MDETR -Modulated Detection for End-to-End Multi-Modal Understanding
[hula-net multimodal llm mask-rcnn object-detection mdetr vilbert deep-learning vlbert mga-net detr vinvl transformer visual-bert mac matt-net film This is my reading note for MDETR -Modulated Detection for End-to-End Multi-Modal Understanding. This paper proposes a method to learn object detection model from pairs of image and tree form text. The trained model is found to be capable of localizing unseen / long tail category.

Introduction
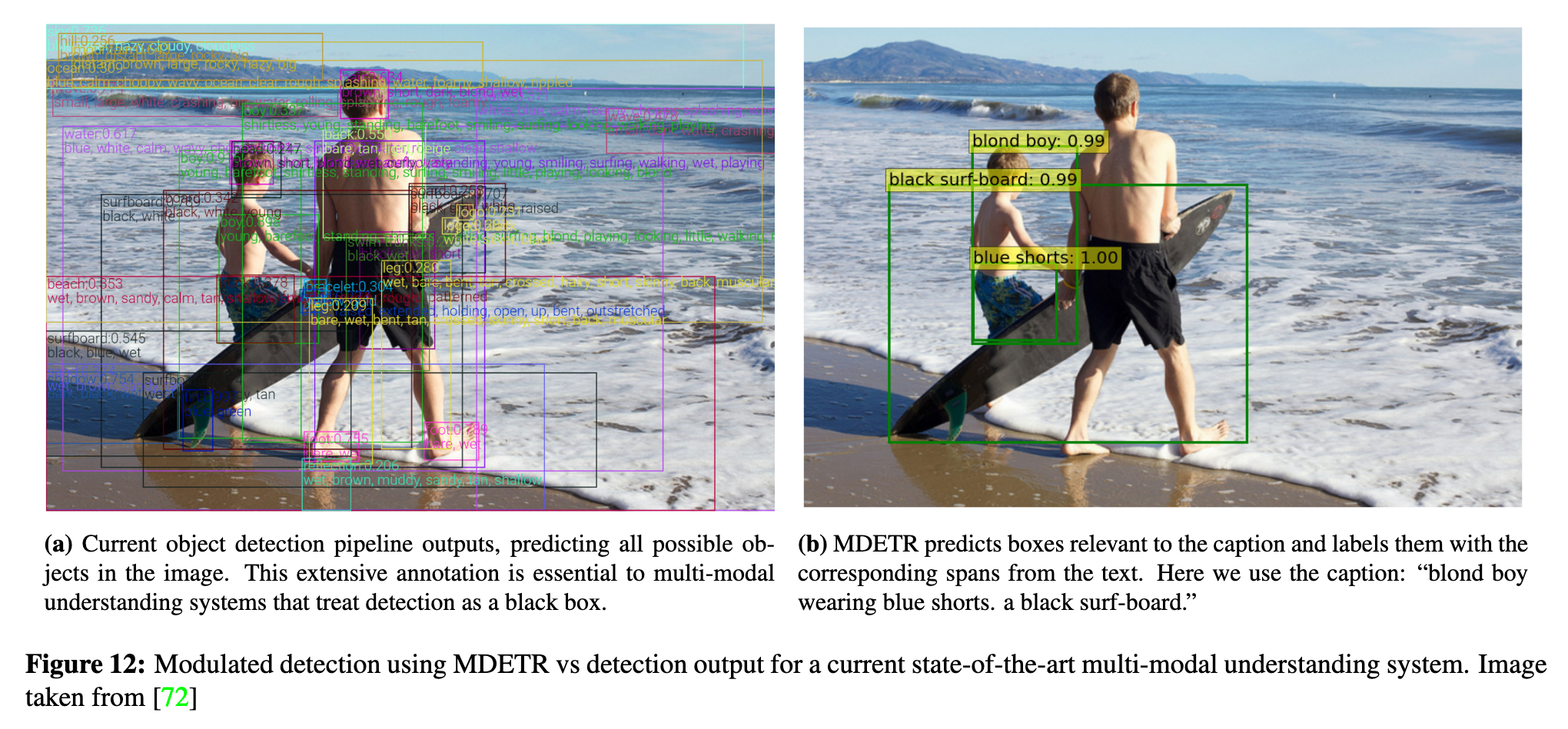
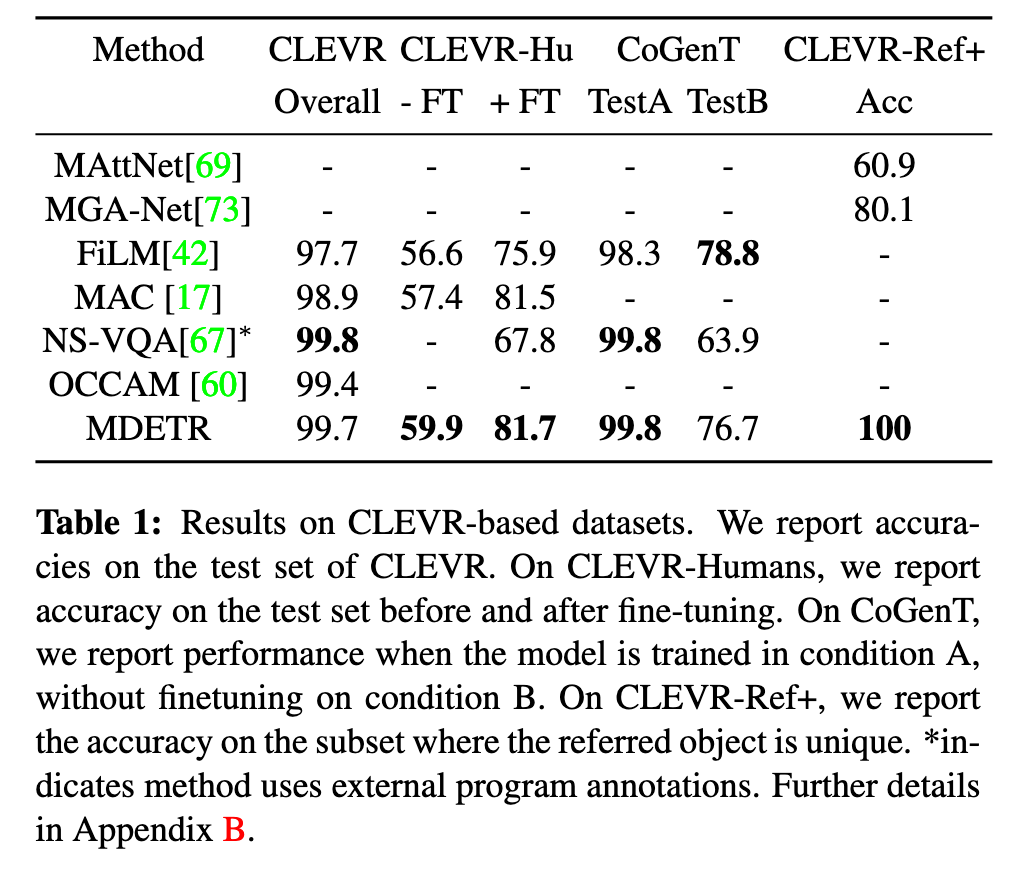
In this paper we propose MDETR, an end-to-end modulated detector that detects objects in an image conditioned on a raw text query, like a caption or a question. We use a transformer-based architecture to reason jointly over text and image by fusing the two modalities at an early stage of the model. We then fine-tune on several downstream tasks such as phrase grounding, referring expression comprehension and segmentation, achieving state-of-the-art results on popular benchmarks. (p. 1)
A recent line of work [66, 45, 13] considers the problem of text-conditioned object detection. These methods extend mainstream one-stage and two-stage detection architectures to achieve this goal. However, to the best of our knowledge, it has not been demonstrated that such detectors can improve performance on downstream tasks that require reasoning over the detected objects, such as visual question answering (VQA). We believe this is because these detectors are not end-to-end differentiable and thus cannot be trained in synergy with downstream tasks. (p. 1)
Our method, MDETR, is an end-to-end modulated detector based on the recent DETR [2] detection framework, and performs object detection in conjunction with natural language understanding, enabling truly end-to-end multimodal reasoning. MDETR relies solely on text and aligned boxes as a form of supervision for concepts in an image. Thus, unlike current detection methods, MDETR detects nuanced concepts from free-form text, and generalizes to unseen combinations of categories and attributes. (p. 1)
DETR
DETR is an end-to-end detection model composed of a backbone (typically a convolutional residual network [12]), followed by a Transformer Encoder-Decoder [59].
The DETR encoder operates on 2D flattened image features from the backbone and applies a series of transformer layers. The decoder takes as input a set of N learned embeddings called object queries, that can be viewed as slots that the model needs to fill with detected objects. All the object queries are fed in parallel to the decoder, which uses cross-attention layers to look at the encoded image and predicts the output embeddings for each of the queries. The final representation of each object query is independently decoded into box coordinates and class labels using a shared feed-forward layer. The number of object queries acts as a de facto upper-bound on the number of objects the model can detect simultaneously. It has to be set to a sufficiently large upper-bound on the number of objects one may expect to encounter in a given image. Since the actual number of objects in a particular image may be less than the number of queries N, an extra class label corresponding to “no object” is used, denoted by ∅. The model is trained to output this class for every query that doesn’t correspond to an object.
DETR is trained using a Hungarian matching loss, where a bipartite matching is computed between the N proposed objects and the ground-truth objects. Each matched object is supervised using the corresponding target as groundtruth, while the un-matched objects are supervised to predict the “no object” label ∅. The classification head is supervised using standard cross-entropy, while the bounding box head is supervised using a combination of absolute error (L1 loss) and Generalized IoU [48]. (p. 2)
Proposed Method
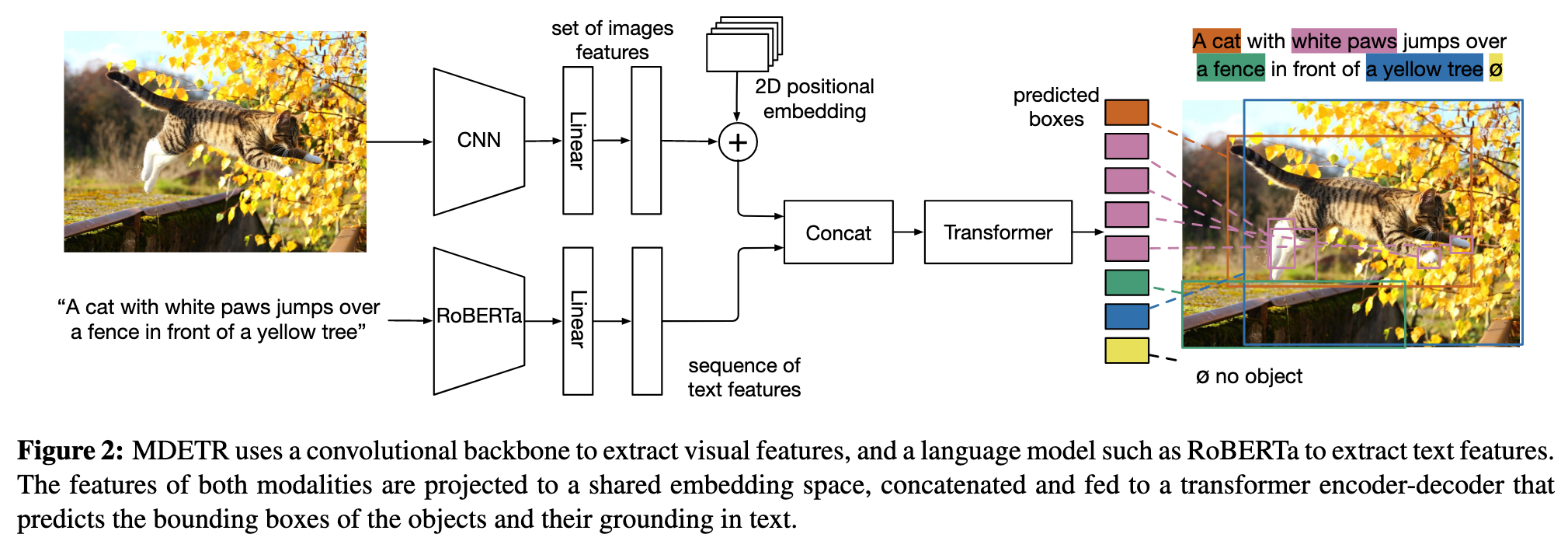
Architecture
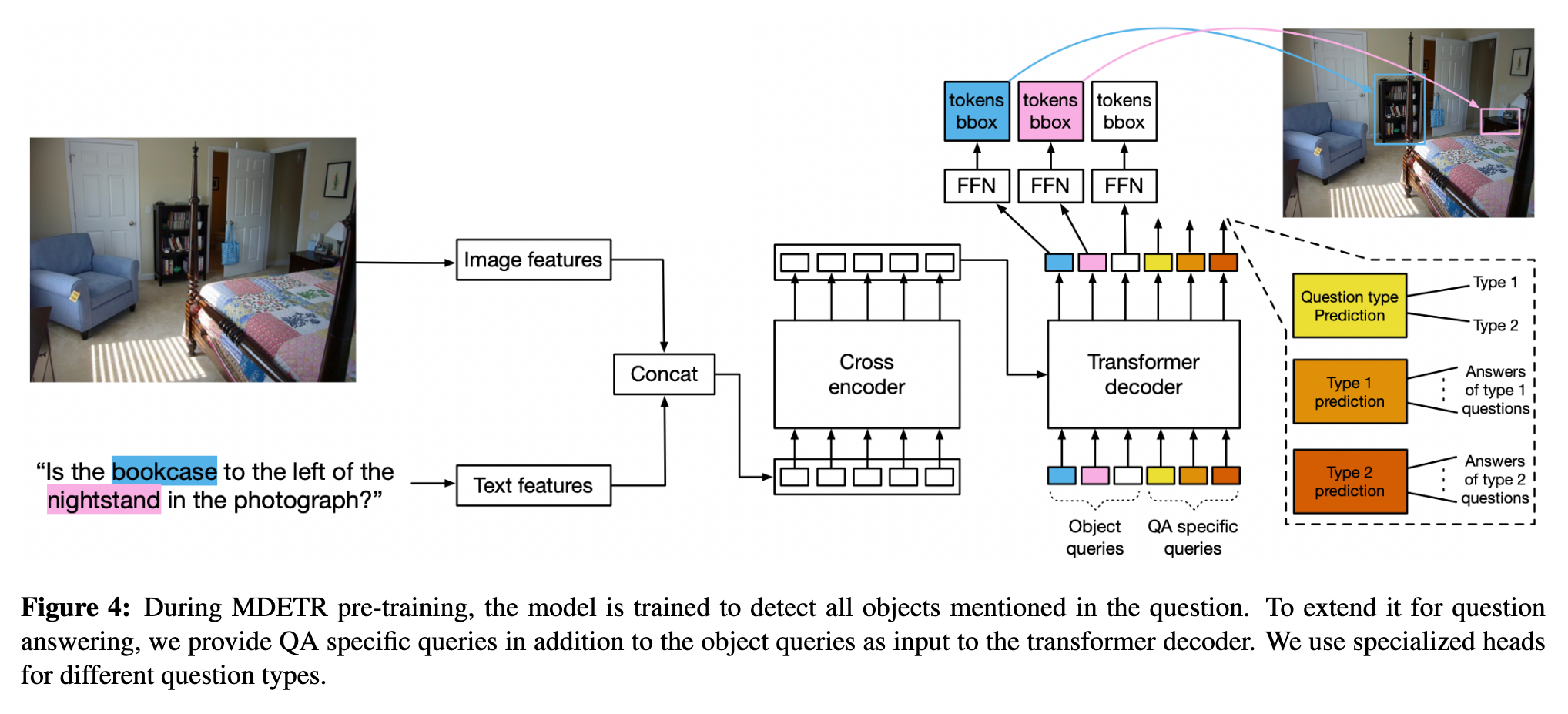
We encode the text using a pre-trained transformer language model to produce a sequence of hidden vectors of same size as the input. We then apply a modality dependent linear projection to both the image and text features to project them into a shared embedding space. These feature vectors are then concatenated on the sequence dimension to yield a single sequence of image and text features. This sequence is fed to a joint transformer encoder termed as the cross encoder. Following DETR, we apply a transformer decoder on the object queries while cross attending to the final hidden state of the cross encoder. The decoder’s output is used for predicting the actual boxes. (p. 3)
Training
We present the two additional loss functions used by MDETR, which encourage alignment between the image and the text. Both of these use the same source of annotations: free form text with aligned bounding boxes. The first loss function that we term as the soft token prediction loss is a non parametric alignment loss. The second, termed as the text-query contrastive alignment is a parametric loss function enforcing similarity between aligned object queries and tokens (p. 3)
Soft token prediction

Instead, we predict the span of tokens from the original text that refers to each matched object. Concretely, we first set the maximum number of tokens for any given sentence to be L = 256. For each predicted box that is matched to a ground truth box using the bi-partite matching, the model is trained to predict a uniform distribution over all token positions that correspond to the object. (p. 3)
but in practice we use token spans after tokenization using a BPE scheme [52]. Any query that is not matched to a target is trained to predict the “no object” label ∅. (p. 3)
Contrastive alignment
the contrastive alignment loss enforces alignment between the embedded representations of the object at the output of the decoder, and the text representation at the output of the cross encoder. the embeddings of a (visual) object and its corresponding (text) token are closer in the feature space compared to embeddings of unrelated tokens. (p. 3)
The contrastive loss for all objects, inspired by InfoNCE [40] is normalized by number of positive tokens for each object and can be written as follows: (p. 3)
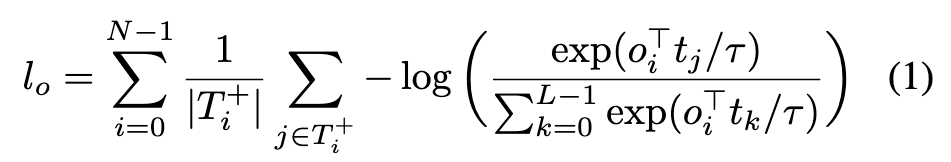
where τ is a temperature parameter that we set to 0.07 following literature [63, 47]. By symmetry, the contrastive loss for all tokens, normalized by the number of positive objects for each token is given by: (p. 3)
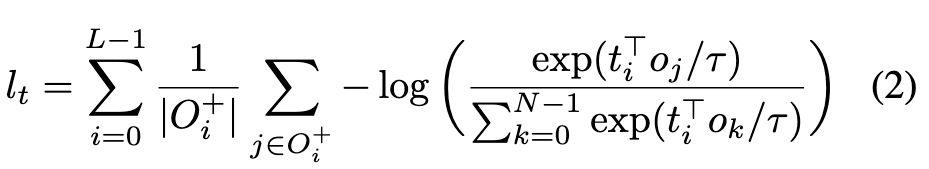
Combining all the losses
In MDETR, a bipartite matching is used to find the best match between the predictions and the ground truth targets just as in DETR. The main difference is that there is no class label predicted for each object instead predicting a uniform distribution over the relevant positions in the text that correspond to this object (soft token predictions), supervised using a soft cross entropy. The matching cost consists of this in addition to the L1 & GIoU loss between the prediction and the target box as in DETR. After matching, the total loss consists of the box prediction losses (L1 & GIoU), soft-token prediction loss, and the contrastive alignment loss. (p. 3)
Experiments
Data combination For each image, we take all annotations from these datasets and combine the text that refers to the same image while ensuring that all images that are in the validation or testing set for all our downstream tasks are removed from our train set. The combination of sentences is done using a graph coloring algorithm which ensures that only phrases having boxes with GIoU ≤ 0.5 are combined, and that the total length of a combined sentence is less than 250 characters. (p. 4)

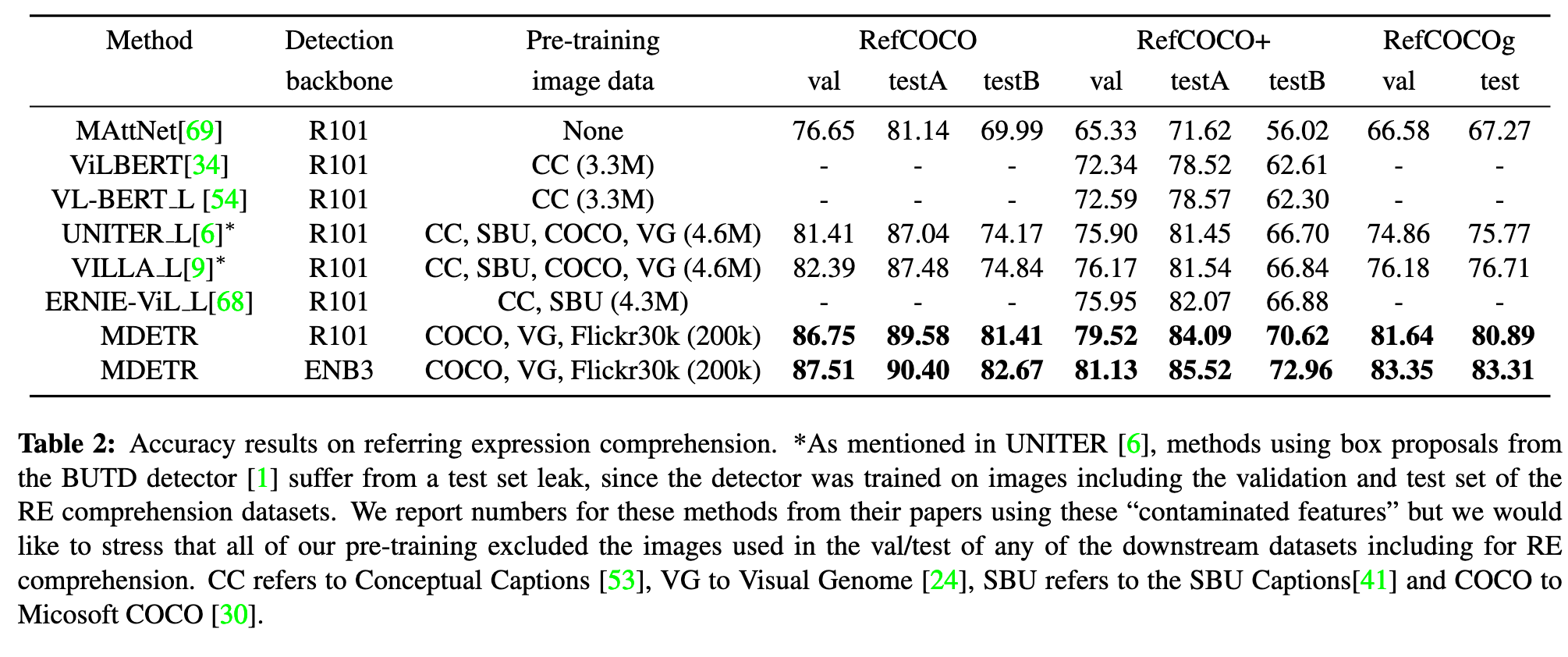
Phrase grounding
Given one or more phrases, which may be inter-related, the task is to provide a set of bounding boxes for each phrase. (p. 5)
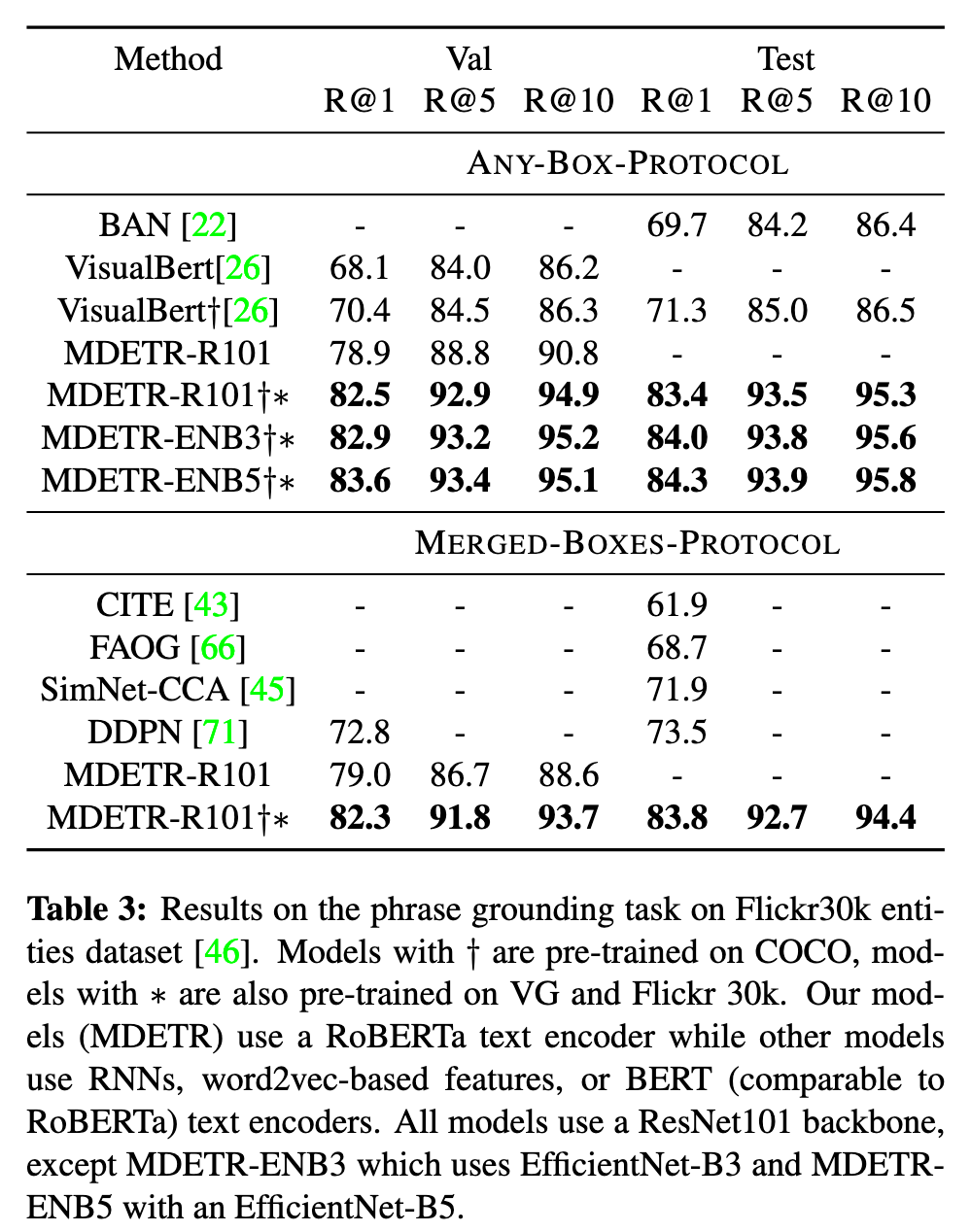
Referring expression comprehension
Given an image and a referring expression in plain text, the task is to localize the object being referred to by returning a bounding box around it. (p. 5)
Referring expression segmentation
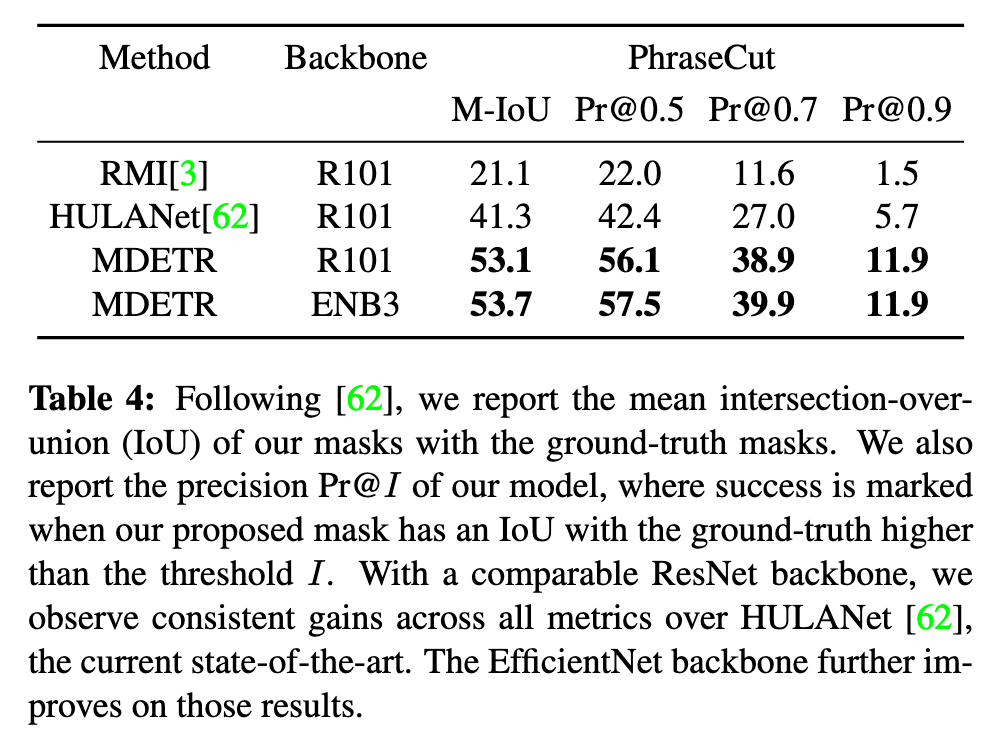
Similarly to DETR, we show that our approach can be extended to perform segmentation by evaluating on the referring expression segmentation task of the recent PhraseCut [62] dataset which consists of images from VG, annotated with segmentation masks for each referring expression. (p. 6)
Visual Question Answering
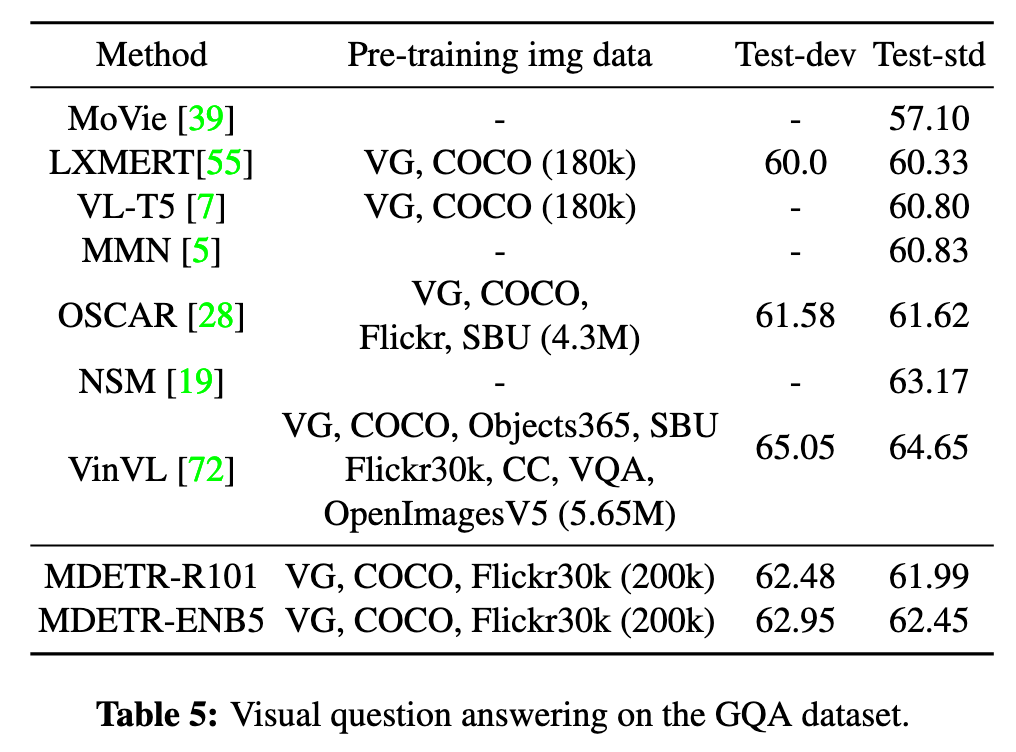

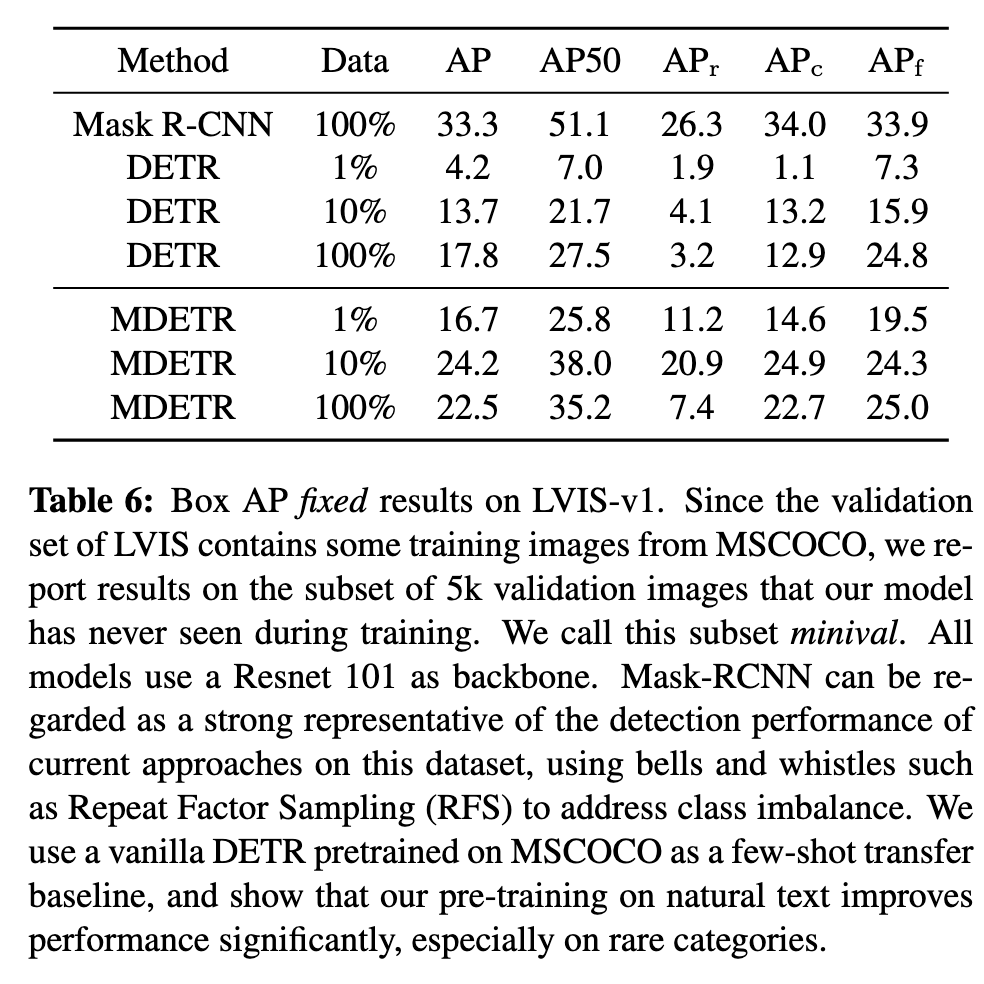


Ablations
Loss ablations
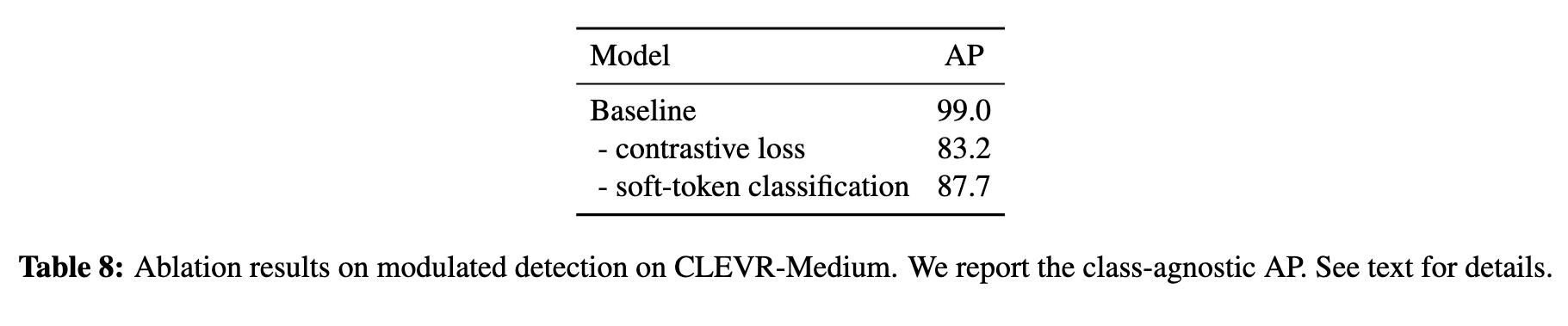
Contrastive loss
As shown in Table 8, removing this loss results in a drastic drop in AP. More specifically, when evaluating the model, it becomes apparent that it is able to filter the objects based on some attributes (in particular their shape and size) but not others (in particular color and texture). (p. 18)
However, it shows that solely predicting the spans of the text query associated with each object is not sufficient to learn proper alignment. The contrastive loss, which forces object-queries to be similar to their corresponding text-token, is thus necessary (p. 18)
Contrastive loss
We observe similar results as the previous ablation, namely a sharp decline in AP and a model that only understands half of the attributes correctly (p. 18)
Question answering ablations