StableVideo Text-driven Consistency-aware Diffusion Video Editing
[text2video read diffusion neural-atlas-layers text2live dreamix dreambooth nla This is my reading note on StableVideo: Text-driven Consistency-aware Diffusion Video Editing. This paper proposes a video editing method based on diffusion. To ensure temporal consistency, the method utilizes neural atlas and inter frame interpolation. The neural atlas separate the videos into foreground and background plane. The lattes defines the mapping of pixel in frame to u v coordinate in atlas. For inter frame interpolation, the edited imago from diffusion is mapping to next frame via atlas, which is then use as initial to denote to the final contents of this frame.
Introduction
In this paper, we tackle this problem by introducing temporal dependency to exist- ing text-driven diffusion models, which allows them to generate consistent appearance for the edited objects. Specifically, we develop a novel inter-frame propagation mechanism for diffusion video editing, which leverages the concept of layered representations to propagate the appearance information from one frame to the next. We then build up a text-driven video editing framework based on this mecha- nism, namely StableVideo, which can achieve consistency- aware video editing (p. 1)

Related Work
- Dreamix [27] proposes a solution to generate consistent video according to input image/video and prompts. However, it focuses more on generating smooth motions, e.g., pose and camera movements, rather than maintaining geometric consistency of the objects across time (p. 1)
- Neural layered atlas (NLA) [24, 23] tries to tackle the temporal continuity problem by decomposing the video into a set of atlas layers, each of which describes one target object to be edited (p. 1)
- Text2LIVE [1] provides a text-driven appearance manipulation solution of adding additional edit layers on atlases, in which a specific generator for the edit layers is trained. Although it achieves good results with strict structure preserved, it is not able to apply thorough editing. M (p. 2)


Temporal Propagation in Video Editing
Some methods rely on key frames [19, 44, 50] or optical flow [37] to propagate contents between frames. (p. 2) Atlas [1, 20] tackles this problem by decomposing the video into unified 2D atlas layers for each target. This approach allows contents to be applied to the global summarized 2D atlases and mapped back to the video, achieving temporal consistency with minimal effort. Inspired by the concept of atlas approach, we employ the pre-trained neural layered atlas model to solve the inconsistency problem in diffusion video editing, thereby achieving high-quality editing results with temporal coherence (p. 3)
Here atlas the pixel in the frame to the UV coordinate in the atlas (like textures for mesh); and vice versa. Being the summary of the whole video, atlases always have distorted appearance due to the viewpoint and camera movement, which are required to be specifically pretrained and generated as in [1]. Diffusion models may fail in generating satisfied atlas pixels in many cases, so that the corresponding edited frames will also be contaminated (p. 2)
Proposed Method
Firstly, instead of editing the atlases directly, we propose to update the atlases via editing key video frames. Secondly, we introduce temporal dependency constraints for diffusion models to generate objects with consistent appearance across time. (p. 2)
In specific, we propose two effective technologies for this purpose. Firstly, to edit the objects with consistent appearance, we design an inter-frame propagation mechanism on top of the existing diffusion model [55], which can generate new objects with coherent geometry across time. Secondly, to achieve temporal consistency by leveraging NLA, we design an aggregation network to generate the edited atlases from the key frames. We then build up a text-driven diffusion-based framework, which provides high-quality natural video editing. (p. 2)
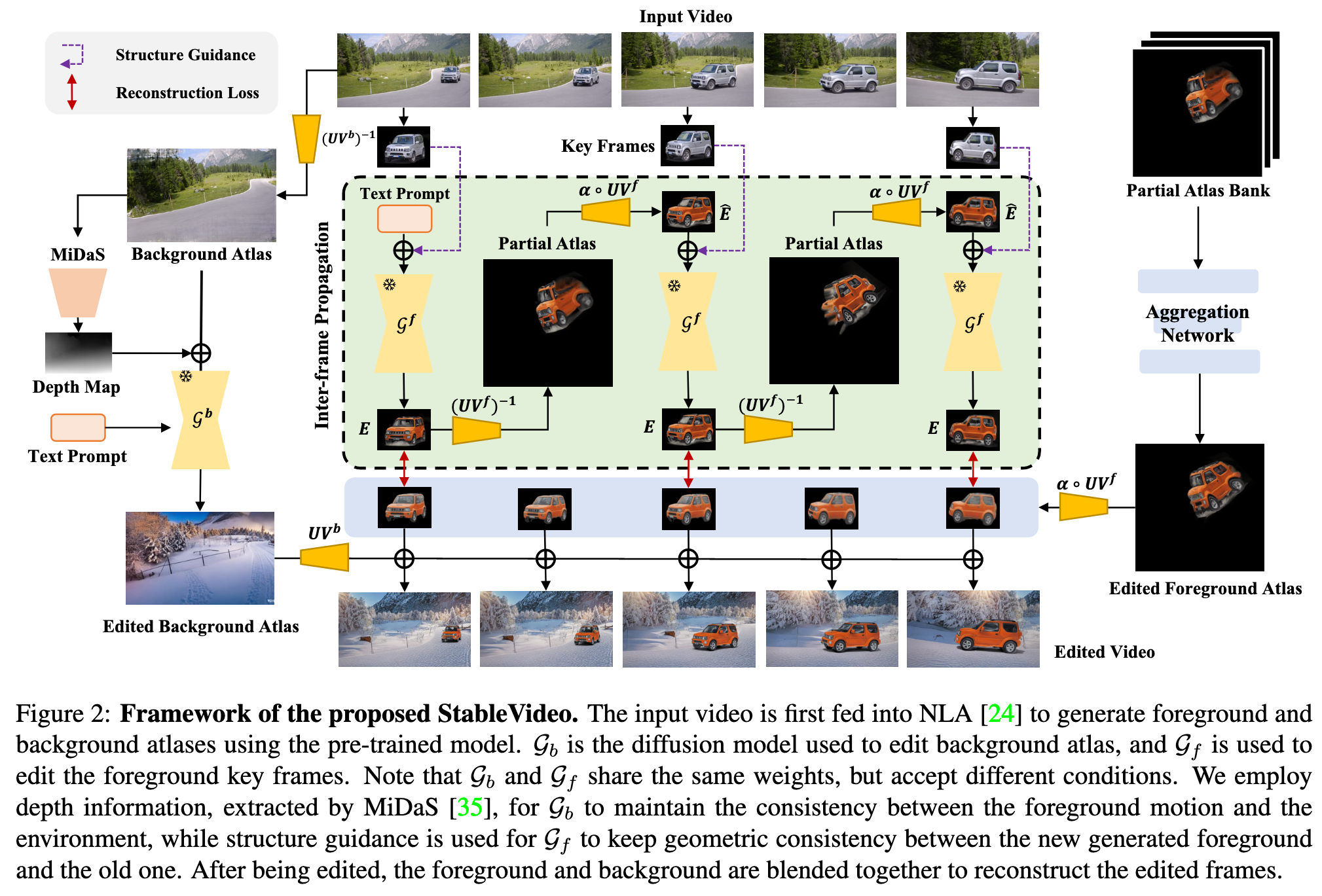
For foreground editing, we adopt key frame editing to generate atlas layers with high quality and the inter-frame propagation module to ensure better geometric and temporal consistency. The edited key frames are then mapped to partial atlases and aggregated by the aggregation network to produce the edited foreground atlas
Problem Formulation
The concept of NLA is to decompose the input video into layered representations, namely foreground atlas and background atlas, which glob- ally summarize the correlated pixels for the foreground and the background, respectively. (p. 3)
Our method achieves geometrical consistent editing by fixing the mappings of $UV_b$ and $UV_f$ , and generating the edited atlases of $A_b$ and $A_f$ . We adopt a pre-trained latent diffusion model [36] with guided conditions as our generator, namely $G_b(·)$ and $G_f (·)$. (p. 4)
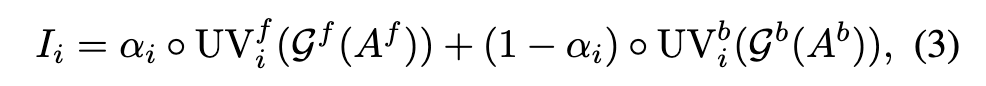
Inter-frame Propagation
We tackle this problem by introducing a conditional denoising process to enable the diffusion models to consider both the structure of the current frame and the appearance information from previous frame, thereby sequentially generating new objects with geometric consistency across time. In specific, we employ canny edge as structure guidance (p. 4) With the help of NLA, we can transfer the appearance features of the overlapping parts of previous frame to the next frame (p. 4)
Given a generator $G_f (·)$ and a text prompt T, we edit the first frame F0 in pixel coordinate system with its structure condition C0 as the extra guidance (p. 4) Then for the remaining key frames, we propagate the editing result from the previous key frame $E_{i−1}$ to obtain the one of the current key frame $E_i$ (p. 4)
Given the partial appearance $\hat{E}i$, we first encode it with VQ-VAE [47] to get the latent representation $\hat{Z}_i$, and then add noise to it with Variance Preserving Stochastic Differential Equation (VP-SDE) (p. 5)
Then we apply denoising process $\hat{Z}_i(t0)$ under the condition guidance from both text prompt T and structure guidance Ci to get the latent representation $Z_i$. Finally, we decode the latent representation to $Z_i$ propagate editing result Ei. (p. 5)
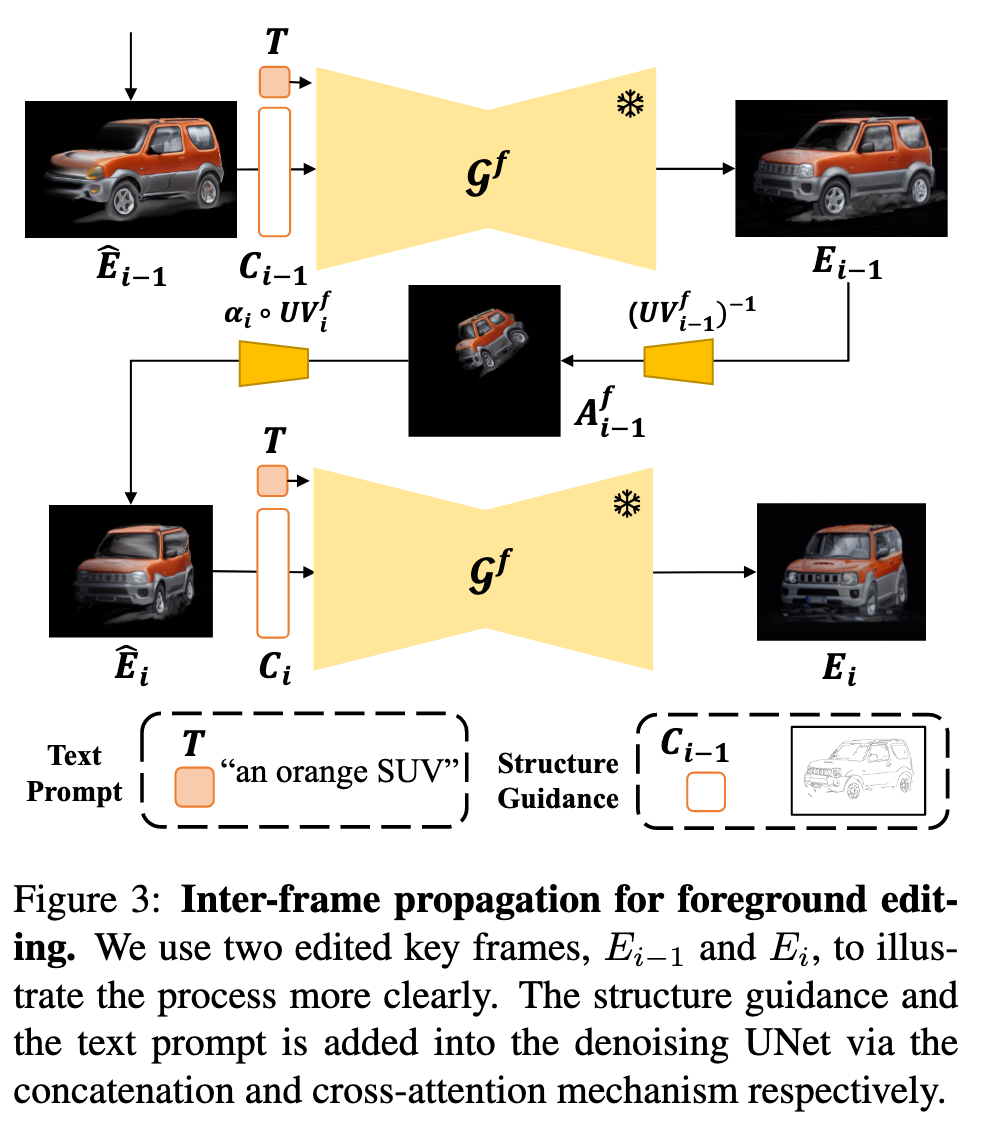
Aggregation Network
Firstly, the geometries and pixels from different viewpoints provide more details of the target objects, allowing the diffusion model to generate the edited content with higher fidelity. Secondly, this alleviates the risk of failure editing due to the potential wrong mapping from the at- las to the video frames. We then aggregate the edited key frames by using a simple yet effective two-layer 2D convolution network with skip connection as shown in Fig. 4. Our goal is to guarantee that the aggregated atlas is highly aligned with the original one, in terms of locations, so that appearance edit will not affect the geometric consistency and the temporal continuity. Reconstruction loss, $L_{rec}$, between the edited and reconstructed key frames is employed in the training process as (p. 5)
Ablation Study
To verify the necessity of the key frame editing, we apply editing in atlas layer directly for the foreground as a simple baseline. The atlas might not be so deformed for human perception, but it significantly affects the diffusion models.

We also conduct extensive ablation study on inter-frame propagation module. The objective of this module is to maintain the geometry of the foreground when editing key frames. Firstly, we consider four different settings for editing key frames as shown in Fig. 11.
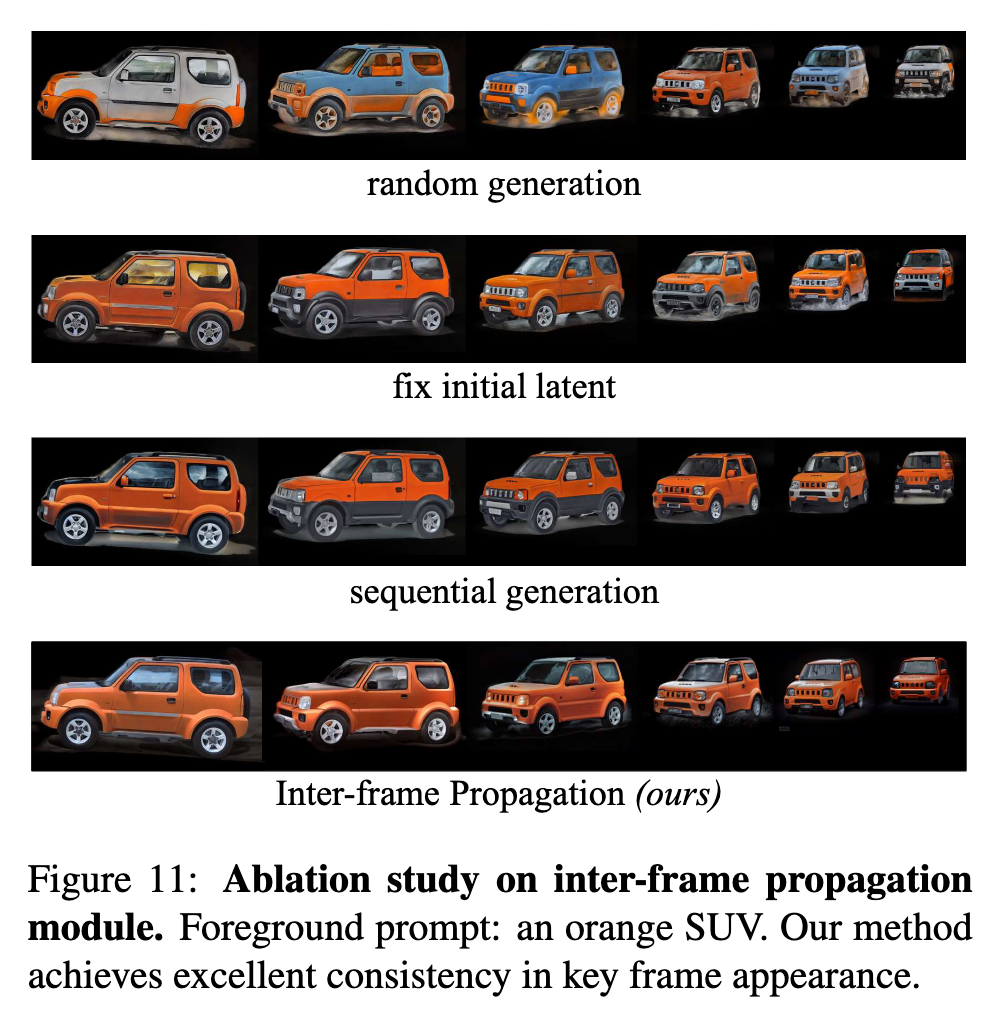
- Random generation. Each key frame only shares the sametext prompt with the others. In this case, there are significant differences among the generated key frames.
- Fix initial latent. Unlike starting from random noise every time we edit, we start generating each key frame from the same latent noise and share the text prompt. In this case, there is higher similarity in the content generated for each frame, but the consistency is still not satisfactory.
- Sequential generation. Furthermore, we concatenate the latent noise between frames. Specifically, we apply image to-image translation between frames. This method still cannot guarantee consistency since the appearances of the objects between the two frames do not match.
- Inter-frame propagation (ours). Our final approach is to employ partial atlas to geometrically align the appearances between two frames, followed by a process of adding noise and then apply denoising process.
Limitations and Future Works
Firstly, our method is constrained by NLA. Learning atlas layers may fail for non-rigid objects with significant structural deformation as shown in Fig. 13. While we can mitigate this by dividing long videos into short clips where the objects can be considered to be rigid, it is still not feasible to address every single case. Secondly, our method is constrained by the capabilities of the diffusion models, which may struggle with specific scenarios such as human or animals. Besides, it may be better to optimize the diffusion model with the objective of aligning the generated contents to the reconstructed ones.
