A Picture is Worth a Thousand Words Principled Recaptioning Improves Image Generation
[diffusion multimodal deep-learning text2image pali image-caption This is my reading note for A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation. The papers found that the text data used to train text to image model is now quality, which is based alt text of images.it proposed to use an image caption model to generate high quality text for the images; then the diffusion model trained from this new text data show much better performance.

Introduction
In this work we observe that these captions are often of low quality, and argue that this significantly affects the model’s capability to understand nuanced semantics in the textual prompts. We show that by relabeling the corpus with a specialized automatic captioning model and training a text-to-image model on the recaptioned dataset, the model benefits substantially across the board. (p. 2)
However, while revolutionary, even modern state-of-the-art text-to-image models may fail to generate images that fully convey the semantics and nuances from the given textual prompts. Failure modes include: missing one or more subjects from the input prompt [5, 7]; incorrect binding of entities and modifiers [5, 7, 8]; and incorrect placement and spatial composition of entities [5, 9, 10]. (p. 2)
In this work we first observe that open-web datasets used to train open text-to-image models suffer from significant issues. (p. 2)
For example, an image of a person can have as Alttext the name of the person and the name of the photographer, but not a description of their appearance, their clothes, their position, or the background. Also, sometimes Alttext tags contain inaccuracies, mistakes and out of context information. See Fig. 4 for examples. (p. 2)
We further observe that while trained mainly on similar datasets of open (image, caption) pairs, recent automatic captioning systems, such as PaLI [12], produce highly accurate captions. (p. 2)
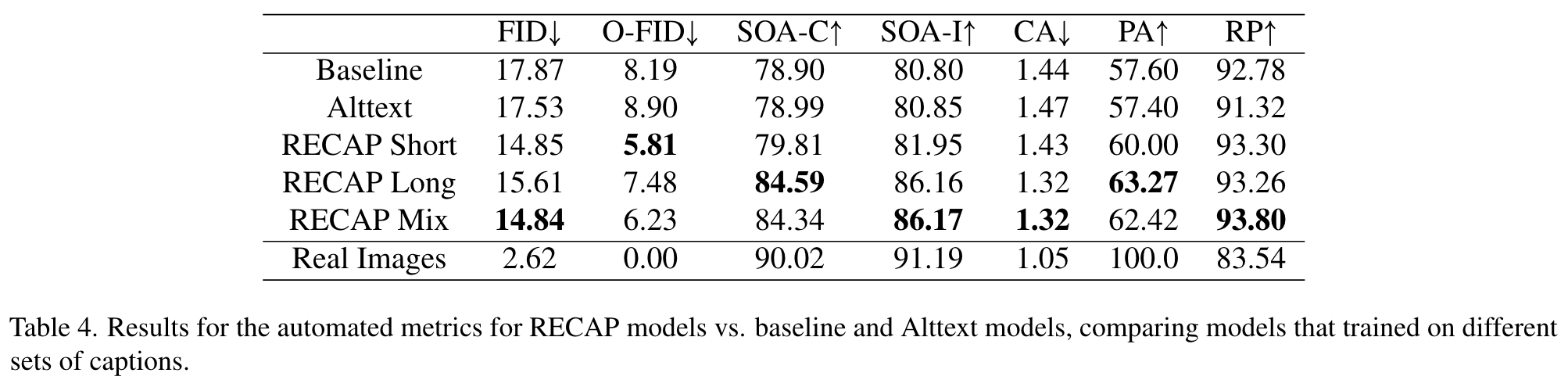
With these observations, we suggest a new method for horizontally improving T2I models by training them on improved captions, auto-generated by a custom I2T model. We call our method RECAP, and show that applying it to Stable Diffusion results in a model that is better than the baseline across the board, with a battery of standard metrics substantially improving, e.g. FID 17.87→14.84, as well as in human evaluation of successful image generation 29.25% → 48.06% (see Section 5). (p. 2)
Method
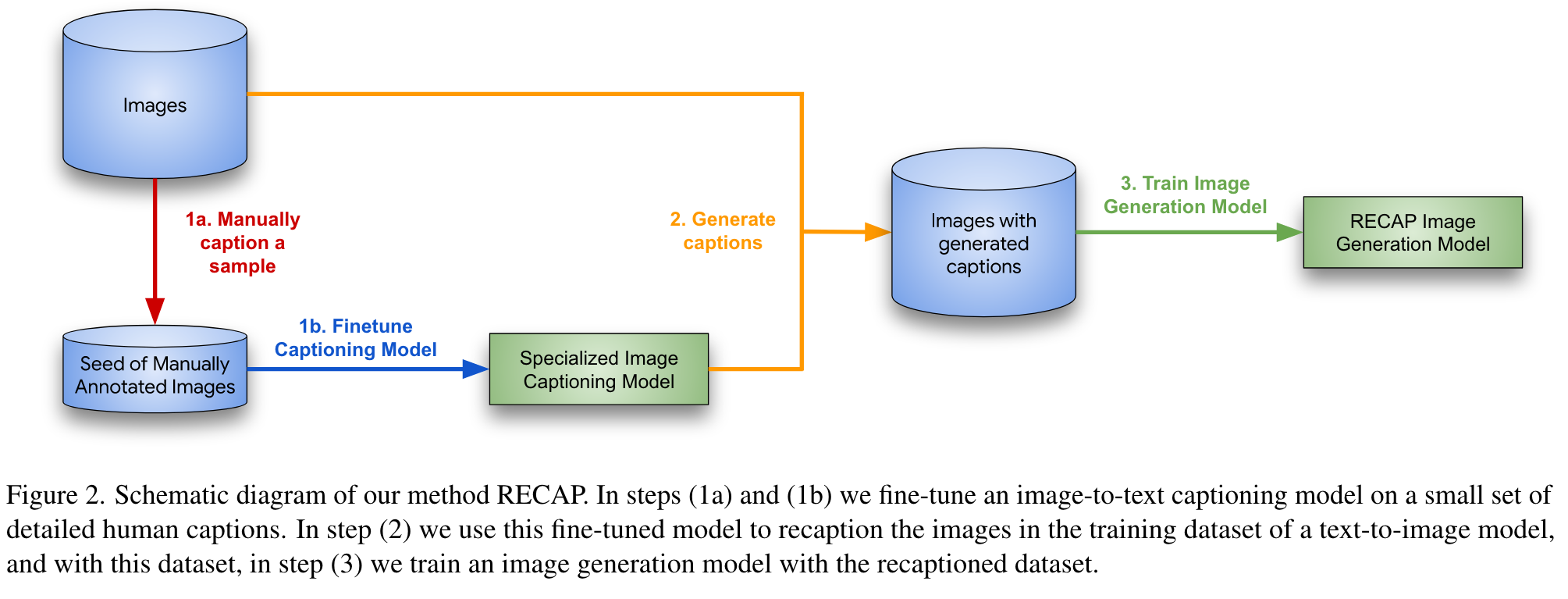
Our method, RECAP consists of 3 steps: (1) fine-tune an automatic captioning system to produce desirable labels; (2) relabel the images from our text-to-image training set with this automatic recaptioning system; and (3) train the textto-image model on the dataset consisting of the images and new captions. Fig. 2 visualizes the overall method. (p. 3)
Captioning Model
We used a pre-trained I2T captioning model (PaLI [12]). As the model outputs are relatively terse and lack in detail, we first collected a small set of 100 manual captions from human raters and fine-tuned the captioning model on that set. (p. 3)
In order to experiment with the effect of different captioning distributions, the raters were asked to provide two types of captions. First, a detailed caption for each image, with these instructions: “Describe what you see in each image using 1-2 detailed sentences”. Note that the instructions limited the length to only 1-2 detailed sentences at most, due to CLIP’s (the downstream text encoder) context size of only 77 tokens, which longer captions exceeded. Second, we collected a short and less detailed caption for each image with this instruction: “Describe what you see in each image using a single short sentence”. We did not iterate on the quality of these manual captions. (p. 4)
With this small dataset, we fine-tuned PaLI for 300 steps, using a learning rate of 4e-5, dropout rate of 0.1 and a batch size of 64, mixing 50% short captions and 50% long captions for multiple copies of the 100 images, using a different fixed conditioning prefix for the short vs. long captions. (p. 4)
Image Generation Model
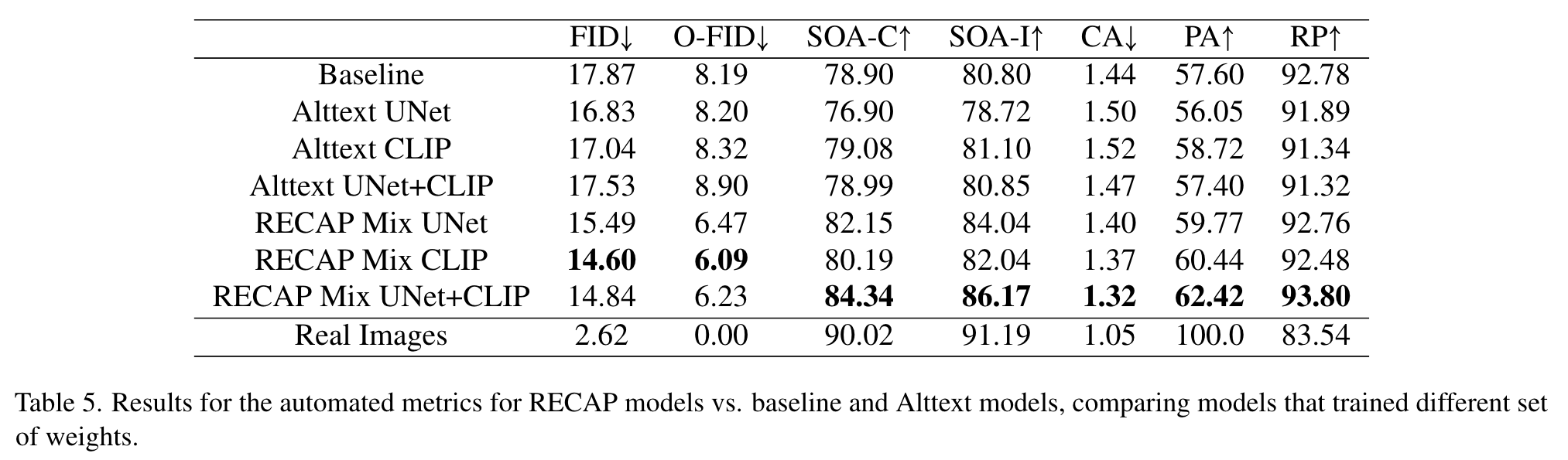
Next, we fine-tuned Stable Diffusion v1.4 for an additional 250k3 steps with a learning rate of 1e-5, batch size of 512, and prompt dropout rate of 0.14. We fine-tuned the model training both UNet and CLIP weights and used a 50%-50% mixture of RECAP Short and RECAP Long captions (RECAP Mix) as this performed best. (p. 4)
Results



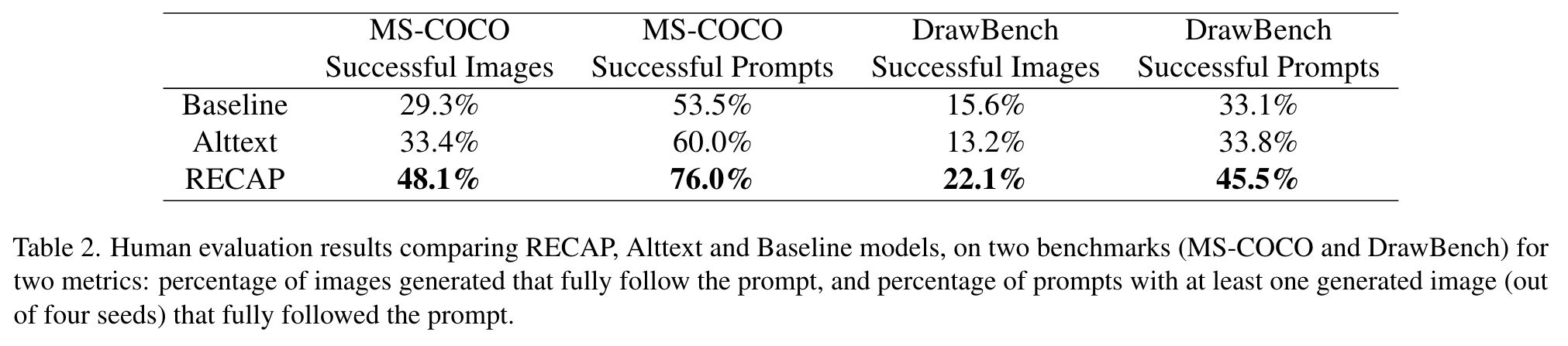
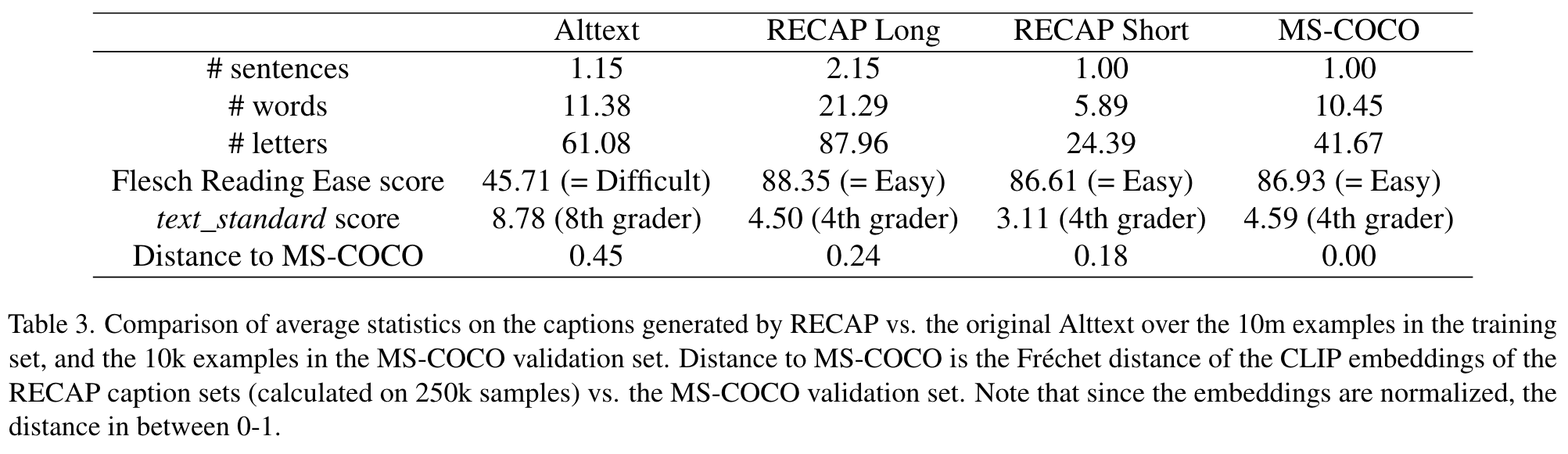
We observe that RECAP is able to generate easy to read sentences, while the original Alttext is often difficult to read. (p. 7)
As suspected, RECAP generated captions are closer in distribution to the MS-COCO captions than the Alttext captions. Furthermore, the RECAP Short captions are closer to MS-COCO than RECAP Long captions. (p. 7)
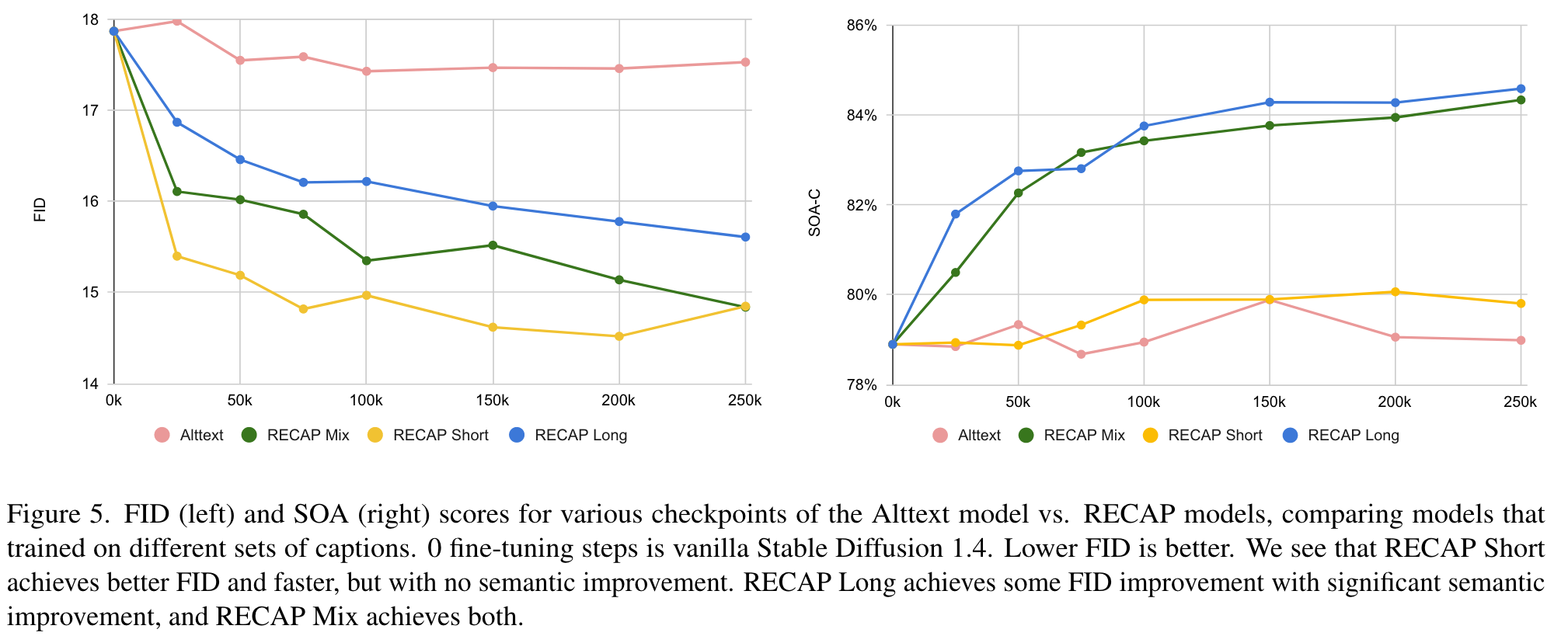
We observe that training on RECAP Short captions achieves better FID scores, and faster, but with little semantic improvement, while the RECAP Long captions exhibit significant semantic improvement (see representative metrics in Fig. 5). Mixing the caption sets (RECAP Mix) provides the best of both worlds. (p. 7)