SEED-Bench Benchmarking Multimodal LLMs with Generative Comprehension
[multimodal deep-learning dataset seed benchmark mme mmbench lamm lvlm-ehub blip blip2 llama llava gpt instruct-blip vicuna video-chat vide-chatgpt mplug-owl This is my reading note for SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. This paper proposes a benchmark suite of modality LLM. It introduces how is the data created and how is the task derived. For evaluation, it utilizes the model’s output of likelihood of answers instead of directly on text answers.
Introduction
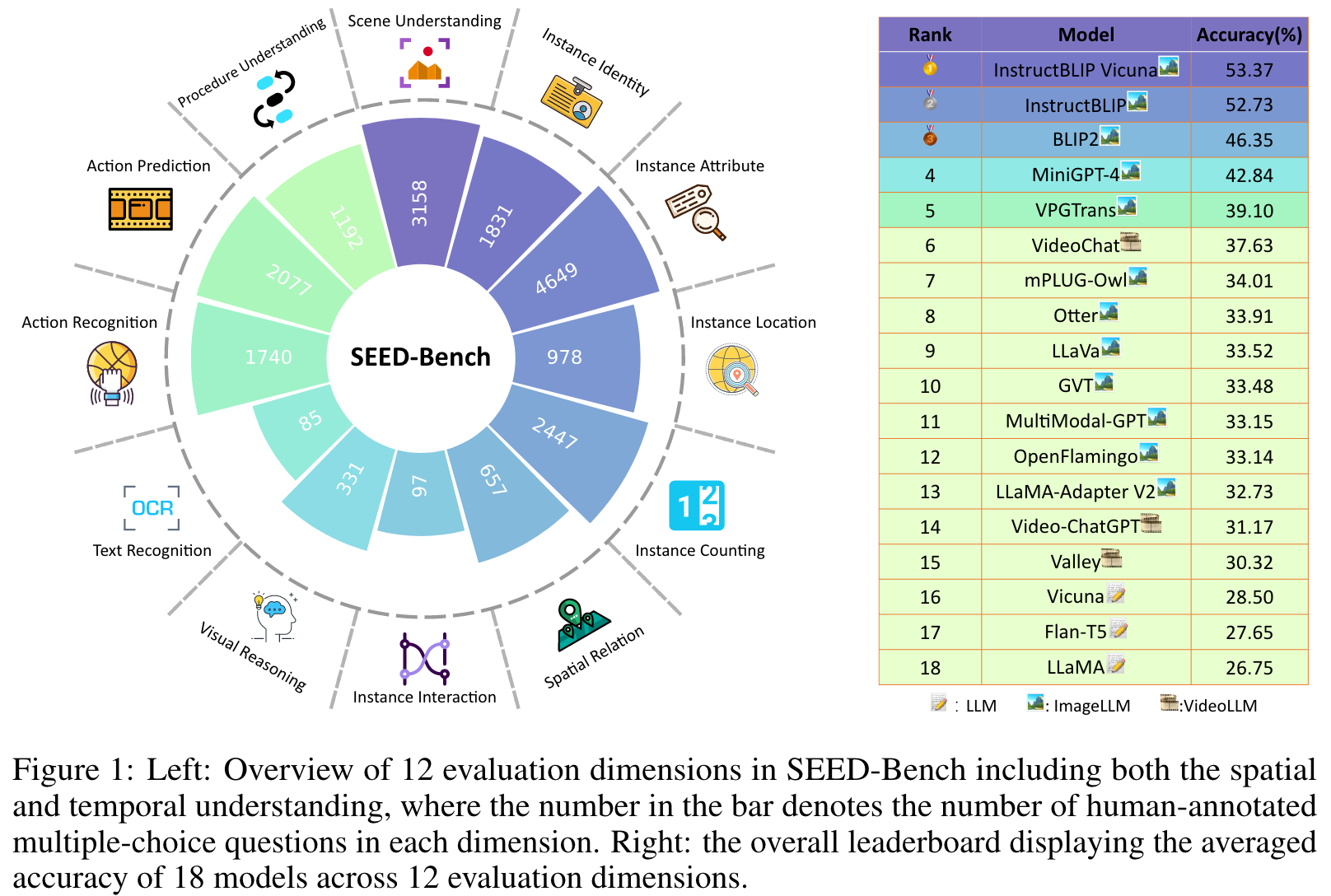
SEED-Bench consists of 19K multiple choice questions with accurate human annotations (×6 larger than existing benchmarks), which spans 12 evaluation dimensions including the comprehension of both the image and video modality. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. (p. 1)
LVLM-eHub [25] and LAMM [24] utilize exiting public datasets across various computer vision tasks as evaluation samples, and employ human annotators or GPT to assess the quality, relevance, and usefulness of model’s predictions. However, the involvement of human and GPT during evaluation not only compromises efficiency, but also leads to increased subjectivity and reduced accuracy of the assessment. MME [23] and MMBench [26] further advance objective evaluation of MLLMs by constructing True/False Questions or Multiple-Choice Questions, which cover a variety of ability dimensions. (p. 2)
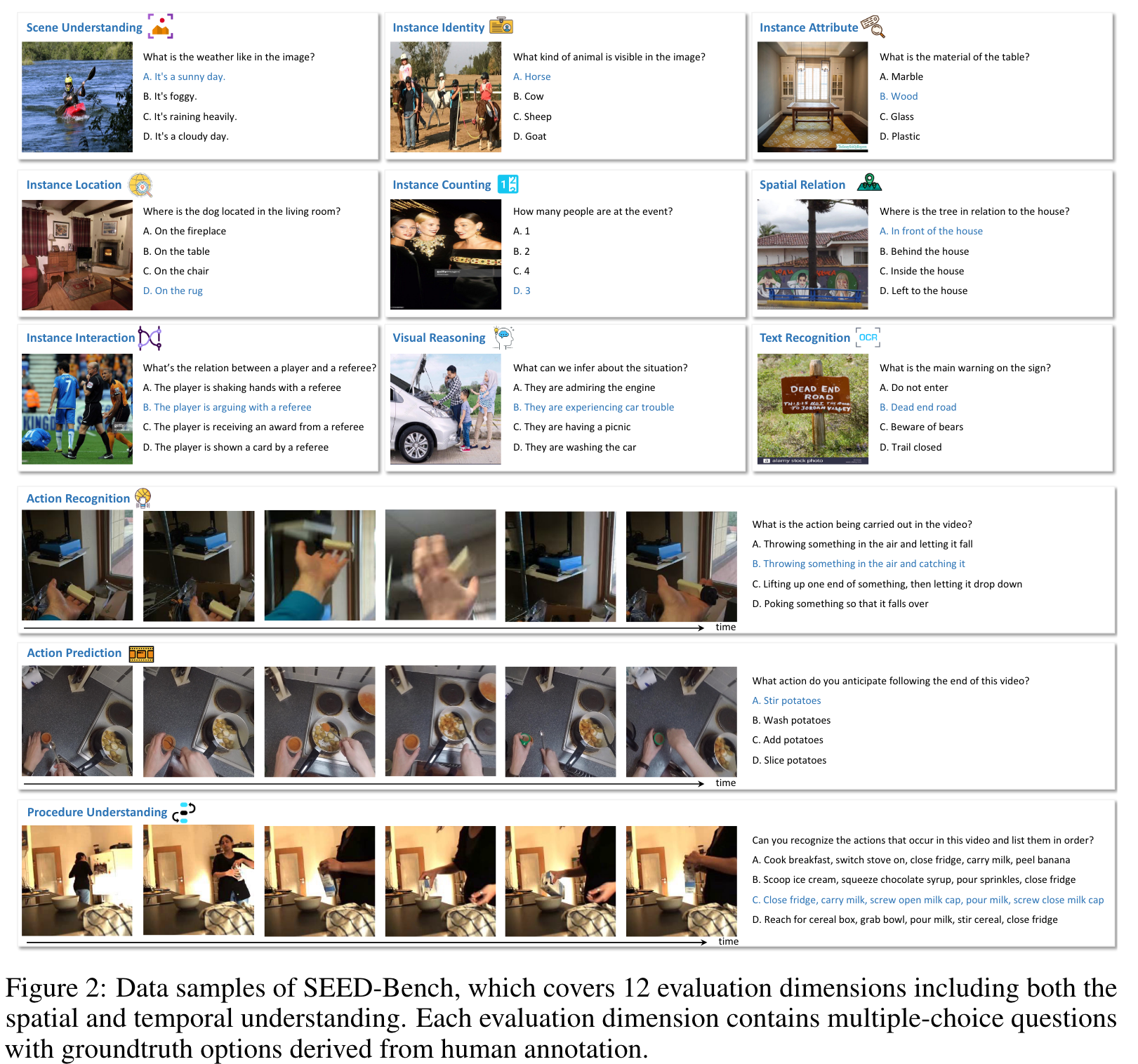
Specifically, for images, we utilize various foundation models to extract their visual information including image-level captions [6, 27], instance-level descriptions [28, 29, 30] and textual elements [31]. For videos, we leverage the original human annotations to provide visual information. We then feed the visual information to ChatGPT/GPT-4 with specially designed prompts corresponding to specific evaluation dimension. ChatGPT/GPT-4 subsequently generates questions as well as four candidate options with one groundtruth answer. We further filter out questions that can be answered without the visual input through utilizing multiple LLMs. Finally, we employ human annotators to choose the correct option of each multiple-choice question and classify each question into one evaluation dimension, resulting in a clean and high-quality benchmark containing 19K multiple-choice questions. (p. 2)

we follow GPT-3 [32] to calculate log-likelihood for each candidate option and select the one with the highest value as the final prediction, without relying on the instruction-following capabilities of models to output “A” or “B” or “C” or “D”. (p. 3)
SEED-Bench
Evaluation Dimensions
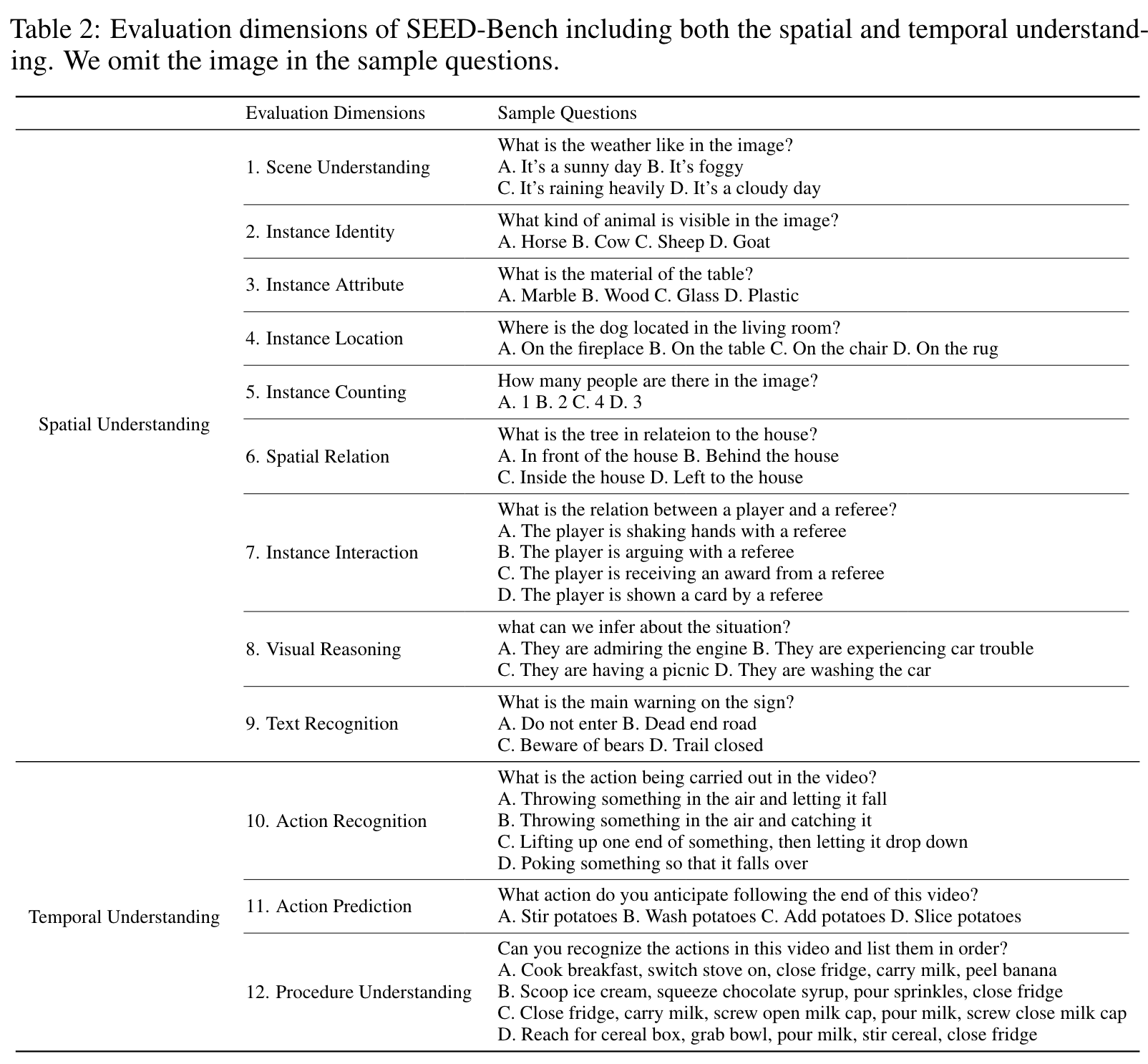
Data Source
In SEED-Bench, we use CC3M [34] dataset with filtered samples to build questions for spatial understanding. Specifically, considering the noisy original captions of CC3M, we generate captions for each image with Tag2Text [27]. We filter out those images with no more than 5 nouns in their captions (p. 6)
We further adopt Something-Something-v2 (SSV2) [35], Epic-kitchen 100 [36] and Breakfast [37] dataset to build questions for temporal understanding. (p. 6)
Multiple-Choice Questions
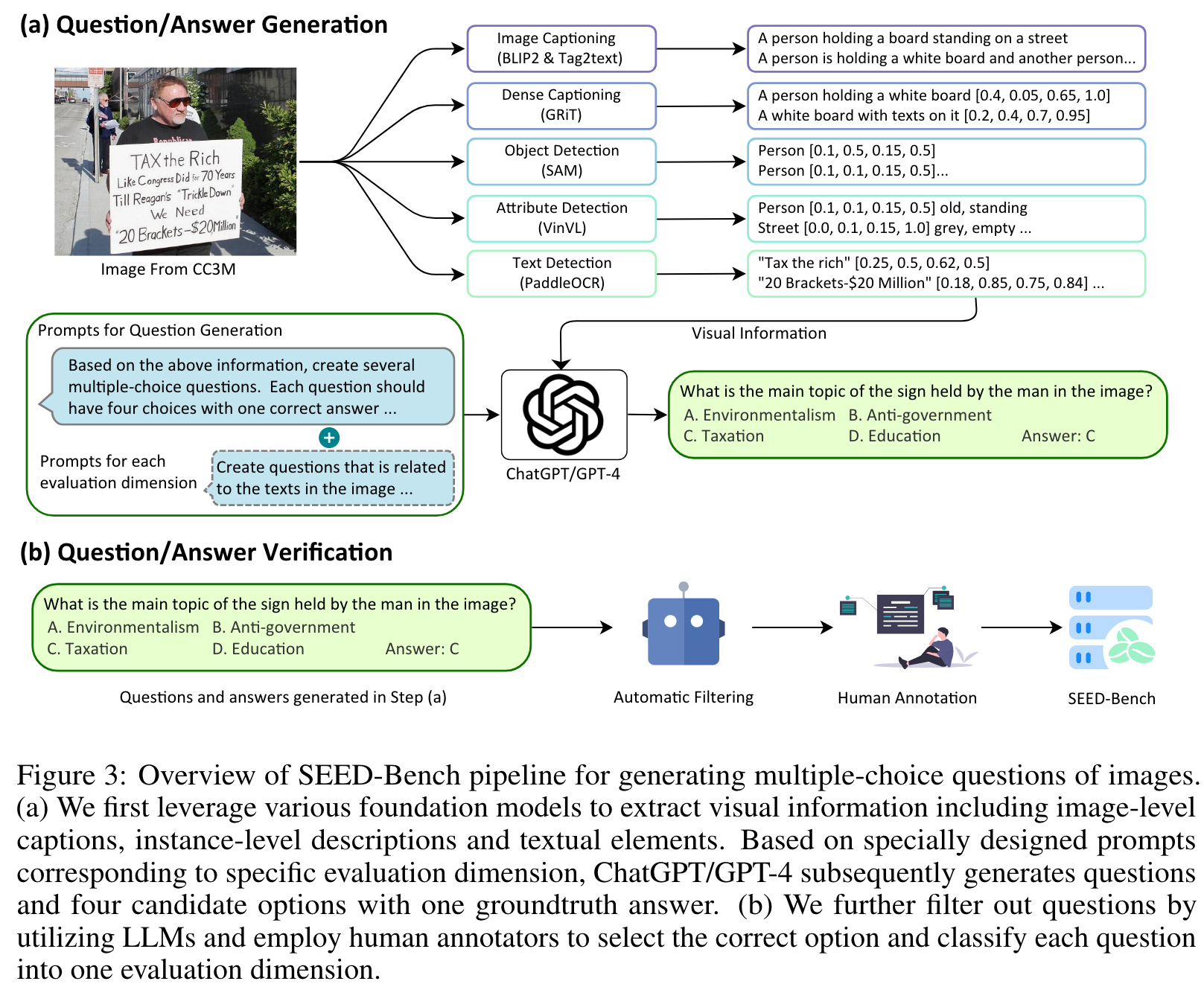
For generating question/answer pairs, we first leverage various foundation models to extract visual information including image-level captions, instance-level descriptions and textual elements. Based on specially designed prompts corresponding to specific evaluation dimension, ChatGPT/GPT-4 subsequently generates questions and four candidate options with one groundtruth answer. For verifying question/answer pairs, we filter out questions that can be answered correctly by multiple LLMs without resorting to visual information. We further employ human annotators to select the correct option and classify each question into one evaluation dimension. (p. 6)

Evaluation Strategy
Specifically, for each choice of a question, we compute the likelihood that an MLLM generates the content of this choice given the question. We select the choice with the highest likelihood as model’s prediction. Our evaluation strategy does not rely on the instruction-following capabilities of models to output “A” or “B” or “C” or “D”. (p. 9)
Evaluation Results
Results
We are surprised to observe that InstructBLIP [10] not only achieves the best performance based on the averaged results across nine dimensions for evaluating spatial understanding, but also surpasses VideoLLMs in terms of the averaged results across three dimensions for evaluating temporal understanding (p. 9)
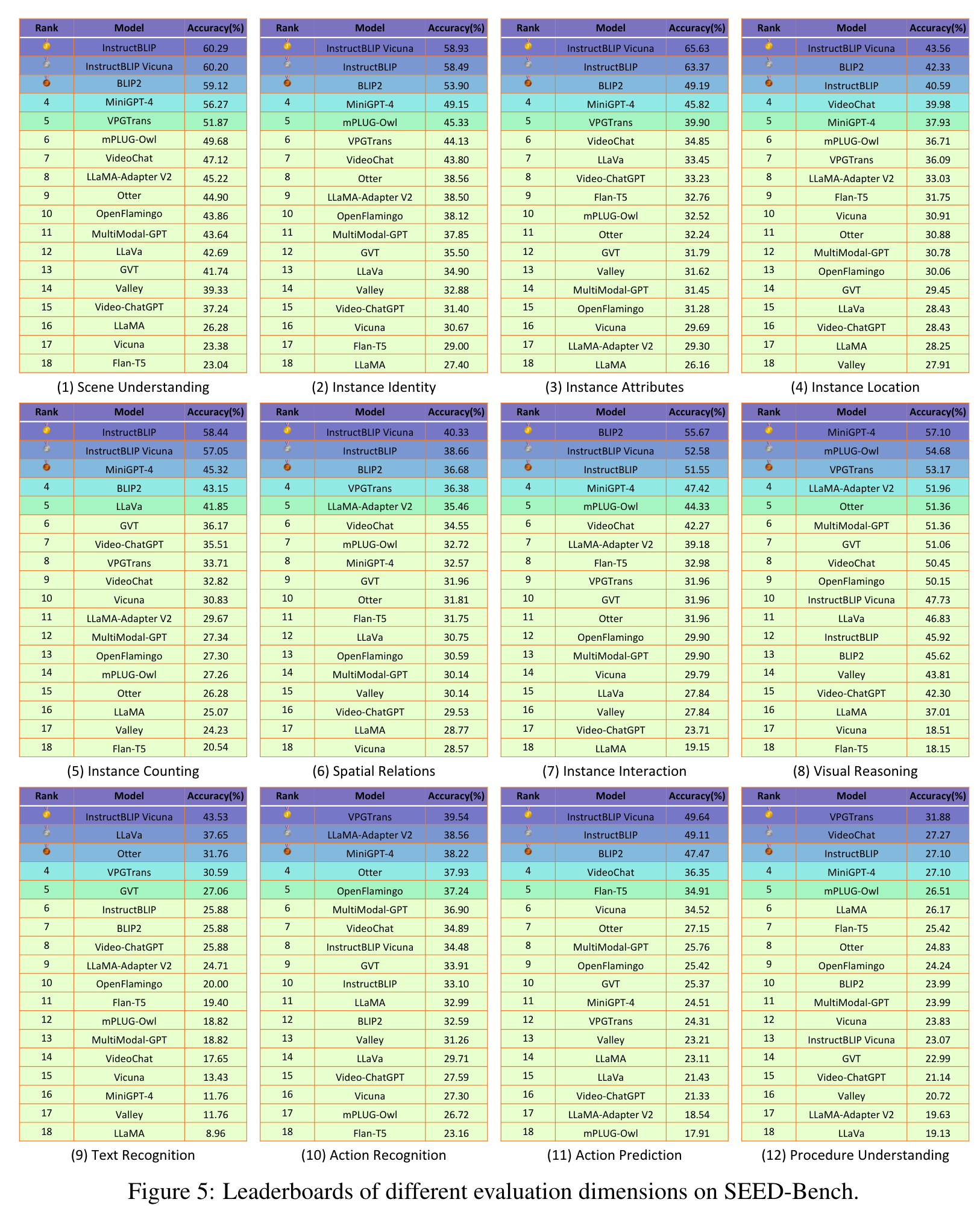
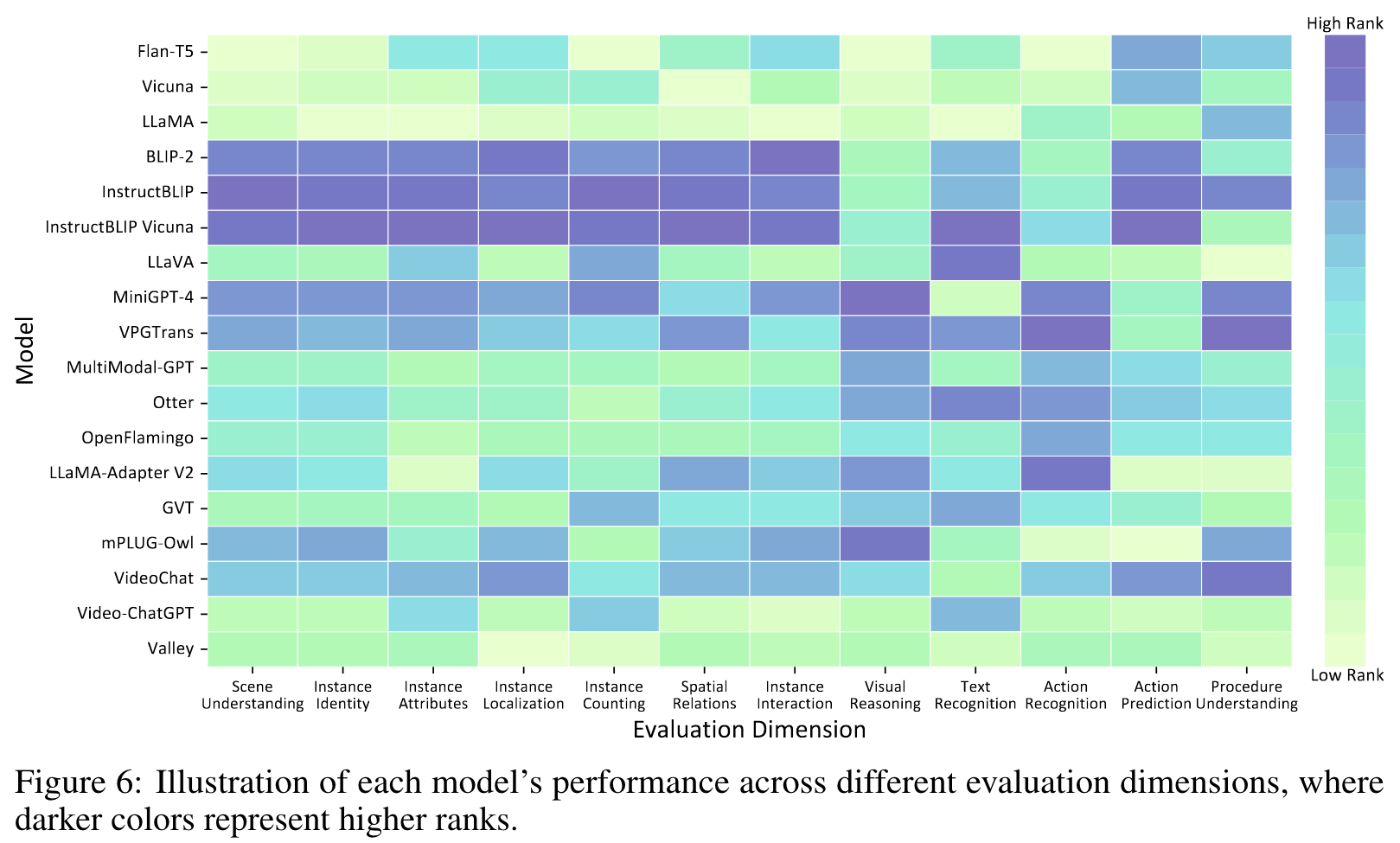
Analysis
However, when comparing the performance of MLLMs to LLMs, we observe that the performance improvement of most MLLMs is still relatively limited. (p. 11)
MLLMs achieve relatively high performance on global image comprehension On the evaluation of scene understanding and visual reasoning, the accuracy of most MLLMs is higher than 40%, and all MLLMs outperforms LLMs. This shows that MLLMs are more proficient in global understanding and reasoning of images, compared with other evaluation dimensions that require fine-grained instance-level comprehension. (p. 11)
InstructBLIP achieves top performance on 8 of 12 evaluation dimensions. We can observe that InstructBLIP outperforms other models on 8 evaluation dimensions and the possible explanations for this superior performance are as follows. (a) The instruction-tuning data of InstructBLIP contains totally 16M samples (larger than other instruction-tuning datasets), and covers a wide range of multimodal tasks, even including QA data of OCR and temporal visual reasoning. (b) The weights of LLMs are frozen when performing instruction-tuning of InstructBLIP, which may alleviate catastrophic forgetting. However, InstructBLIP series models still perform poorly on action recognition and 1 procedure understanding that differ significantly from the instruction-tuning data. (p. 12)
MLLMs show weaker abilities in understanding spatial relationships between objects. (p. 12)
Most MLLMs show poor performance for text recognition. (p. 12)
VideoLLMs achieve promising results on spatial understanding. It shows that VideoChat’s ability of spatial understanding does not degrade by jointly training on both image and video data during the pre-training and instruction-tuning stages. (p. 12)
Most MLLMs exhibit unsatisfactory performance on fine-grained temporal understanding. This demonstrates that it is extremely difficult for both the ImageLLMs and VideoLLMs to perform fine-grained temporal reasoning so that they can recognize and sort the key actions in a video. (p. 12)
VideoLLMs fail to achieve competitive performance on temporal understanding. Although VideoLLMs are instruction-tuned on video data, they do not exhibit a significant advantage on evaluation dimensions for temporal understanding. Surprisingly, two VideoLLMS (Video-ChatGPT and Valley) even perform worse than most ImageLLMs on action recognition, action prediction and procedure understanding. It indicates that the capabilities of existing VideoLLMs for fine-grained action recognition, temporal relationship understanding and temporal reasoning are still limited. Similar concerns about existing VideoLLMs are also presented in recent works [15, 16]. (p. 12)