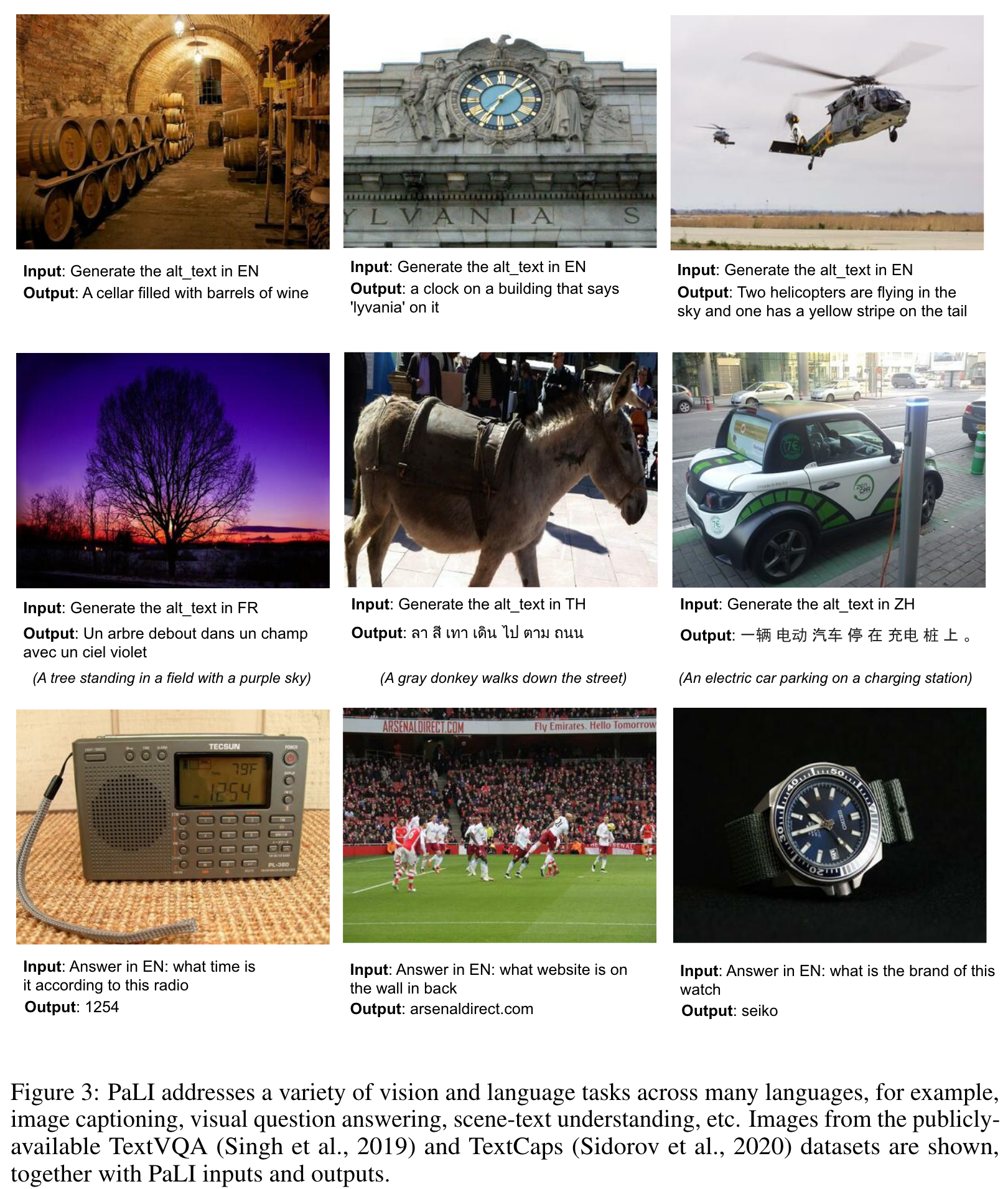
PaLI A Jointly-Scaled Multilingual Language-Image Model
[bert pali simvlm multimodal llm coca blip deep-learning git ofa beit transformer flamingo This is my reading note for PaLI: A Jointly-Scaled Multilingual Language-Image Model. This paper formulates all the image-text pretraining tasks as visual question answering. The major contributions of this paper includes 1) shows balanced size of vision model and language model improves performances; 2) training with mixture of 8 tasks is important.
Introduction
PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pre-trained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. (p. 1)
We introduce PaLI, a model that performs image-only, language-only, and image+language tasks across many languages, using a single “image-and-text to text” interface. A key characteristic of PaLI is a more balanced parameter share between the language and vision components, with more capacity to the vision backbone yielding large gains in performance. Another key ingredient to PaLI is the reuse of large unimodal backbones for language and vision modeling, in order to transfer existing capabilities and reduce training cost. (p. 1)
We find benefits from jointly scaling both the vision and the language components, with vision providing a better return on investment (accuracy improvement per parameter/FLOP). As a result, the capacity of our largest PaLI model, PaLI-17B, is distributed relatively equitably between the two modalities, with the ViT-e component accounting for about 25% of the total parameter count. (p. 2)
We enable knowledge-sharing between multiple image and/or language tasks by casting them into a generalized VQA-like task. We frame all tasks using an “image+query to answer” modeling interface, in which both the query and answer are expressed as text tokens. (p. 2)
RELATED WORK
One approach for image-text pre-training is contrastive learning. Another approach is to train vision-language models to generate text autoregressively (p. 3)
- SimVLM (Wang et al., 2021) propose an image-language pre-training approach leveraging a prefix language modeling objective.
- The unified framework OFA (Wang et al., 2022b) extends the generation capability to include text to image generation.
- Concurrent with our work, Unified-IO (Lu et al., 2022) further scaled up the number of objectives and tasks and demonstrated decent performance across the board through only multi-task pre-training without task-specific fine-tuning. (p. 3)
Recent works explore joint vision and language modeling with increased model capacity.
- CoCa (Yu et al., 2022) pre-trains a 2.1B image-text encoder-decoder model jointly with contrastive loss and generative loss.
- GIT (Wang et al., 2022a) trains a model consisting of a single image encoder and a text decoder with a captioning (generative) loss, where the image encoder is pre-trained with contrastive loss. In their latest version, GIT2, the model size is scaled up to 5.1B, with the majority of parameters on the vision side (4.8B).
- BEiT-3 (Wang et al., 2022c) presents an architecture with vision, language, and vision-language experts, operating with a shared multi-head self-attention followed by a switch for “expert” modules, resulting in a 1.9B model trained from scratch on a variety of public image, text and image-text datasets.
- Flamingo (Alayrac et al., 2022) is built upon a 70B language model (Hoffmann et al., 2022) as a decoder-only model whose majority of parameters are frozen in order to preserve language-generation capabilities, along with a 435M vision encoder. (p. 3)
THE PALI MODEL
ARCHITECTURE
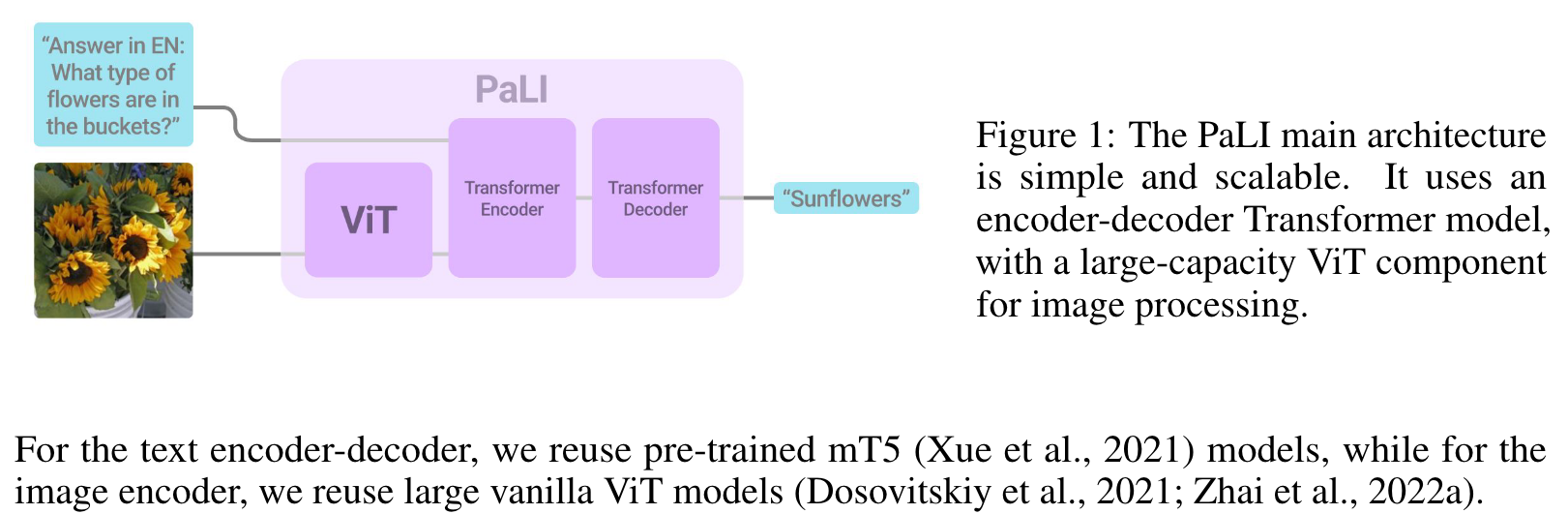
With PaLI, we aim to perform both unimodal (language, vision) and multimodal (language and vision) tasks. we resolve this by using a sufficiently general interface for all tasks considered: the model accepts as input an image and text string, and generates text as output. The same interface is used both during pre-training and fine-tuning. (p. 3)
Figure 1 shows a high-level schematic of the model architecture. At its core, PaLI has a text encoderdecoder Transformer (Vaswani et al., 2017). To include vision as input, the text encoder is fed with a sequence of visual “tokens”: output patch features of a Vision Transformer which takes as input an image. No pooling is applied to the output of the Vision Transformer before passing the visual tokens to the encoder-decoder model via cross-attention. (p. 3)
The visual component
The only other difference is that we apply learning rate cool-down twice, once with and once without inception crop augmentation, and average (“soup”) the weights of the two models as in Wortsman et al. (2022). (p. 4)
Scaling up vision backbones leads to saturating gains on classification tasks such as ImageNet (Zhai et al., 2022a). We further confirm this, observing that ViT-e is only marginally better than ViT-G on ImageNet (Table 17). However, we observe substantial performance improvements from ViT-e on vision-language tasks in PaLI (Section 4). (p. 4)
The language component
We experiment using the pre-trained mT5-Large (1B parameters) and mT5-XXL (13B parameters), from which we initialize the language encoder-decoder of PaLI. We train on a mix of many tasks, including pure language understanding tasks (Section A.2). This helps avoid catastrophic forgetting of the mT5’s language understanding and generation abilities. (p. 4)
DATA
WebLI scales up the image language data collection from English-only datasets to 109 languages. In addition to annotation with web text, we use publicly available automatic service to extract OCR annotations on all images, resulting in 29 billion image-OCR pairs. To balance quality and retain scale, we filter the dataset to the highest quality subset retaining only the top 10% scoring of the original WebLI image-text pairs (about 1B examples), which we use to train PaLI. (p. 4)
Training mixture
To accommodate diverse tasks in the image-language space, we train PaLI using a mixture of eight pre-training tasks. This mixture is designed to span a range of general capabilities useful for downstream tasks.
- Span corruption on text-only data uses the same technique described by Xue et al. (2021) on text-only examples. Split-captioning on WebLI alt-text data is inspired by the pre-training objective of Wang et al. (2021), and works by splitting each alt-text string randomly into two parts, ⟨cap1⟩ and ⟨cap2⟩, used for input and target, respectively.
- Captioning on CC3M-35L with the alt-text string in language ⟨lang⟩ as the target, based on the Conceptual Captions (Sharma et al., 2018) training data and machine translated alt-texts.
- OCR on WebLI OCR-text data uses the concatenation of the annotated OCR texts in language ⟨lang⟩ (Kil et al., 2022) produced by publicly available automatic service for the input image.
- English and Cross-Lingual VQA is VQ2ACC3M (Changpinyo et al., 2022a), translated in the same way as CC3M-35L. Note that we use English answers in all instances here, as the English-native answers for VQA are often short and too prone to errors to perform out-of-context automatic translation.
- English and Cross-Lingual visual question generation (VQG) is also based on native and translated VQ2A-CC3M-35L VQA triplets. Similarly, we use only English answers here.
- English-only Object-Aware (OA) VQA is based on VQA triplets derived from automatically-produced, non-exhaustive object labels, inspired by Piergiovanni et al. (2022a). The QA pairs include listing all the objects in the image and whether a subset of objects are in the image. To create these examples, we require object-level annotations, for which we use Open Images (Kuznetsova et al., 2020).
- Object detection is a generative object-detection task inspired by Chen et al. (2021; 2022). (p. 5)
We specify each task using a training data source and a template-based prompt, and train the model using a language-model–style teacher forcing (Goodfellow et al., 2016) with a standard softmax cross-entropy loss. (p. 5)
MODEL TRAINING
All PaLI variants are trained for one epoch over the entire pre-training dataset (1.6B) with 224×224 image resolution. Only the parameters of the language component are updated, the vision component is frozen, which is beneficial (Sec. 4.6). For the largest model, PaLI-17B, we perform an additional high-res (588×588) phase similar to previous works (Radford et al., 2021; Yuan et al., 2021; Yu et al., 2022). (p. 5)
EXPERIMENTS
MODEL SCALING
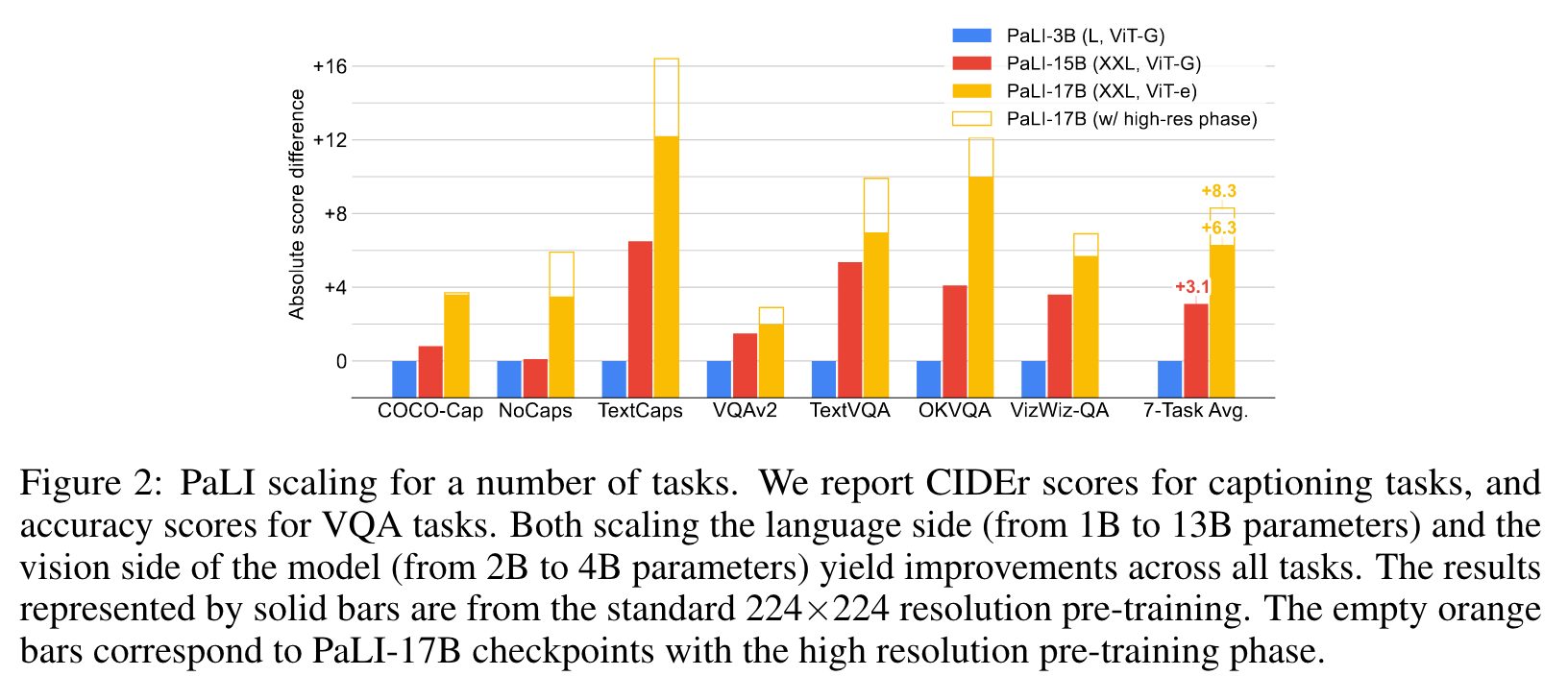
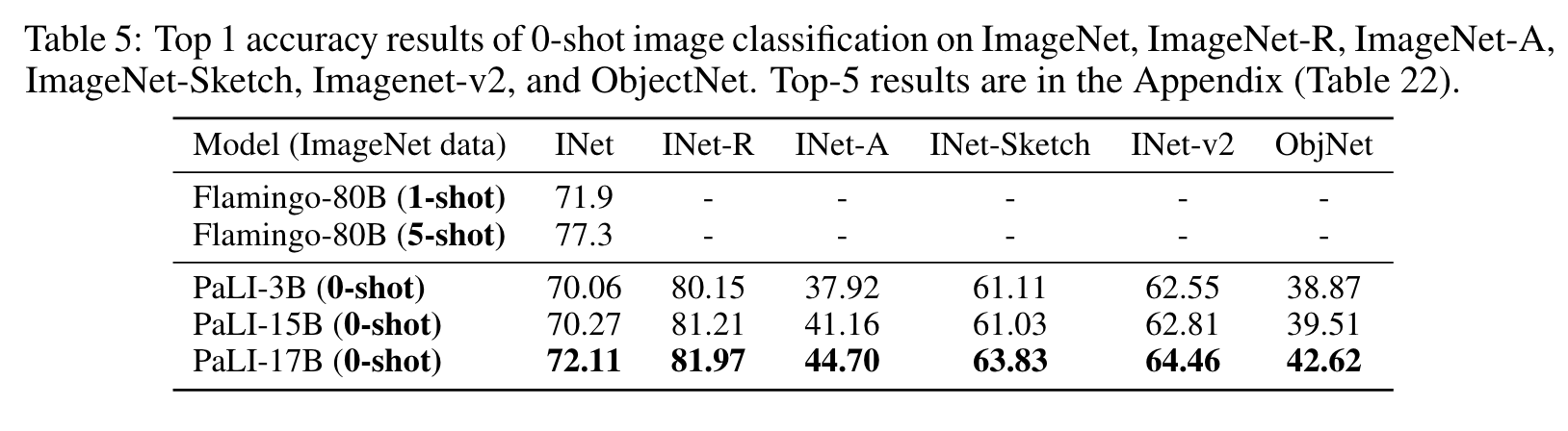
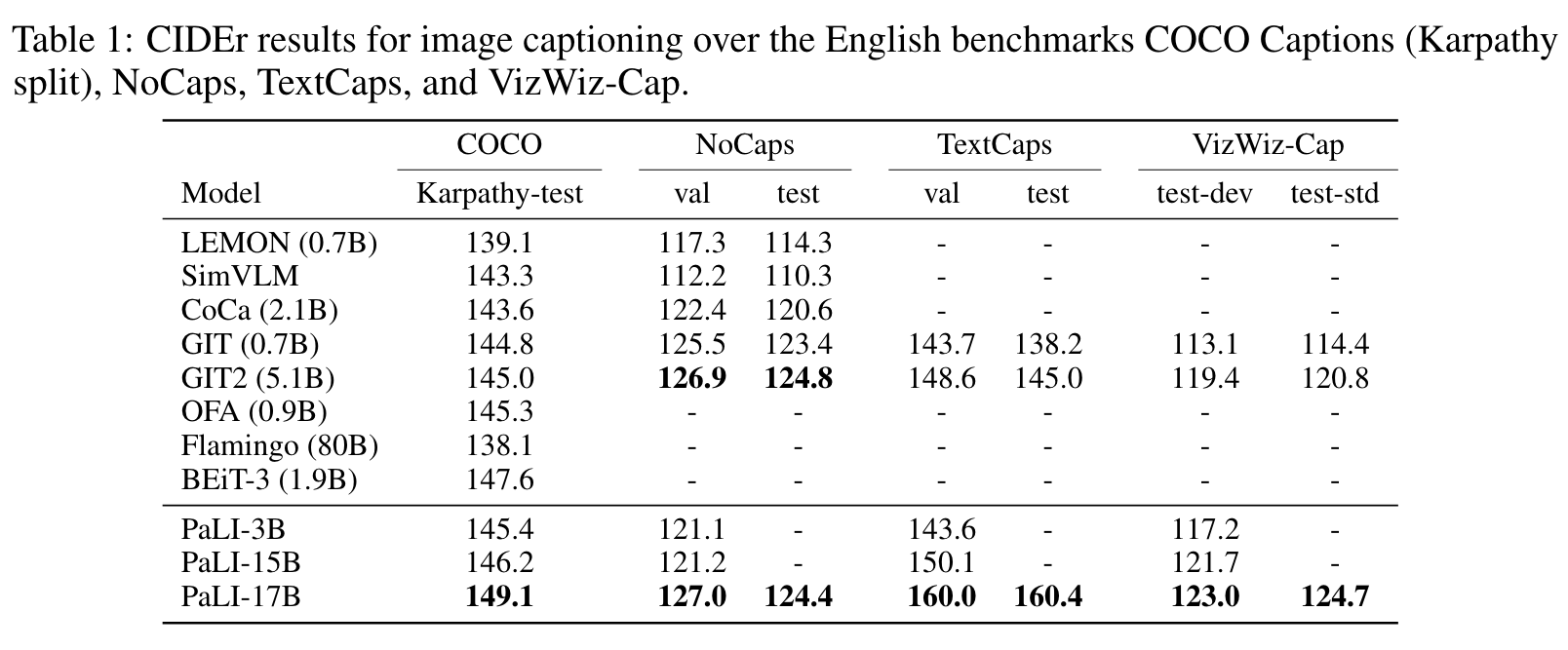
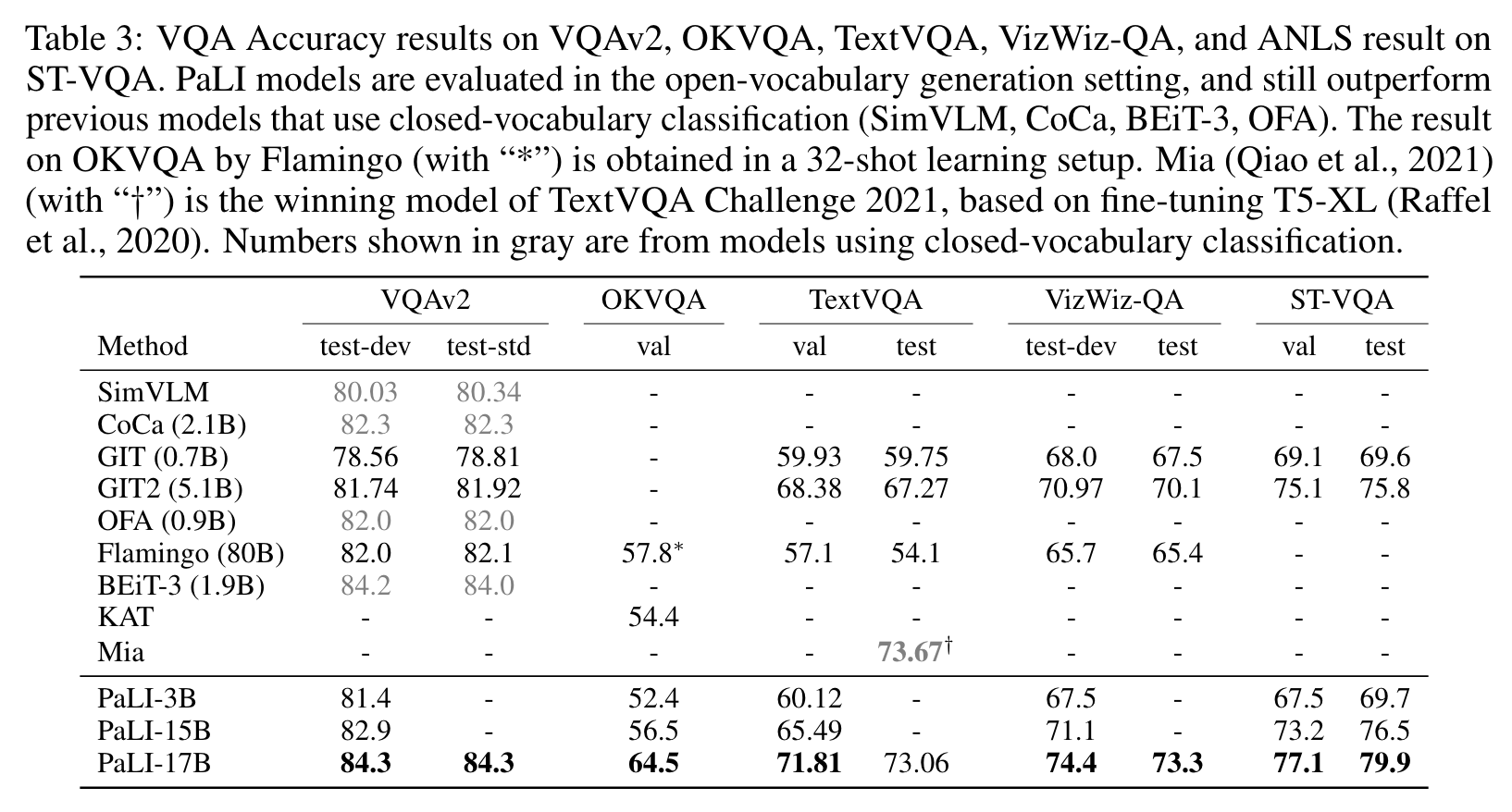
Figure 2 also shows that scaling the visual component is important: when scaling from a ViT-G to a ViT-e model, although the overall model size is increased by only about 13% (+2B parameters), the average performance improvement over all seven benchmarks (additional +3.2) is larger than the one obtained with much larger increases in the capacity of the language model (+3.1) which takes more parameters (+12B). The high-resolution pre-training phase at 588×588 resolution brings an additional +2.0 points, which also indicates the potential of scaling up the vision component of the model. (p. 9)
ABLATION STUDIES