Swin Transformer
[cyclic-shift instance-segmentation object-detection self-attention local semantic-segmentation shifted-window deep-learning image-classification transformer window swin-transformer ViT provides the possibilities of using transformers along as a backbone for vision tasks. However, due to transformer conduct global self attention, where the relationships of a token and all other tokens are computed, its complexity grows exponentially with image resolution. This makes it inefficient for image segmentation or semantic segmentation task. To this end, twin transformer is proposed in Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, which addresses the computation issue by conducting self attention in a local window and has multi-layers for windows at different resolution.
Network Architecture
The image below described the architecture of the swin transformer:
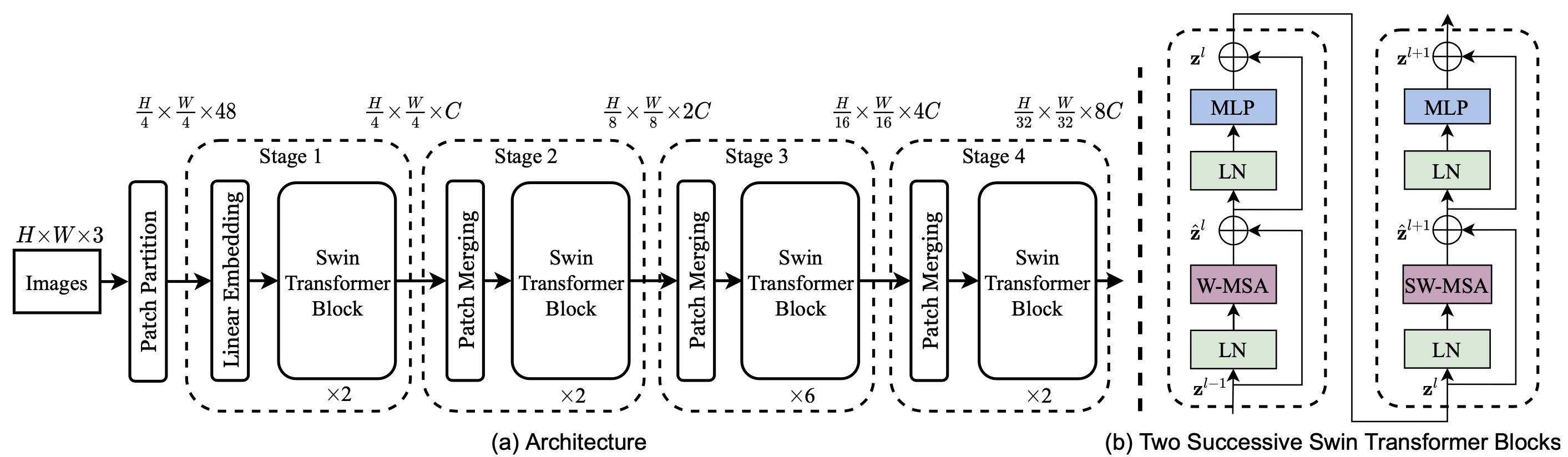
For input:
- It first splits an input RGB image into non-overlapping patches by a patch splitting module, like ViT. Each patch is treated as a “token” and its feature is set as a concatenation of the raw pixel RGB values. The paper uses \(4\times4\) patches;
- A linear embedding projects the each patch (\(1\times48\)) to a \(1\times C\) feature vector. C could be 96, 128 and 192, depends on network size.
Swin Transformer is built by replacing the standard multi-head self attention (MSA) module in a Transformer block by a module based on shifted windows. A Swin Transformer block consists of a shifted window based MSA module, followed by a 2-layer MLP with GELU non- linearity in between. A LayerNorm (LN) layer is applied before each MSA module and each MLP, and a residual connection is applied after each module.
Self Attention in Non-overlapped Windows
One of the major contributions of swin transformer is that it proposes to perform self attention in a local window instead of globally (each red box as shown below). The windows are arranged to evenly partition the image in a non-overlapping manner and each window contains \(M\times M\) patches (M=7 in the paper).
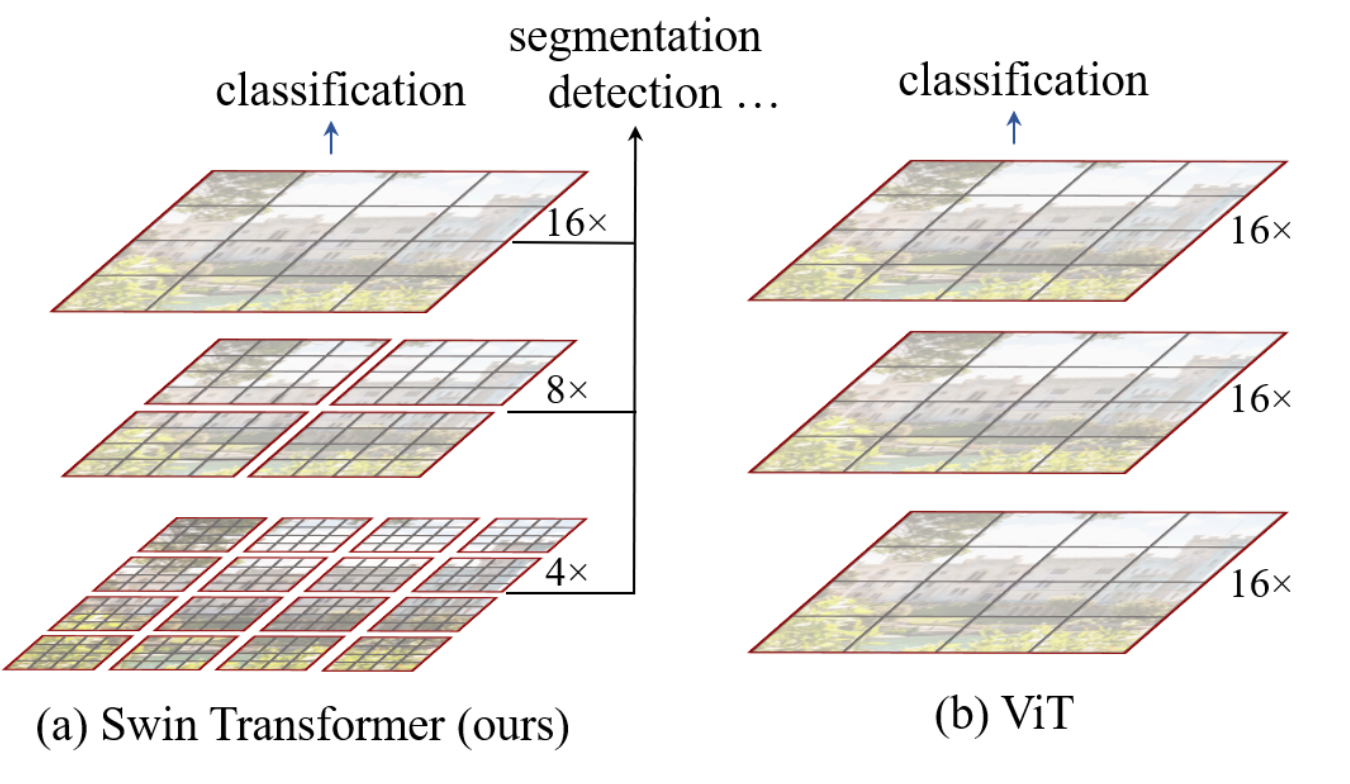
To produce a hierarchical representation, the number of tokens is reduced by patch merging layers as the network gets deeper. The first patch merging layer concatenates the features of each group of \(2\times2\) neighboring patches, and applies a linear layer on the 4C-dimensional concatenated features. This reduces the number of tokens by a multiple of \(2\times2=4\) (2× downsampling of resolution), and the output dimension is set to 2C.
Shifted Windows
The window-based self-attention module lacks connections across windows, which limits its modeling power. To intro- duce cross-window connections while maintaining the effi- cient computation of non-overlapping windows, we propose a shifted window partitioning approach which alternates be- tween two partitioning configurations in consecutive Swin Transformer blocks.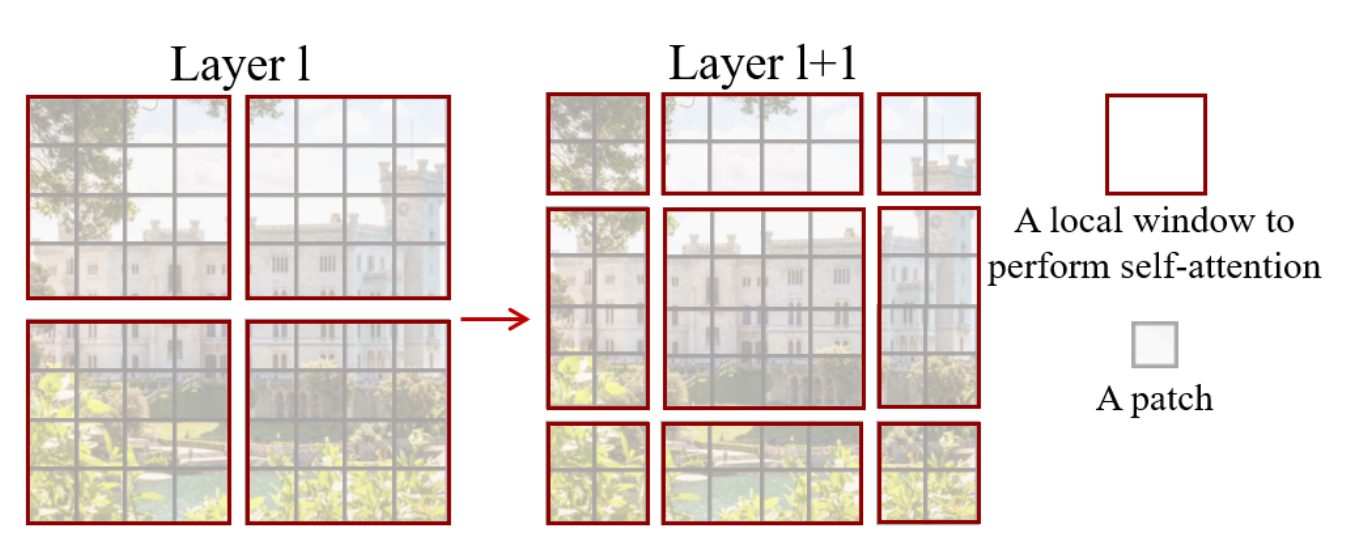
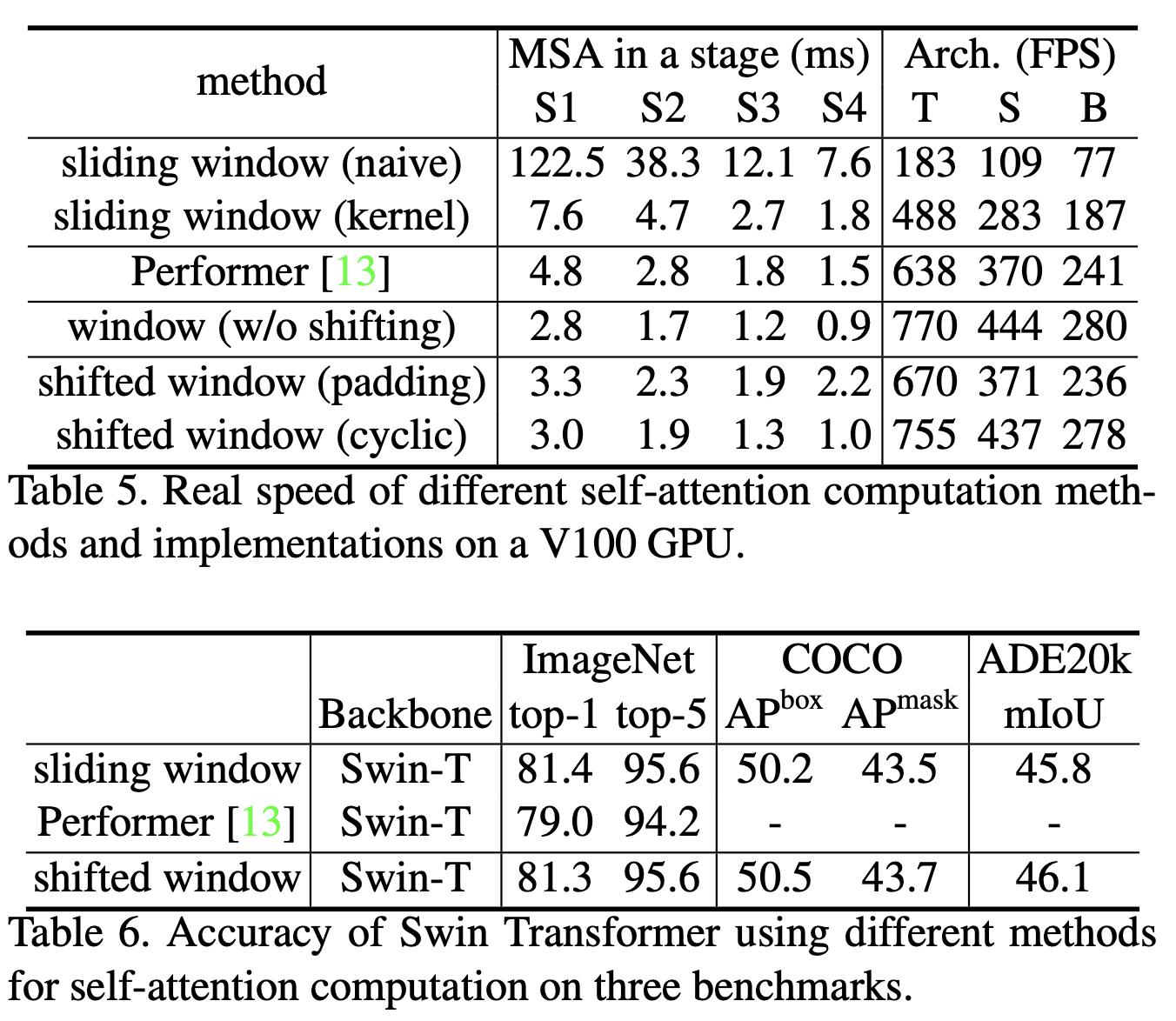
To handle the window at the boundary of image, cyclic shift is used. With the cyclic-shift, the number of batched windows re- mains the same as that of regular window partitioning, and thus is also efficient. It is found to be more efficient and accurate than sliding window method or padding window method.
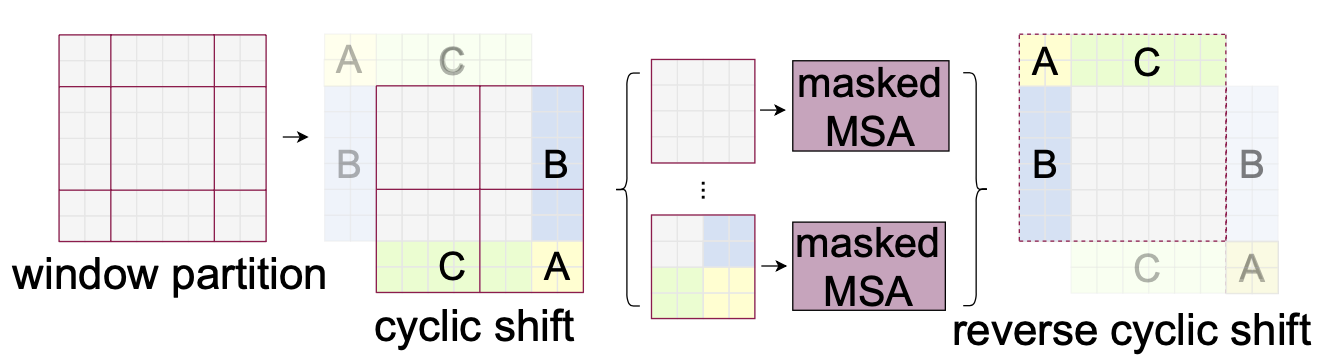
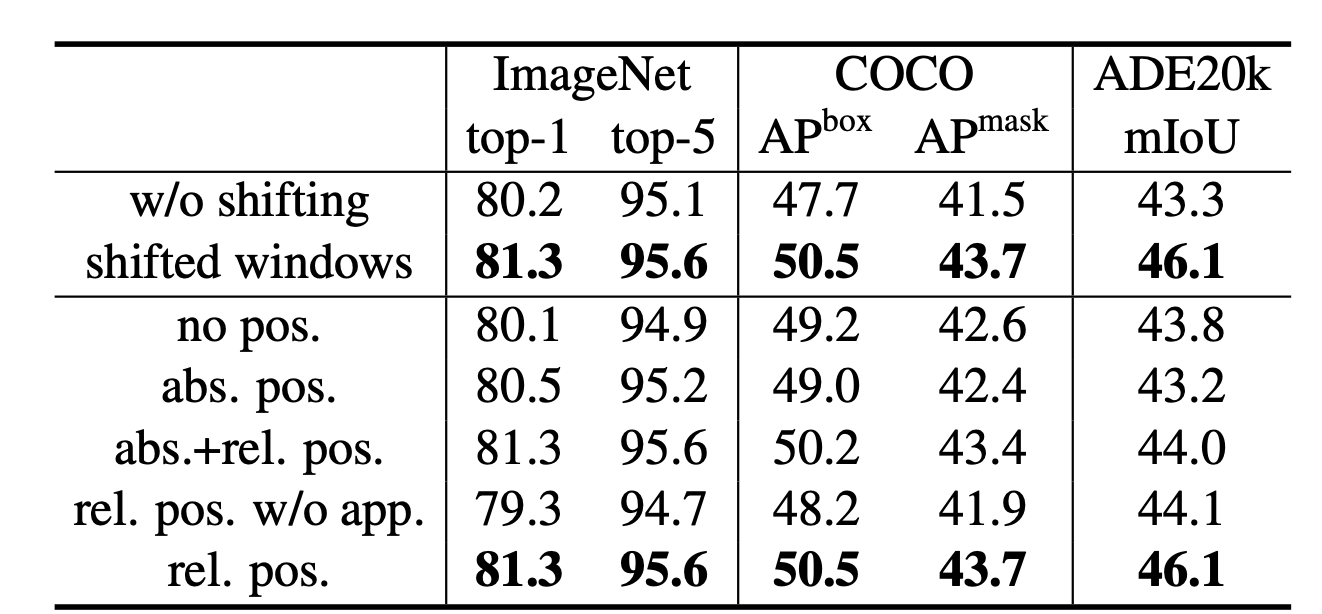
Table below compares the performance of with and without shifted window, which obviously shows the benefits:
Relative Position Bias
A relative position bias \(B\in\mathbb{R}^{M^2\times M^2}\) is included to each head in computing the similarility for self attention:
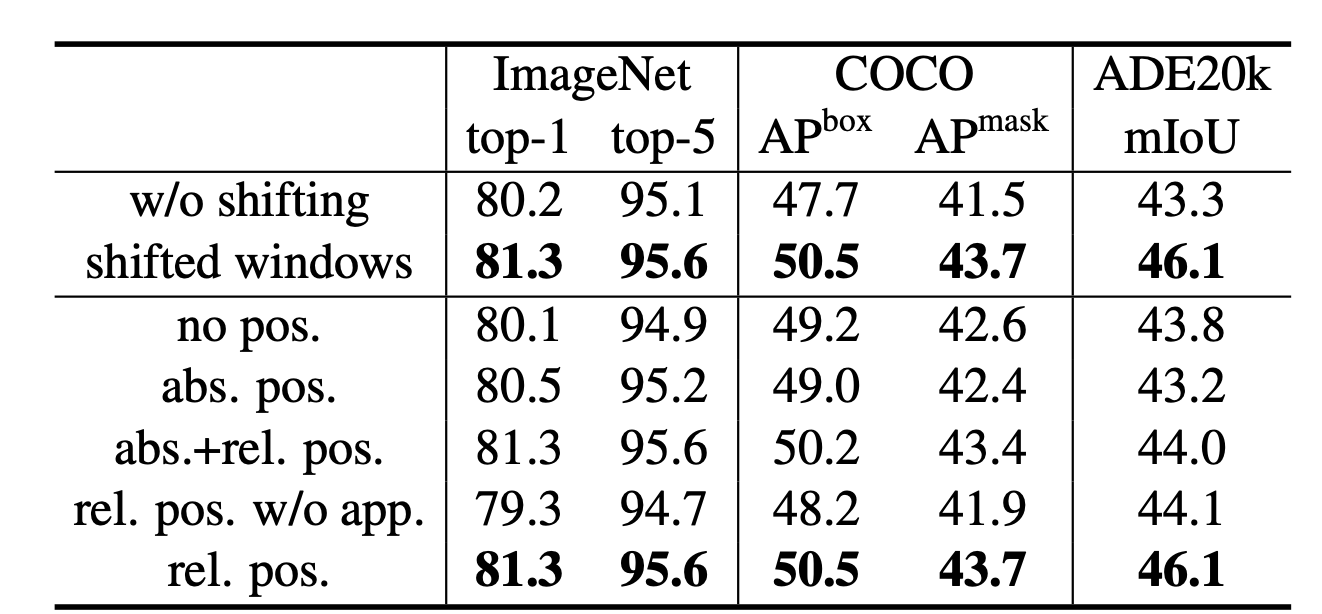
\[Attention(Q,K,V)=SoftMax(\frac{QK^T}{\sqrt(d)+B})\]d is the query (Q) and key (K) dimension. B is learned from data. The experiment shows relative position bias is important to the final performance, and outperform absolute/global position embedding, which is shown in the table below.
Experiment Result
Generally it is found that swin transformer has similar performance (accuracy and speed) as efficient net on image classification task on ImageNet. However, swin transformer obviously outperforms other methods on object detection, instance segmentation and semantic segmentation method, for both accuracy and speed. I want to refer this table from paperswithcode:
| TASK | DATASET | MODEL | METRIC NAME | METRIC VALUE | GLOBAL RANK | |
|---|---|---|---|---|---|---|
| 0 | Semantic Segmentation | ADE20K | Swin-L (UperNet, ImageNet-22k pretrain) | Test Score | 62.8 | # 1 |
| 1 | Semantic Segmentation | ADE20K val | Swin-L (UperNet, ImageNet-22k pretrain) | mIoU | 53.5 | # 1 |
| 2 | Instance Segmentation | COCO minival | Swin-L (HTC++, multi scale) | mask AP | 50.4 | # 1 |
| 3 | Object Detection | COCO minival | Swin-L (HTC++) | box AP | 57.1 | # 2 |
| 4 | Instance Segmentation | COCO minival | Swin-L (HTC++) | mask AP | 49.5 | # 2 |
| 5 | Object Detection | COCO minival | Swin-L (HTC++, multi scale) | box AP | 58 | # 1 |
| 6 | Object Detection | COCO test-dev | Swin-L (HTC++, single scale) | box AP | 57.7 | # 2 |
| 7 | Instance Segmentation | COCO test-dev | Swin-L (HTC++, single scale) | mask AP | 50.2 | # 2 |
| 8 | Object Detection | COCO test-dev | Swin-L (HTC++, multi scale) | box AP | 58.7 | # 1 |
| 9 | Instance Segmentation | COCO test-dev | Swin-L (HTC++, multi scale) | mask AP | 51.1 | # 1 |
| 10 | Image Classification | ImageNet | Swin-L (384 res, ImageNet-22k pretrain) | Top 1 Accuracy | 86.4% | # 17 |
| 11 | Image Classification | ImageNet | Swin-B (384 res, ImageNet-22k pretrain) | Top 1 Accuracy | 86% | # 20 |
| 12 | Image Classification | ImageNet | Swin-B (384x384 res) | Top 1 Accuracy | 84.2% | # 37 |