Subject-Diffusion Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
[imagen mix-of-show personalize instructpix2pix dreambooth elite lora fast-composer diffusion segment-anything deep-learning instant-booth text2image taming-encoder blip-diffusion clip blip cones glide dall-e2 umm-diffusion stable-diffusion ediffi This is my reading note for Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning. This paper propose a diffusion method to generate images with given visual concepts and text prompt. Especially the paper is able to hand multiple visual concert jointly. To handle that, the paper detect the visual concepts from the input images, then the segmented images and bounding box are encoded feed into latent diffusion model. To enhance the consistency, the visual embedding is inserted into the text encode of the prompt.

Introduction
LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. We design a new unified framework that combines text and image semantics by incorporating coarse location and fine- grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi- subject generation. (p. 1)
Another technique roadmap [63, 61, 11, 12] is to re-train the text-to-image generation base model by specially-designed network structures or training strategies on a large-scale personalized image dataset, but often resulting in inferior fidelity and generalization as compared with test-time fine- tuning approaches. (p. 2)
To achieve controllable personalized image generation in open domains, we propose a novel frame- work that comprises three distinct parts. The first part involves incorporating location control by concatenating the mask images of the main subjects during the noise injection process. The second part involves fine-grained reference image control, where we design a combined text-image informa- tion module to better integrate the two information granularities. We append the image representation to the text embedding using a specific prompt style and perform feature fusion within the text encoder. Additionally, we add adapter modules to the UNet to specifically receive personalized image informa- tion, thereby increasing the fidelity of personalized images. For the third part, to further control the generation of multiple subjects, we introduce attention control during training. (p. 3)
Related Work
Text-to-Image Generation
Stable diffusion [47], ERNIE-ViLG2.0 [15] and ediffi [4] propose to employ cross-attention mechanism to inject textual condition into the diffusion generation process. (p. 3)
Subject-driven Text-to-Image Generation
Another group of solutions only fine-tunes the token embedding of the subject to adapt to learning visual concepts. DreamBooth [49] fine-tunes the entire UNet network, while Custom Diffusion [31] only fine-tunes the K and V layers of the cross-attention in the UNet network. The LoRA [27] model is further used to efficiently adjust the fine-tuning parameters (p. 3)
For multiple personalized subject generation, the concept neurons of multiple trained personalized models are directly concatenated. Mix-of-Show [18] trains a separate LoRA model for each subject and then performs fusion. Cones 2 [38] generates multi-subject combination images by learning the residual of token embedding and controlling the attention map. (p. 4)
InstructPix2Pix simply concatenating the latent of the reference images during the model’s noise injection process. (p. 4)
UMM-Diffusion presents a novel Unified Multi-Modal Latent Diffusion [40] that takes joint texts and images containing specified subjects as input sequences and generates customized images with the subjects. (p. 4)
Build the Dataset
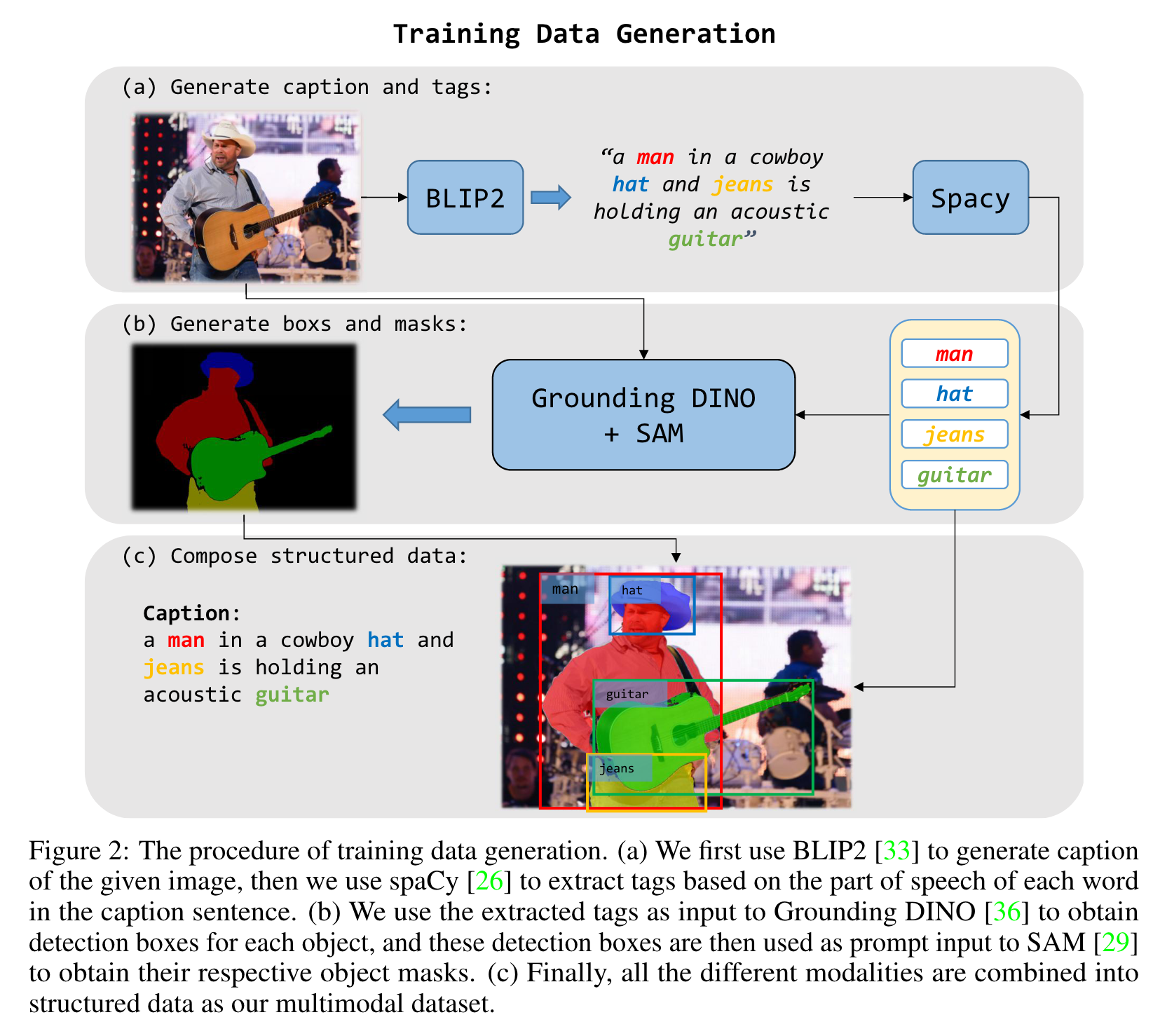
It consists of a variety of different modalities, including image-text pairs, instance detection boxes, segmentation masks, and corresponding labels. (p. 4)
By using BLIP-2, we can generate more precise captions for each image. In order to accomplish this, we perform part-of-speech analysis on the generated captions and treat the nouns as entity tags. Once we have obtained the entity labels, we can use the open-set detection model Grounding DINO [36] to detect the corresponding location of the entity and use the detection box as a cue for the segmentation model SAM [29] to determine the corresponding mask. (p. 5)
Proposed Method
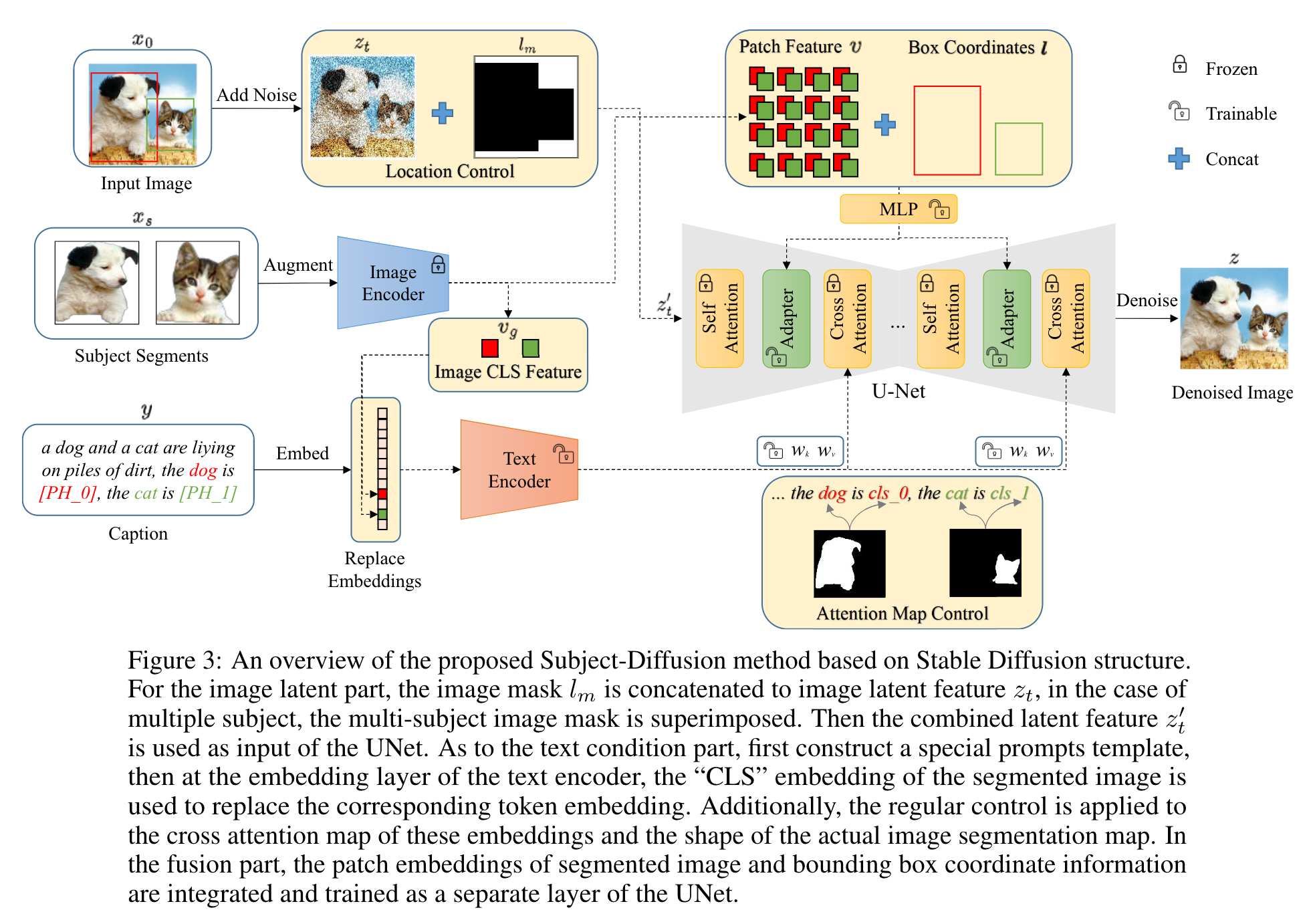
The first component entails effectively integrating segmented reference image information through specially constructed prompts. This is achieved by learning the weights of the blended text encoder to simultaneously enhance both prompt generalization and image fidelity. For the second component, a new layer for learning is added to the UNet, which receives patch embedding of the segmented image and corresponding position coordinate information. The third part introduces additional control learning of the cross-attention map to support multi-subject learning. (p. 6)
Exploitation of Auxiliary Information
Location control
A binary mask feature map is generated and concatenated to the original image latent feature for a single subject. For multiple subjects, we overlay the binary images of each subject and then concatenate them onto the latent feature (p. 7)
Dense image control
To address this challenge, we propose to incorporate dense image features as an important input condition, similar to the textual input condition. To ensure that the model focuses solely on the subject information of the image and disregards the background information, we feed the segmented subject image into the CLIP [44] image encoder to obtain 256-length patch feature tokens. Furthermore, to prevent confusion when generating multiple subjects, we fuse the corresponding image embedding with the Fourier-transformed coordinate position information of the subject (p. 7)
we introduce a new learnable adapter layer between the self-attention layer and the cross-attention layer, which takes the fused information as input and is defined as follows: (p. 7)
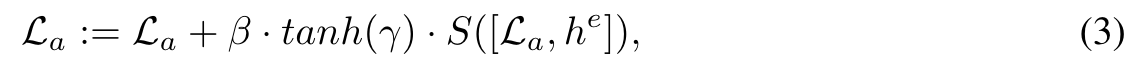
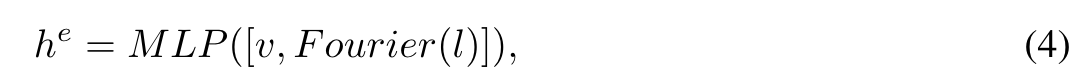
where M LP (·, ·) is a multi-layer perceptron that first concatenates the two inputs across the feature dimension: v the visual 256 patch feature tokens of an image, and l the coordinate position information of the subject. (p. 7)
Fusion text encoder
We conduct extensive experiments, showing that fusing text and image information before the text encoder and then retraining the entire text encoder has stronger self-consistency than fusing them later. Specifically, we replace the entity token embedding at the first embedding layer of the text encoder with the image subject “CLS” embedding at the corresponding position, and then retrain the entire text encoder. (p. 7)
Cross attention map control
One direct approach is to modify the region of the cross- attention map based on the bounding box of the entity [62, 10, 60, 43, 46, 35, 66]. Another approach is to guide the model to refine the cross-attention units to attend to all subject tokens in the text prompt and strengthen or excite their activations [8]. The proposed approaches in this study are primarily based on the conclusions drawn from Prompt-to-Prompt [23]. The cross-attention in the text-to-image diffusion models can reflect the positions of each generated object specified by the corresponding text token (p. 8)
Therefore, we introduce an additional loss term that encourages the model not only to reconstruct the pixels associated with learned concepts but also to ensure that each token only attends to the image region occupied by the corresponding concept (p. 8)
Objective function
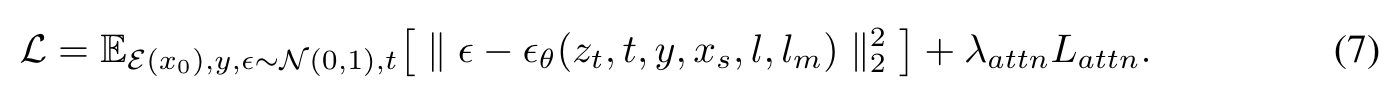
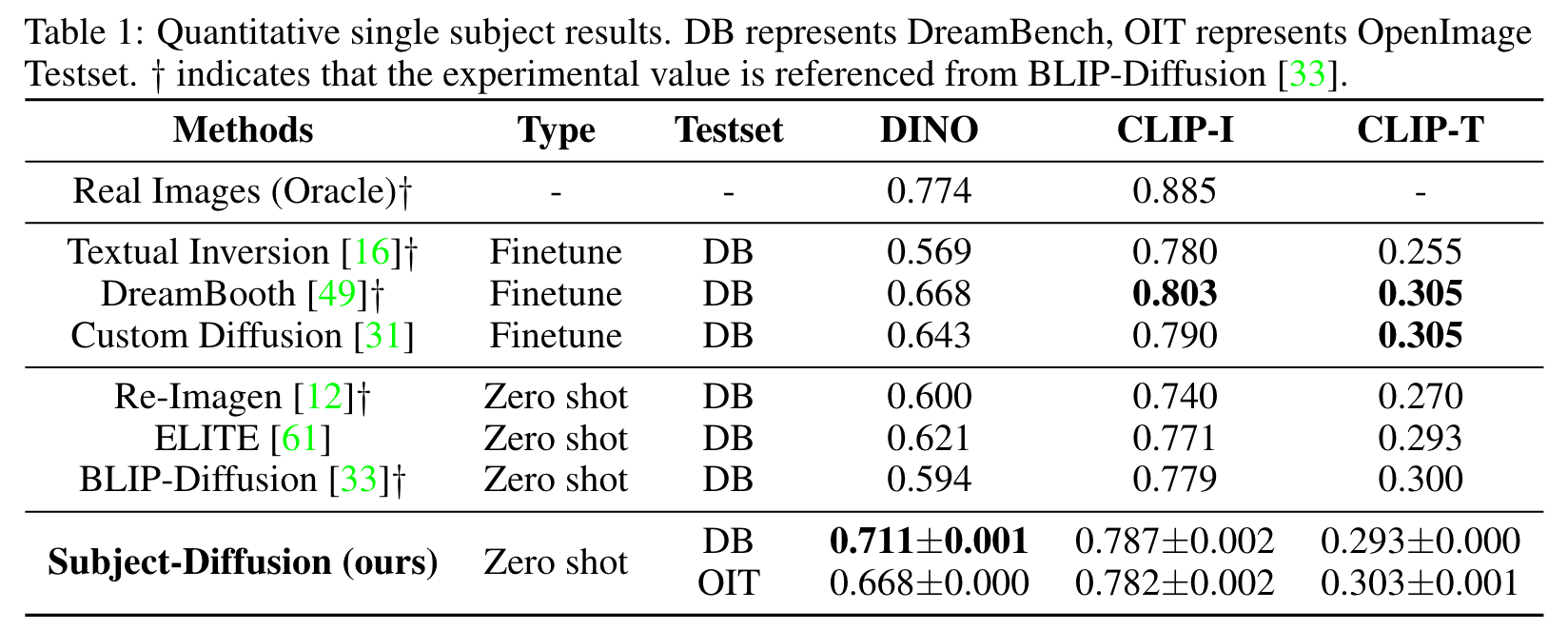
Experiments


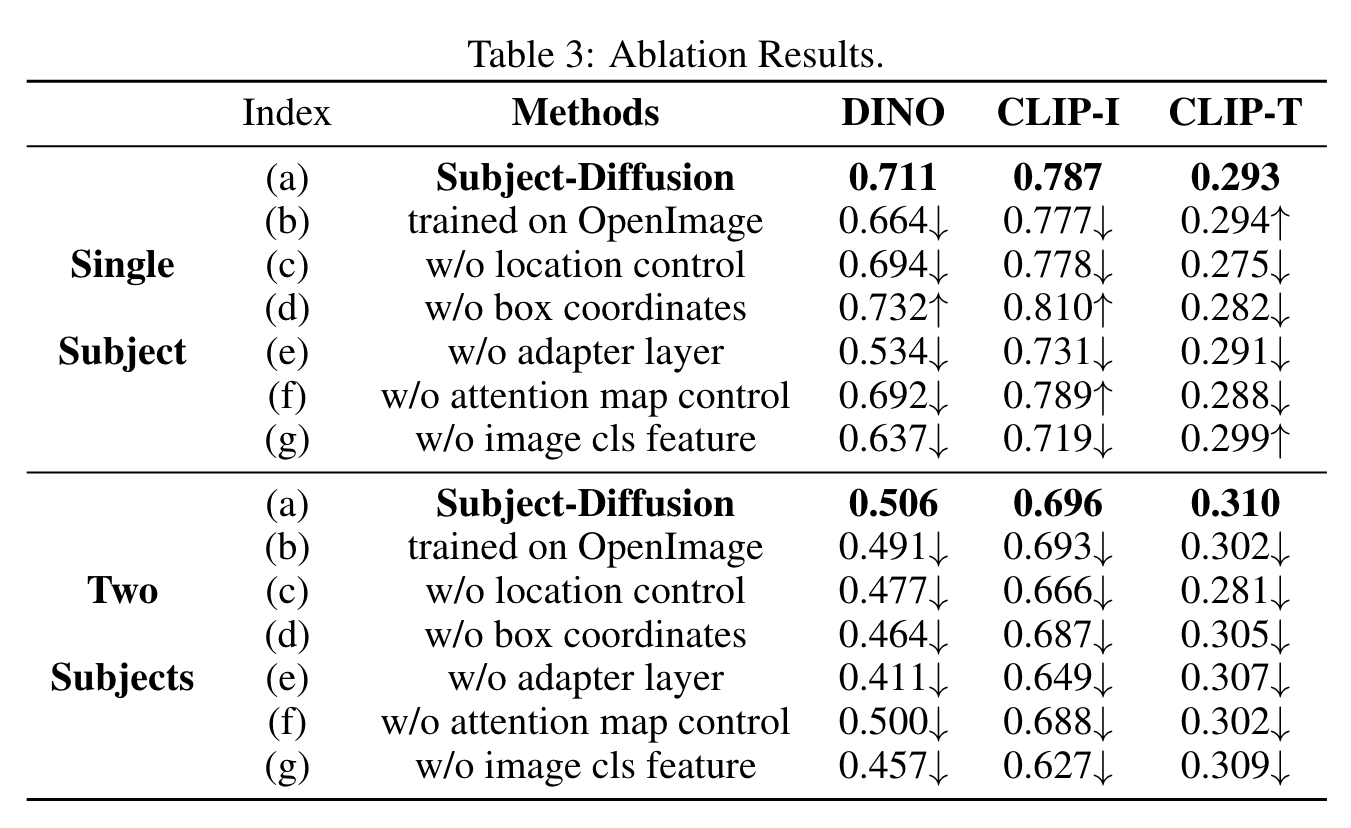
Ablation
Impact of our training data
The training data proposed in this paper consists of large-scale, richly annotated images, thereby enabling our model to effectively capture the appearance features of any given subject. To further assess the impact of training data, we retrain our model using OpenImages [32] training data, limiting the categories to only 600. Our evaluation results (a) and (b) demonstrate that this smaller dataset leads to lower image similarity, with the DINO and CLIP-I scores both decreasing for single-subject and two-subject cases, which underscores the importance of utilizing large-scale training data in generating highly personalized images. However, the results still surpass or are on par with those of ELITE and BLIP-diffusion. (p. 12)
Impact of location control
Recently, some methods [5, 39] argue that the location control on input latent also plays an important role in preserving image fidelity. Hence, we simply remove the location control from our model to discuss its impact. The comparison between experiments (a) and (c) declares that, if we remove the location control, our model would meet an apparent degeneration over all evaluation metrics. (p. 13)
Effectiveness of box coordinates
To prevent any confusion between patch features from reference images, we incorporate box coordinate information for each subject. Our results from experiments (a) and (d) indicate that the introduction of coordinate information leads to significant improvements on two-subject generation (with the DINO score increasing by 0.042, the CLIP-I score increasing by 0.09, and the CLIP-T score increasing by 0.005). However, the fidelity of single-subject generation decreased by 0.021 for the DINO score and 0.023 for the CLIP-I score. This decline may be due to the fact that, when generating a single subject, the information becomes overly redundant, making it challenging for the model to grasp the key details of the subject. (p. 13)
Effectiveness of adapter layer
The high fidelity of our model is primarily attributed to the 256 image patch features input to the adapter layer. As demonstrated in experiment (e), removing this module results in a significant drop in nearly all of the metrics. (p. 13)
Impact of attention map control
To enhance the model’s focus on semantically relevant subject regions within the cross-attention module, we incorporate the attention map control. Our experimental results (f) clearly indicate that this operation delivers a substantial performance improvement for two-subject generation as well as a slight performance improvement for single-subject generation. This difference is most likely due to the ability of the attention map control mechanism to prevent confusion between different subjects. (p. 13)
Impact of image “CLS” feature
To explore the impact of image features on the diffusion model’s cross-attention, we conduct additional experiments without the use of the image “CLS” feature and without implementing the attention map control mechanism. The results of (a), (f), and (g) indicate that the absence of the image “CLS” feature led to a significant reduction in the fidelity of the subject, highlighting the significance of the feature in representing the overall image information. Furthermore, we observe a slight increase in the CLIP-T score, indicating a trade-off between image and text obedience. (p. 13)
Limitation
Although our method is capable of zero-shot generation with any reference image in open domains and can handle multi-subject scenarios, it still has certain limitations. First, our method faces challenges in editing attributes and accessories within user-input images, leading to limitations in the scope of the model’s applicability. Secondly, when generating personalized images for more than two subjects, our model will fail to render harmonious images with a high probability. Moreover, multi-concept generation will increase the computational load slightly. In the future, we will conduct further research to address these shortcomings. (p. 15)