Tell Your Model Where to Attend Post-hoc Attention Steering for LLMs
[llm deep-learning attention pasta llama gpt instruction-tuning This is my reading note for Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs. This paper proposes to improve LLM instruction follow performance by changes the attention weight to emphasize contents highlighted by user. The attention head to model is found by profiling the model on a small scale set of data.
Introduction
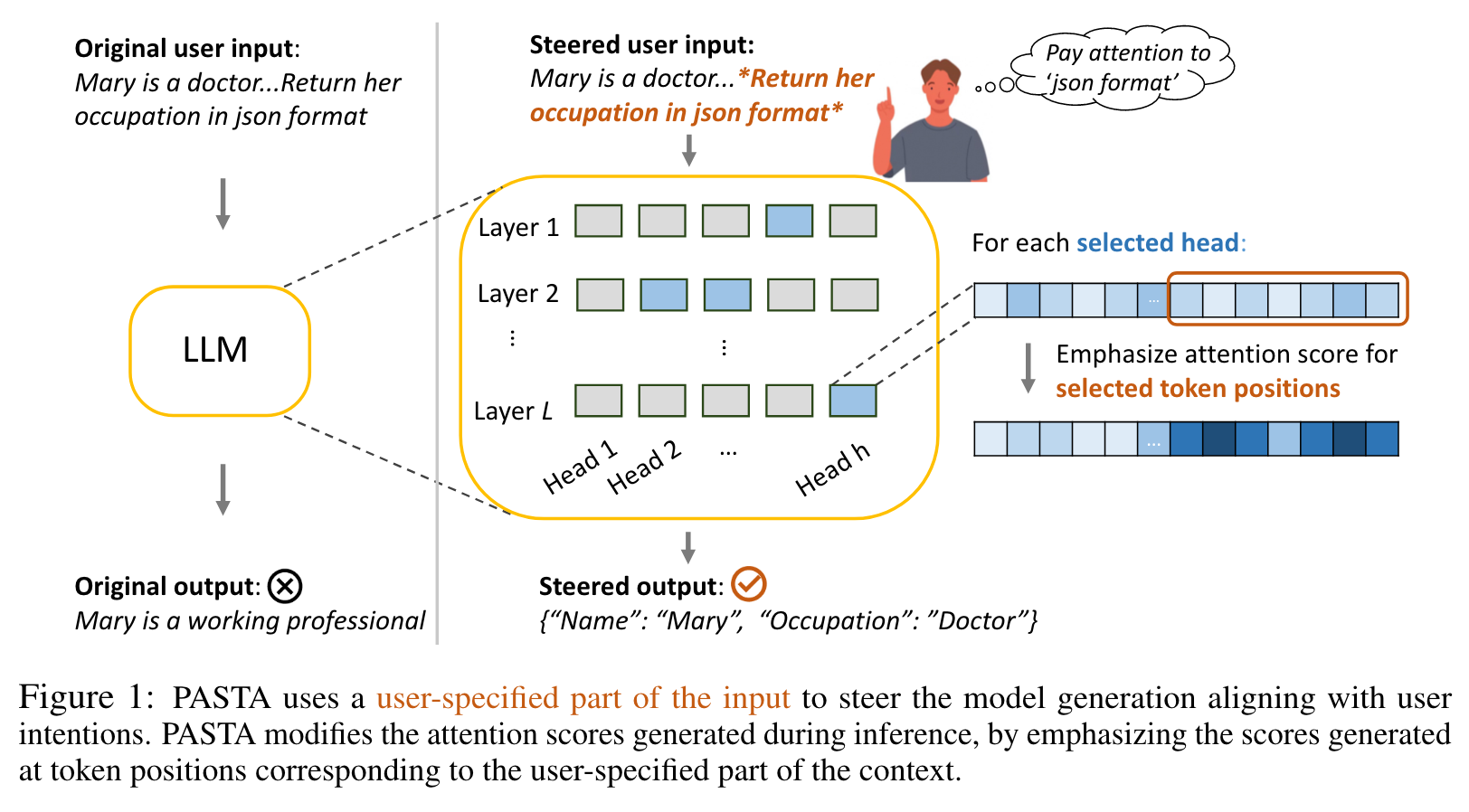
In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. This motivates us to introduce PASTA – Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. (p. 1)
LLMs often encounter challenges in understanding their contextual inputs during interactions with users (Shen et al., 2023; Lu et al., 2021). This difficulty becomes particular evident when they are presented prompts1 containing extensive background contexts or complex user instructions. Lengthy contexts can overwhelm LLMs, as their attention modules, learned from data, are unable to fully capture crucial details (Liu et al., 2023). Complex instructions can further inhibit the model from focusing on the user’s intentions, resulting in undesired outputs (Wei et al., 2022). Additionally, for time-sensitive data, such as news articles, there can exist factual knowledge within contexts, which contradicts with model prior beliefs induced from outdated pre-training. As a result, a model may generate outputs conditioned on its pre-existing belief instead of attending to new facts within the contexts (Meng et al., 2022a;b; Mitchell et al., 2022; Hernandez et al., 2023). All of these challenges contribute to LLMs struggling to comprehend user intentions. (p. 1)
In interactions between users and LLMs, it is users also need to highlight specific information for the model. Existing methods, however, do not support such a mechanism. LLMs are inherently limited to processing plain texts, devoid of any stylistic cues or emphasis markers (Brown et al., 2020b; Liu et al., 2021; Wei et al., 2022). Even when emphasis markers are added to prompts, state-of-the-art LLMs often struggle to discern weak signals from a couple of marker tokens (See evidence in Section 5.1). (p. 2)
PASTA upweights the attention scores of the user-specified tokens while down weighting the other tokens at specific attention heads. Through steering attention modules, PASTA directs the model to pay close attention to the user-specified parts and hence generate the desired output aligning with the highlighted contents. Notably, PASTA is applied after training and does not require changing any model parameters; PASTA only requires access to the attention scores of specific heads of an LLM. (p. 2)
Since attention heads can serve different functions (Tenney et al., 2019; Deb et al., 2023), we introduce an efficient model profiling algorithm to identify which heads are effective for steering. Specifically, we subsample small training sets from multiple tasks and evaluate the performance of attention steering for each individual head across these tasks. PASTA selects the attention heads that, when steered, generally improve the multi-task performance. We empirically observe that steering these heads not only benefits the existing tasks but also enhances the performance on unseen tasks. Notably, the model profiling is performed only once for an LLM. The selected attention heads can be regarded as a model-level profile, effective for steering the LLM on unseen tasks. (p. 2)
Proposed Method
In evaluation datasets, we assume that the user-specified part of each example is already provided by enclosing at its both ends in some emphasis markers, like ‘∗’ marker in Markdown. (p. 3)
PASTA (Algorithm 1) consists of two components: (i) post-hoc attention steering, which emphasizes the user-specified parts of the input during inference, see Section 3.1 and (ii) multi-task model profiling, which selects the effective attention heads for steering, see Section 3.2. (p. 3)

POST-HOC ATTENTION STEERING
Specifically, given the index set of highlighted input spans as G, PASTA emphasizes these user-specified tokens by an attention projection T : (p. 3)
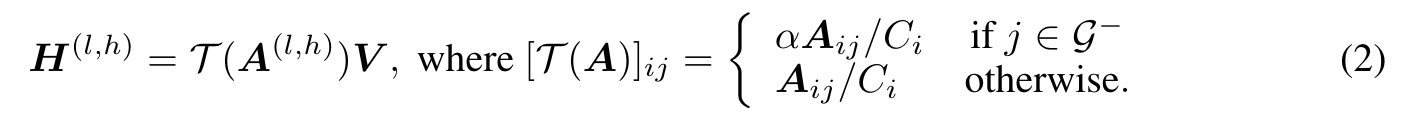
(2) steers the model attention by scaling down the scores of tokens that are not highlighted by the user. The reason of selecting (2) is that it can be more numerically stable compared to scaling up scores. Alternatively, one can also scale the attention scores by adding a positive constant to the underlined tokens G. The reason of we select multiplication in (2) instead of addition is that it preserves the difference on attention magnitude among the highlighted tokens. As such, the steering operation only adjusts overall attention scales of two groups of tokens. In contrast, addition by a large constant to the highlighted tokens results in their attention scores almost uniformly distributed, leading to unnecessary information loss and performance degeneration. (p. 4)
MULTI-TASK MODEL PROFILING
Empirically, we find that applying attention steering in (2) to all attention heads performs worse than applying it only to specific heads (see Section 5.3). It is important to specify the correct attention heads, given that different heads serve distinctive roles in encoding semantic/syntactic information. (p. 4)
We then set the attention head set H for steering as the intersection of top-k performing heads, $H=\intersect_{i=1}^m R_{1:k}^{(i)}$ (see Section 5.3 for alternative choices). Intuitively, we expect performance to improve as the nu (p. 4)
Importantly, this process needs to be performed only once for a LLM, similar to finetuning. However, unlike finetuning, model steering does not modify model weights and, more importantly, generalizes to new tasks. The resulting head set H can be regarded as a model-level profile. Once it is determined, we can apply the attention steering on H to both existing tasks and unseen tasks to enhance model contextual understanding and benefit downstream performance. (p. 4)
EXPERIMENTAL SETUP
For each task, the prompt templates in our results are as follows:
- JSON Formatting:
- (Original)
{context}. Answer the occupation of {person} and generate the answer as json format. Here is an example: {“name”: , “occupation”: ,}. Now generate the answer. - (Shortened one in Section 5.2)
{context}. Answer the occupation of {person} and generate the answer as json format. - (Rephrased one in Section 5.2)
Answer the occupation of {person} and generate the answer as json format. Here is an example: {“name”: , “occupation”: ,}. {context}. Now generate the answer.
- (Original)
- Pronouns Changing:
- (Original):
{context}. For the aforementioned text, substitute ‘she’ and ‘he’ with ‘they’ and generate the occupation of {person} after changing pronouns. - (Shortened one in Section 5.2):
{context}. Change ‘she’ and ‘he’ with ‘they’ and answer the occupation of {person} after replacing the pronouns - (Rephrased one in Section 5.2):
{context}. For the aforementioned descriptions, replace ‘she’ and ‘he’ with ‘they’ in the aformentioned text and generate the new text after replacing the pronouns.
- (Original):
- BiasBios:
{context}. {person} has the occupation of. - CounterFact:
Previously, {old fact}. Currently, {new fact}. {question}(p. 14)
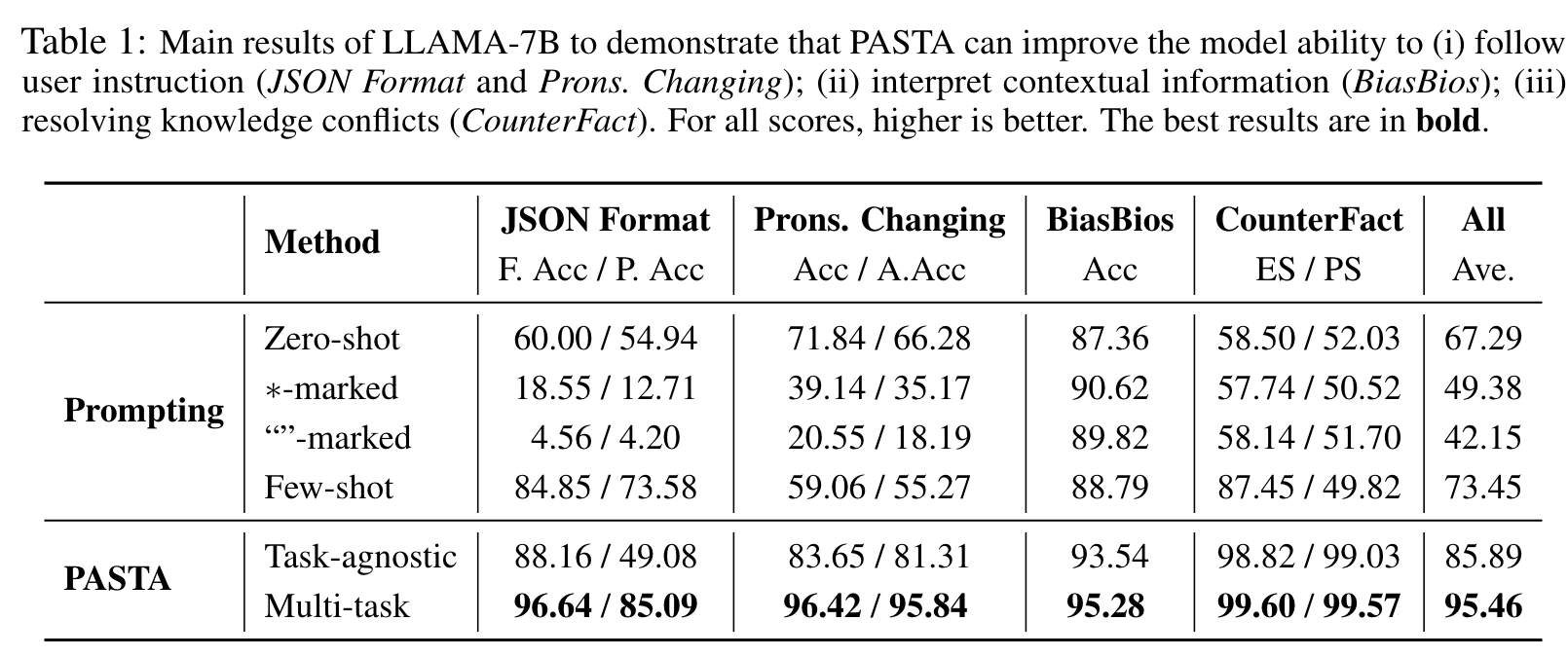
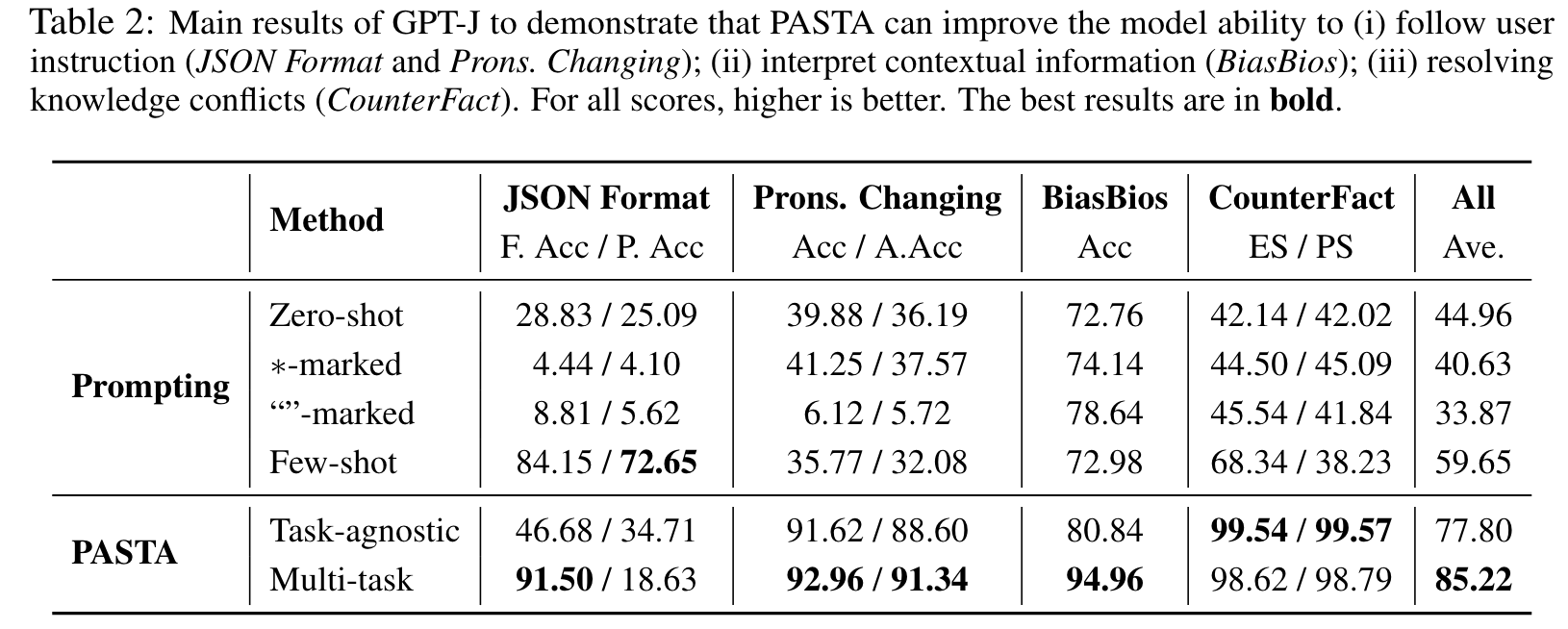

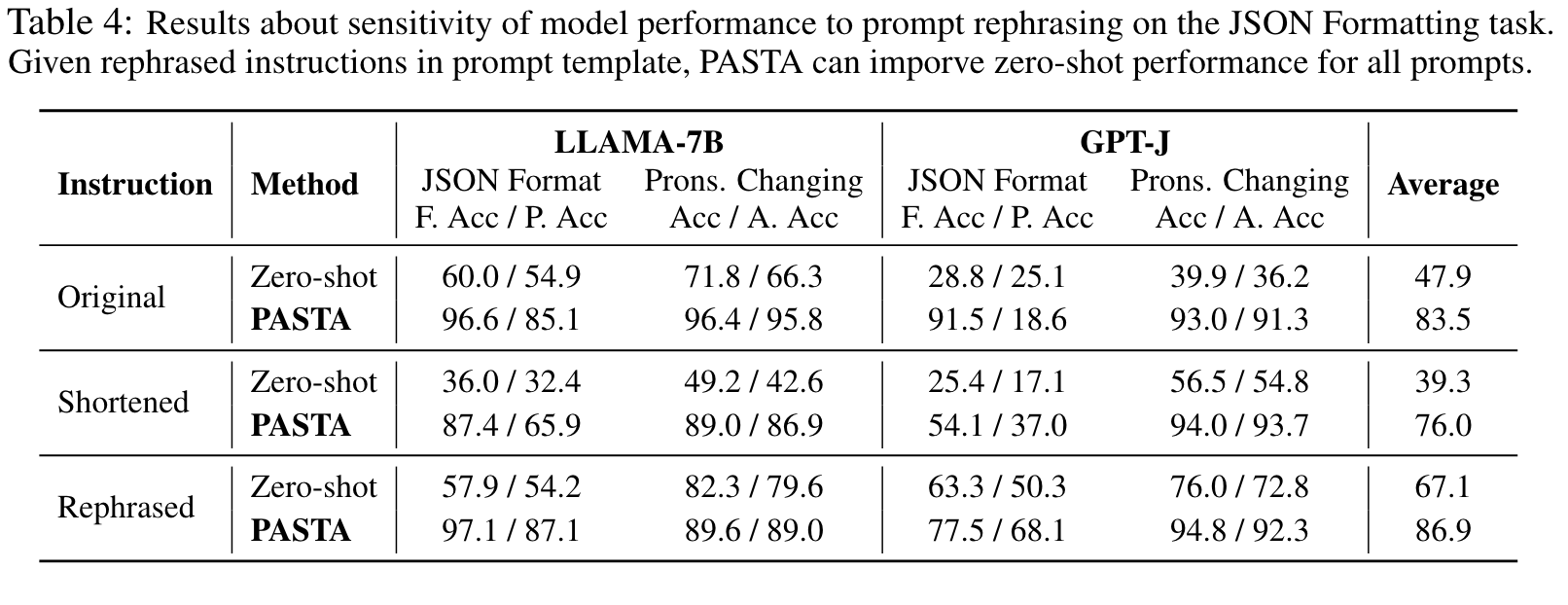
We find that PASTA can alleviate the sensitivity of model performance to varying prompts. Specifically, Table 4 evaluates the performance of LLAMA-7B and GPT-J on JSON Formatting and Pronouns Changing task given different instructions in the prompt template, all of which convey the same meaning (see precise prompts in Appendix A.1). (p. 7)
ABLATIONS
Model profiling
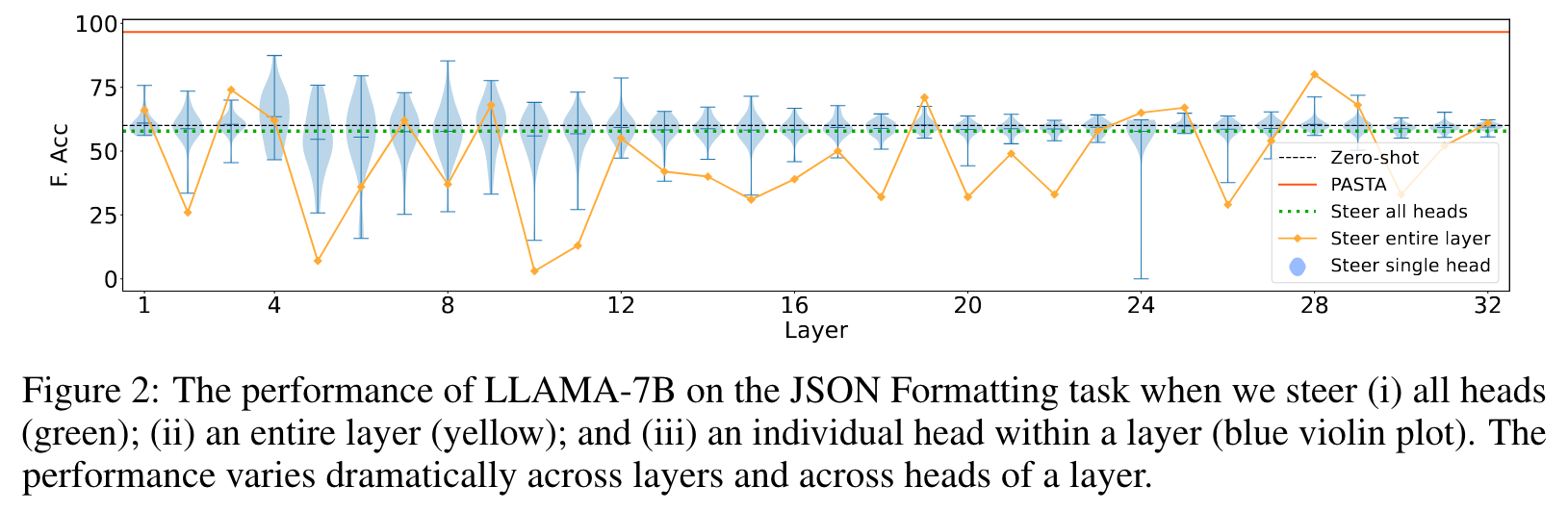
Selecting heads via model profiling in PASTA (red line) significantly outperforms other approaches. Steering all heads (dashed green line) degrades performance compared to the baseline zero-shot performance (dashed black line). This is likely because steering all heads over-amplifies the user-specified information at the expense of other essential information required for effective generation and prediction. (p. 8)
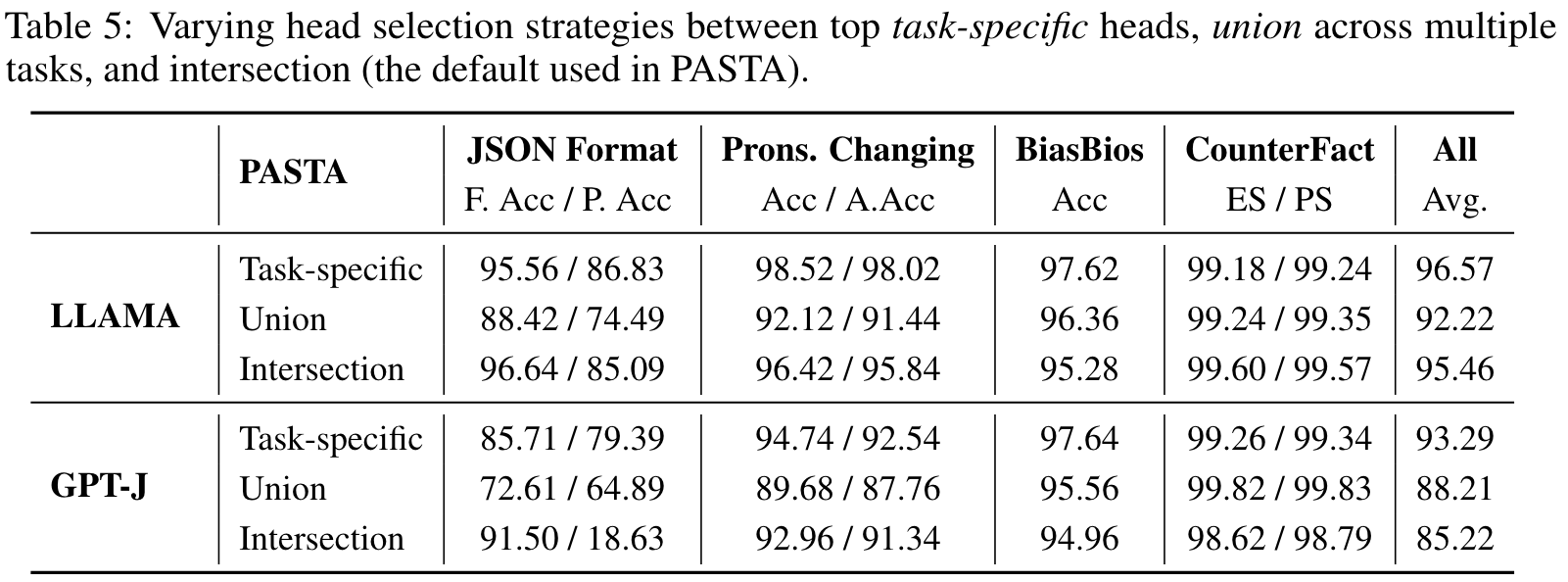
Varying strategies for selecting heads during profiling
Using task-specific heads rather than intersection-selected heads sometimes yields improved performance, but requires selecting a different set of heads for each new task. (p. 8)
Varying the number of heads to be steered
The results suggest that as more heads are included for steering, the model follows the user even more closely, achieving higher efficacy (JSON Format Acc. and Pron. Change Acc.). However, at some point, this it results in a decrease in the metrics reflecting the generation quality (JSON Pred. Acc and Fluency). Thus, there is a trade-off between emphasizing efficacy and generation quality, requiring choosing the number of heads during model profiling. (p. 8)
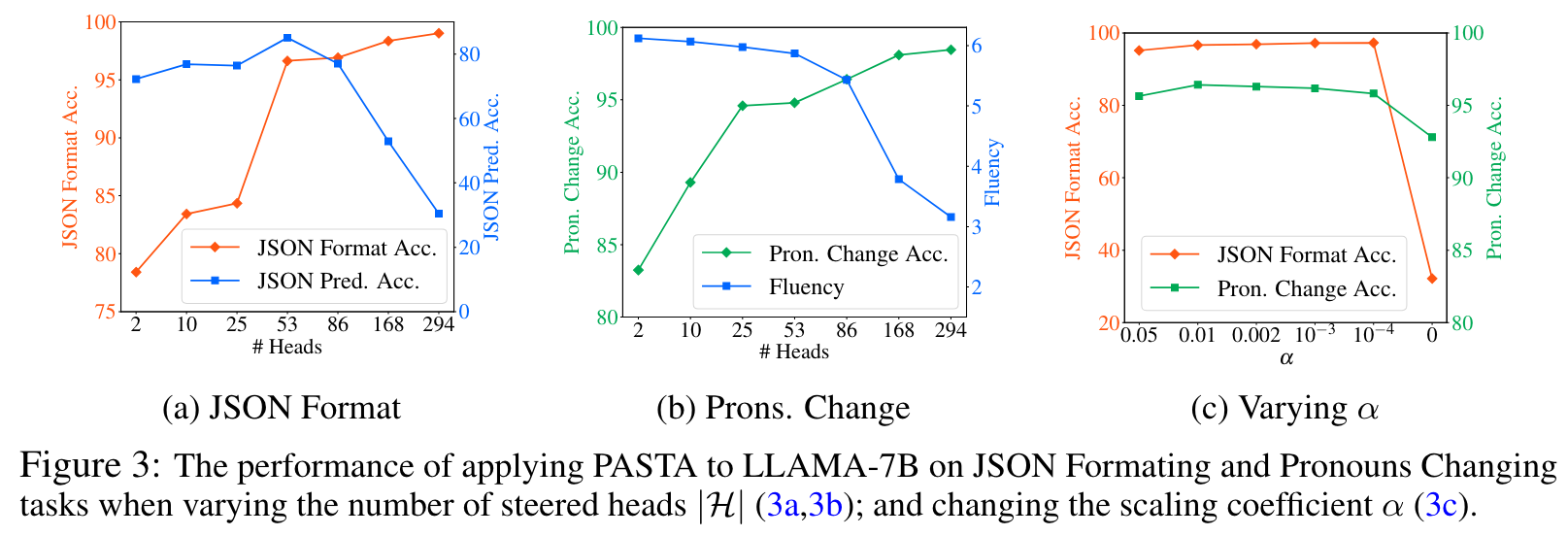
Varying the scaling coefficient α
The results indicate that PASTA is fairly robust to this hyperparameter; in practice, we fix it as 0.01. Notice that setting α to zero should be avoided, as this leads to the complete removal of other crucial contexts at the steered heads, resulting in performance degeneration. (p. 9)