mPLUG-Owl2 Revolutionizing Multi-modal Large Language Model with Modality Collaboration
[llm multimodal deep-learning mplug-owl2 cog-vlm frozen llm attention sft supervised-finetuning ofa clip pali qwen-vl unified-io flamingo coca simvlm beit git instruct-blip This is my reading note for mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. This paper proposes a method to unify visual and text data for multi modal model. To this end, it uses QFormer to extract visual information and concatenate to text and feed to LLM. However, it separates the projection layer and layer norm for visual and text. This paper is similar to COGVLM.
Introduction
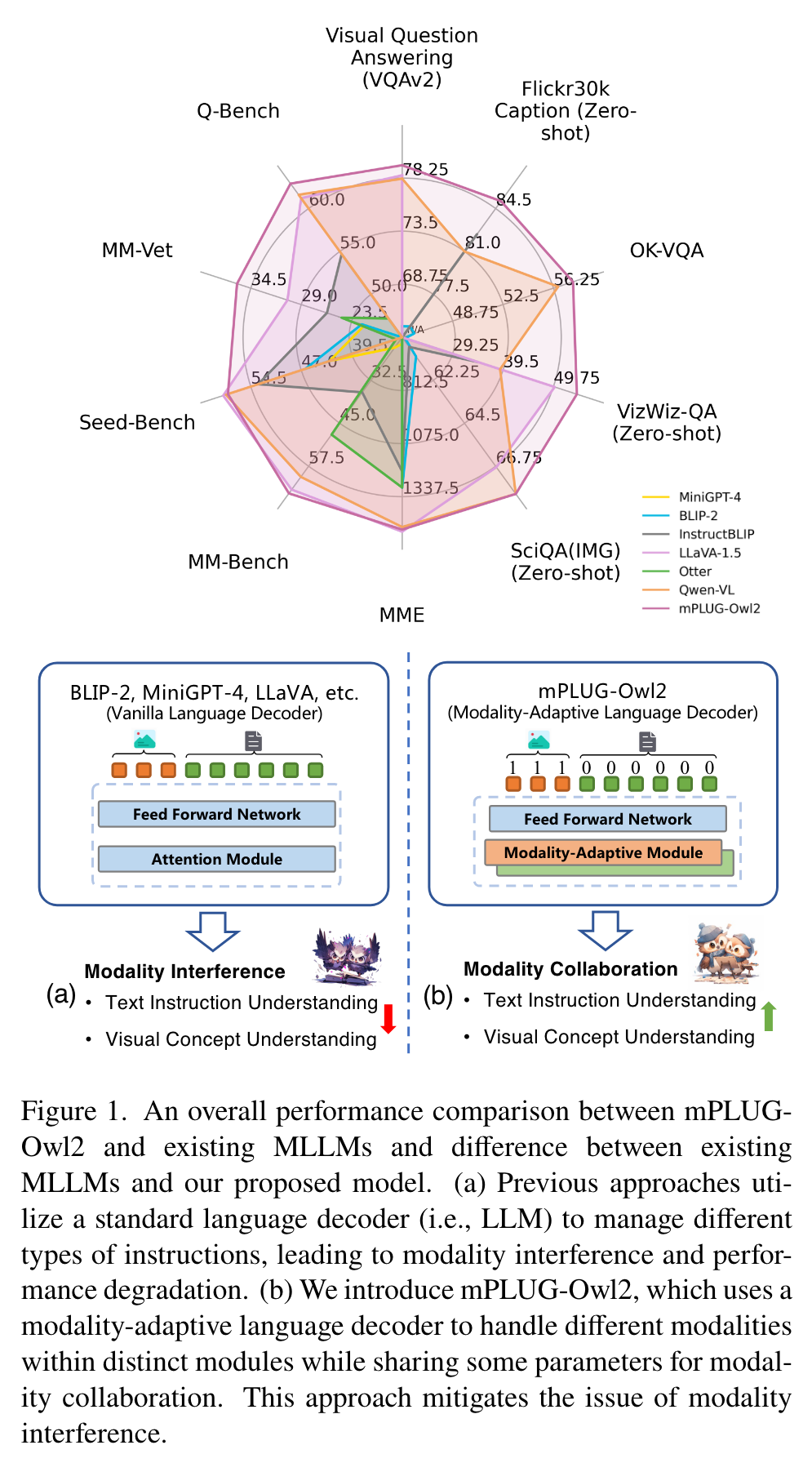
In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. (p. 1)
Previous studies [27, 63] in multi-modal learning suggest that different modalities can effectively collaborate, thereby enhancing the performance of both text and multi-modal tasks simultaneously. Recent works utilize cross-modal alignment modules (e.g., Q-former [15, 31, 75] and linear layer [10, 38]) to map visual features from the vision encoder into the frozen LLMs to carry out multi-modal tasks by leveraging preserved language capabilities. some researchers [38, 68] opt to fine-tune LLMs during multi-modal instruction tuning. While fine-tuning significantly improves multi-modal tasks, it risks weakening text task performance [16]. (p. 2)
Specifically, mPLUG-Owl2 incorporates certain shared functional modules to promote modality collaboration and introduces a modality-adaptive module that serves as a pivot across different modalities. Therefore, vision and language modalities are projected into a shared semantic space for crossmodality interaction, while the proposed module helps preserve modality-specific features. (p. 2)
Related Work
For instance, Flamingo [2] is a forerunner in this area, using a frozen vision encoder and a large language model equipped with gated cross-attention for cross-modality alignment. In contrast, PaLM-E [16] integrates extracted visual features directly through linear layers into the pre-trained PaLM [12] model, which boasts 520 billion parameters, thereby leading to robust performance across numerous real-world applications. (p. 2)
One significant limitation of this method, however, is the creation of lengthy visual sequences. To address this, BLIP-2 [31], drawing inspiration from DETR [8], developed a Q-former to reduce the sequence length of visual features efficiently. (p. 2)
Nevertheless, it should be noted that these methods directly align the visual features with the LLMs, treating vision and language signals as equivalent, thereby overlooking the unique granularities between vision and language modalities. (p. 2)
Methodology
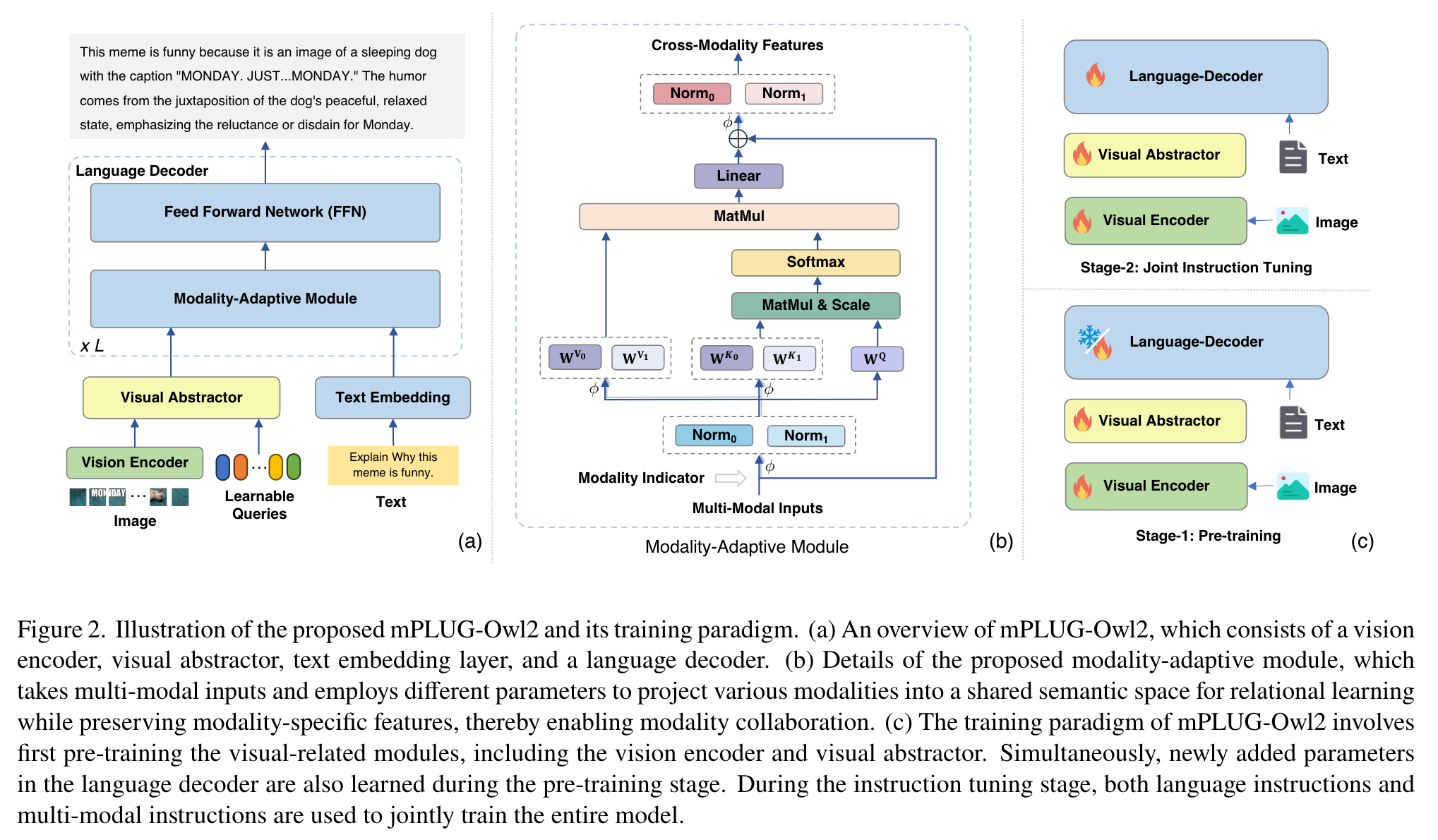
Model Architecture
Specifically, we utilize ViT-L/14 as the vision encoder and LLaMA-2-7B [58] as the language decoder. These visual token features are then combined with text token embeddings and fed into the language decoder. Additionally, to reduce the presence of abundant redundancy in the images (e.g., background, similar patches), Q-Former is used.
Moreover, to augment the fine-grained perception ability, we integrate sinusoidal positional embeddings with the image feature I and V (p. 3)
Modality-Adaptive Module
Prior approaches [15, 38, 68, 75] typically attempt to align visual features with language features by projecting image features into the language semantic space. However, this strategy can cause a mismatch in granularity , where image features often contain fruitful semantic information compared to the discrete semantic information within text embedding features. (p. 3)
modality indicators is used to separate visual tokens from text tokens. we first normalized different modalities into the same magnitude. Then, we reformulate the self-attention operation by leveraging separated linear projection layers for key projection matrix and value projection matrix while preserving query projection matrix shared as follows: (p. 4)
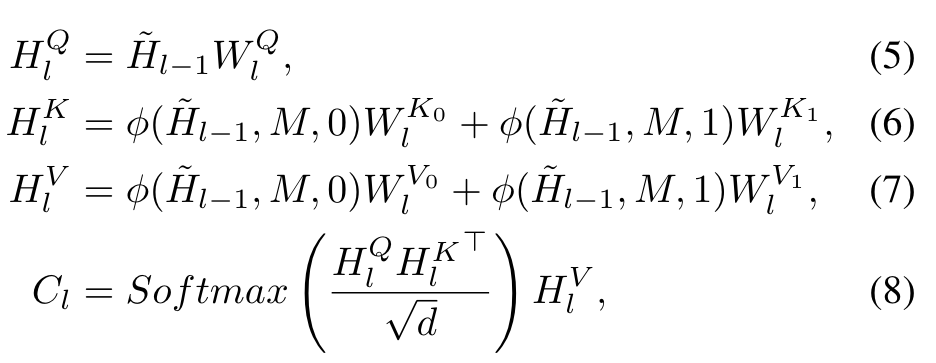
Training Paradigm
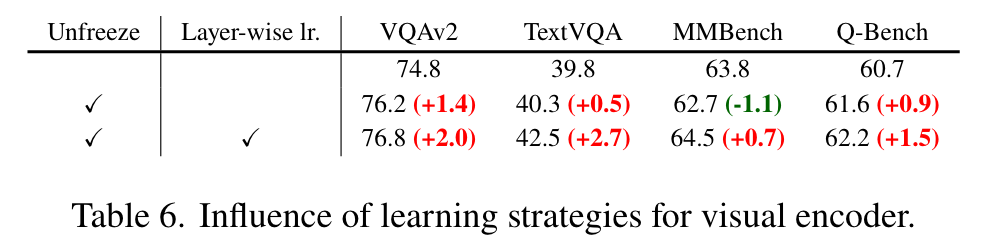
As depicted in Figure 2 (c), we employ a two-stage approach in training mPLUG-Owl2, comprising pre-training and visual instruction tuning similar to [38, 68], which aims to align the pre-trained vision encoder and language model during the pre-training phase, and then fine-tune the language model with language modeling loss during the instruction tuning phase. To address the issue, we make the vision encoder trainable throughout both the pre-training and instruction tuning stages. (p. 4)
Experiment
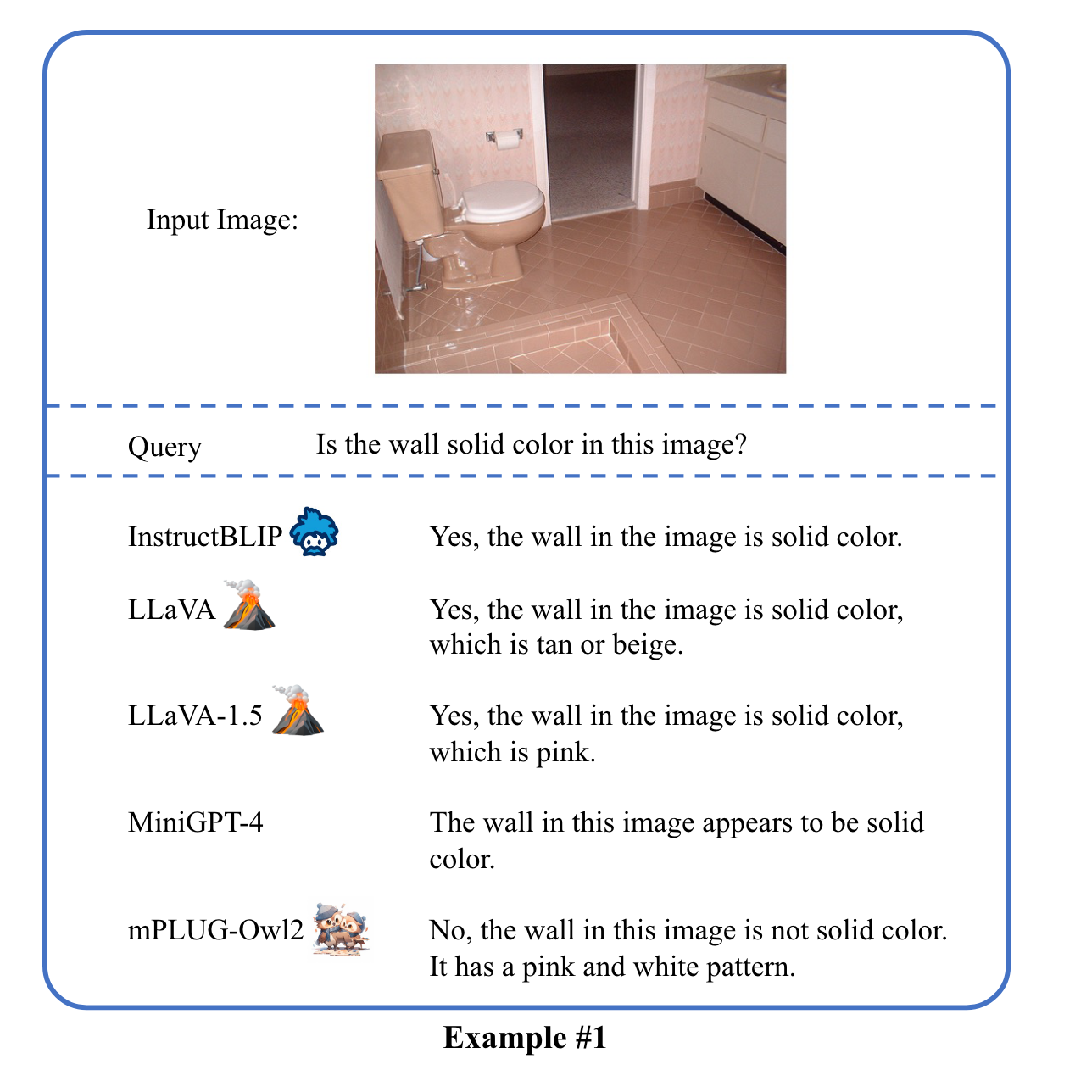
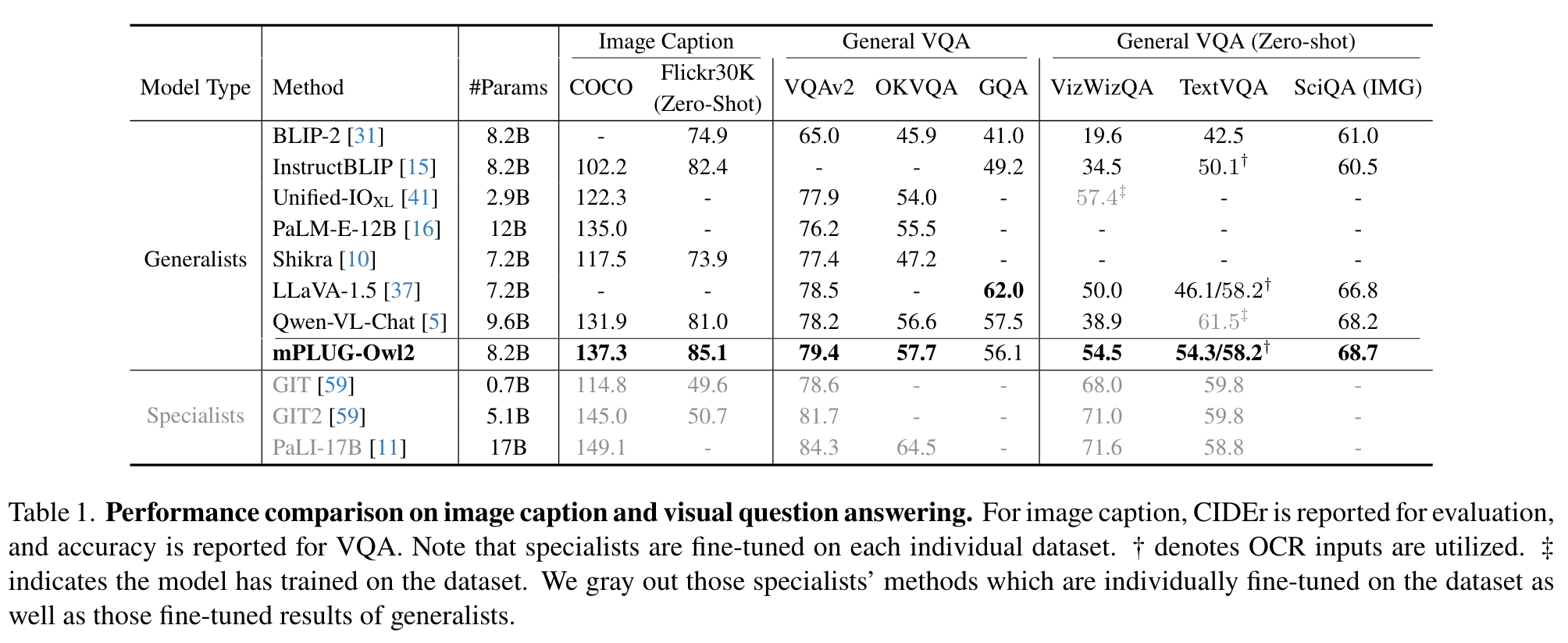
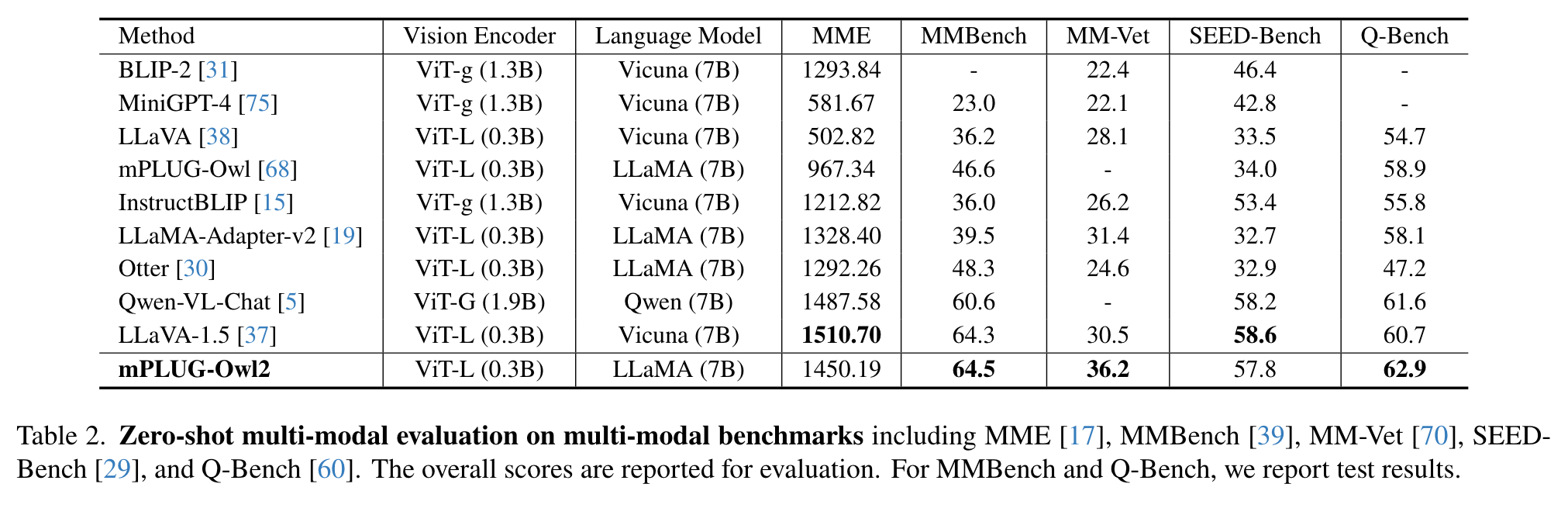
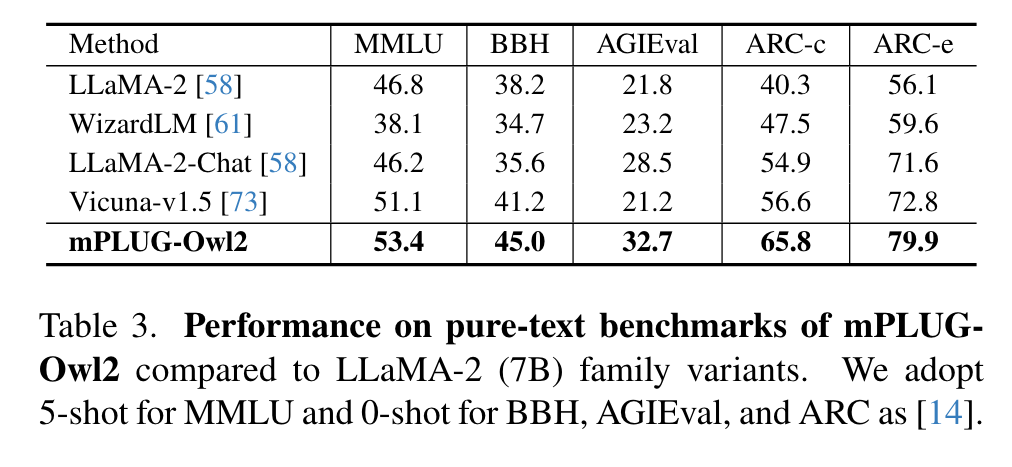
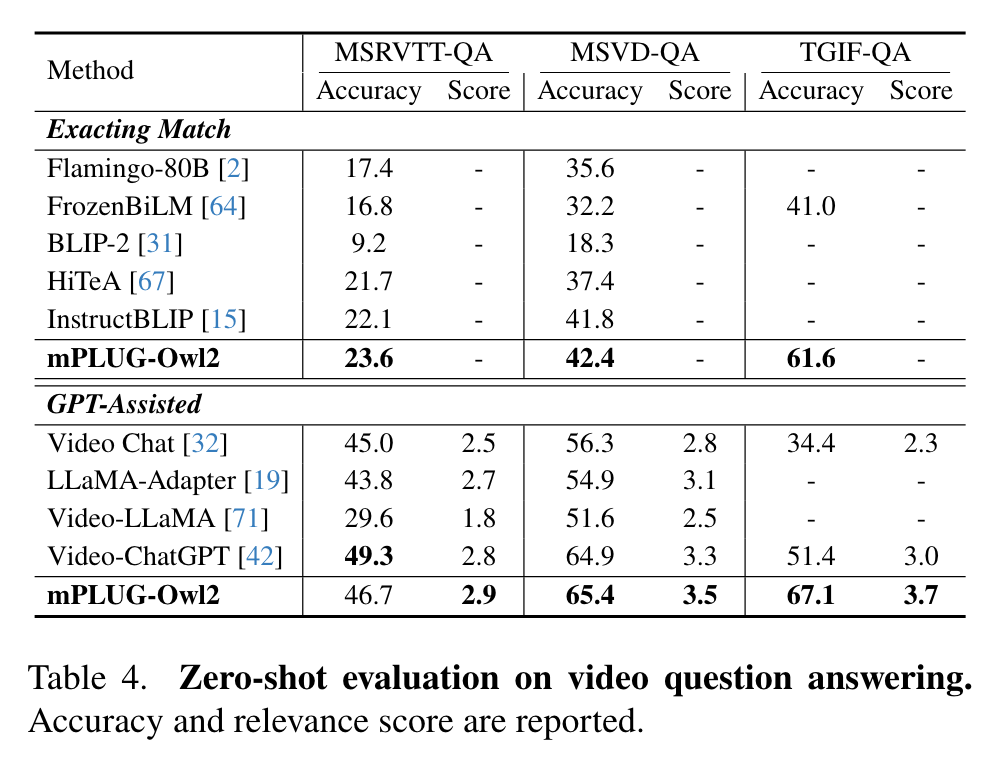
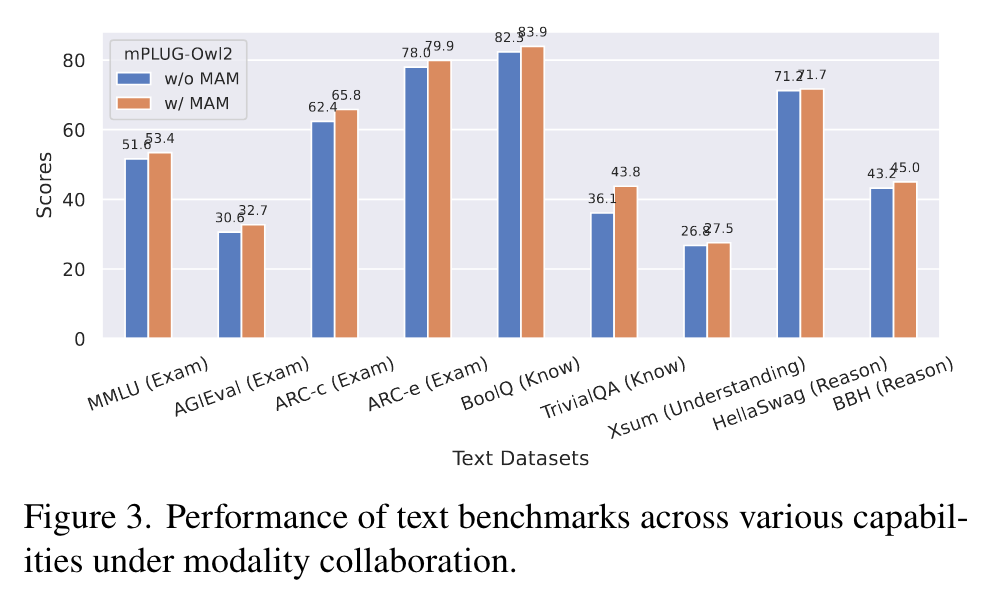
Ablation
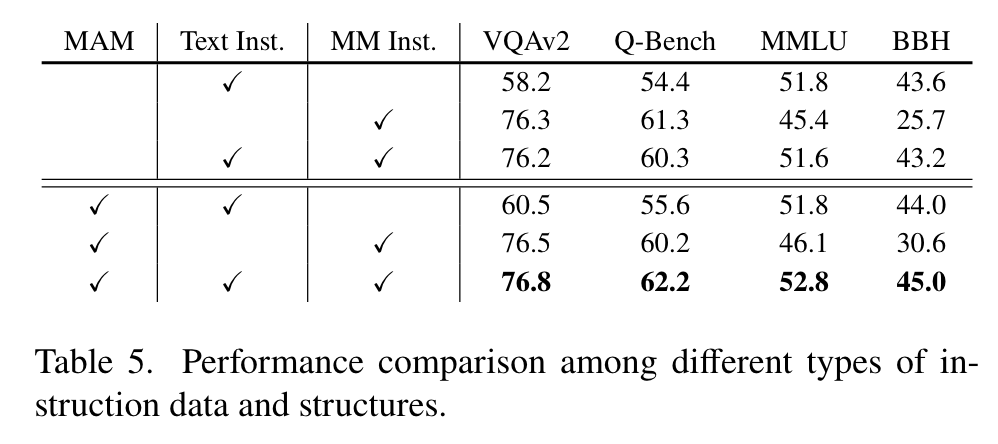
Impact of Number of Learnable Queries
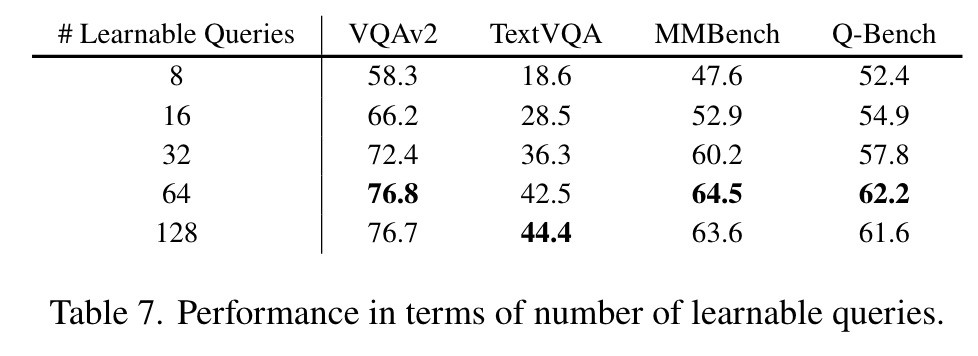
It can be observed that the model consistently exhibits improvement as the number of learnable queries increases until it reaches a saturation point, suggesting that 64 may be the optimal number for representing an image. (p. 8)
Impact of Image Resolution
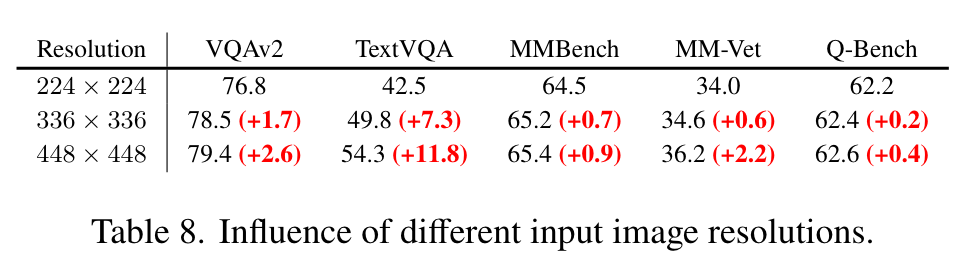
As observed in the table, using a higher resolution proves advantageous for multi-modal tasks, particularly in the question answering scenario. (p. 8)
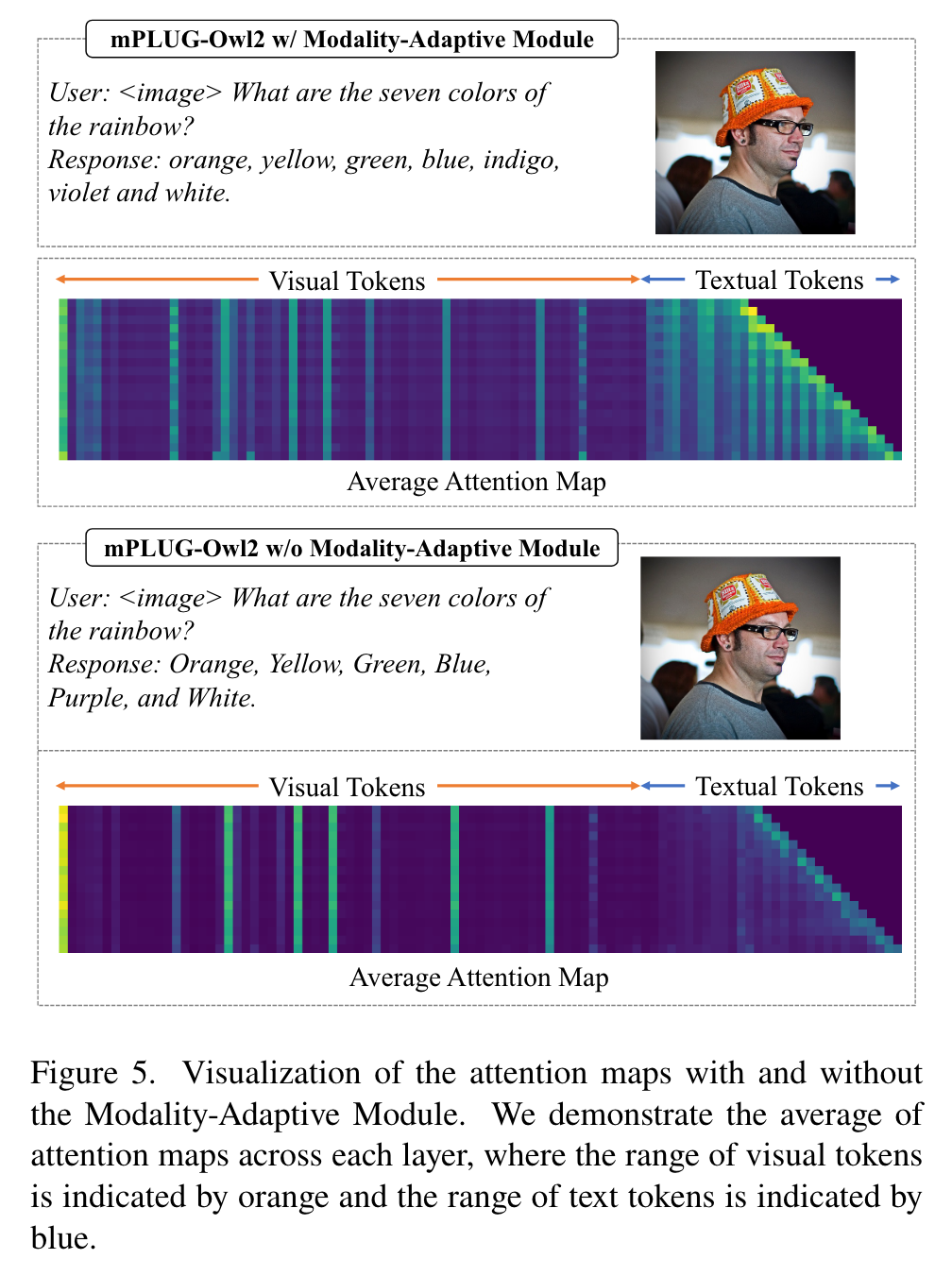
Impact of Modality-Adaptive Module in Multi-Modal Scenario
It can be observed that regardless of whether the Modality-Adaptive Module is incorporated or not, the model focuses more on the textual tokens in the earlier layers while paying more attention to the visual tokens in the later layers. This suggests that the modeling of visual and textual information plays different roles in the collaboration of multimodal language models (MLLMs). An intuitive explanation is that MLLMs initially use syntactic information to comprehend instructions and then identify relevant visual content tokens by considering the textual input. (p. 8)
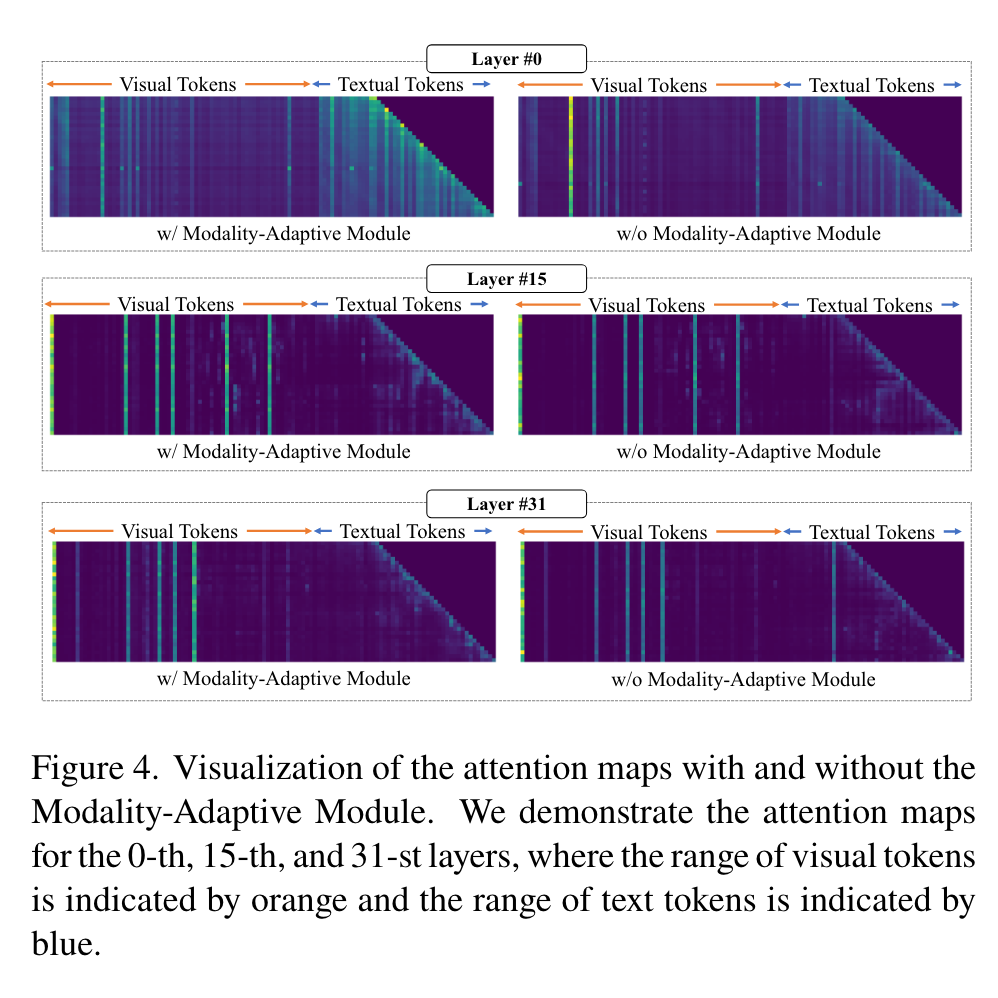
When using the Modality-Adaptive Module, it can be observed that the model explicitly pays more attention to the textual content in the earlier stages and focuses more on the visual content in the later stages. The Modality-Adaptive Module prevents visual and textual tokens from being treated as the same and encourages collaboration between different modalities (p. 8)
Impact of Modality-Adaptive Module in UnrelatedModality Scenarios
During the generation process, it can be observed that the model primarily focuses on the textual input (p. 8)