MM-VID Advancing Video Understanding with GPT-4V(ision)
[llm multimodal tool deep-learning gpt4v vqa video-caption vlog blip2 grit whipser chatgpt gpt4 This is my reading note for MM-VID: Advancing Video Understanding with GPT-4V(ision). The paper proposes a system of understanding long video based on GPT 4V. To this end it first converts long video to short clips and pass every frames of clips to GPT 4V to generate text description. This description, together with audio transcription, is then ted to GPT 4U for final video understand. The analyst is based user ratings between normal vision subjects and vision impaired subjects.

Introduction
MM-VID is designed to address the challenges posed by long-form videos and intricate tasks such as reasoning within hour-long content and grasping storylines spanning multiple episodes. MM-VID uses a video-to-script generation with GPT-4V to transcribe multimodal elements into a long textual script. The generated script details character movements, actions, expressions, and dialogues, paving the way for large language models (LLMs) to achieve video understanding. This enables advanced capabilities, including audio description, character identification, and multimodal high-level comprehension. (p. 2)
It involves not only identifying who are in the scene and what they do, but also pinpointing when and how they act, while recognizing subtle nuances and visual cues across different scenes (p. 2)
Given an input video, MM-VID performs multimodal pre-processing, including scene detection and automatic speech recognition (ASR), to collect important information in the video. The input video is then split into multiple clips according to the scene detection algorithm. Then, we employ GPT-4V, which takes the clip-level video frames as input and generates a detailed description for each video clip. Finally, GPT-4 is adopted to generate a coherent script for the full video, conditioning on the clip-level video descriptions, ASR, and video metadata if available. (p. 2)
For example, VLog [6] uses BLIP2 [34] and GRIT [71] as dense image captioners, Whisper [56] as ASR translator, and ChatGPT as a reasoner. By transcribing a given video to textual descriptions (e.g., document), it enables ChatGPT for video question-answering tasks. (p. 3)
Proposed Method
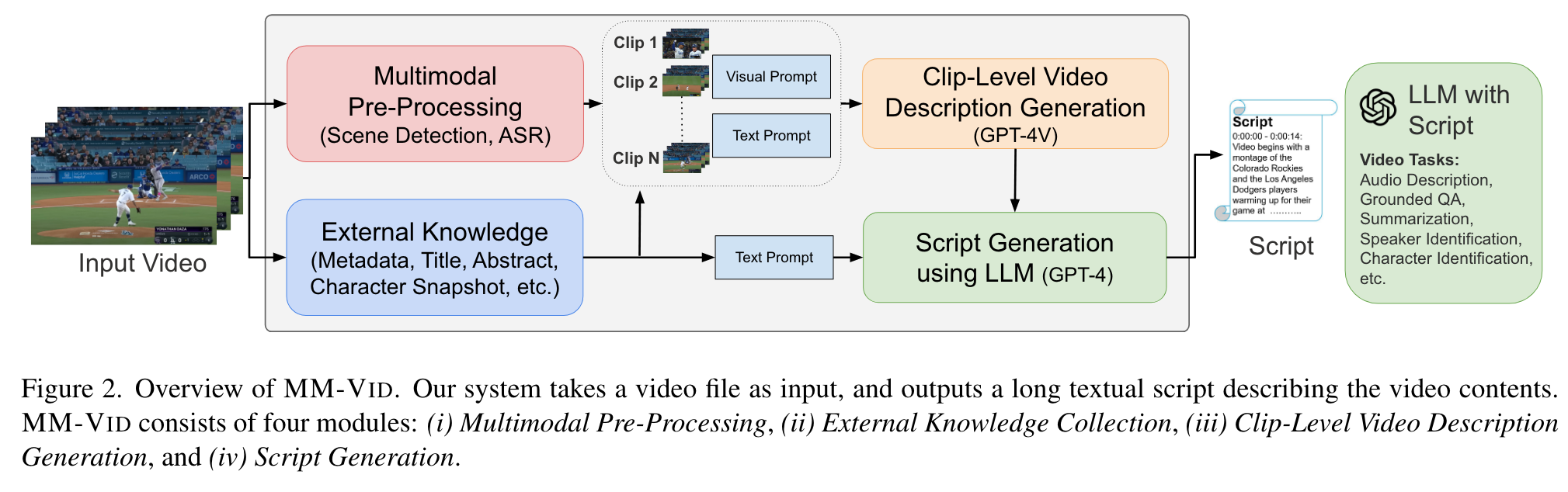
we divide the video into several short video clips. This process involves uniform sampling of video frames, with each clip consisting of 10 frames. To enhance the overall quality of frame sampling, we use established scene detection tools like PySceneDetect [5] to help identify crucial scene boundaries. (p. 4)
For each clip, which typically consists of 10 frames, we employ GPT-4V to generate video descriptions. By feeding the video frames along with the associated text prompt into the model, GPT-4V utilizes the input to generate detailed descriptions that capture the visual elements, actions, and events depicted in those frames. (p. 4)
we explore the use of visual prompting, where the character’s face photos are presented alongside the character’s name in the input to GPT-4V. Our empirical results suggest that visual prompting is helpful to enhance the quality of video descriptions, particularly for more accurate character identification. (p. 4)
After generating the descriptions for each video clip, we use GPT-4 to integrate these clip-level descriptions into a coherent script. This script serves as a comprehensive description of the entire video, and is used by GPT-4 for a diverse set of video understanding tasks. (p. 4)
Experiment

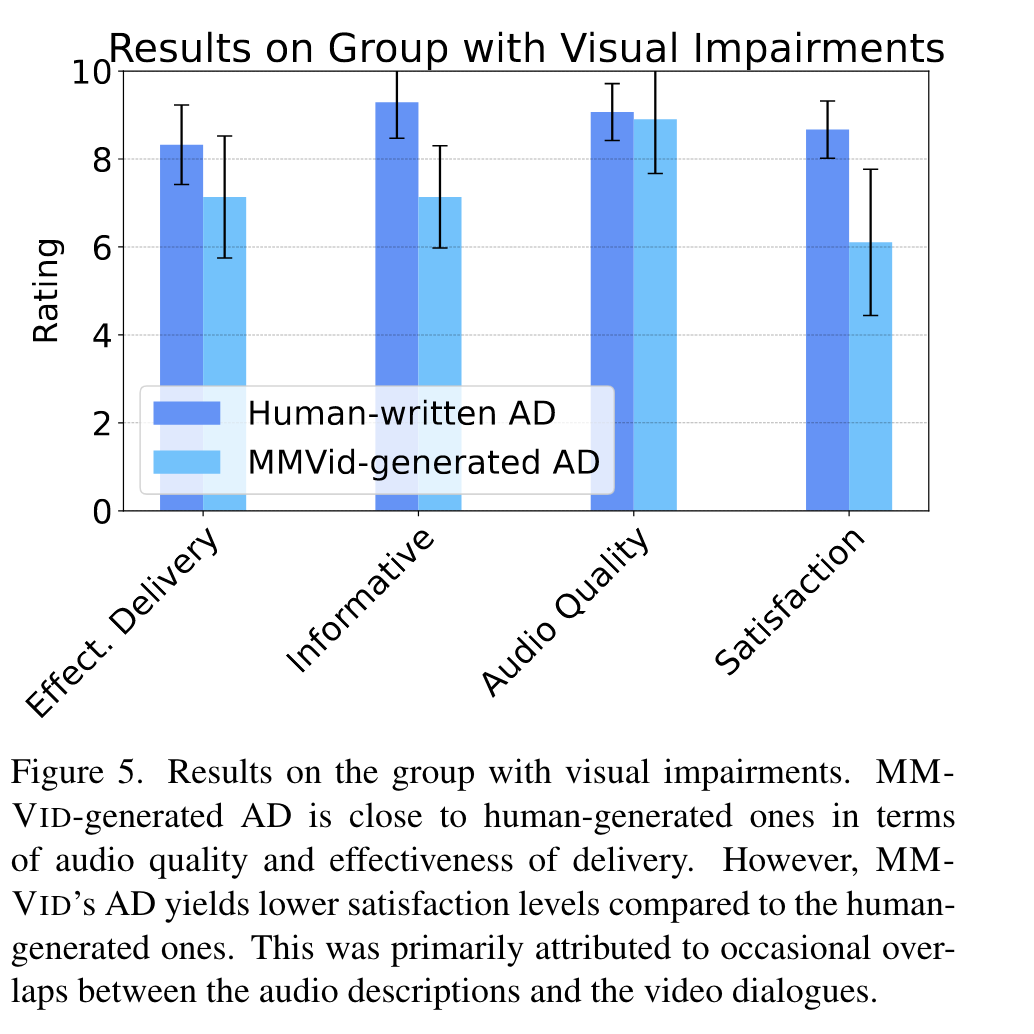
We explore the potential of MM-VID for people who are blind or have low vision. (p. 7)
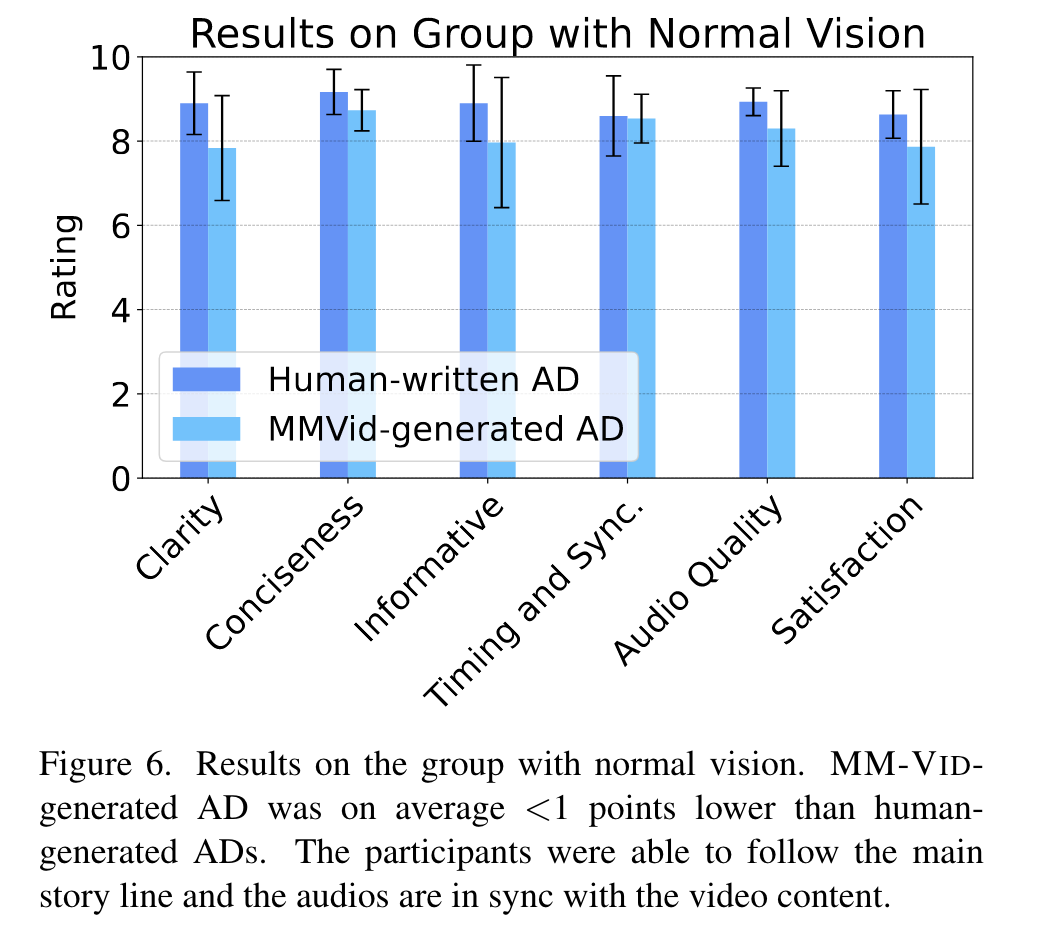
For every video used in our evaluation, participants are exposed to two versions: the first containing human-crafted AD and the second powered by MM-VID-generated AD. Both renditions are narrated using text-to-speech (TTS) technology. We have designed two questionnaires for the two groups, referenced in Table 1 and Table 2, respectively. Participants with visual impairments are instructed to base their evaluation exclusively on auditory cues. In contrast, those with normal vision are instructed to consider both visual and auditory elements. (p. 7)
Some of the difficulties indicated by participants while listening to MM-VID-generated ADs were 1) occasional overlaps between AD audio and original video dialogues 2) wrong descriptions due to hallucinations of GPT-4V(ision). Regardless of the difference in overall satisfaction, all the participants agreed that MM-VID-generated AD can provide a cost-effective and scalable solution. (p. 8)