ProlificDreamer High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
[vsd variational-score-distillation diffusion prolific-dreamer score-distillation-sampling distill deep-learning sds dreamfusion text2image 3d This is my reading note on ProlificDreamer High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. This method proposes variational score sampling to replace score distillation sampling to improve the details of text to image or text to 3D models. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/
Introduction
Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of aconstant as in SDS and present variational score distillation (VSD), a principledparticle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality witha common CFG weight (i.e., 7.5). (p. 1)

DreamFusion introduces the Score Distillation Sampling (SDS) algorithm to optimize a single 3D representation such that the image rendered from any view maintains a high likelihood as evaluated by the diffusion model, given the text (p. 3)
Score distillation sampling (SDS) is an optimization method by distilling pretrained diffusion models, also known as Score Jacobian Chaining (SJC) [54]. It is widely used in text-to-3D generation [33, 54, 20, 28, 54, 4] with great promise. SDS optimizes the parameter $\theta$ by solving
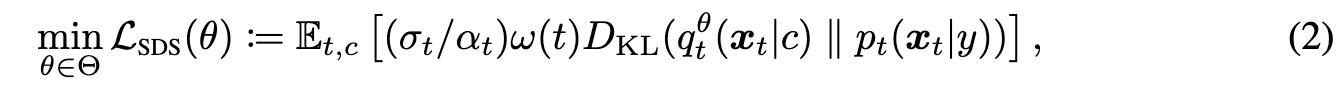 Here c is camera parameter and y the text prompt given as condition. Its gradient is approximated by:
Here c is camera parameter and y the text prompt given as condition. Its gradient is approximated by:
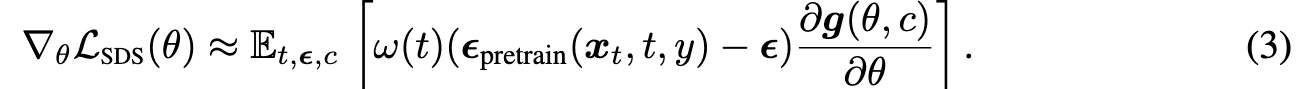
Variational Score Distillation
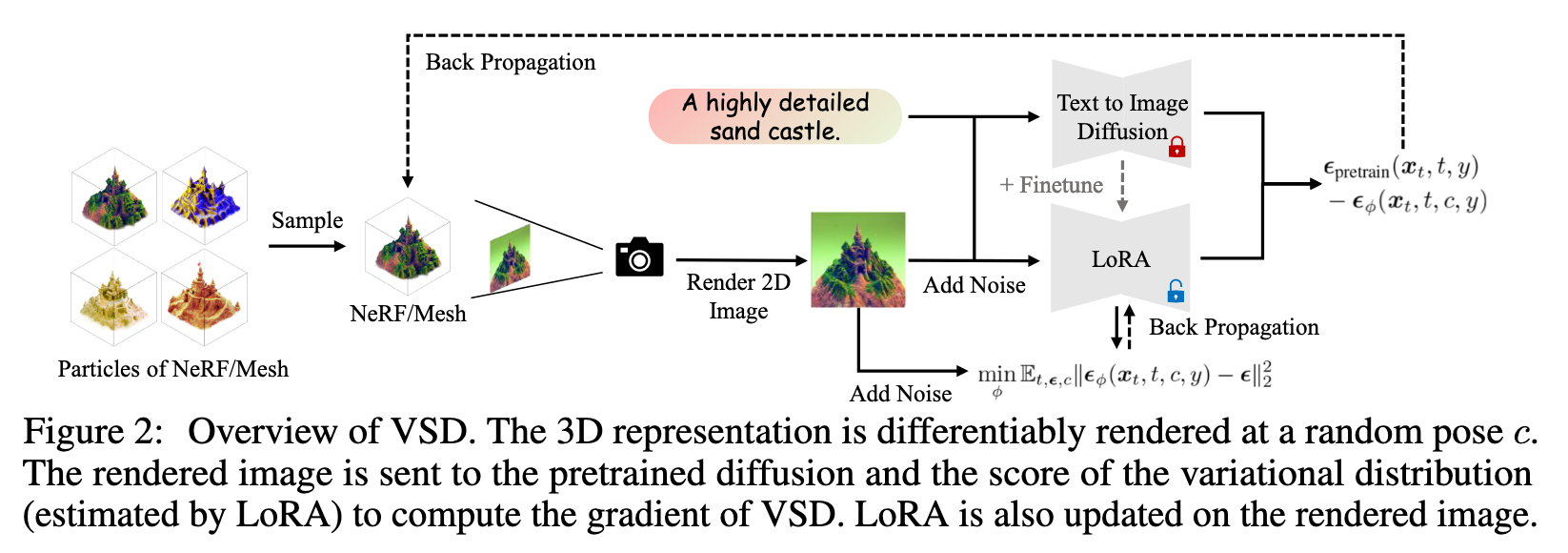
We first present Variational Score Distillation (VSD), which treats the corresponding 3D scene given a textual prompt as a random variable instead of a single point as in SDS [33]. VSD optimizes a distribution of 3D scenes such that the distribution induced on images rendered from all views aligns as closely as possible, in terms of KL divergence, with the one defined by the pretrained 2D diffusion model (see Sec. 3.1). Under this variational formulation, VSD naturally characterizes the phenomenon that multiple 3D scenes can potentially align with one prompt. To solve it efficiently, VSD adopts particle-based variational inference [23, 3, 9], and maintains a set of 3D parameters as particles to represent the 3D distribution. We derive a novel gradient-based update rule for the particles via the Wasserstein gradient flow (see Sec. 3.2) and guarantee that the particles will be samples from the desired distribution when the optimization converges (see Theorem 2). Our update requires estimating the score function of the distribution on diffused rendered images, which can be efficiently and effectively implemented by a low-rank adaptation (LoRA) [18, 39] of the pretrained diffusion model. The final algorithm alternatively updates the particles and score function. (p. 3)
The VSD could be described as:
To obtain 3D representations of high visual quality, we propose to optimize the distribution $\mu$ to align its samples with the pretrained diffusion model by solving:
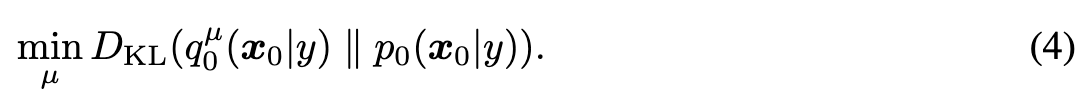
This is a typical variational inference problem that uses the variational distribution $q_0^\mu(x_0|y)$ to approximate (distill) the target distribution $p_0(x_0|y)$ (p. 5). We simultaneously solve an ensemble of these problems (termed as variational score distillation or VSD) as follows:
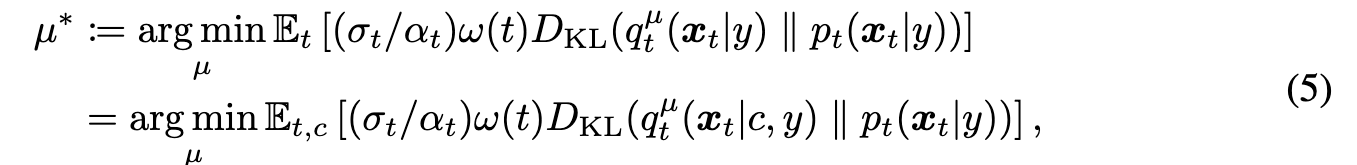
Here \(q_t^\mu(x_t|y):=\int q_0^\mu(x_0|y)p_{t_0}(x_t|x_0)d_{x_0}\) To solve problem (5), a direct way can be to train another parameterized generative model for $\mu$, but it may bring much computation cost and optimization complexity. Inspired by previous particle-based variational inference [23, 3, 9] methods, we maintain n 3D parameters $\theta_{i=1}^n$ as particles and derive a novel update rule for them. Intuitively, we use $\theta_{i=1}^n$ to “represent” the current distribution $\mu$, and $\theta(i)$( will be samples from the optimal distribution $\mu^*$ if the optimization converges (p. 5)
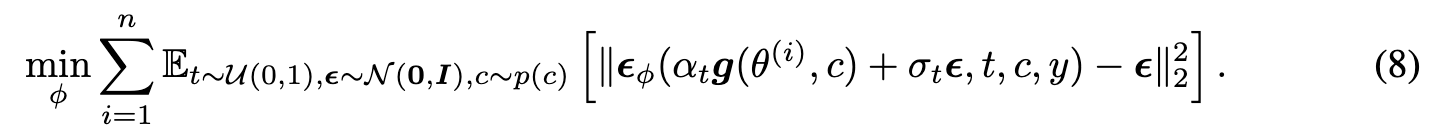
In practice, we parameterize $\epsilon_\phi$ by either a small U-Net [38] or a LoRA (Low-rank adaptation [18, 39]) (p. 6). The gradient could be computed as:
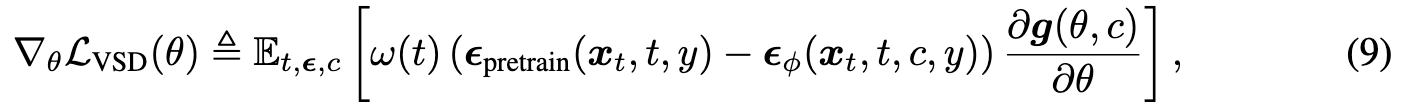
The algorithm of VSD could be written as:

Comparison with SDS
Theoretically, comparing the update rules of SDS (Eq. (3)) and VDS (Eq. (9)), SDS is a special case of VSD by using a single-point Dirac distribution $\mu(\theta|y) \approx \delta(\theta−\theta^1)$ (p. 6)
ProlificDreamer
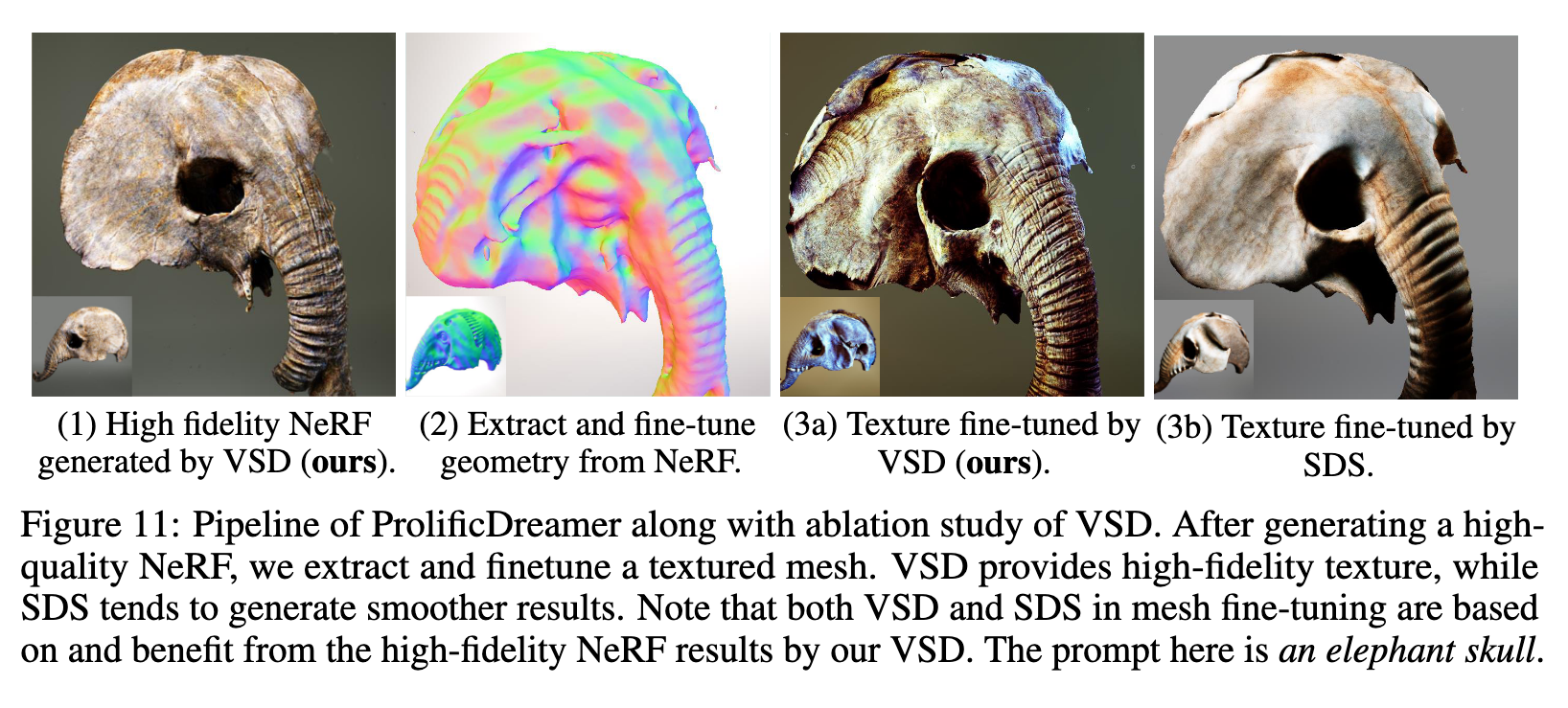
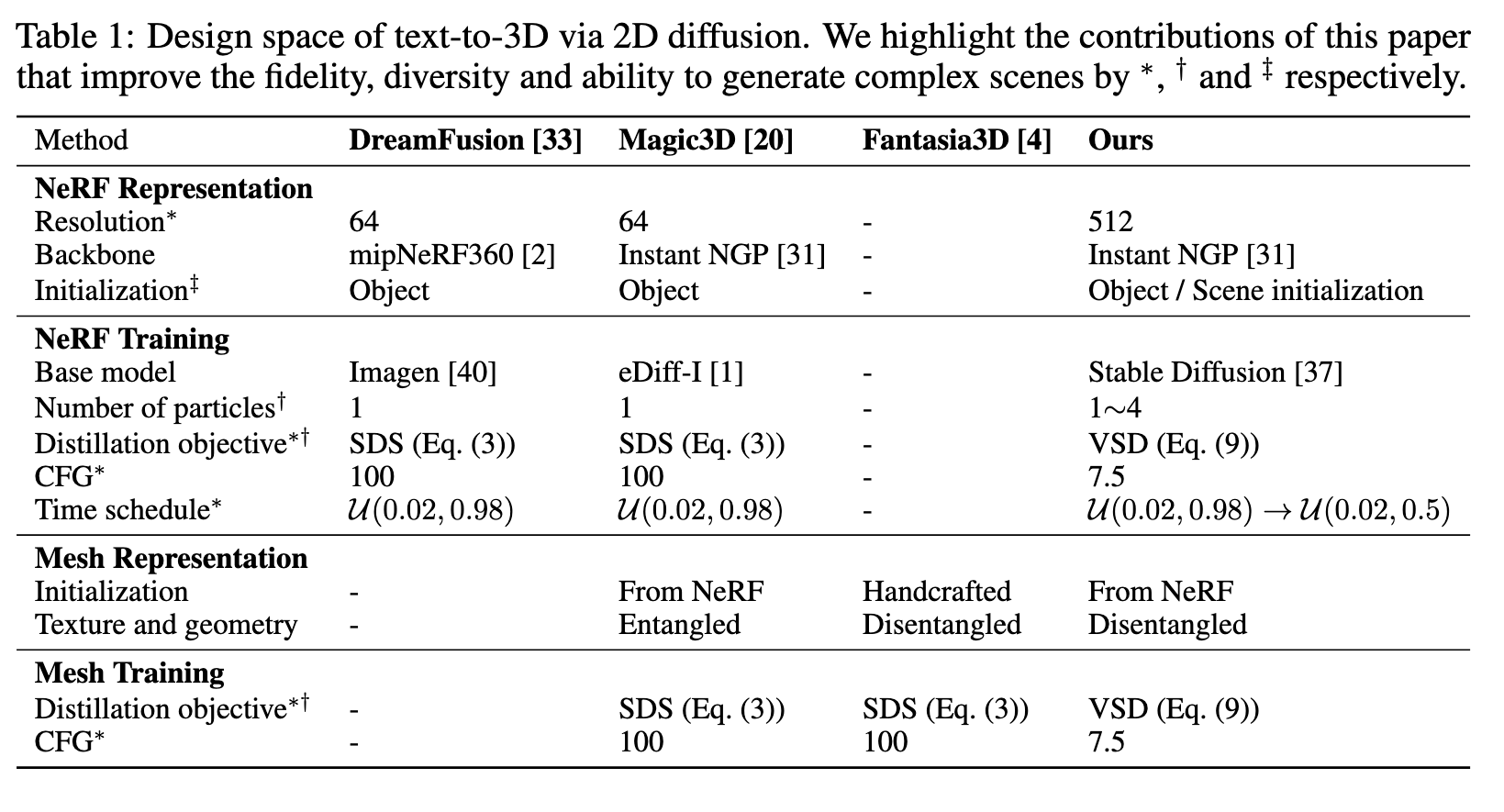 Combining all improvements highlighted in Tab. 1, we arrive at ProlificDreamer, an advanced text-to-3D approach. In the second stage, we use DMTet [44] to extract textured mesh from the NeRF obtained in the first stage, and further fine-tune the textured mesh for high-resolution details (p. 8)
Combining all improvements highlighted in Tab. 1, we arrive at ProlificDreamer, an advanced text-to-3D approach. In the second stage, we use DMTet [44] to extract textured mesh from the NeRF obtained in the first stage, and further fine-tune the textured mesh for high-resolution details (p. 8)
Experiment Result


Ablation Study

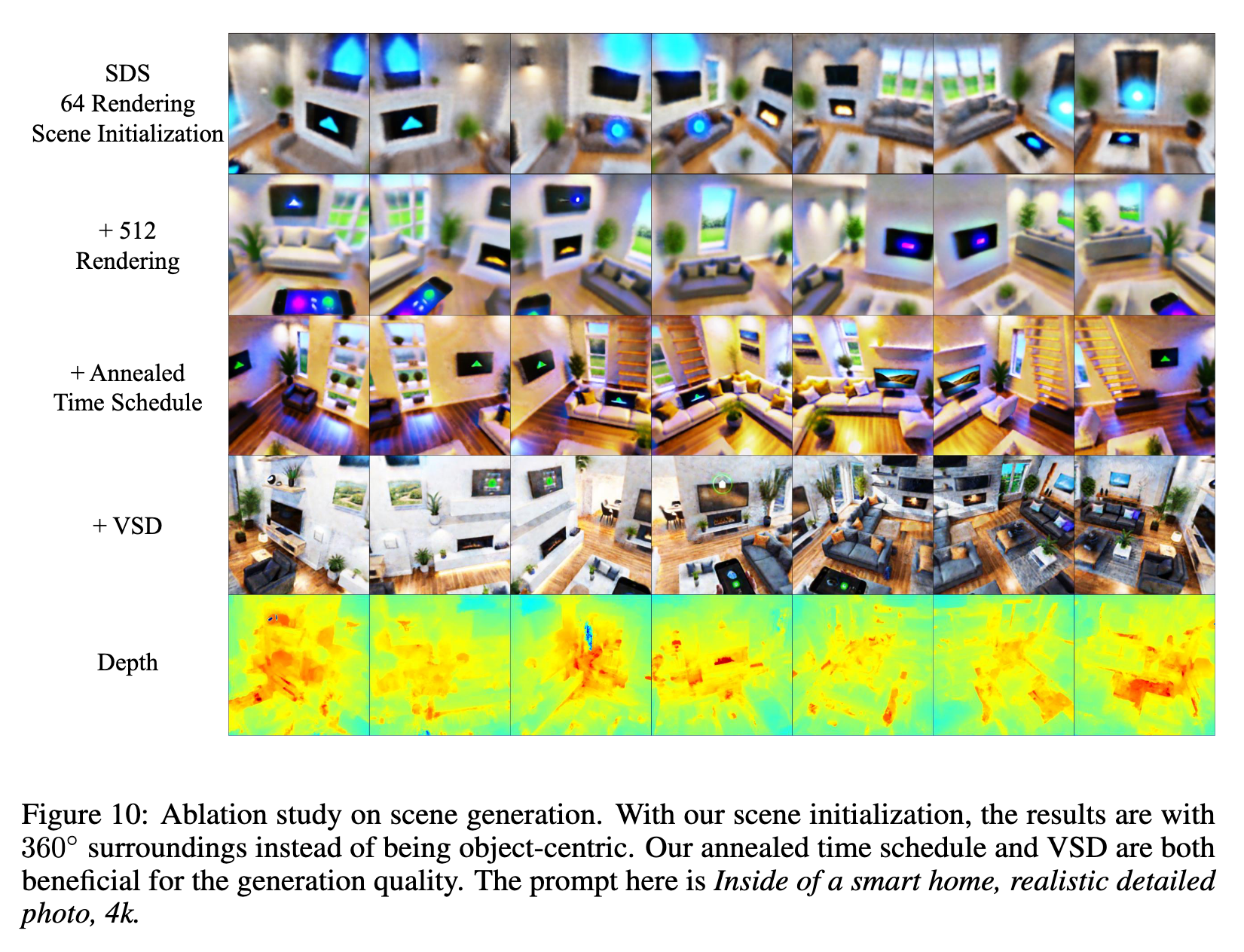
- Ablation on NeRF training. Fig. 5 provides the ablation on NeRF training. Starting from the common setting [33, 20] with 64 rendering resolution and SDS loss, we ablate our proposed improvements step by step, including increasing resolution, adding annealed time schedule, and adding VSD all improve the generated results. It demonstrates the effectiveness of our proposed components. We provide more ablation on large scene generation in Appendix E, with a similar conclusion.
- Ablation on mesh fine-tuning. We ablate between SDS and VSD on mesh fine-tuning, as shown in Appendix E. Fine-tuning texture with VSD provides higher fidelity than SDS. As the fine-tuned results of textured mesh are highly dependent on the initial NeRF, getting a high-quality NeRF at the first stage is crucial. Note that the provided results of both VSD and SDS in mesh fine-tuning are based on and benefit from the high-fidelity NeRF results in the first stage by our VSD.
- Ablation on CFG. We perform ablation to explore how CFG affects generation diversity. We find that smaller CFG encourages more diversity. Our VSD works well with small CFG and provides considerable diversity, while SDS cannot generate plausible results with small CFG (e.g., 7.5), which limits its ability to generate diverse results. Results and more details are shown in Appendix I. (p. 9)
- Ablation Study on Large Scene GenerationHere we perform an ablation study on large scene generation to validate the effectiveness of our proposed improvements. We start from 64 rendering resolution, with SDS loss and our scene initialization. The results are shown in Figure 10. It can be seen from the figure that, with our scene initialization, the results are with 360◦ surroundings instead of being object-centric. Increasing rendering resolution is slightly beneficial. Adding annealed time schedule improves the visual quality of the results. Replacing SDS with VSD makes the results more realistic with more details. (p. 21)
- E.2 Ablation Study on Mesh Fine-tuningHere we provide an ablation study on mesh fine-tuning. Fine-tuning with textured mesh further improves the quality compared to the NeRF result. Fine-tuning texture with VSD provides higher fidelity than SDS. Note that both VSD and SDS in mesh fine-tuning is based on and benefit from the high-fidelity NeRF results by our VSD. And it’s crucial to get a high-quality NeRF with VSD at the first stage.
- E.3 Ablation on Number of ParticlesHere we provide ablation study on number of particles. We vary the number of particles in 1, 2, 4, 8and examine how will the number of particles affects the generated results. The CFG of VSD is set as 7.5. The results are shown in Fig. 12. As is shown in the figure, the diversity of the generated results is slightly larger as the number of particles increases. Meanwhile, the quality of generated results is not affected much by the number of particles. Owing to the high computation overhead to optimize3D representations and limitations on computation resources, we now only test at most 8 particles. We provide a 2D experiment with 2048 particles in Appendix H to demonstrate the scalability of VSD. We leave the experiments of more particles in 3D as future work.
- E.4 Ablation on Rendering ResolutionHere we provide an ablation study on the rendering resolution during NeRF training with VSD. As shown in Fig. 13, training with a higher resolution produces better results with finer details. Inaddition, our VSD still provides competitive results under a lower training resolution (128 or 256), which is more computationally efficient than the 512 resolution. (p. 22)


Limitations
Although ProlificDreamer achieves remarkable text-to-3D results, currently the generation takes hours of time, which is much slower than image generation by a diffusion model. Although large scene generation can be achieved with our scene initialization, the camera poses during training are regardless of the scene structure, which may be improved by devising an adaptive camera pose range according to the scene structure for better-generated details. (p. 10)