Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey
[masked-language-modeling multimodal contrast-loss masked-image-modeling deep-learning review image-text-matching pretrain foundation-model This is my reading note for Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey. It provides an OK review for multimodality pre-trained models without diving too much into details.
Background
Such a pre-training scheme take full advantage of the large-scale unlabeled data, therefore, getting rid of expensive annotation costs. (p. 4)
Pre-training in Natural Language Processing
The large-scale pre-trained models [29, 43, 44, 5356] first appeared in the NLP field. Their success is mainly attributed to self-supervised learning and network structures like Transformer [9]. XLNet [14] is developed based on a generalized permutation language modeling objective, which achieves unsupervised language representation learning. (p. 5)
Pre-training in Computer Vision
Chen et al. [63] attempt to auto-regressively predict pixels using a sequence Transformer. The model obtained by pre-training on the low-resolution ImageNet dataset demonstrates strong image representations. The ViT (Vision Transformer) model [64] directly adopts the pure Transformer to handle the sequence of image patches for classification. (p. 5)
For the pre-training methods, the Masked Image Modeling (MIM) [63, 64] is proposed to learn rich visual representations via masked parts prediction by conditioning on visible context. MIM provides another direction for the exploration of the visual large-scale pre-training model. He et al. propose the MAE [68] to re-explore pixel regression in MIM and show more comparable performance on multiple image recognition tasks. BEiT [69] greatly improves MIM’s performance via masked visual token prediction, and PeCo [70] finds injecting perceptual similarity during visual codebook learning benefits MIM pre-trained representation. (p. 5)
Pre-training in Audio and Speech
For example, the wav2vec [71] is the first work that applies contrastive learning to improve supervised speech recognition by learning the future raw audio based on the past raw audio. The vq-wav2vec [71] uses context prediction tasks from wav2vec to learn the representations of audio segments. DiscreteBERT [72] is BERT-style model by finetuning the pre-trained BERT models on transcribed speech. HuBERT [73] uses self-supervised speech learning where an offline clustering step is used to generate discrete labels of masked speech signals. wav2vec 2.0 [74] solves a contrastive task to predict the masked latent representation. w2v-BERT [75] uses contrastive learning and masked speech modeling simultaneously, where a model predicts discretized speech tokens and another model solves a masked prediction task. (p. 5)
Multi-Modal Pre-training
Key Challenges
The widely used contrastive learning, modality based matching, and modality translation are all valid and meaningful attempts. How to design new multi-modal pretraining objectives is one of the most challenging tasks for MM-PTMs. (p. 6)
Advantages of MM-PTMs
Therefore, the MM-PTMs can help extracting the common features of multimodalities. (p. 7)
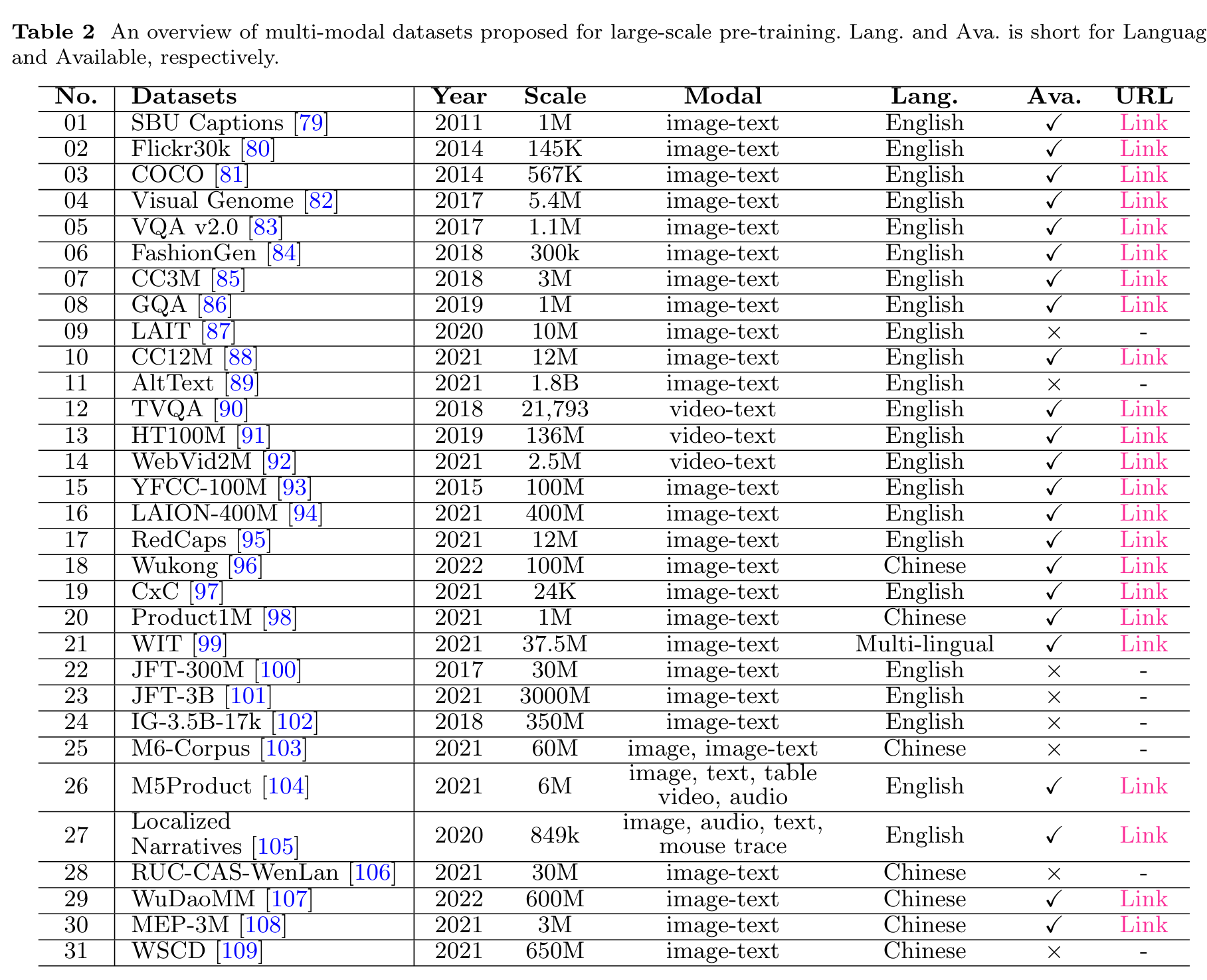
Dataset
Pre-training Objectives
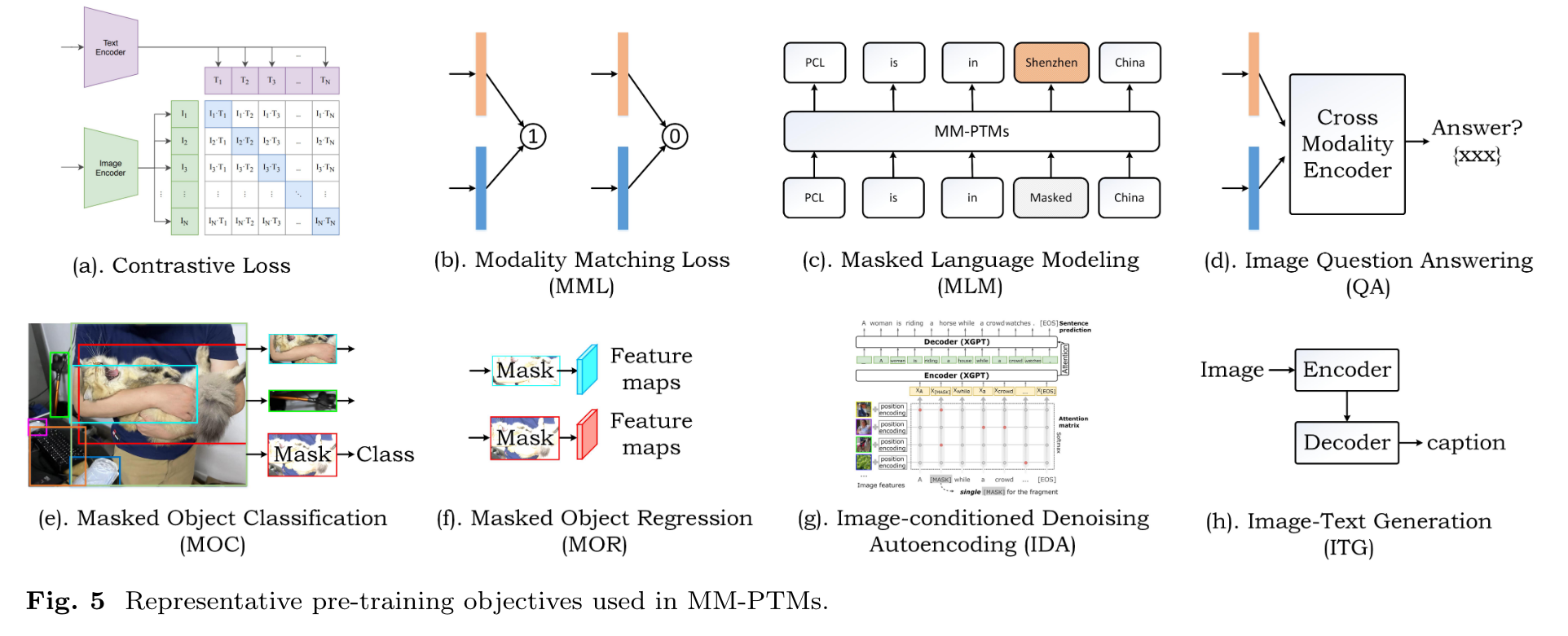
Some notable loss functions are described below:
- Contrastive loss (CS) function usually constructs positive and negative training samples which is widely used in dual-modality. For example, CLIP [77], ALIGN [21] are all trained using contrastive learning loss. (p. 10)
- Modality Matching loss (MML). They extract the positive and negative image-sentence pairs and train their model to predict whether the given sample pairs are aligned or not (in other words, to predict the matching scores). Different from regular negative image-text samples, the authors of InterBERT [115] design the image-text matching with hard negatives (i.e., ITM-hn) by selecting the highest TF-IDF similarities. (p. 10)
- Masked Language Modeling (MLM) is another widely pre-training objective, usually, the researchers usually mask and fill the input words randomly using special tokens. The surrounding words and corresponding image regions can be used as a reference for the masked word prediction. Wang et al. train SIMVLM [116] using the Prefix Language Modeling (PrefixLM), which executes the bi-directional attention on the prefix sequence and auto-regressive factorization on the rest tokens, respectively (p. 10)
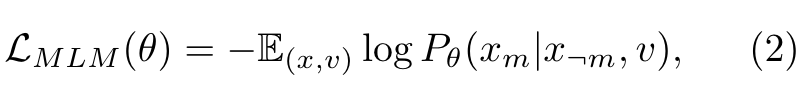
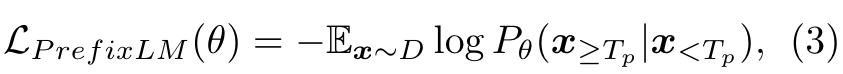
- Image Question Answering (QA) is used in LXMERT [117] to further expand the pretraining data, as many image-sentence pairs are image and question. The authors train their model to predict the answers as one of their pre-training objectives. (p. 11)
- Masked Object Classification (MOC) mainly focuses on masking the visual images using zero values. Then, people often take the predicted labels by object detector as the ground truth labels. (p. 11)
- Masked Object Regression (MOR) is implemented to regress the masked feature or image regions. (p. 11)
- Word-Region Alignment (WRA) is used in UNITER [18] which target at explicitly achieves the fine-grained alignment between the multimodal inputs via Optimal Transport (OT) [120]. Specifically, the authors learn a transport plan which is a 2D matrix to optimize the alignment and resort to the IPOT algorithm [121] for approximate OT distance estimation. Then, the authors take this distance as the WRA loss to optimize their networks. (p. 12)
- Image-conditioned Denoising Autoencoding (IDA) is adopted in XGPT [11] to align the underlying image-text using an attention matrix. (p. 12)
- OBject Detection (OBD) is introduced in the [125] as a direct set prediction to enhance the pre-training. Also, the authors consider object attribute prediction to learn the fine-grained semantic information. (p. 12)
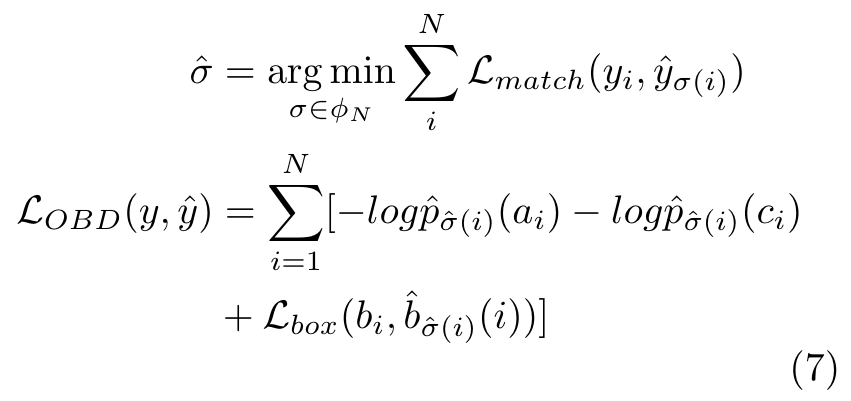
- Image-Text Generation (ITG): The aligned image and text are capable of training a model for text generation based on a given image (p. 12)
- Video-Subtitle Matching (VSM) considers two targets for the video-text pre-training task, i.e., (i) local alignment, (ii) global alignment, as used in HERO [126]. (p. 13)
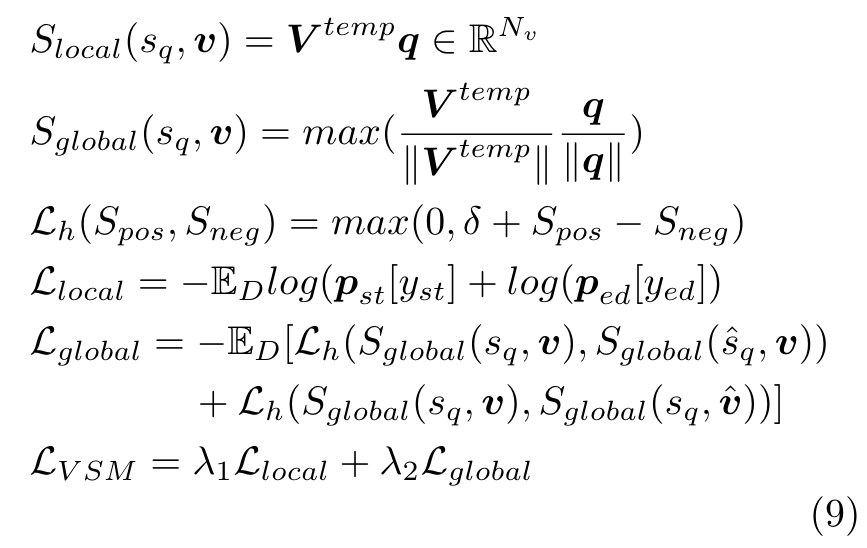
- Frame Order Modeling (FOM) is treated as a classification problem in HERO [126], which targets reconstructing the timestamps of selected video frames. (p. 13)
Pre-training Network Architecture
According to the manner of multi-modal information fusion, two categories of MM-PTMs can be concluded, i.e., single- and cross-stream. In this subsection, we will present these two architectures separately.
Single- and Multi-stream
Single-stream
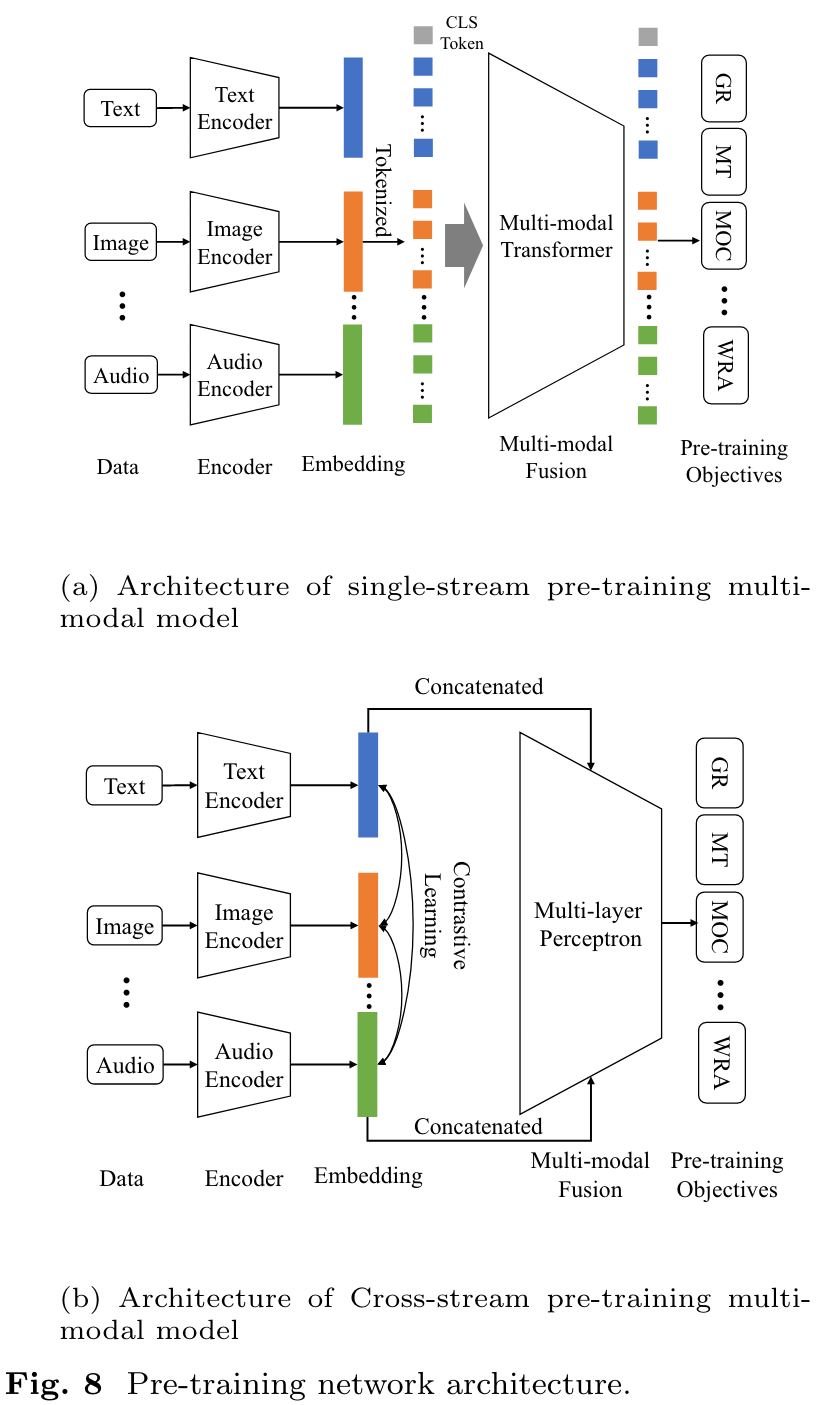
Multi-modal inputs such as images and text are treated equally and fused in a unified model. The uni-modal features extracted from each modality are tokenized and concatenated by the separators as the input of the multi-modal transformer for multi-modal fusion, as shown in Fig. 8(a). In the transformer, the MHSA (multi-head self-attention) mechanism is usually adopted to interactively fuse the unimodal features, then, the multi-modal fusion features are output from the class token of the transformer. (p. 14)
Single-stream pre-training models perform token-level matching based on strong semantic correlation, e.g. object features of the image are matched with semantic features of object tags. It provides realistic interaction between uni-modal features, and multi-modal fusion features contain information from different modalities with better characterization capability. (p. 14)
Cross-stream
Features of different modalities are extracted in parallel by independent models and then are aligned by self-supervised contrastive learning in cross-stream architecture. The pre-training models obtain aligned uni-modal features rather than fused multi-modal features. (p. 14)
Compared with pre-training models based on single-stream, cross-stream models align different modality features into a consistent high-dimensional feature space, such as text semantics and visual image representation. Cross-stream pre-training models generally contain the CS pre-training objective and achieve embedding-level matching based on “weak semantic correlation” [106]. The structure of cross-stream models is more flexible, and modifying the branching structure of one modality of the model does not affect other modalities, making it easy to deploy in real scenarios. However, cross-stream models extract the aligned multimodal common features, and how to effectively exploit the information differences and complementarity between multi-modal data is an issue to be studied. (p. 15)
In addition, depending on the needs of the pretraining objectives, the structure of pre-training models can be divided into with and without a decoder. If pre-training objectives contain generative tasks, such as masked image reconstruction, generating matching images based on the text description, etc., the pre-training model adds a decoder after the encoder for converting multimodal fusion features into the corresponding output. (p. 15)
Modality Interactive Learning
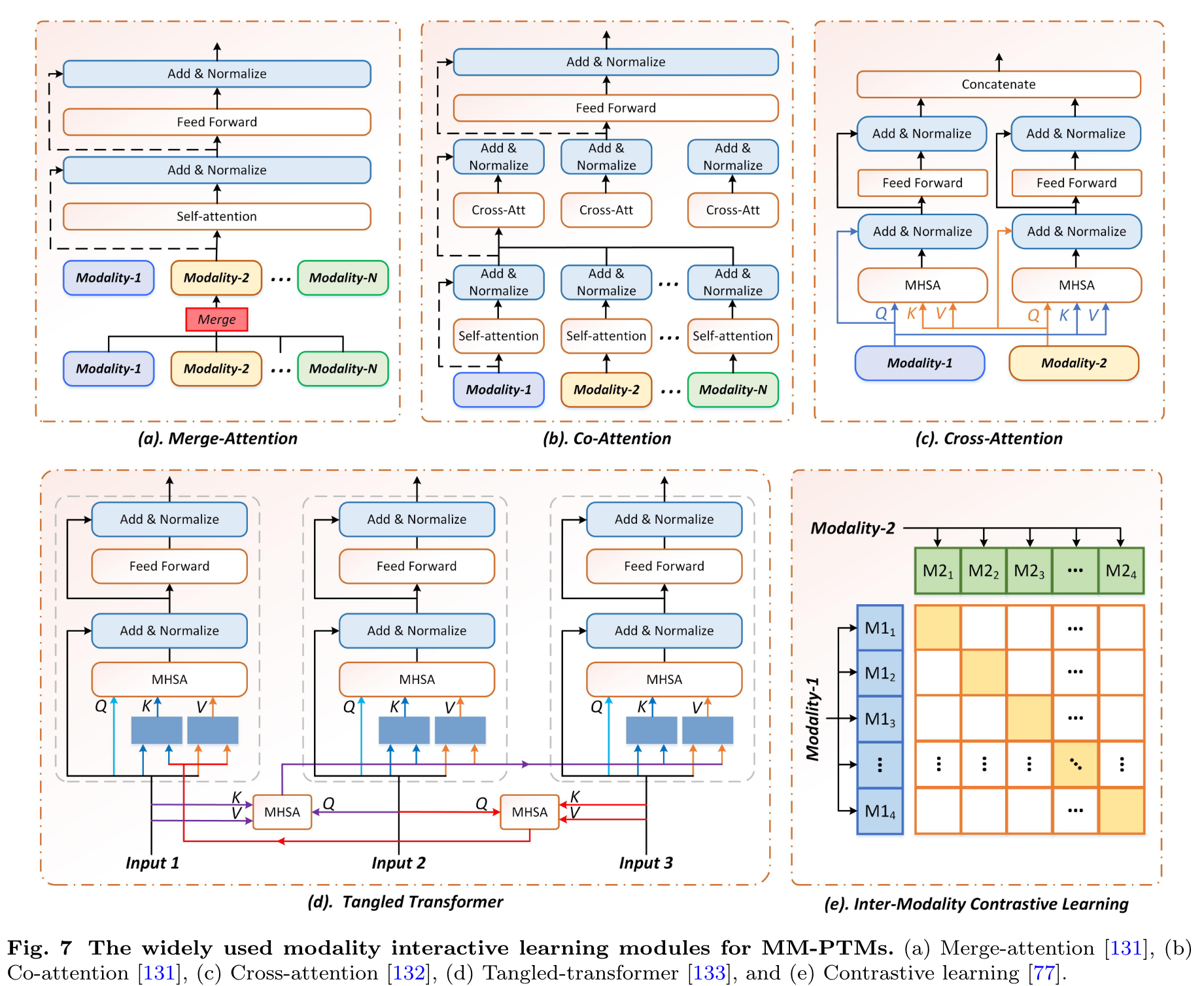
Most of current large-scale pre-trained multimodal models adopt concatenate, add, Mergeattention, Co-attention, and Cross-attention [132] to achieve interactive learning between modalities. (p. 15)
- Merge-attention: As shown in Fig. 7 (a), a unified feature representation is obtained by concatenating the input modalities. Then, this feature is fed into the fusion network. (p. 15)
- Co-attention: For the co-attention module, as shown in Fig. 7, each input modality has its own self-attention layers for modality-specific feature embedding. Then, the multiple embeddings are fused using a cross-attention layer. (p. 15)
- Cross-attention. Specifically, they mutually input one modality into the Q-branch of another self-attention network. Then, the output of two modalities are concatenated as one unified representation for final prediction. (p. 15)
- Tangled-transformer. As shown in Fig. 7 (d), the authors inject one modality to the Transformer network designed for other modality to enhance the interactions. (p. 15)
Pre-training using Knowledge
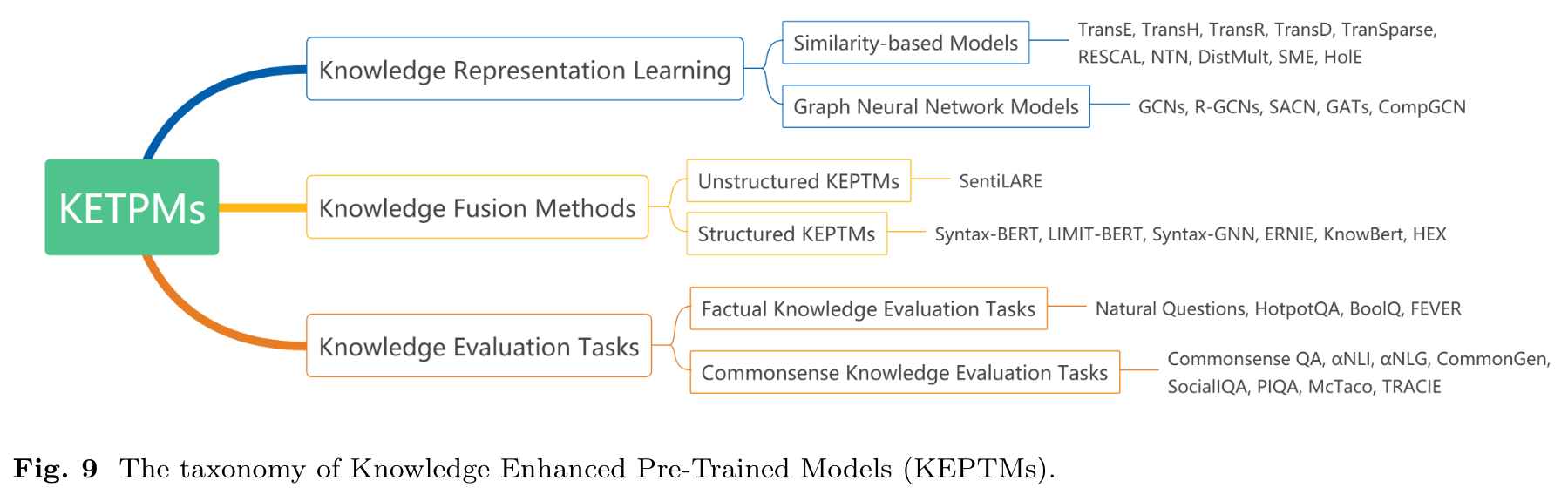
Conventional pre-trained models suffer from poor logical reasoning and lack of interpretability. To alleviate those problems, it is straightforward to involve knowledge, deep understanding of data, in pre-training models, i.e., pre-training using knowledge also known as Knowledge Enhanced Pre-Trained Models (KEPTMs) shown in Fig. 9. (p. 15)
Knowledge Representation Learning
By learning to represent symbolic knowledge, usually in the form of entities and relations, knowledge representation learning enables neural network based models to fuse knowledge and improve their reasoning capabilities. Similarity-based models and graph neural network (GNN) models are two major methods of knowledge representation learning. (p. 15)
Knowledge Fusion Methods
How to fuse knowledge into pre-trained models and improve their logical understanding of data after knowledge representation learning remains a challenge to researchers. According to the category of knowledge provided, KEPTMs roughly contain two categories: unstructured knowledge and structured knowledge enhanced pre-trained models. (p. 20)
Structured KEPTMs
Contrary to unstructured KEPTMs, structured KEPTMs take account of sorts of structural information, including syntax-tree, rules and knowledge graphs. (p. 20)
Factual Knowledge
Evaluation Tasks Factual knowledge is the knowledge of facts, including specific details and elements to describe the objective facts [28]. Factual knowledge evaluation tasks focus on testing models’ reasoning ability on factual knowledge over various domains, like answering questions by giving a fact or judging the correctness of a given fact. (p. 21)
Commonsense Knowledge Evaluation Tasks
Commonsense knowledge refers to the information generally accepted by the majority of people concerning everyday life, i.e. the practical knowledge about how the world works [29]. Like factual knowledge evaluation tasks, Commonsense QA also focuses on QA, but such QA requires prior knowledge outside the given document or context [232]. (p. 21)
Characteristics of Different Pre-trained Big Models
Specifically, the early multi-modal pre-trained big models usually design an interactive learning module, for example, the ViLBERT [140], LXMERT [117]. They integrate the co-attention or cross-attention mechanism into their framework to boost the feature representation between multiple inputs. (p. 22)
This allows for seamless integration with numerous downstream tasks and providing a high degree of flexibility. In contrast, many current big models directly process the inputs using projection layers and feed them into a unified network like the Transformers, including UnicoderVL [114], VideoBERT [158], UniVL [160]. More and more works demonstrate that the powerful Transformer network can achieve comparable or event better performance. (p. 22)
Research Directions
Incremental Learning based Pretraining
pre-training is an expensive process. When we gathered another group of data, the pre-training on the mixed data are expensive, redundant, and not environmentally friendly. However, seldom of them consider incremental learning for big models, and it is still unclear if the incremental learning algorithms developed for traditional deep learning work well for big models. (p. 25)
Another interesting problem is modality incremental learning, in another word, how to introduce and absorb the new modality into the already pre-trained multi-modal model. (p. 25)
Fine-grained Multi-Modal Pretraining
Most existing MM-PTMs are pre-trained from a global-view, for example, the researchers adopt the matching between the whole image and language as a supervised signal for the pre-training. Note that, the fine-grained local information mining or instance level pre-training may further improve the overall performance of multi-modal pre-training. Some researchers have exploited the possibilities of fine-grained pre-training strategies [98]. (p. 25)
the users need to initialize their model using pre-trained weights, then, finetune on downstream tasks. Therefore, it exists a gap between multimodal pre-training and finetuning. Recently, a new framework (termed prompt learning) is developed for big model based downstream tasks, which slickly transforms the setting of downstream tasks to make them consistent with pretraining [266]. (p. 26)
Related Works