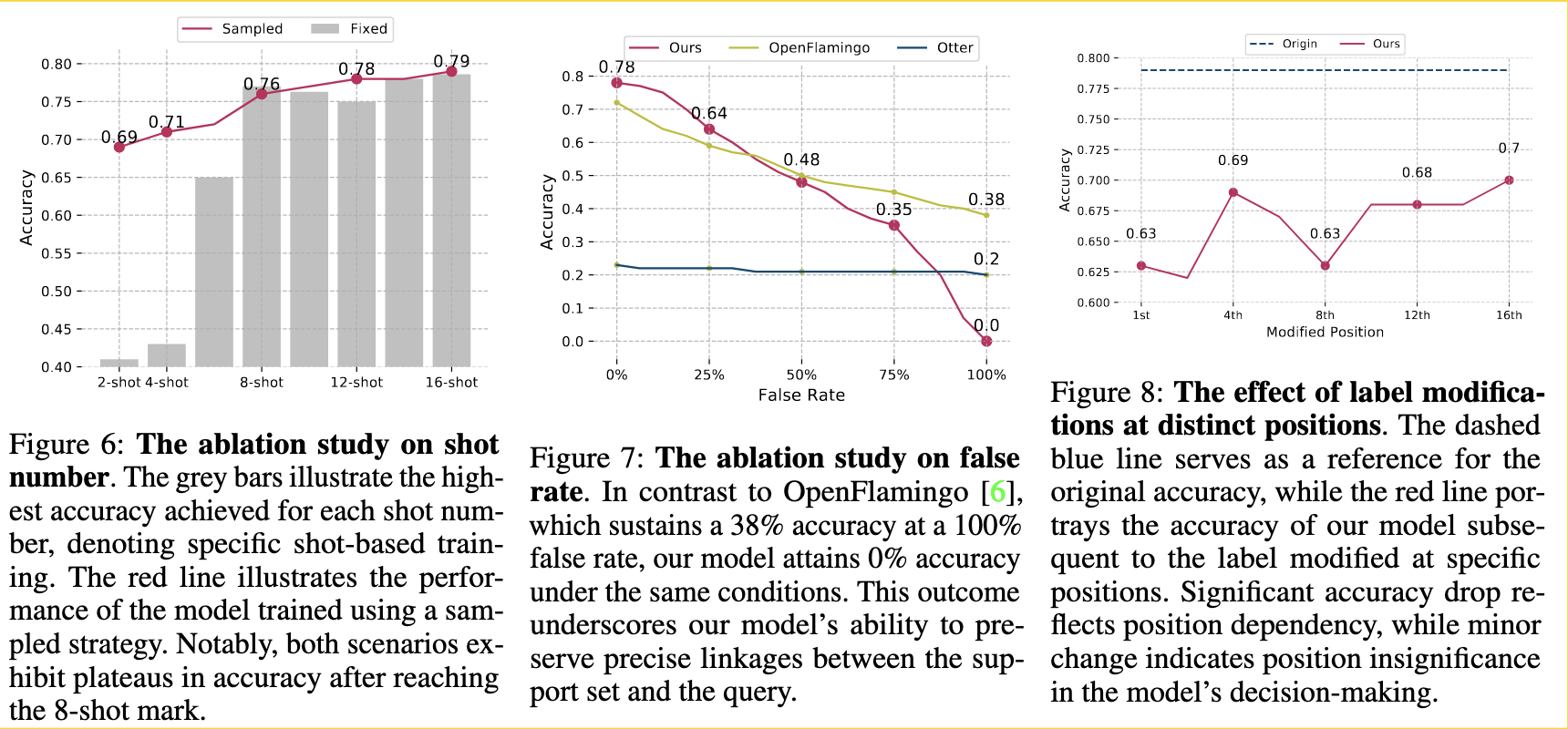
Current MLLMs fail to link the unseen image-label pairs to recognize novel objects in a single conversation. The primary method for MLLMs to learn from demonstrations is known as in-context learning, wherein the models show remarkable improvement on downstream tasks after being exposed to a few input-label pairs. However, the model’s performance is not affected even if the answers provided in the meta-tasks are all wrong. [1] Thus, what MLLMs have “learned” from demonstration remains on answering questions in a specific format rather than understanding the causal relationship between the image-label pairs. (p. 2)
Related Work
Multimodal Prompt Tuning Multimodal Prompt Tuning (M-PT) is commonly used in contrastive learning-based multimodal large models, such as CLIP [12]. In the training process, prompt tuning usually freezes most of the model’s parameters and only updates a small number of parameters to achieve results similar to fine-tuning [14–17]. PT [14] add tunable prompt embeddings to each layer of the encoder and decoder, only the weights of the added embeddings will be updated during training (p. 3)
Multimodal Instruction Tuning Multimodal Instruction Tuning (M-IT) enhances the zero-shot capability of MLLMs in unseen tasks by fine-tuning them on an instruction descriptions-based dataset (p. 3)
In the Multimodal In-Context Learning (M-ICL) settings, following the input image samples and optional instruction, MLLMs can learn new task patterns in a few-shot manner [29–32]. (p. 3)
In-Context Learning Formally, in-context learning [34] refers to: the model should choose the answer with the highest prediction score from a set candidate answers Y = {y1, y2, …, yn}, given a query input x, conditioning on a support set S, which consists of multiple inputlabel pairs from a wide variety of tasks, where S = {(x1, y1),(x2, y2), …,(xn, yn)}. (The query and the sample of S should belong to different tasks.) From another perspective, in-context learning could be denoted as training-free few-shot learning, as it transforms the training stage of few-shot learning into the demonstration input for Large Language Models. Noted that the ICL [34] is consistent with FSL, where the tasks in the demonstration (training) stage and in the inference (query) stage are different. (p. 3)
Link-Context Learning Essentially, link-context learning (LCL) represents a form of training-free and causal-linked few-shot learning. In this approach, a support set S = (x1, y1),(x2, y2), …,(xn, yn) is provided, along with a query sample x from the query set Q, where the data pairs from the support set are causally linked to the query set. The model is tasked with predicting the answer based on the causal-linked relationship between the query and support set. (p. 3)
Proposed Method
Training strategy of selecting samples:
- 2-way strategy: In this strategy, we train the MLLMs for binary image classification, where the C = {c1, c2}. To be more specific, c1 and c2 here represent the prototype of two classes. We denote the training class set as T = {t1, t2, …, t100}, we randomly sample a class ti as the positive class, where its neighbor class set Nti = {nti1 , nti2 , …, nti 100} (nti1 is the most similar class to ti, while the nti 100 is the least). Then we apply a hard-negative mining strategy, where we sample the negative class ntij from Nti with a probability pj = P 101−j 100 m=1 m . Noted that this setting is fixed to train on 16 shots.
- 2-way-random strategy: In this strategy, we first train the MLLMs on fixed-16 shots following the [2-way] strategy, then further train the model with shots averaged sampled from 2-16 shots for 10 epochs.
- 2-way-weight strategy: Within this strategy, we initially train the MLLMs using a fixed-16 shot regimen, adhering to the [2-way] approach. Subsequently, we refine the model by additional training with shots sampled from the range of 2-16, with each shot’s probability denoted as pj = ej P16m=2 em .
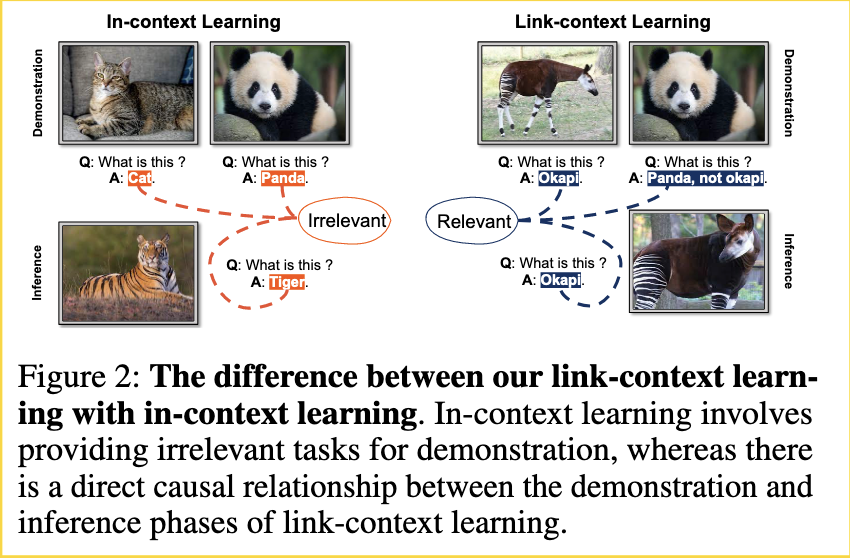
- mix strategy: To enhance the model’s generalizability, we undertake a fine-tuning process that involves both [2-way] tasks and Shikra’s [27] original tasks. During each iteration, the training samples are evenly sampled from both the [2way] tasks and the original tasks. This balanced approach ensures that the model gains proficiency in both the newly introduced link-context learning tasks and the pre-existing tasks from Shikra [27]. (p. 4)
Experiment Result