Localizing and Editing Knowledge in Text-to-Image Generative Models
[diffusion deep-learning image2image text2image personalize stable-diffusion diff-quick-fix This is my reading note for Localizing and Editing Knowledge in Text-to-Image Generative Models. This paper studied how each component of diffusion model contribute to the final result: only that self attention layer of last tokens contribute to the final result. Then it proposes a simple method to perform image editing by modifying that layer.
Introduction
In particular, we show that unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes (e.g., style / objects). Remarkably, we find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers. (p. 1)
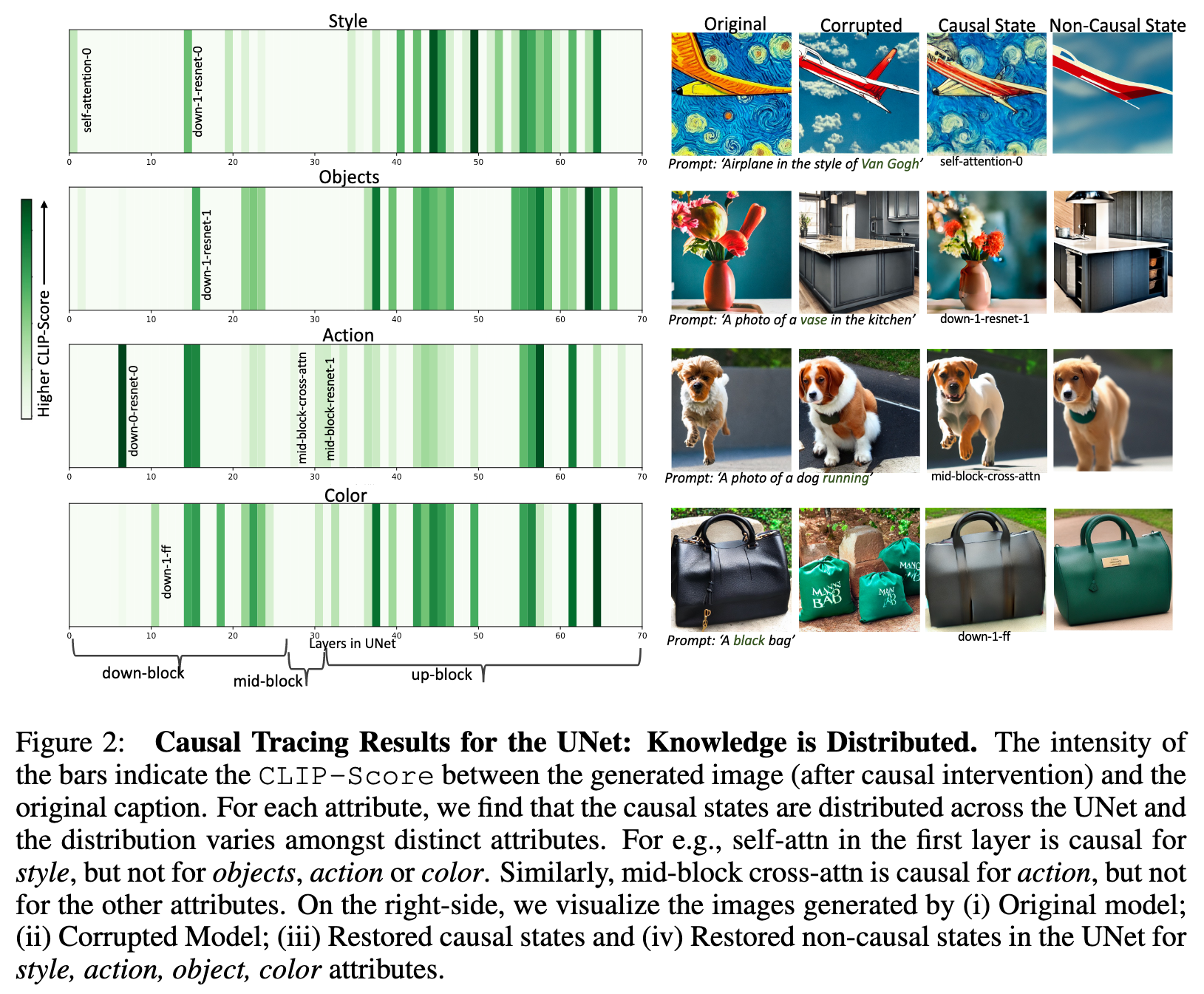
Based on this observation of only one causal state in the text-encoder, we introduce a fast, data-free model editing method DIFF-QUICKFIX which can effectively edit concepts (remove or update knowledge) in text-to-image models. DIFF-QUICKFIX can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning based editing methods. (p. 1)
This attribute-specific information is usually specified in the conditioning textual prompt to the UNet in text-to-image models which is used to pull relevant knowledge from the UNet to construct and subsequently generate an image. This leads to an important question: How and where is knowledge corresponding to various visual attributes stored in text-to-image models? (p. 2)
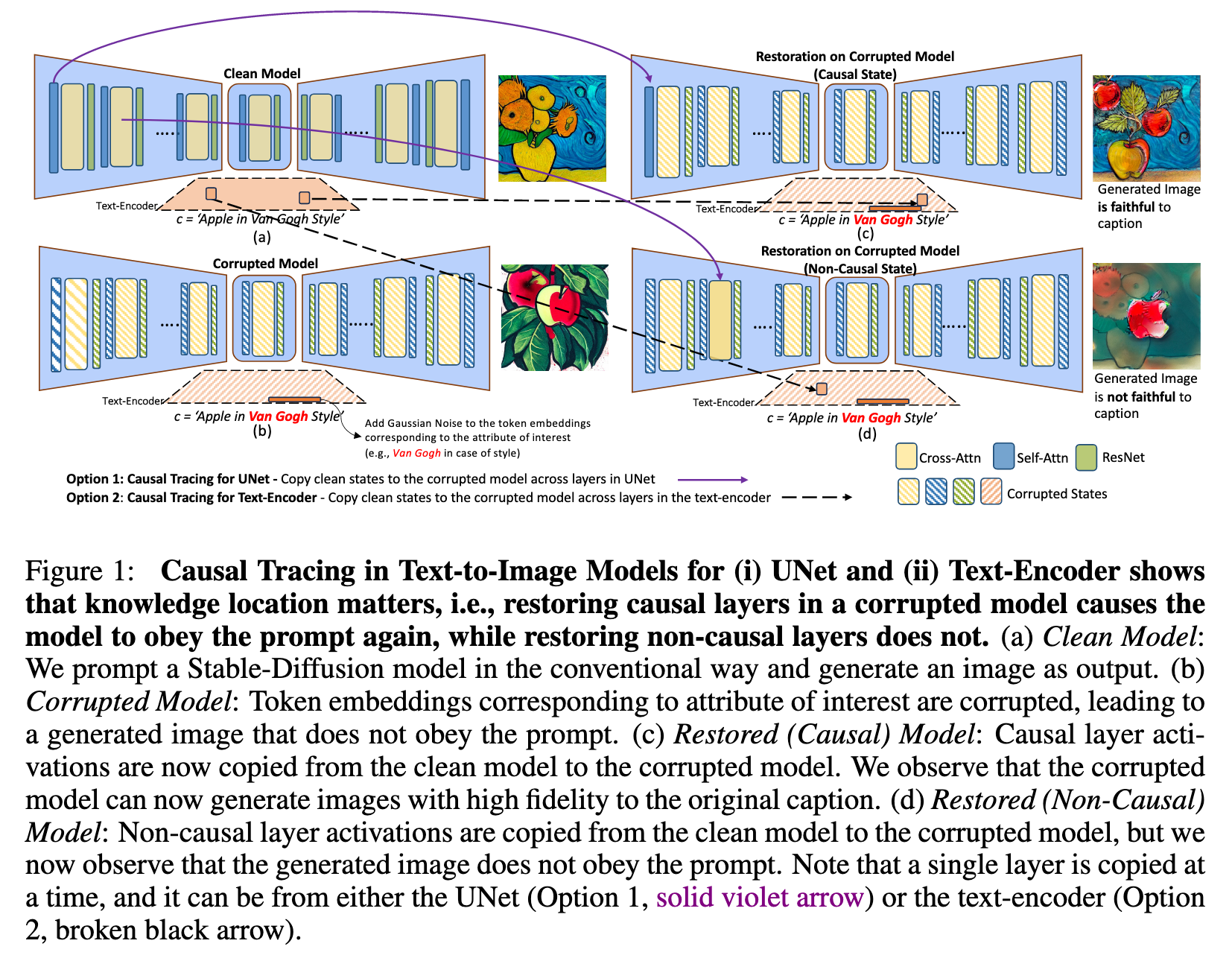
However, each of these components store attribute information with a different efficacy and often different attributes have a distinct set of causal components where knowledge is stored. For e.g., for style – we find that the first self-attention layer in the UNet stores style related knowledge, however it is not causally important for other attributes such as objects, viewpoint or action. To our surprise, we specifically find that the cross-attention layers are not causally important states and a significant amount of knowledge is in fact stored in components such as the ResNet blocks and the self-attention blocks. (p. 2)
Remarkably, in the text-encoder, we find that knowledge corresponding to distinct attributes is strongly localized, contrary to the UNet. However unlike generative language models (Meng et al., 2023) where the mid MLP layers are causal states, we find that the first self-attention layer is causal in the CLIP based text-encoders of public text-to-image generative models (e.g., Stable-Diffusion). (p. 2)
Identification of local causal states in a given model has a crucial benefit: it allows for incorporating controlled edits to the model by updating only a tiny fraction of the model parameters without any fine-tuning. Using our observation that the text-encoder hosts only one localized causal state, we introduce a new data-free and fast model editing method DIFF-QUICKFIX which can edit concepts in text-to-image models effectively using a closed-form update. In particular, we show that DIFF-QUICKFIX can (i) remove copyrighted styles, (ii) trademarked objects as well as (iii) update stale knowledge 1000x faster than existing fine-tuning based editing methods such as (Kumari et al., 2023; Gandikota et al., 2023a) with comparable or even better performance in some cases. (p. 3)
CAUSAL TRACING FOR TEXT-TO-IMAGE GENERATIVE MODELS
ADAPTING CAUSAL TRACING FOR TEXT-TO-IMAGE DIFFUSION MODELS
Causal Mediation Analysis (Pearl, 2013; Vig et al., 2020) is a method from causal inference that studies the change in a response variable following an intervention on intermediate variables of interest (mediators). One can think of the internal model components (e.g., specific neurons or layer activations) as mediators along a directed acyclic graph between the input and output. For textto-image diffusion models, we use Causal Mediation Analysis to trace the causal effects of these internal model components within the UNet and the text-encoder which contributes towards the generation of images with specific visual attributes (e.g., objects, style). (p. 4)
Where is Causal Tracing Performed? We identify the causal model components in both the UNet ϵθ and the text-encoder vγ. For ϵθ, we perform the causal tracing at the granularity of layers, whereas for the text-encoder, causal tracing is performed at the granularity of hidden states of the token embeddings in c across distinct layers. T (p. 4)
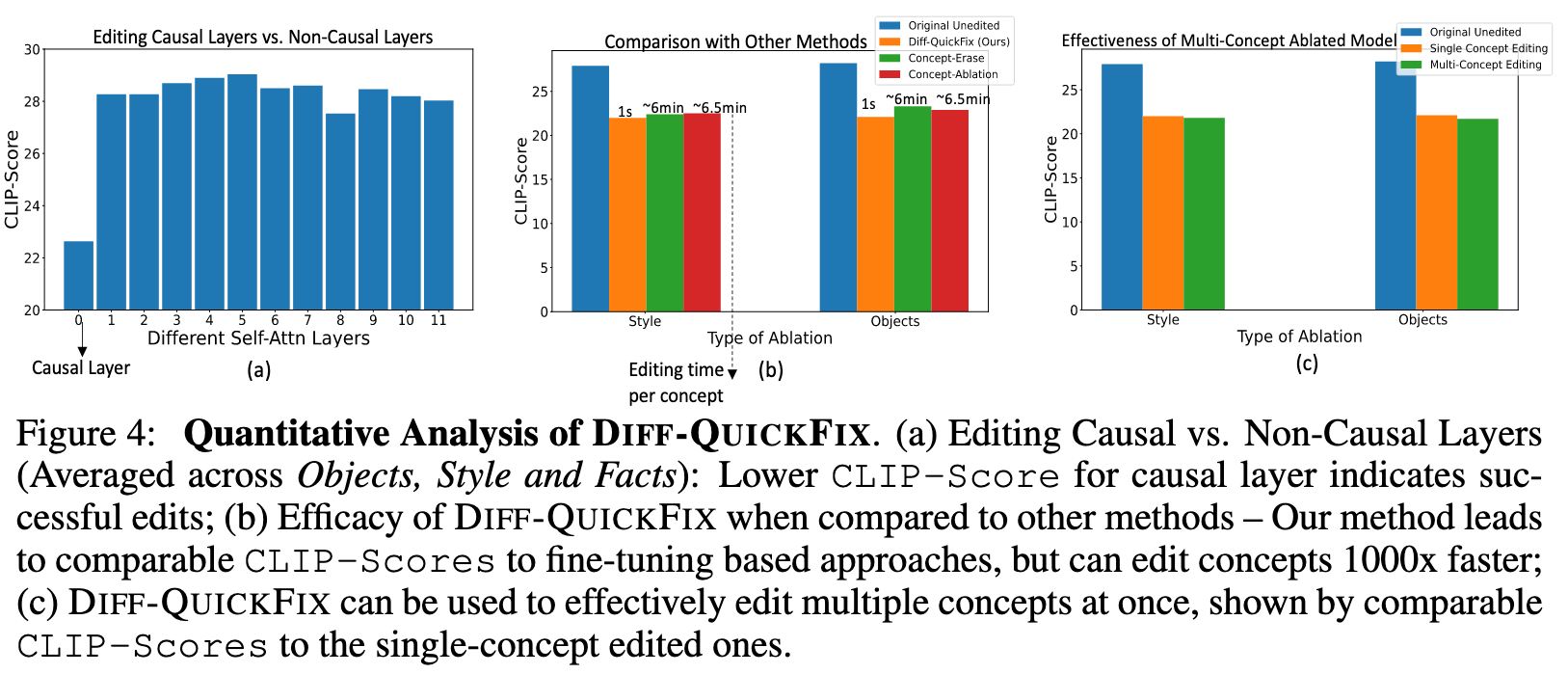
TRACING KNOWLEDGE IN UNET
To perform causal tracing on the UNet ϵ_θ (see Fig 1 for visualization), we perform a sequence of operations that is somewhat analogous to earlier work from (Meng et al., 2023) which investigated knowledge-tracing in large language models. We consider three types of model configurations:
- a clean model ϵθ, where classifier-free guidance is used as default;
- a corrupted model ϵ^{corr}_θ , where the word embedding of the subject (e.g., Van Gogh) of a given attribute (e.g., style) corresponding to a caption c is corrupted with Gaussian Noise; and,
- a restored model ϵrestored θ , which is similar to ϵ^{corr}_θ except that one of its layers is restored from the clean model at each time-step of the classifier-free guidance. We run classifier-free guidance to obtain the combined score estimate: (p. 5)
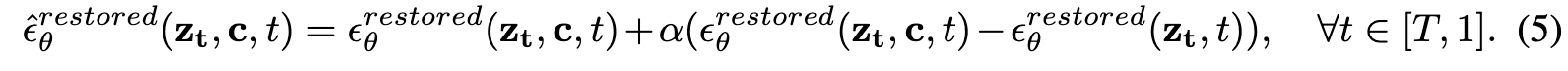{kind=link}
TRACING KNOWLEDGE IN THE TEXT-ENCODER
!
DIFF-QUICKFIX: FAST MODEL EDITING FOR TEXT-TO-IMAGE MODELS
we design a fast, data-free model editing method leveraging our interpretability observations in Section 4, where we find that there exists only one causal state (the very first self-attention layer) in the text-encoder for Stable-Diffusion. (p. 7)
DIFF-QUICKFIX specifically updates this W_out matrix by collecting caption pairs (c_k, c_v) where c_k (key) is the original caption and c_v (value) is the caption to which c_k is mapped. For e.g., to remove the style of ‘Van Gogh’, we set c_k = ‘Van Gogh’ and c_v = ‘Painting’. In particular, to update W_out, we solve the following optimization problem: (p. 8)
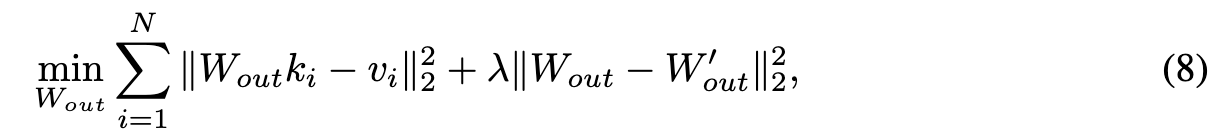
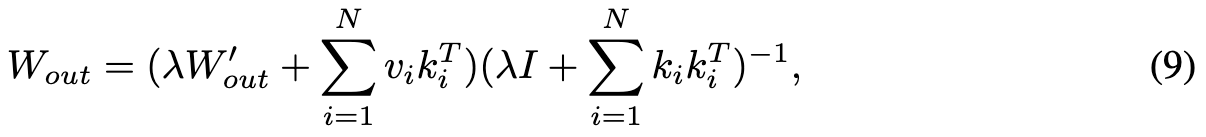
Experiment