Octopus Embodied Vision-Language Programmer from Environmental Feedback
[octopus visprog tool-former multimodal llm reinforcement-learning robot dataset deep-learning tool viper-gpt hugging-gpt This is my reading note for Octopus: Embodied Vision-Language Programmer from Environmental Feedback. The paper proposes a method on how to leverage large language model and vision encoder to perform action in game to complete varying tasks.
Introduction
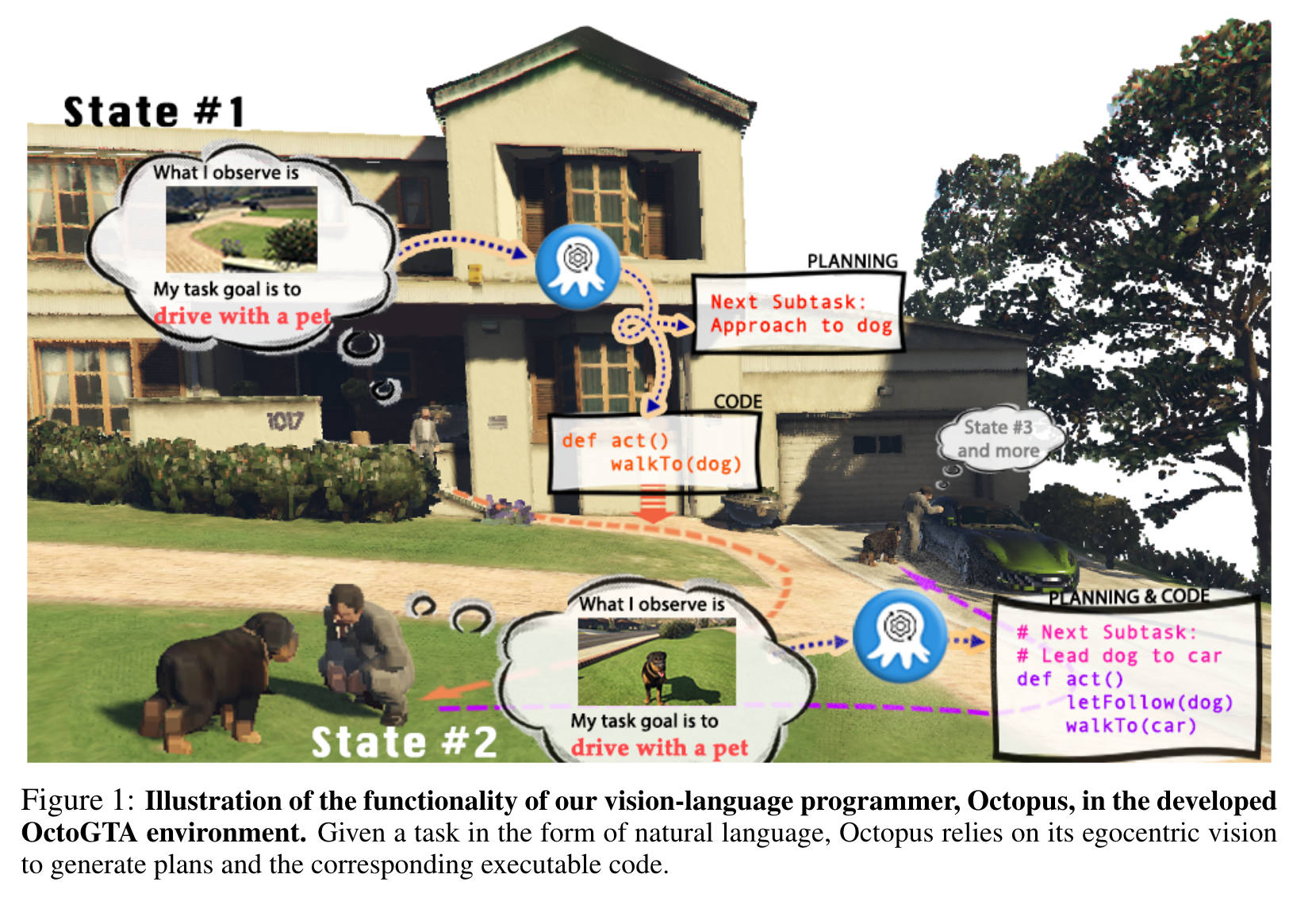
Large vision-language models (VLMs) have achieved substantial progress in multimodal perception and reasoning. Furthermore, when seamlessly integrated into an embodied agent, it signifies a crucial stride towards the creation of autonomous and context-aware systems capable of formulating plans and executing commands with precision. In this paper, we introduce Octopus, a novel VLM designed to proficiently decipher an agent’s vision and textual task objectives and to formulate intricate action sequences and generate executable code (p. 1)
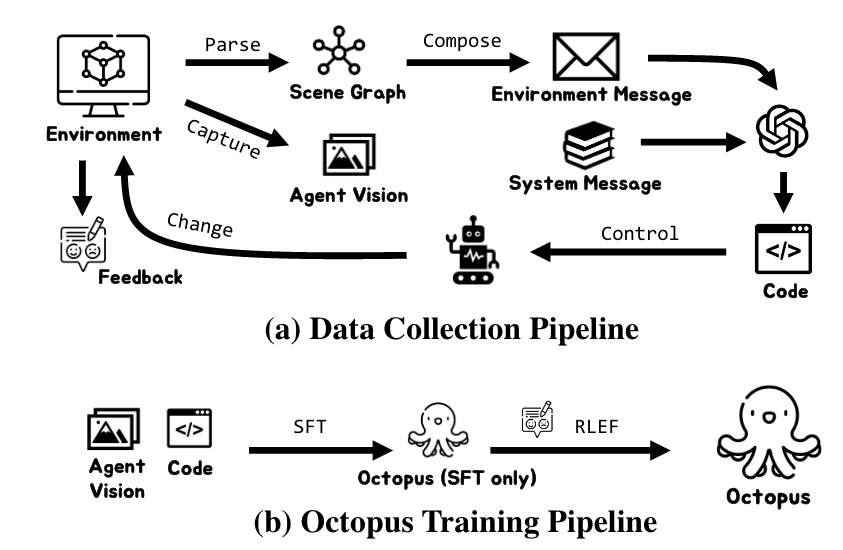
Octopus is trained by leveraging GPT-4 to control an explorative agent to generate training data, i.e., action blueprints and the corresponding executable code, within our experimental environment called OctoVerse. We also collect the feedback that allows the enhanced training scheme of Reinforcement Learning with Environmental Feedback (RLEF). (p. 1)
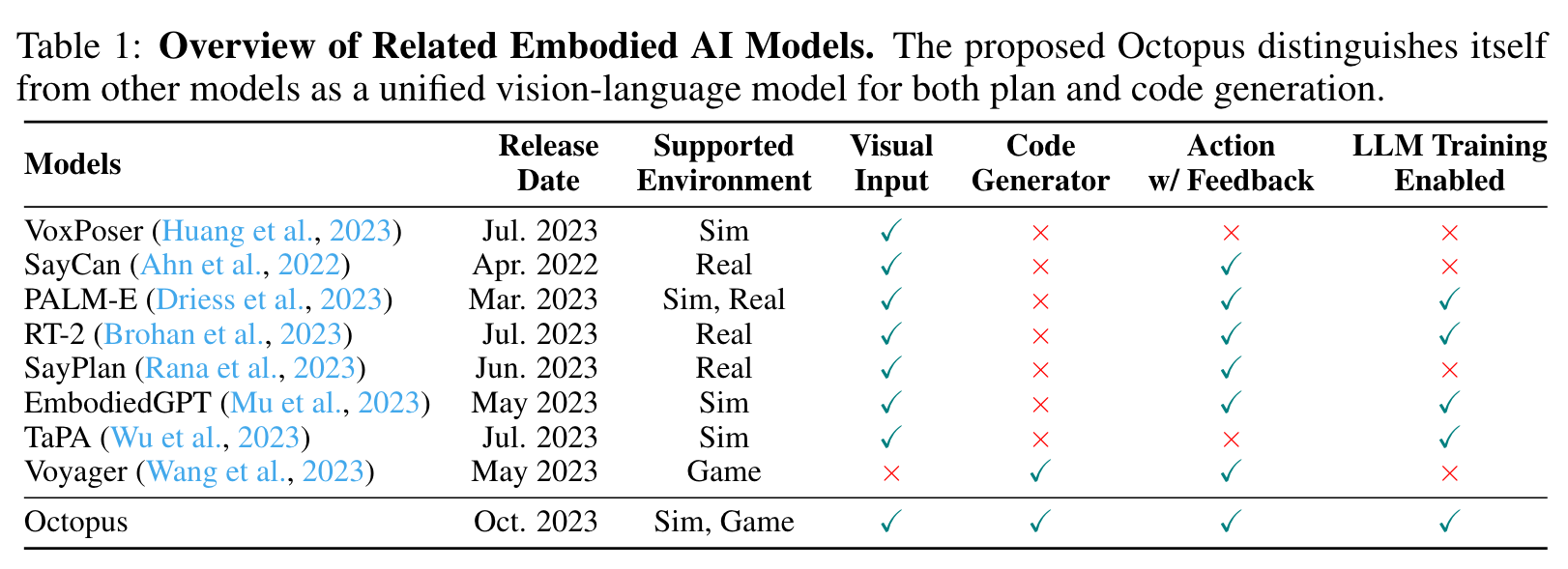
In fact, such a “programmatic” paradigm has been, although not in vision, leveraged by pioneering works such as ToolFormer (Schick et al., 2023), HuggingGPT (Shen et al., 2023), ViperGPT (Sur´ıs et al., 2023), and VisProg (Gupta & Kembhavi, 2023). They harness LLMs to craft programs and trigger relevant APIs. Game-centric models like Voyager (Wang et al., 2023) and Smallville (Park et al., 2023) have similarly employed GPT for function calls within game engines, though they often parse data directly from their environments (p. 2)
To empower Octopus with its vision-centric programming capabilities, we leveraged GPT-4 to collect training data within our experimental realm, the OctoVerse. Here, GPT-4 was provided with intricate system messages, extensive environmental cues, and clearly defined objectives. Based on this input, GPT-4 formulated crucial action strategies and their associated code. Meanwhile, the agent operating in the OctoVerse captured its visual perspectives. Octopus, fed by the collected data, stands out in generating code that seamlessly melds vision, language instruction, and action code. (p. 2)
During the data collection phase, the agent, guided by GPT-4, concurrently receives feedback from simulators about the efficacy of each executed code step, discerning successful moves from unsuccessful ones. This led us to incorporate the Reinforcement Learning with Environmental Feedback (RLEF) approach into our pipeline. Successful steps earn rewards, which are then used to train a reward model. (p. 2)
RELATED WORK
THE OCTOVERSE ENVIRONMENT AND DATA COLLECTION
OVERVIEW OF OCTOVERSE
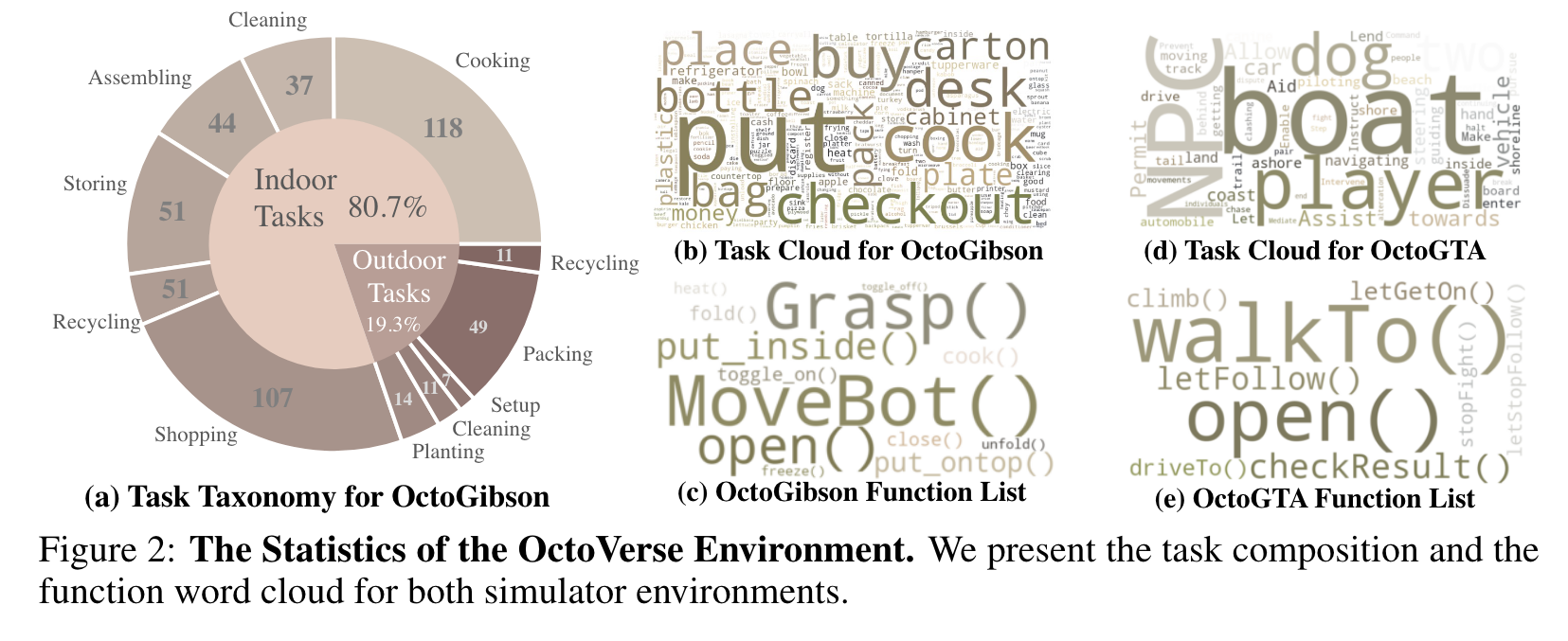
Each task begins with an initial state and concludes with a definitive termination state, allowing for a straightforward assessment of task completion. Conversely, the remaining 109 are reasoning tasks which necessitate deeper comprehension. An example is “buy a chocolate”, where the agent needs to know to pick a chocolate bar from the shelf and then place it, along with money, on the checkout counter. (p. 4)
INSTRUCTIONS FROM EXPLORATION
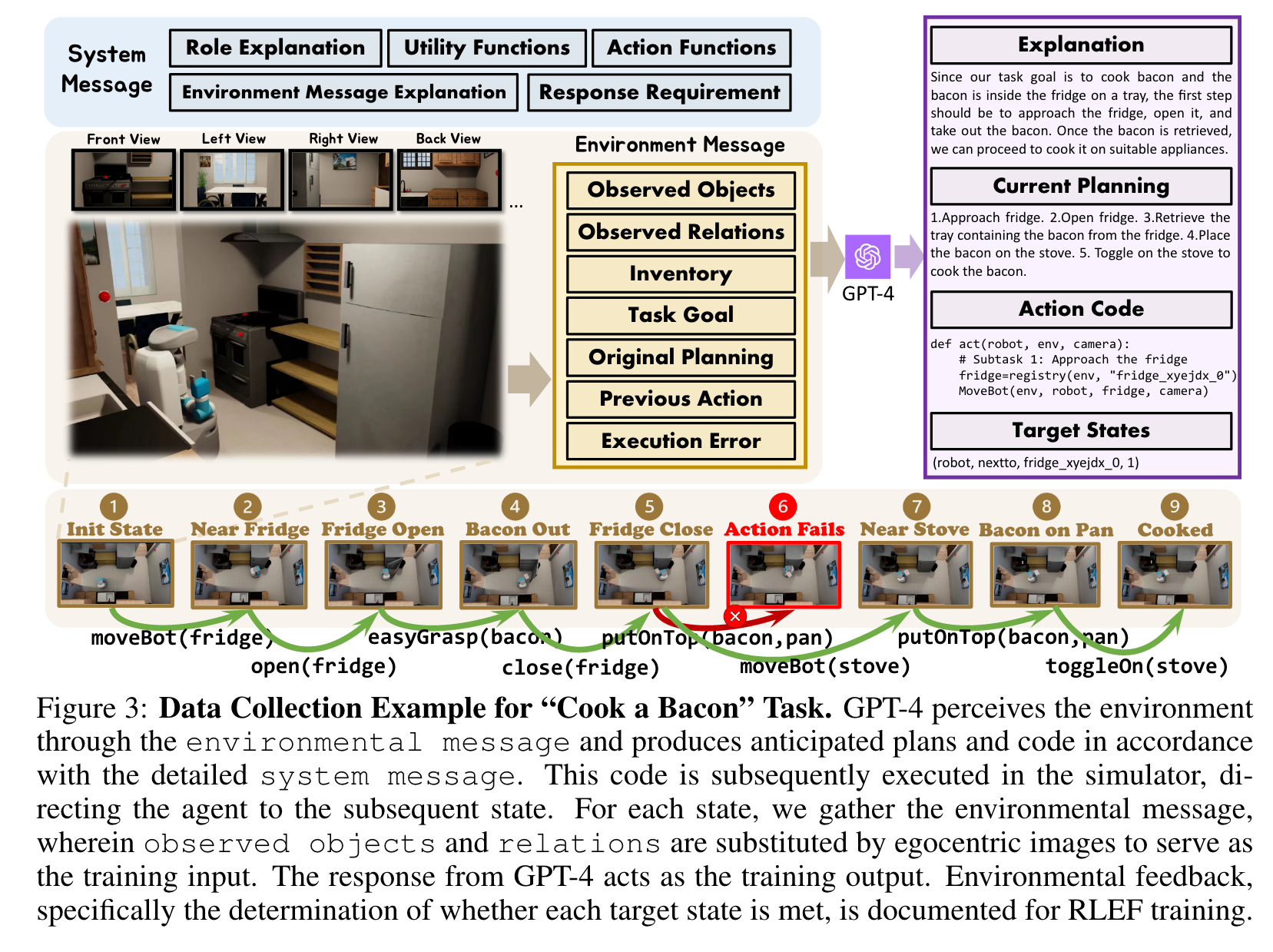
Thus, the primary task in organizing training data is to form a succinct pairing: “vision input + current/historical states → next step plan + executable code” (p. 5)
Having prepared the environment message, we next crafted a structured system message to ensure that the robot not only understands its input but also maintains a consistent output format. (p. 6)
It’s worth noting that the combined length of the system and environment messages can be extremely long. As a result, standard GPT-4 8K models may struggle to produce meaningful outputs, necessitating the use of the more robust GPT-4 32K model (p. 6)
Such setbacks reset the task to its previous state. If a task remains incomplete after 10 steps, it is deemed unsuccessful, and we terminate this task for budget concerns. All data pairs, regardless of the task’s completion status, are valuable resources for refining instructions. (p. 6)
ENVIRONMENTAL FEEDBACK
The automatic annotation of the feedback is twofold, focusing on both step-level and task-level judgments. Step-level judgment assesses the alignment of post-execution states with their target states. (p. 6)
One can visualize the action sequence for task completion as a tree, where each node indicates a step (subtask), encapsulating an action code. Accompanying each step is a binary value that denotes success or failure, giving preference to the successful branch over its counterpart. Tasklevel judgment, on the other hand, gauges the successful execution of the overall task. If the task is not completed as intended, every state within that task is labeled as negative. This collated feedback data serves as a foundation for our Reinforcement Learning with Environmental Feedback (RLEF) methodology, which we discuss in greater detail in Section 4.3. (p. 6)
THE OCTOVERSE DATASET
This training dataset encompasses 416 tasks, further divided into 3776 subtasks by GPT-4 exploration. For each subtask, beyond planning and executable code solutions, we capture 10 images representing the agent’s perspective: 8 are egocentric images (spaced every 45 degrees), and 2 are bird’s-eye view (BEV) images—one at a closer range and another at a greater distance. (p. 6)
OCTOPUS: THE EMBODIED VISION-LANGUAGE PROGRAMMER
ARCHITECTURE
At the core of Octopus is the seamless integration of two critical components: MPT-7B Language Decoder (MosaicML, 2023) and CLIP VIT-L/14 Vision Encoder (Radford et al., 2021). (p. 7)
To further enhance the synergy between the vision and language components, we have incorporated design principles from the Flamingo architecture (Alayrac et al., 2022). This is evident in our employment of the Perceiver Resampler module and the intricate weaving of Cross-Gated Attention modules. Initially, the Perceiver Resampler module ingests a sequence of image or video features to produce a fixed set of visual tokens. Subsequently, these tokens condition the language layers through Cross-Gated Attention modules, where the tokens act as keys and values while text from preceding layers serves as queries. (p. 7)
SUPERVISED FINETUNING WITH INSTRUCTIONS FROM EXPLORATION
We train the Octopus model on our collected dataset from OctoVerse DE = {(X_v, T_i, T_r)} with token-level supervised fine-tuning (SFT) (Ouyang et al., 2022; Touvron et al., 2023). The training objective involves next-token prediction, akin to GPT series models (Brown et al., 2020; OpenAI, 2023), additionally with the incorporation of visual and textual inputs. (p. 7)
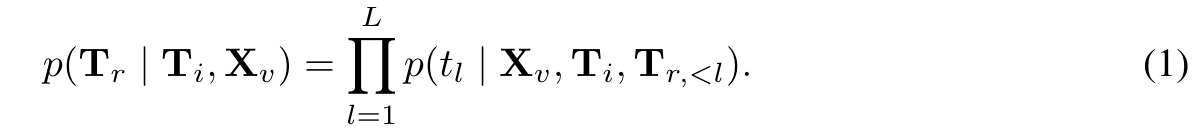
REINFORCEMENT LEARNING WITH ENVIRONMENTAL FEEDBACK (RLEF)
Tree-based Task Representation
We organize these data into environmental reward datasets DR = {(X^∗_v, T^∗_i , T^i_r, T^j_r, c)} where T^i_r and T^j_r are two responses on the tree with the same parental node’s task description T^∗_i , and c is the index of preferred response that could lead to final completion of the given task. (p. 7)
Reward Model Configuration
The function of this text-based reward model is to assess state transitions, denoted by T^∗i → T^{i,j} r , to determine which transitions yield higher rewards and thereby assist the agent in task execution and completion. (p. 8)
Policy Model Development
Next, we employ the above supervised fine-tuned model as the initial policy model (Ouyang et al., 2022) π^INIT with fixed parameters. Then we initialize another duplicate of the model as the RL-tuned model π^RL_θ , and train it with Proximal Policy Optimization (PPO) (Schulman et al., 2017) to maximize response rewards. (p. 8)
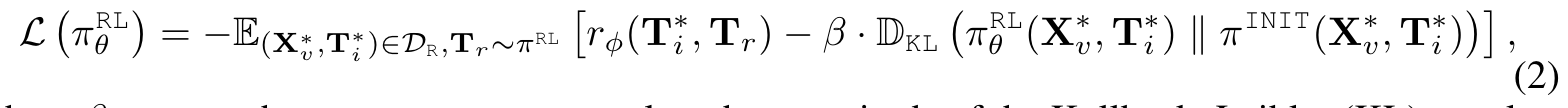
EXPERIMENTS

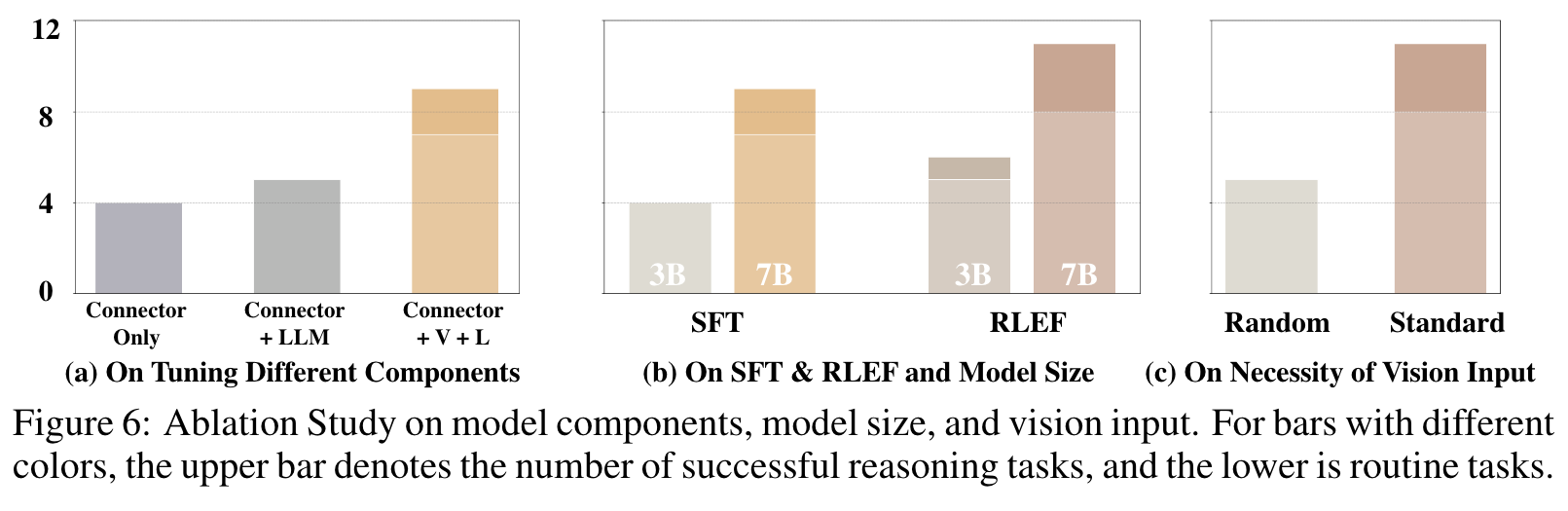
ABLATION STUDY
7B v.s. 3B Model Size
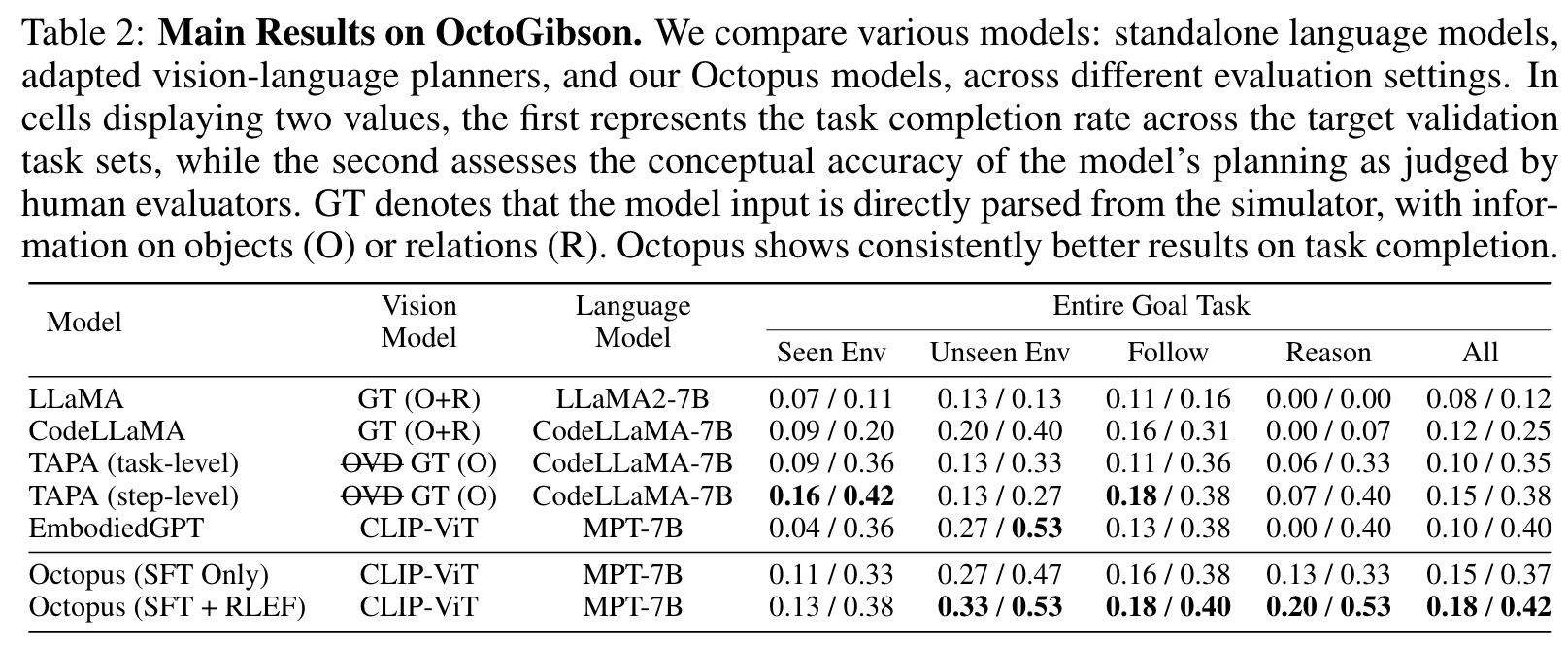
As illustrated in Figure 6 (a), downsizing the model manifests in a noticeable performance drop. The congruency of results across both the SFT and RLEF models underscores the importance of an apt model size when sculpting vision-language models. (p. 10)
Limitations
In its current incarnation, it can only produce succinct code. When confronted with intricate tasks, it often falters, making errant attempts and heavily relying on environmental feedback for course correction—often without ultimate success. Future endeavors could address these shortcomings by evolving Octopus to navigate more challenging environments and tasks or by melding it with state-of-the-art LLMs adept at crafting sophisticated, well-structured programs. (p. 11)