MagiCapture High-Resolution Multi-Concept Portrait Customization
[attention face prompt2prompt diffusion personalize deep-learning text2image This is my reading note on MagiCapture High-Resolution Multi-Concept Portrait Customization. This paper proposes a diffusion method to apply a style to a specific face image. Both the style and face are given as images. To do this, this paper fine tune existing model with LORA given several new loss functions: one is face identity loss for the face region given a face recognition model; another one is background similarity for the style. The two loss are applied to the latent vector.

Introduction
However, despite the plausible results from these personalization methods, they tend to produce images that often fall short of realism and are not yet on a commercially viable level. This is particularly noticeable in portrait image generation, where any unnatural artifact in human faces is easily discernible due to our inherent human bias. (p. 1)
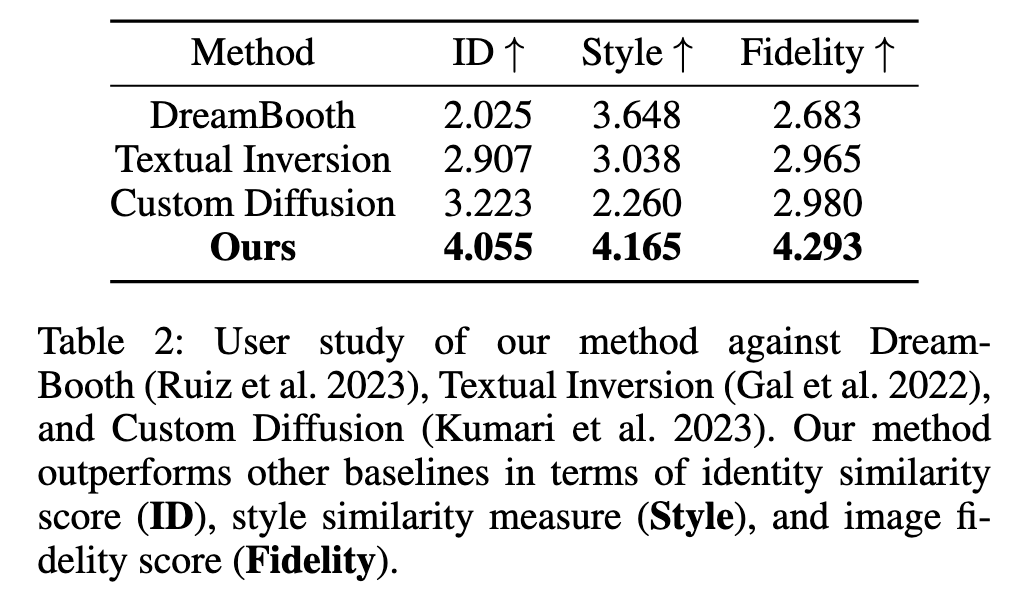
For instance, given a handful of random selfies, our fine-tuned model can generate high-quality portrait images in specific styles, such as passport or profile photos. The main challenge with this task is the absence of ground truth for the composed concepts, leading to a reduction in the quality of the final output and an identity shift of the source subject. To address these issues, we present a novel Attention Refocusing loss coupled with auxiliary priors, both of which facilitate robust learning within this weakly supervised learning setting. Our pipeline also includes additional post-processing steps to ensure the creation of highly realistic outputs. (p. 1)
Our method employs composed prompt learning, incorporating the composed prompt as part of the training process, which enhances the robust integration of source content and reference style. This is achieved through the use of pseudo labels and auxiliary loss. Moreover, we propose the Attention Refocusing loss in conjunction with a masked reconstruction objective, a crucial strategy for achieving information disentanglement and preventing information leakage during inference (p. 2)
- We present a novel Attention Refocusing loss combined with masked reconstruction objective, effectively disentangling the desired information from input images and preventing information leakage during the generation process.
- We put forth a composed prompt learning approach that leverages pseudo-labels and auxiliary loss, facilitating the robust integration of source content and reference style (p. 2)
Related Work
- With the rise of GANs, there have been efforts to fine-tune GANs, like Pivotal Tuning (Roich et al. 2022), based on GAN inversion (Zhu et al. 2020).
- More recently, studies have sought to personalize diffusion models using small image datasets.
- DreamBooth (Ruiz et al. 2023) fine-tunes entire weights,
- Textual Inversion (Gal et al. 2022) adjusts text embeddings,
- and Custom Diffusion (Kumari et al. 2023) adapts the mapping matrix for the cross-attention layer.
- While effective in learning concepts, these models sometimes generate less realistic or identity-losing images. Methods like ELITE (Wei et al. 2023) and InstantBooth (Shi et al. 2023) employ a data driven approach for encoder-based domain tuning, which is not directly comparable to our approach. (p. 2)
Preliminaries
DreamBooth fine-tunes the entire UNet model, Textual Inversion exclusively adjusts the CLIP text embedding of the special token, and Custom Diffusion optimizes the key and value mapping matrices within the crossattention layer of the UNet. (p. 3)
Large-scale text-to-image diffusion models utilize cross-attention layers for text-conditioning. In Stable Diffusion (Rombach et al. 2022), CLIP text encoder (Radford et al. 2021) is used to produce text embedding features. These text embeddings are then transformed to obtain the key K and value V for the cross-attention layer through linear mapping, and spatial feature of image is projected to query Q (p. 3)
Such attention maps are useful for visualizing the influence of individual tokens in the text prompt. Moreover, they can be altered or manipulated for the purpose of image editing, as demonstrated in Prompt-to-Prompt (Hertz et al. 2022). (p. 3)
Proposed Method
Two-phase Optimization
Similar to Pivotal Tuning (Roich et al. 2022) in GAN inversion, our method consists of two-phase optimization.
- In the first phase, we optimize the text embeddings for the special tokens [V ∗] using the reconstruction objective as in (Gal et al. 2022). While optimizing the text embeddings is not sufficient for achieving high-fidelity customization, it serves as a useful initialization for the subsequent phase.
- In the second phase, we jointly optimize the text embeddings and model parameters with the same objective. Rather than optimizing the entire model, we apply the LoRA (Hu et al. 2021), where only the residuals ∆W of the projection layers in the cross-attention module are trained using low-rank decomposition (p. 4)
Masked Reconstruction
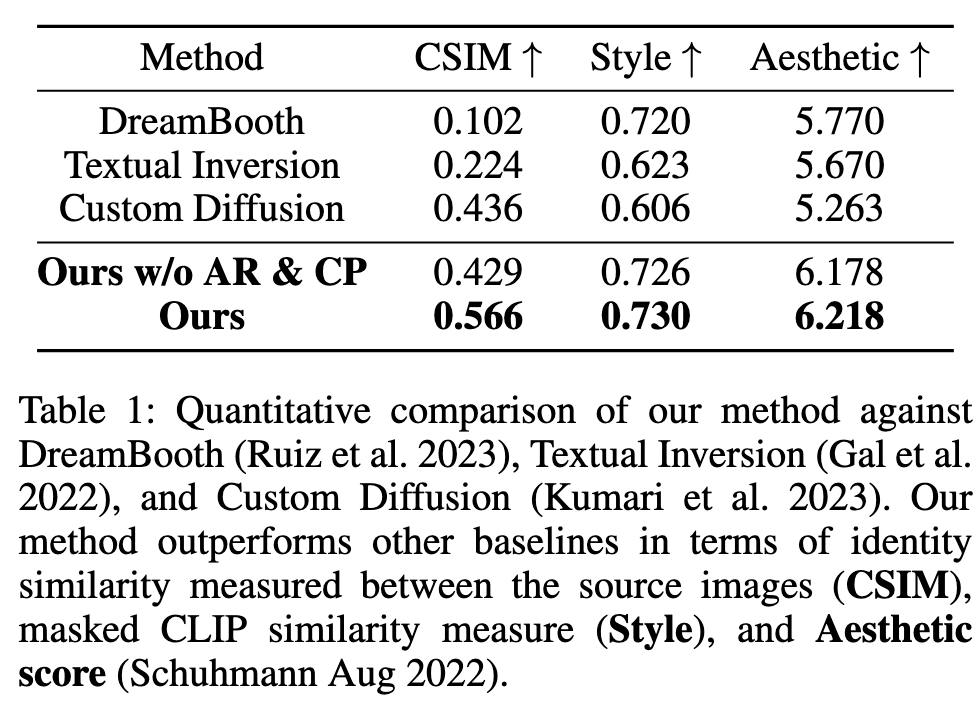
In our approach, a source prompt cs (e.g., A photo of [V 1] person.) and a reference prompt cr (e.g., A photo of a person in the [V 2] style.) are used to reconstruct the source image Is and a target style image Ir respectively. It is crucial to disentangle the identity of the source subject from non-facial regions, such as the background and clothing, to prevent this unwanted information from being encoded into the special token [V 1]. Similarly, we need to disentangle the reference image to ensure that the facial details of the person in the reference image are not embedded into the special token [V 2].
To achieve this, we propose to use a masked reconstruction loss. Specifically, we employ a mask that indicates the relevant region and apply it element-wise to both the ground truth latent code and the predicted latent code. In the context of portrait generation, a source mask Ms indicates the facial region of the image Is, and a target mask Mr denotes the non-facial areas of the reference image Ir. (p. 4)
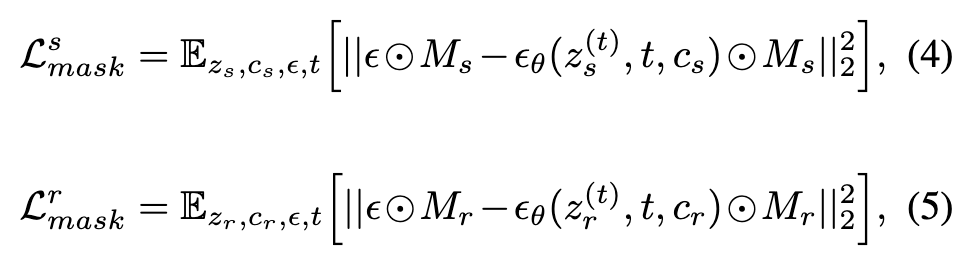
Composed Prompt Learning
Typically, the resulting images generated using these unseen composed prompts suffer from a shift in the identity of the source subject and a decline in output quality. To address this issue, we include training on the composed prompt. (p. 4)
We craft pseudo-labels and develop an auxiliary objective function to suit our needs. In the context of the portrait generation task, we want to retain the overall composition, pose, and appearance from the reference style image, excluding the facial identity (p. 4)
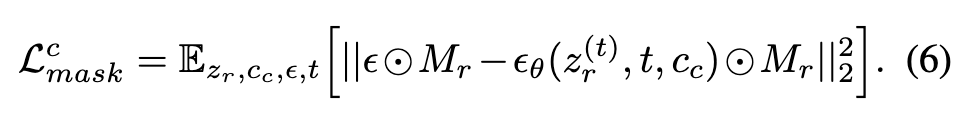
For the facial regions, we use an auxiliary identity loss that utilizes a pre-trained face recognition model (Deng et al. 2019) R and cropping function B conditioned by the face detection model (Deng et al. 2020): (p. 4)
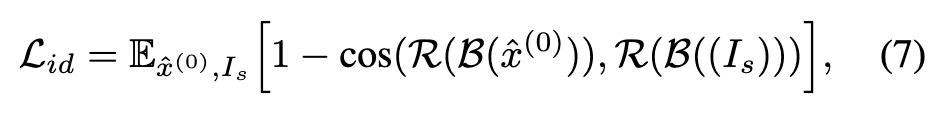
Timestep tid is sampled as t_id ∼ Uniform(1, T ′ ), where T ′ < T, to avoid blurry and inaccurate xˆ(0) estimated from noisy latent with large timesteps, which can impair cropping or yield odd facial embeddings (p. 4)
We augment the composed prompt cc by randomly selecting from predefined prompt templates to boost editing stability and generalization. (p. 4)
Attention Refocusing

When optimizing with training images, it is vital to achieve information disentanglement, ensuring that special tokens exclusively embed the information of the region of interest, denoted as Mv for v ∈ {s, r}. However, the masked reconstruction objective falls short of this goal because the presence of transformer layers in the UNet backbone gives the model a global receptive field. The same limitation applies to denoising steps in the inference stage, where we desire attention maps of special tokens to focus only on the intended areas. (p. 5)
To solve this issue, we propose a novel Attention Refocusing (AR) loss, which steers the cross attention maps Ak of the special token [V ∗] (where k = index([V ∗])) using a binary target mask. Our AR loss incorporates two crucial details: First, it is applied only to regions where ¬Mv, where the mask value is zero. For the attention map values Ak[i, j] where (i, j) ∈ {(i, j)|Mv[i, j] = 1}, the optimal values can vary across different UNet layers and denoising time steps, so they do not necessarily have to be close to 1. Conversely, for Ak[i, j] where (i, j) ∈ {(i, j)|Mv[i, j] = 0}, the values should be forced to 0 to achieve information disentanglement during training and minimize information spill in the inference stage. Second, it is essential to scale the attention maps to the [0,1] range. Both of these techniques are required to avoid disrupting the pre-trained transformer layers’ internal operations, which would lead to corrupted outputs. The Attention Refocusing loss can be formulated as follows: (p. 5)
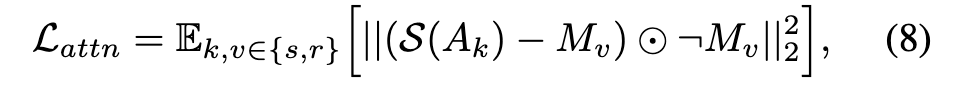
Specifically, we employ a pretrained super-resolution model (Wang et al. 2021) and a face restoration model (Zhou et al. 2022) to further improve the quality of the generated samples. (p. 5)
Experiment