LongLoRA Efficient Fine-tuning of Long-Context Large Language Models
[attention group lora low-rank llm shift-short-attention sparse longnet deep-learning s2-attn transformer longmem This is my reading note on LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models. The paper proposes a method to fine tune a pretrained LLM to handle long context. To this end, it divide the data into different groups and performed attention within group; for half of heads, it shift the groups by half to enable attention across the groups.
Introduction
We present LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost. In this paper, we speed up the context extension of LLMs in two aspects. On the one hand, although dense global attention is needed during inference, fine- tuning the model can be effectively and efficiently done by sparse local attention. The proposed shift short attention (S2-Attn) effectively enables context extension, leading to non-trivial computation saving with similar performance to fine-tuning with vanilla attention (p. 1)
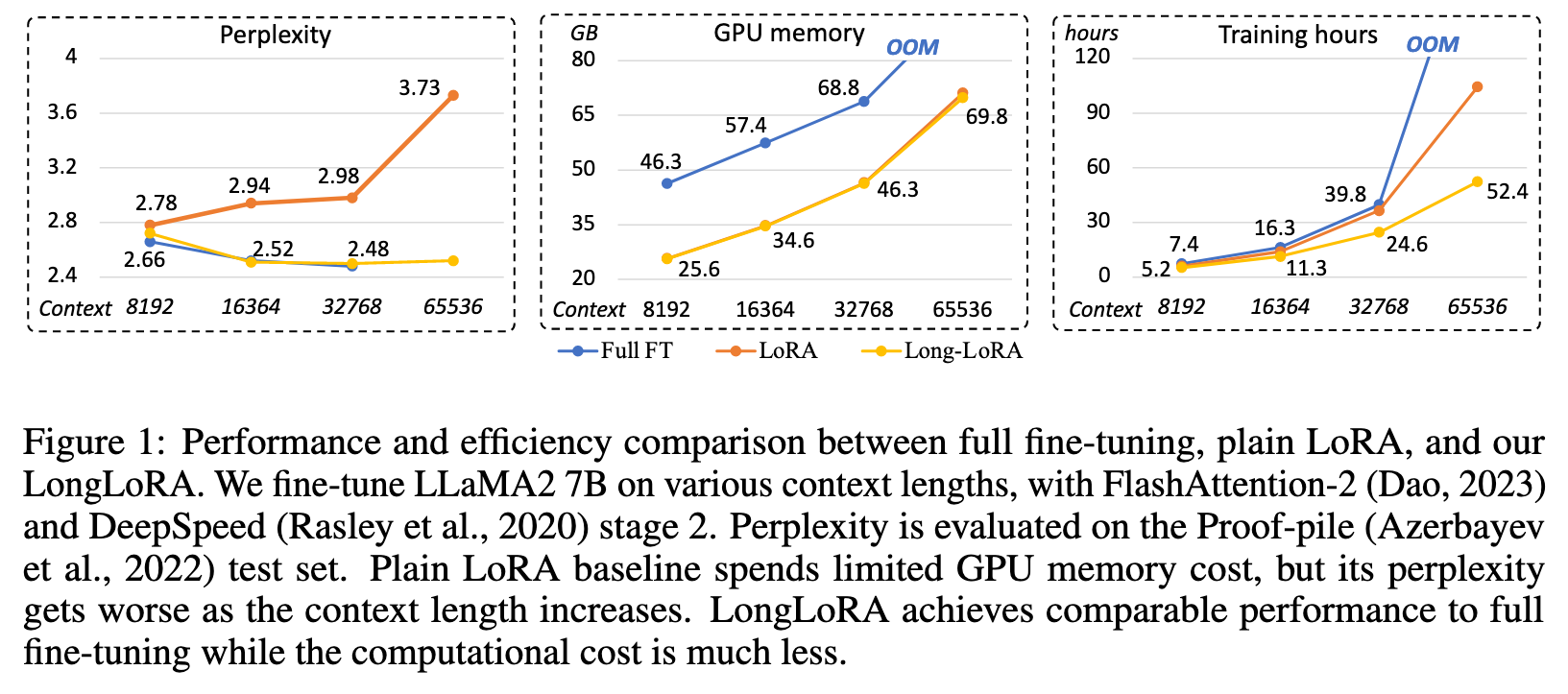
For instance, Position Interpolation (Chen et al., 2023) spent 32 A100 GPUs to extend LLaMA models from 2k to 8k context, and 128 A100 GPUs for longer context fine-tuning. FOT (Tworkowski et al., 2023) used 32 TPUs for standard transformer training and 128 TPUs for LongLLaMA. (p. 2)
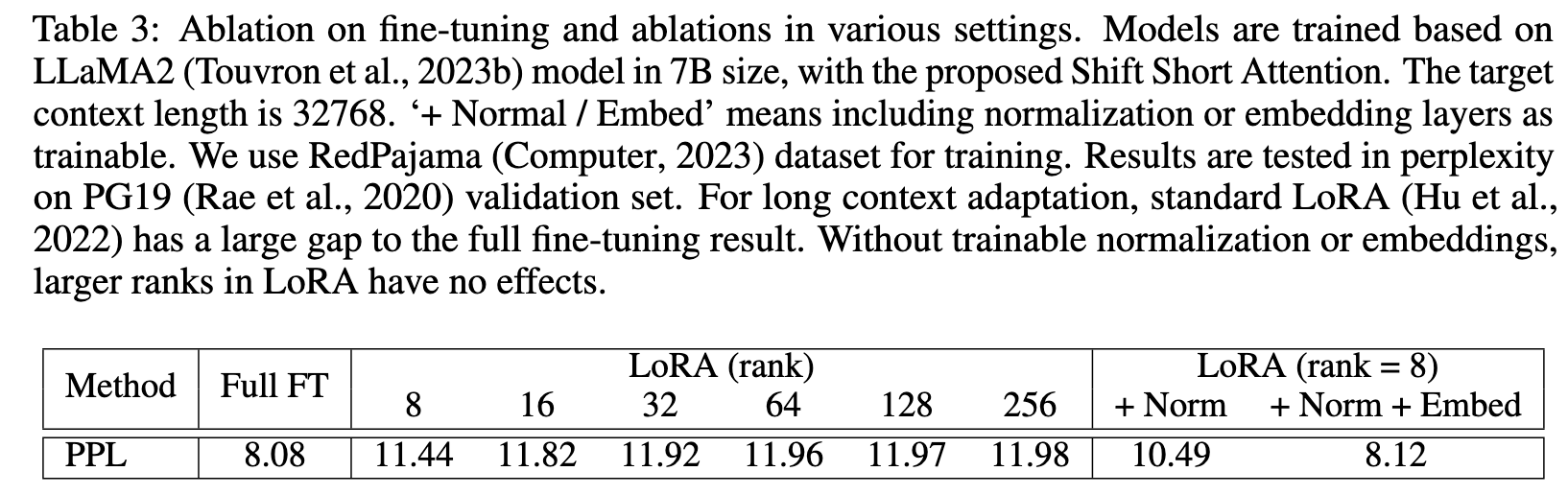
One straightforward approach is to fine-tune a pre-trained LLM via low-rank adaptation (LoRA) (Hu et al., 2022). LoRA modifies the linear projection layers in self-attention blocks by utilizing low-rank matrices, which are generally efficient and reduce the number of trainable parameters. However, our empirical findings indicate that training long context models in this manner is neither sufficiently effective nor efficient. In terms of effectiveness, plain low-rank adaptation results in a high perplexity in long context extension, as in Table 3. Increasing the rank to a higher value, e.g., rank = 256, does not alleviate this issue. In terms of efficiency, regardless of whether LoRA is employed or not, computational cost increases dramatically as the context size expands, primarily due to the standard self-attention mechanism (Vaswani et al., 2017). (p. 2)
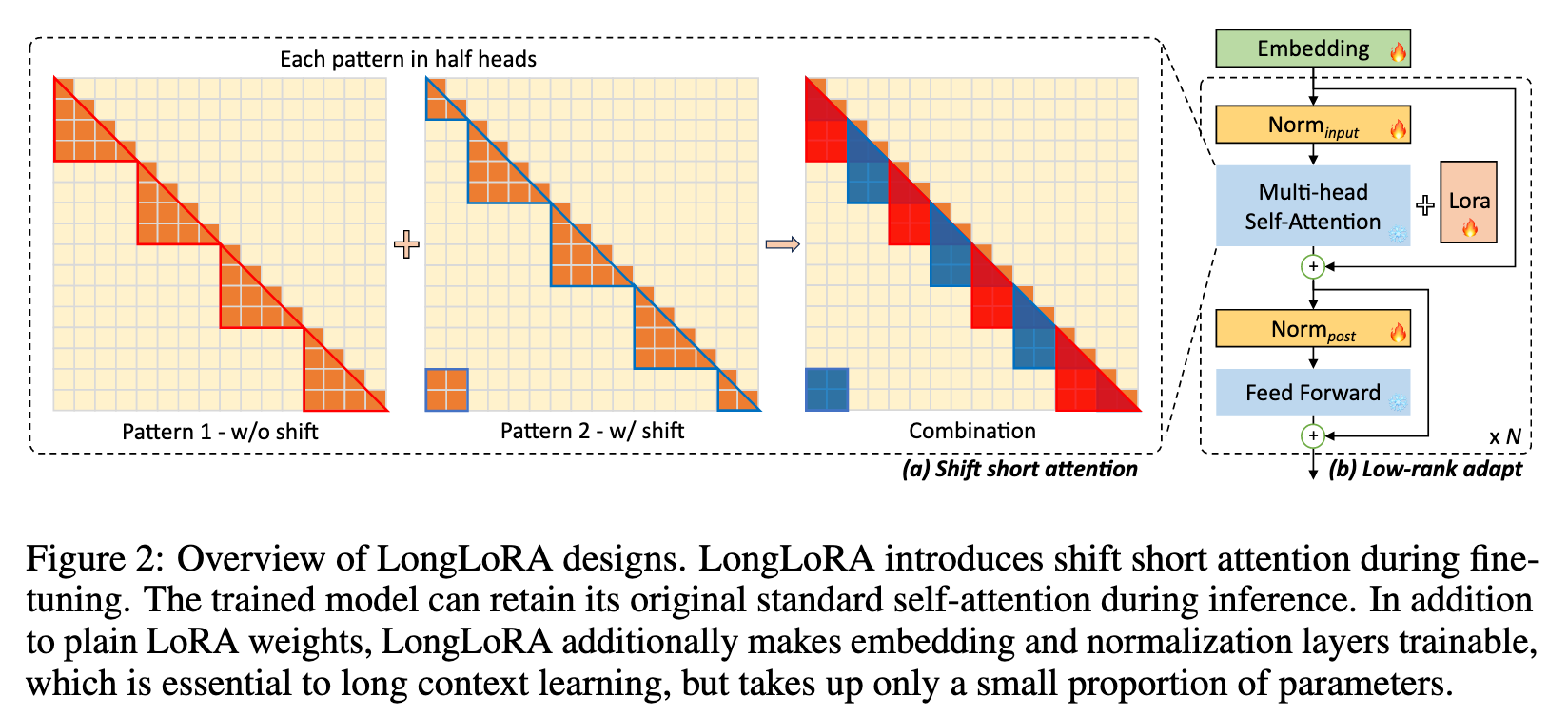
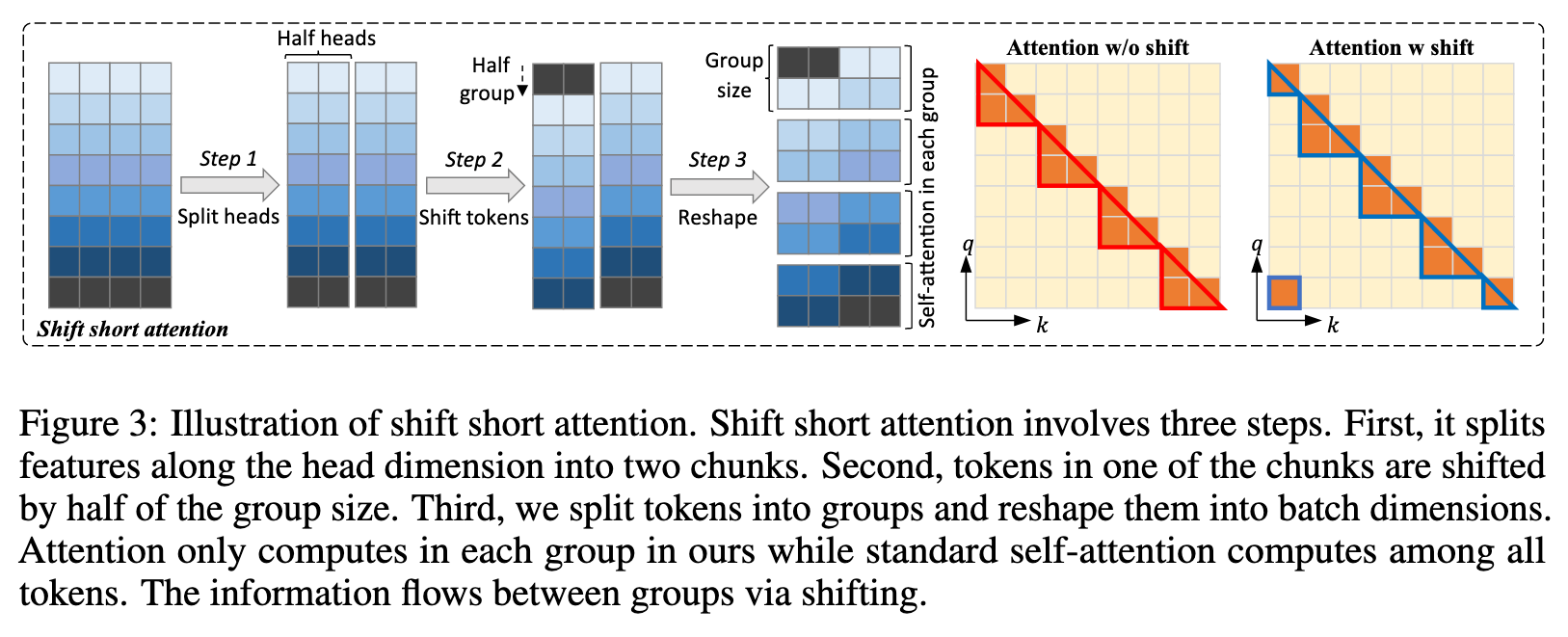
Similarly, we find that short attention is also able to approximate long context during training. We present shift short attention (S2-Attn) as an efficient substitute for standard self-attention. As shown in Figure 2, we split context length into several groups and conduct attention in each group individually. In half attention heads, we shift the tokens by half group size, which ensures the information flow between neighbouring groups This shares a high-level spirit with Swin Transformer (Liu et al., 2021). (p. 2)
We empirically show that learnable embedding and normalization layers are the key to unlocking long context LoRA fine-tuning, in Table 3. (p. 2)
Related Work
Long-context Transformers
Many works modify multi-head attention to be approximated ones. For example, Longformer (Beltagy et al., 2020) and BigBird (Zaheer et al., 2020) use sparse attention to handle long sequences. Other works (Wu et al., 2022; Bulatov et al., 2022) utilize memory mechanisms as a compression on past inputs, to look up relevant tokens. One limitation of these works is that these compression has a large gap to full attention, making it infeasible to fine-tune pre-trained LLMs. (p. 3)
Long-context LLMs
Recently, a number of works have tried to extend the context length of LLMs via fine-tuning. Position Interpolation (Chen et al., 2023) introduces a modification upon rotary position encoding (Su et al., 2021) and extends the context length of LLaMA to 32768. Focused Transformer (Tworkowski et al., 2023) utilizes contrastive learning to train LongLLaMA. Both of them rely on full fine- tuning, which is computationally expensive (128 A100 GPUs / 128 TPUv3 for training). Landmark attention (Mohtashami & Jaggi, 2023) is an efficient approach, but somewhat lossy. It compresses long context inputs into retrieved tokens (p. 3)
Some literature focuses on the position embedding modification of LLMs for long context extension, including Position Interpolation (Chen et al., 2023), NTK-aware (ntk, 2023), Yarn (Peng et al., 2023), positional Skipping (Zhu et al., 2023), and the out-of-distribution related method (Han et al., 2023). (p. 4)
Efficient Fine-tuning
In addition to LoRA (Hu et al., 2022), there are many other parameter-efficient fine-tuning methods, including prompt tuning (Lester et al., 2021), prefix tuning (Li & Liang, 2021), hidden state tuning (Liu et al., 2022), bias tuning (Zaken et al., 2022), and masked weight learning (Sung et al., 2021). Input-tuning (An et al., 2022) introduces an adapter to tune input embedding. (p. 4)
Proposed Method
Background
For long sequences, self-attention struggles with computation cost, which is quadratic to the sequence length. (p. 4)
For a pre-trained weight matrix $W \in R^{d \times k}, it is updated with a low-rank decomposition W + ∆W = W + BA, where $B \in R^{d\times r}$ and $A \in R^{r\times k}$. The rank $r \ll min(d, k)$. During training, W is frozen with no gradient updates, while A and B are trainable. This is the reason why LoRA training is much more efficient than full fine-tuning. (p. 4)
In the Transformer structure, LoRA only adapts the attention weights (Wq, Wk, Wv, Wo) and freezes all other layers, including MLP and normalization layers. This manner is simple and parameter- efficient. However, we empirically show that only low-rank adaptation in attention weights does not work for long context extension. (p. 4)
SHIFT SHORT ATTENTION
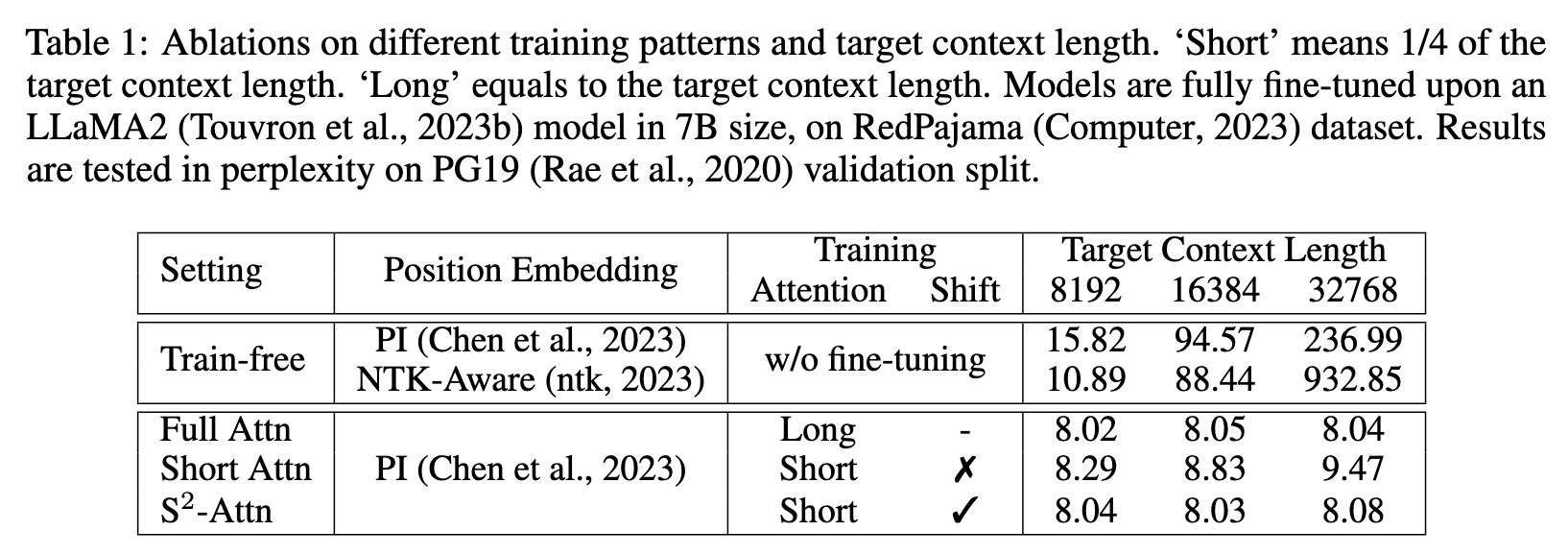
Without fine-tuning, models perform worse as the context length grows up, even with proper position embeddings (Chen et al., 2023; ntk, 2023) equipped. (p. 5)
To introduce communication between groups, we include a shifted pattern, as shown in Figure 2. We shift the group partition by half group size in half attention heads. This manner does not increase additional computation cost but enables the the information flow between different groups. We show that it gets close to the standard attention baseline in Table 1. (p. 5)
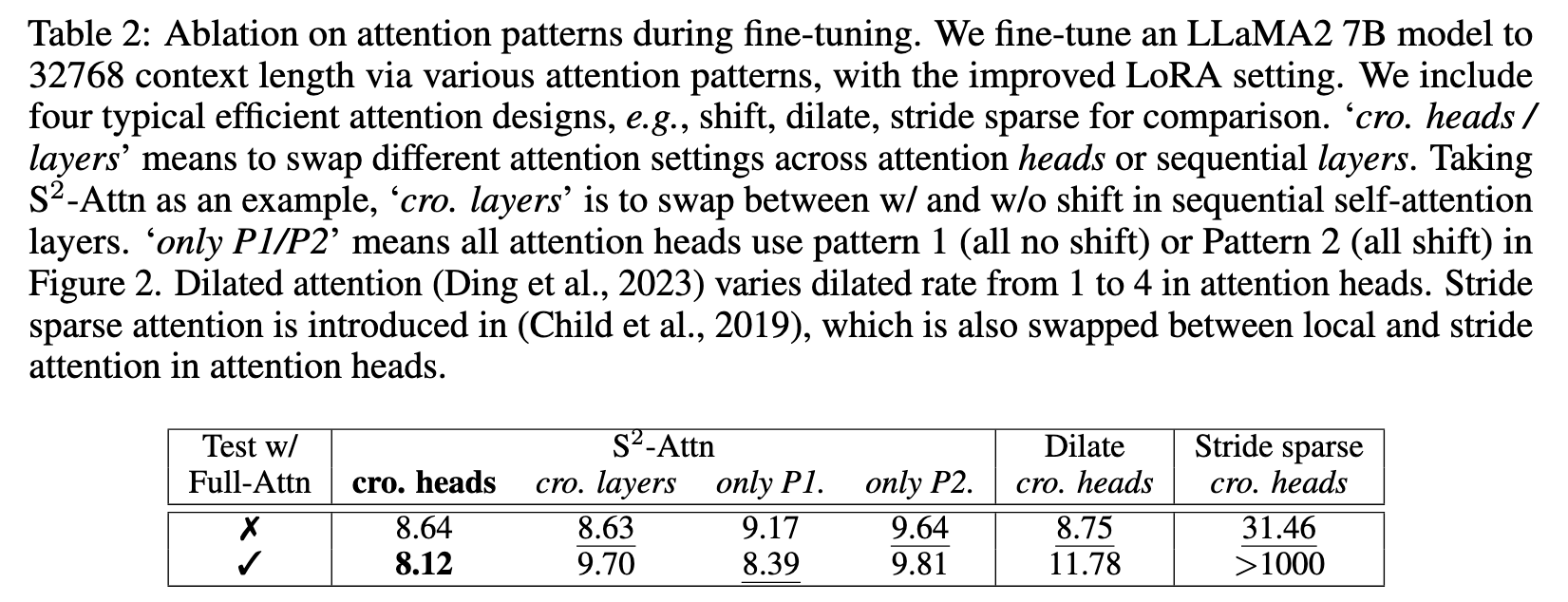

We show that S2-Attn not only enables efficient fine-tuning but also supports full attention testing. (p. 6)
IMPROVED LORA FOR LONG CONTEXT
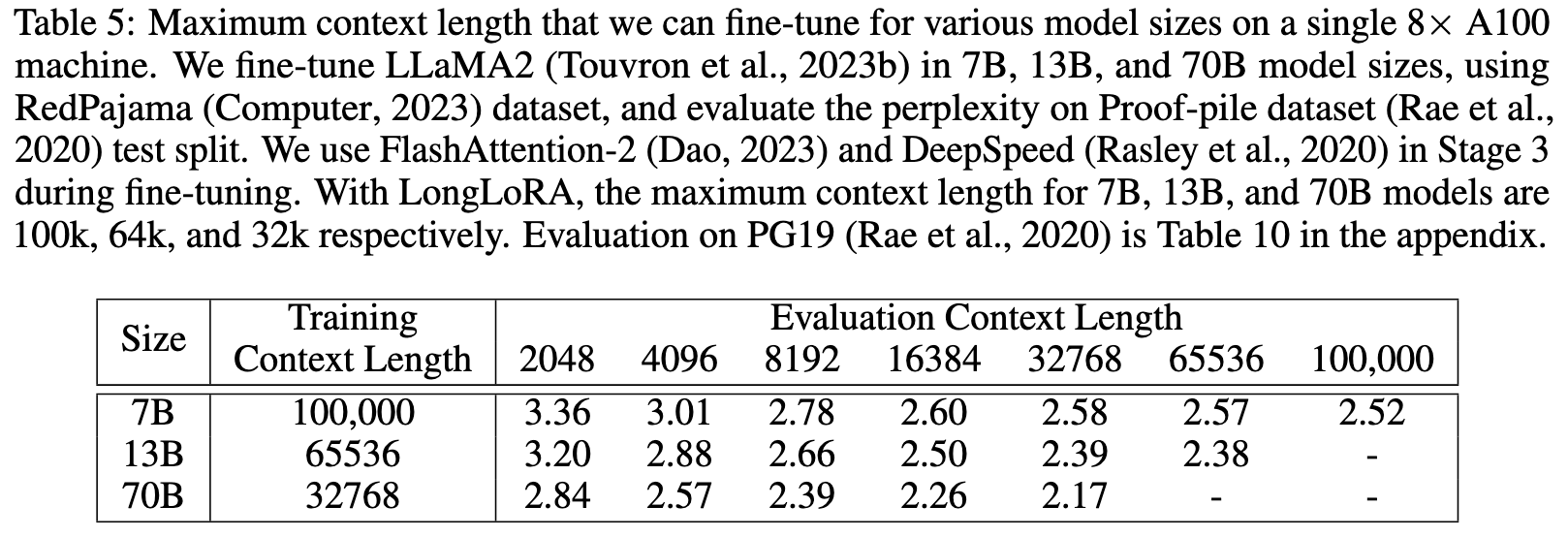
As shown in Table 3, the gap between LoRA and full fine-tuning grows as the target context length becomes larger. And LoRA with larger ranks cannot reduce the gap. (p. 6)
To bridge this gap, we open embedding and normalization layers for training. As shown in Table 3, they occupy limited parameters but make effects for long context adaptation. Especially for normal- ization layers, the parameters are only 0.004% in the whole LLaMA2 7B. We denote this improved version of LoRA as LoRA+ in experiments. (p. 6)
However experiment result (Table 4) doesn’t show LoRA+ improves the result.
Experiment