Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
[object-detection llm multimodal tool segment deep-learning prompt gpt-4v segment-anything-model sam instance-segmentation semantic-segmentation seem mask-dino semantic-sam open-vocabulary open-seed grounding-dino glip-v2 poly-former seg-gpt This is my reading note for Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. This paper demonstrates how to combine the Sam with gpt-4v to perform more fine grained visual understanding of visual data. To this end, the paper first uses Sam to annotate the image with region marks and number. GPT-4V is then promoted to understand the image with those annotations.

Introduction
we employ off-the-shelf interactive segmentation models, such as SAM, to partition an image into regions at different levels of granularity, and overlay these regions with a set of marks e.g., alphanumerics, masks, boxes. Using the marked image as input, GPT-4V can answer the questions that require visual grounding. (p. 1)
Despite the unprecedented, strong, vision-language understanding capabilities, GPT-4V’s fine-grained visual grounding ability is relatively weak, or yet to be unleashed. For example, GPT-4V can hardly produce a sequence of accurate coordinates for a dog in the image1, or a few traffic lights [54]. (p. 2)
in this study we focus on improving visual inputs by proposing a new visual prompting method to unleash the visual grounding capability of LMMs. One is to encode visual prompts such as point, box, and stroke into latent features, which are then used to prompt the vision models [65, 19]. The other is to overlay visual marks directly onto the input images. (p. 2)
Despite the size of LLMs growing dramatically, eliciting reasoning capabilities still requires more sophisticatedly designed queries, i.e., prompting. In the past, a number of works attempted to do prompt engineering to endow more capability for LLMs. In-context learning is a main-stream way to teach LLMs to follow specific instructions as instantiated by a few examples [2, 15] As a follow-up, some other techniques such as chain-of-thought and tree-of-thought [47, 53] are proposed to enhance the arithmetic, commonsense, and symbolic reasoning tasks. (p. 11)
Set-of-Mark Prompting
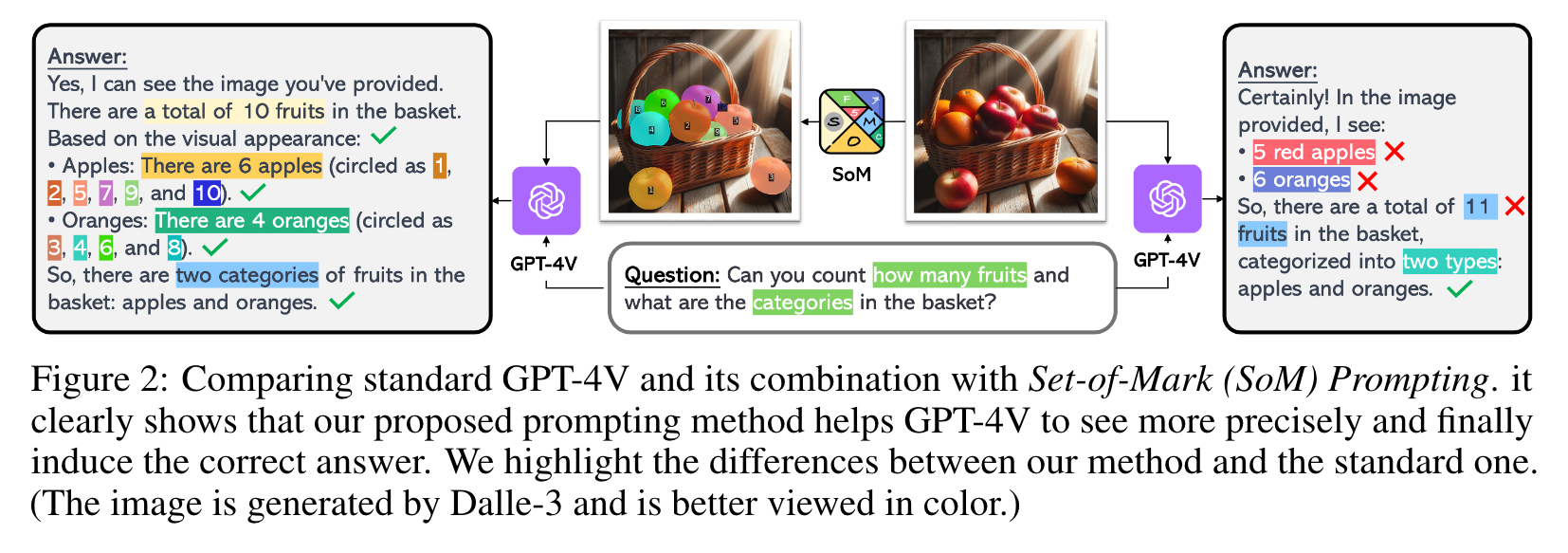
we develop Set-of-Mark Prompting, a simple prompting method of overlaying a number of marks to the meaningful regions in an image. This operation augments the input image I to a marked image Im while keeping the other inputs to LMMs unchanged (p. 3)
Although it is straightforward to apply SoM to all LMMs, we find that not all LMMs have the ability to “speak out” about the marks. Actually, we find that only GPT-4V, when equiped with SoM, shows the emergent grounding ability and significantly outperforms the other LMMs. (p. 3)
Image Partition

The requirement of segmentation tools:
- Strong performance: the region partition should be precise enough to convey fine-grained spatial layout information to GPT-4V. In this sense, we choose one of the state-of-the-art image segmentation models MaskDINO [24].
- Open vocabulary: the segmentation models should be open-vocabulary so that they can recognize objects out of predefined vocabulary. As such, we opt for the advanced models like SEEM [65].
- Rich granularity: Finally, the region of interest might be not only a full object but also a part of it. Therefore, we also employ SAM [19] and Semantic-SAM [21]. (p. 4)
Based on our image partition toolkit, we divide an input image I of size H × W into K regions $R=[r_1,\dots,r_k]\in {0,1}^{K\times H \times W}$, which are represented by K binary masks. (p. 4)
Set-of-Mark Generation

Mark Type. In addition, we note that the mark types should be image-dependent to avoid any conflicts with the original image contents. For example, given an arithmetic image full of numbers, the numeric marks should be avoided, while the alphabetic characters should be not used for a screenshot of a document. We leave the automatically determining which mark types to use and how to combine them to future work (p. 4)

Mark Location. The resulting mask is then fed to a distance transform algorithm, which helps to find the location inside the mask where the minimal distance to all boundary points is maximal. In practice, however, a region may be so small that the mark could cover the (almost) whole region. In this case, we move the marks off the region slightly. W The resulting mask is then fed to a distance transform algorithm, which helps to find the location inside the mask where the minimal distance to all boundary points is maximal. In practice, however, a region may be so small that the mark could cover the (almost) whole region. In this case, we move the marks off the region slightly (p. 5)
Interleaved Prompt

SoM Prompting for Vision
We highlight that the unique merit of using SoM to prompt GPT-4V is that it can produce outputs beyond texts. Since each mark is exclusively associated with an image region represented by a mask, we can trace back the masks for any mentioned marks in the text outputs. (p. 6)

- Open-vocabulary Image Segmentation: We ask GPT-4V to exhaustively tell the categories for all marked regions and the categories that are selected from a predetermined pool.
- Referring Segmentation: Given a referring expression, the task for GPT-4V is selecting the top-matched region from the candidates produced by our image partition toolbox. (p. 6)
- Phrase Grounding: Slightly different from referring segmentation, phrase grounding uses a complete sentence consisting of multiple noun phrases. We ask GPT-4V to allocate the corresponding regions for all labeled phrases.
- Video Object Segmentation: It takes two images as input. The first image is the query image which contains a few objects of interest to identify in the second image. Given that GPT-4V supports multiple images as input, our prompting method can also be applied to ground visual objects across frames in a video. (p. 7)
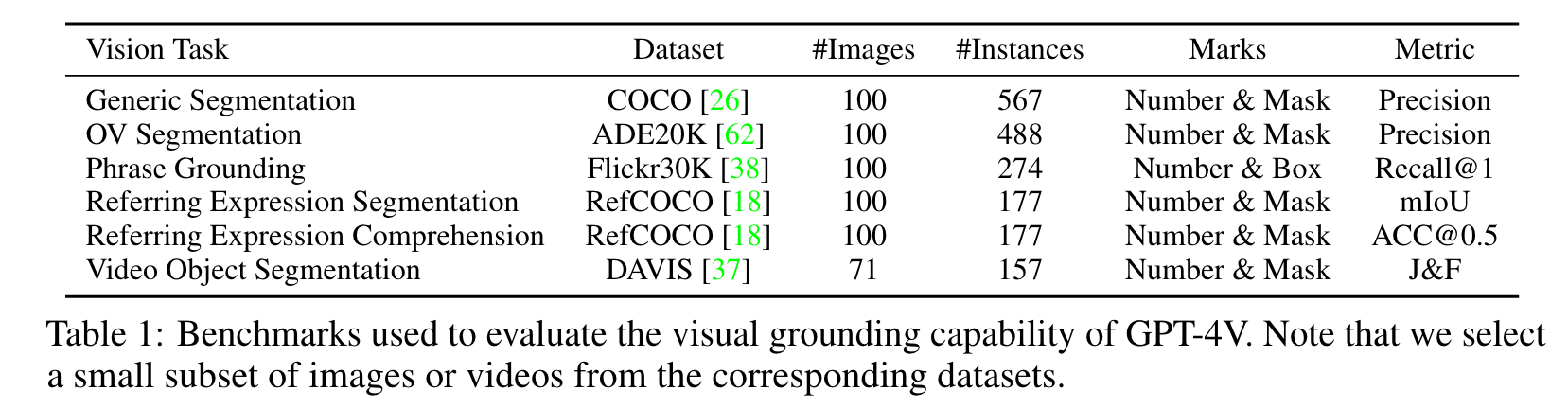
Experiments
State-of-the-art specialist models. For each of the vision tasks, a number of methods have been proposed. We choose state-of-the-art and representative methods for comparison. More specifically,
- MaskDINO [24] for generic segmentation on COCO,
- OpenSeeD [55] for zeroshot segmentation on ADE20K,
- Grounding DINO [31] and GLIPv2 [56] for phrase grounding on Flick30K,
- Grounding DINO and PolyFormer [29] for referring expression comprehension,
- PolyFormer and SEEM [65] for referring expression segmentation
- and SegGPT [46] for video object segmentation. We attempt to shed light on the gap between the strongest generalist vision model GPT-4V and specialist models that are sophisticatedly designed and trained with the take-specific data. (p. 8)
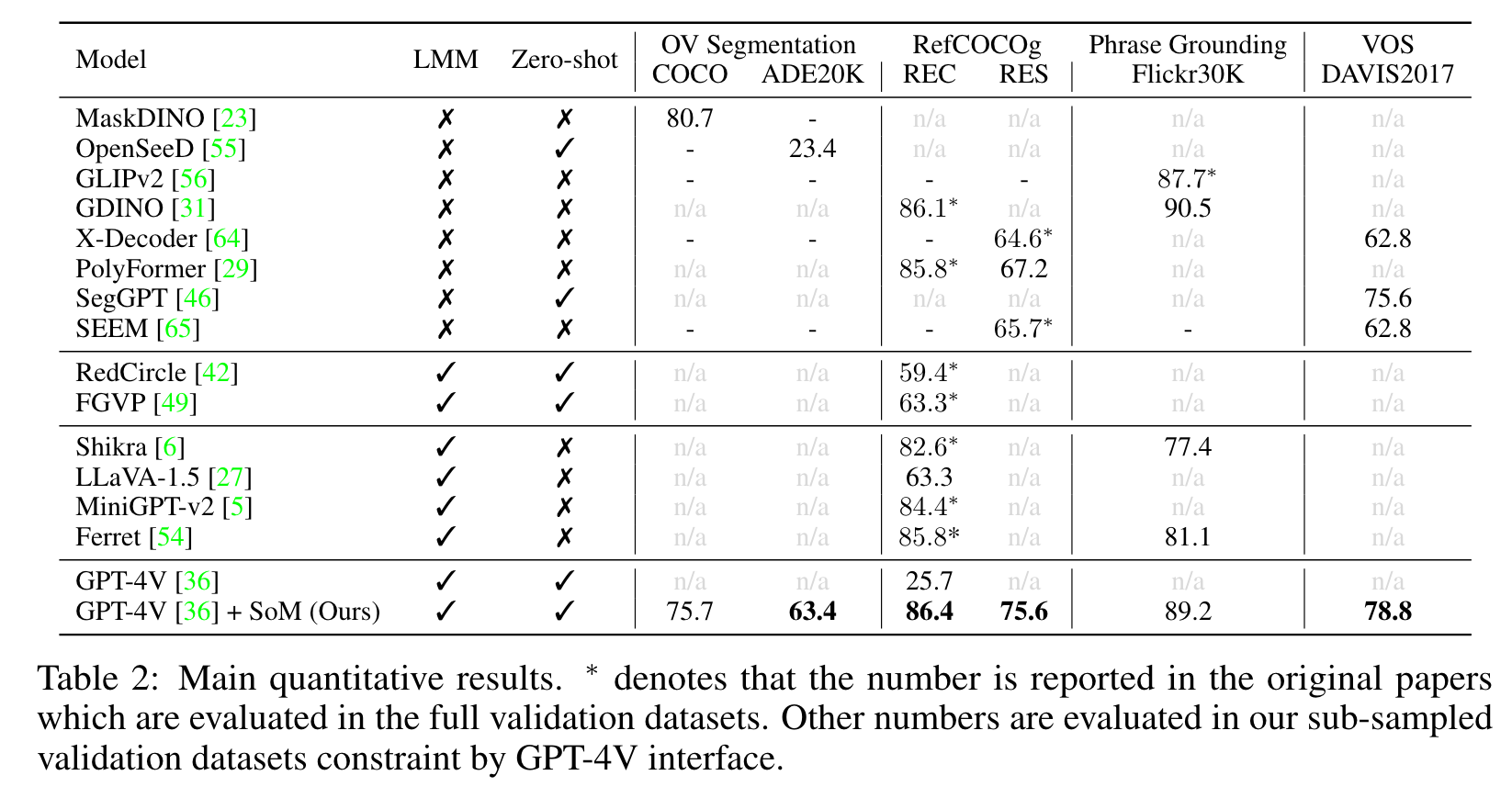

Ablation Study

Mark type As shown in Table 3, the scheme of adding extra boxes can improve the performance significantly (p. 10)
Golden mark location. We also observe that most failure cases when using GT masks are not the GPT-4V’s problem, but the annotation itself is ambiguous or incorrect. (p. 10)
These results indicate that the focus of GPT-4V to understand visual contents is not necessarily at the center. Developing a better mark allocation algorithm should be considered. (p. 10)
Discussion
The mystery in GPT-4V. It is still mysterious why the proposed Set-of-Mark Prompting could work so well with GPT-4V. Out of curiosity, we also ran some examples on other open-sourced LMMs such as LLaVa-1.5 and MiniGPT-v2. However, both models can hardly interpret the marks and ground themselves on those marks. We hypothesize a few reasons for the extraordinary visual grounding capability exhibited in GPT-4V. First, scale matters. We believe the scale of model and training data used in GPT-4V is several orders of magnitude than the aforementioned open-sourced LMMs. Second, the data curation strategy is probably another secret sauce for GPT-4V. GPT-4V could automatically associate the image regions and marks without any explicit prompt in texts. Such kind of data could be probably from literature figures, charts, etc, which are usually clearly labeled or marked [1]. We doubt that GPT-4V specifically employs fine-grained vision data as covered in this work. (p. 12)