PhotoVerse Tuning-Free Image Customization with Text-to-Image Diffusion Models
[dream-booth e4t diffusion personalize custom-diffusion textual-inversion deep-learning instant-booth dream-artist text2image profusion suti This is my reading note for PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion. This paper proposes a fine tune free personalized image edit method bases on diffusion. To this end it proposes dual branch to encode text and image feature. Lora is used to update the existing model. it also proposed to use a random fusion injection to condition the attention with image and text embedding. However the paper fails to describe why this random fusion injection is needed.

Introduction
To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. This results in a rapid and effortless generation, typically completed in ∼ 5 seconds. (p. 1)
Related Work
In the literature on GAN inversion, there are primarily two approaches: optimization based inversion, involves directly optimizing the latent code to minimize image reconstruction error. While this method achieves high fidelity, its drawback lies in the requirement of a hundred times iterations, rendering it unsuitable for realtime applications. Encoder-based inversion, trains a neural network to predict the latent code. Once trained, the encoder performs a single forward pass to obtain a generalized result, offering improved efficiency. (p. 2)
In the pursuit of enabling personalized text-to-image synthesis, several methods e.g., Dreambooth (Ruiz et al. 2023a), Textual Inversion (Gal et al. 2022), DreamArtist (Dong, Wei, and Lin 2022), and CustomDiffusion (Kumari et al. 2023) primarily focused on identity preservation and propose the inverse transformation of reference images into the pseudo word through per-subject optimization. Text-to-image models undergo joint fine-tuning to enhance fidelity. The resulting optimized pseudo word can then be leveraged in new prompts to generate scenes incorporating the specified concepts. However, this optimization-based paradigm often requires expensive computational resources and large storage requirements, taking minutes to hours when executed on high-end GPUs. (p. 1)
Also, these approaches had limitations in their language editing capabilities due to potential overfitting on a tiny identity-specific image dataset. Recent encoder-based methods e.g., E4T (Gal et al. 2023a), InstantBooth (Shi et al. 2023), SuTI (Chen et al. 2023), Profusion (Zhou et al. 2023) aimed to address these challenges by optimizing pseudo token embeddings, introducing sampling steps, or incorporating new modules for concept injection. However, challenges persist, such as the need for multiple input images and test-time tuning (Sohn et al. 2023) to maintain identity preservation and editability (p. 2)
Optimization-based methods, such as DreamArtist (Dong, Wei, and Lin 2022), directly optimize the pseudo word to establish a mapping between userprovided images and textual inversion. Other approaches, e.g., Dreambooth (Ruiz et al. 2023a) and CustomDiffusion (Kumari et al. 2023) employ fine-tuning of text-to-image models to enhance fidelity. However, these strategies require minutes to hours for concept-specific optimization. In contrast, encoder-based methods such as E4T (Gal et al. 2023a), InstantBooth (Shi et al. 2023), Profusion (Zhou et al. 2023) train an encoder to predict the pseudo word, enabling the generation of personalized images within a few fine-tuning steps. (p. 3)
Proposed Method
This involves designing adapters to project the reference image into a pseudo word and image feature that accurately represents the concept. These concepts are then injected into the text-to-image model to enhance the fidelity of the generated personalized appearance. (p. 3)
To enable this process, we incorporate the original text-to-image model with concept conditions and train it within a concept scope, supplemented by an additional face identity loss. (p. 3)
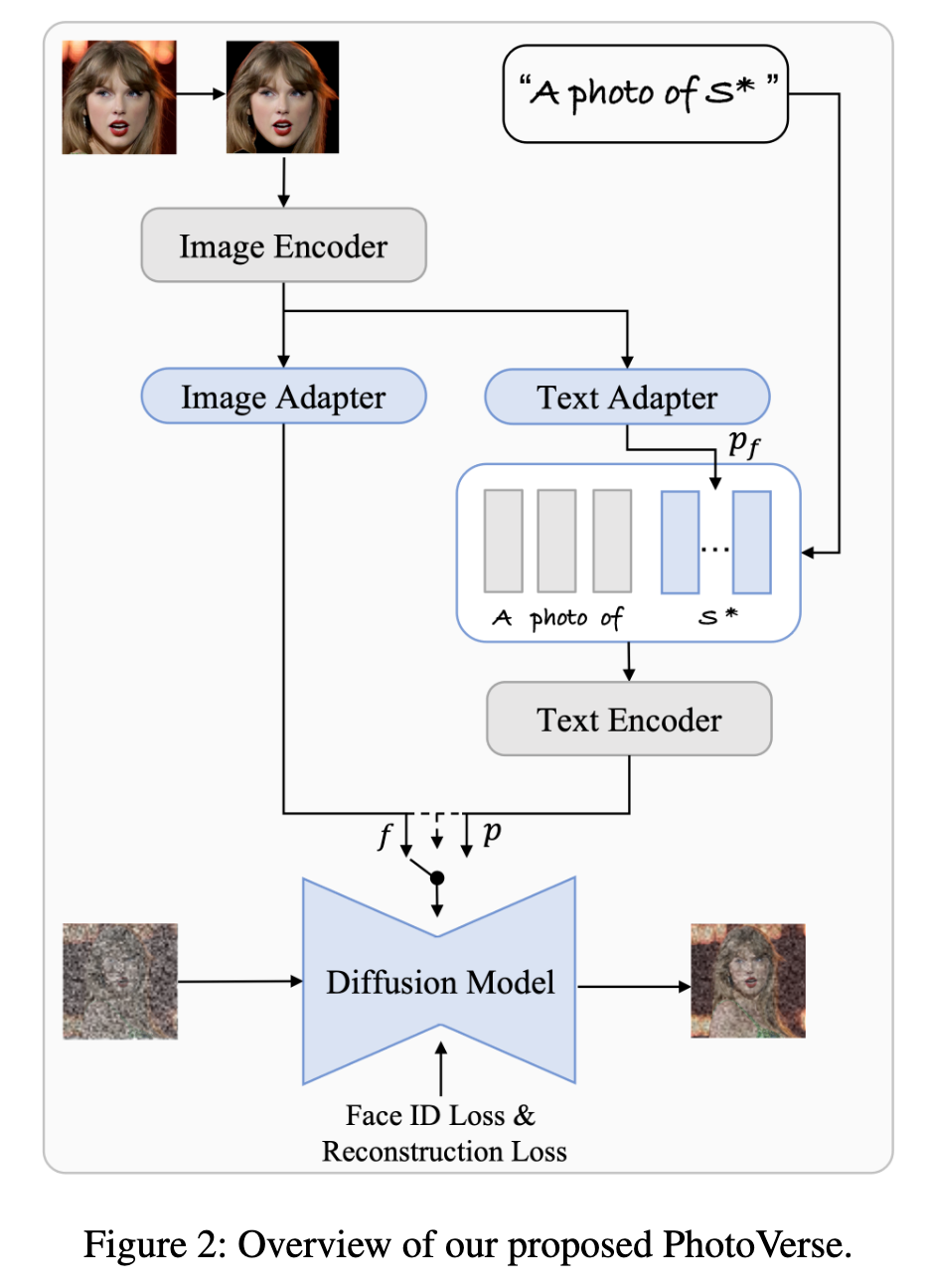
Dual-branch Concept Extraction
In the preprocessing stage, Firstly, a face detection algorithm was applied to identify and localize human faces within the input image x. (p. 4)
Initially, we utilize the CLIP image encoder, the same encoder employed in Stable Diffusion, to extract the features of the reference image. To accomplish this, we utilize the feature obtained from the CLIP image encoder. These features are then mapped using an image adapter, which follows the same structural design as the text adapter. The resulting feature capture essential visual cues related to identity, enabling a more accurate representation of the desired attributes during image generation. (p. 4)
Dual-branch Concept Injection
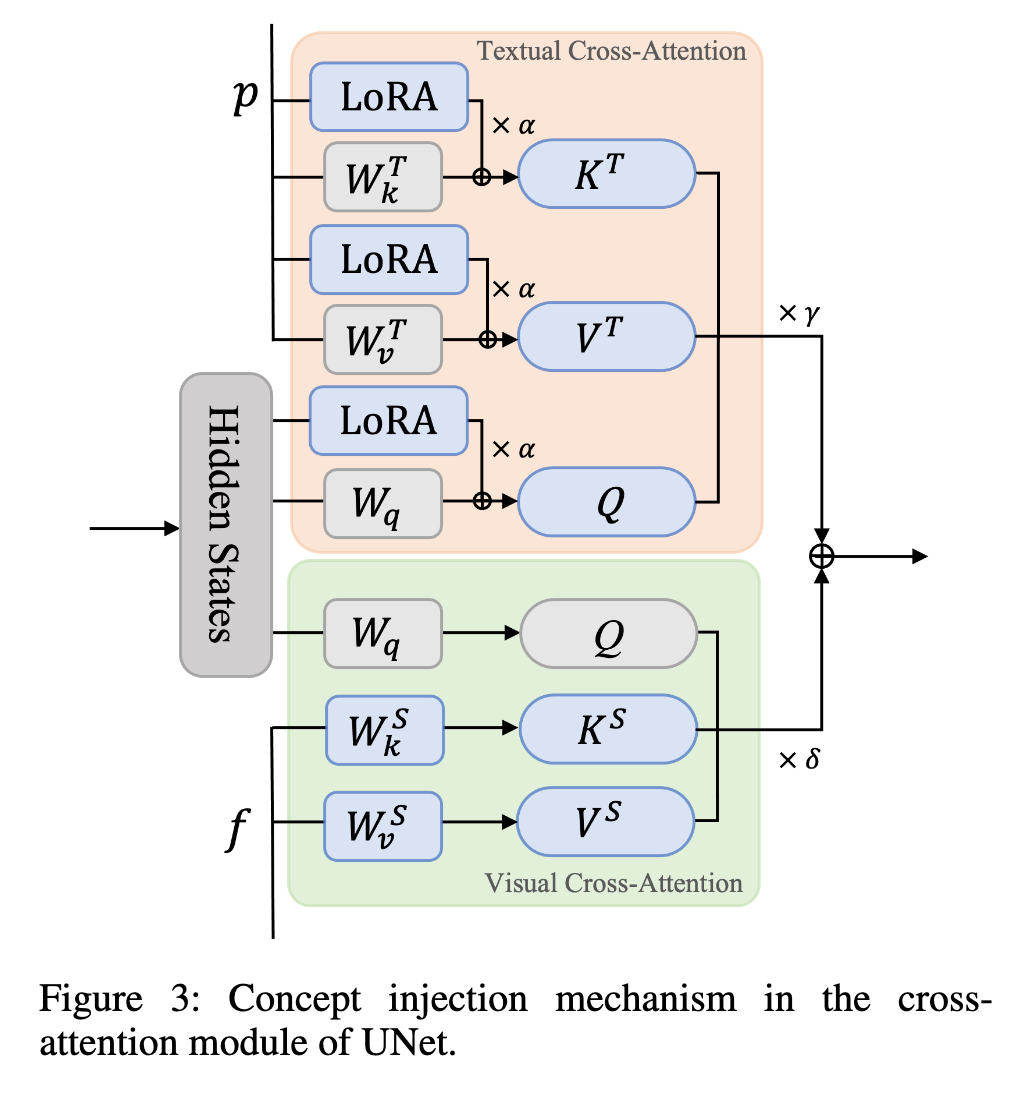
Rather than fine-tuning the entire UNet, which can be computationally expensive and potentially reduce model editability due to overfitting, we only add conditions and fine-tune the weights in the cross-attention module (p. 4)
Then we present a random fusion strategy for the multimodality branches: where γ and σ denote two scale factors that regulate the influence of control. A random seed is sampled from the uniform distribution U = (0, 1), the fused representation can be obtained in the following manner: (p. 5)
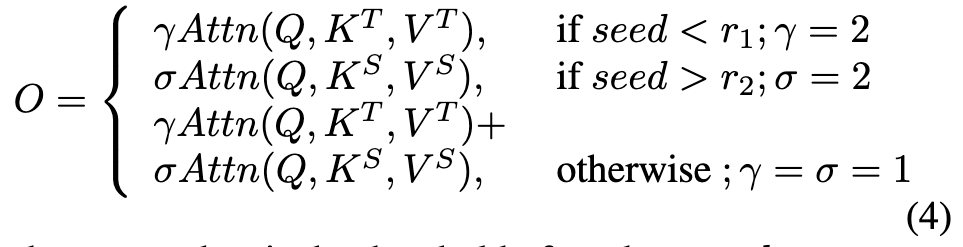
The whole pipeline can be trained as usual LDM (Rombach et al. 2022) does, except for additional facial identity preserving loss Lface: (p. 5)
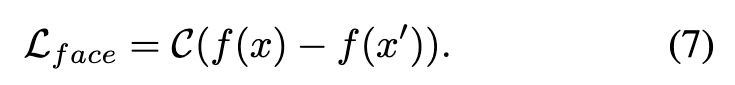
Here, f(·) represents a domain-specific feature extractor, x denotes the reference image, and x′ corresponds to the denoised image with the prompt “a photo of S∗”. To achieve the goal of measuring identity in human face scenarios, we employ the Arcface face recognition approach (Deng et al. 2019). The function C(·) computes the cosine similarity of features extracted from the face region in the images (p. 5)
Experiment

Our approach successfully retains crucial subject features, including facial features, expressions, hair color, and hairstyle. For instance, when compared to alternative techniques, our proposed method outperforms in restoring intricate hair details while effectively preserving facial features, as evident in the first row. Additionally, as observed in the second row, our approach excels at fully restoring facial features while maintaining consistency with the desired “Manga” style specified in the prompt. In contrast, the Profusion-generated photo exhibits blurry mouth details, while E4T fails to exhibit a sufficiently pronounced “Manga” style. Shifting to the third row, our results successfully capture characteristic expressions present in the input images, such as frowning. (p. 6)
