Tag2Text Guiding Vision-Language Model via Image Tagging
[object-detection multimodal deep-learning tag multi-label image-captioning contrast-loss image-text-matching vit swin-transformer tag2text blip blip2 lemon simvlm villa albef align flava This is my reading note for Tag2Text: Guiding Vision-Language Model via Image Tagging. This paper proposes to add tag recognition to vision language model and shows improved performance.

Introduction
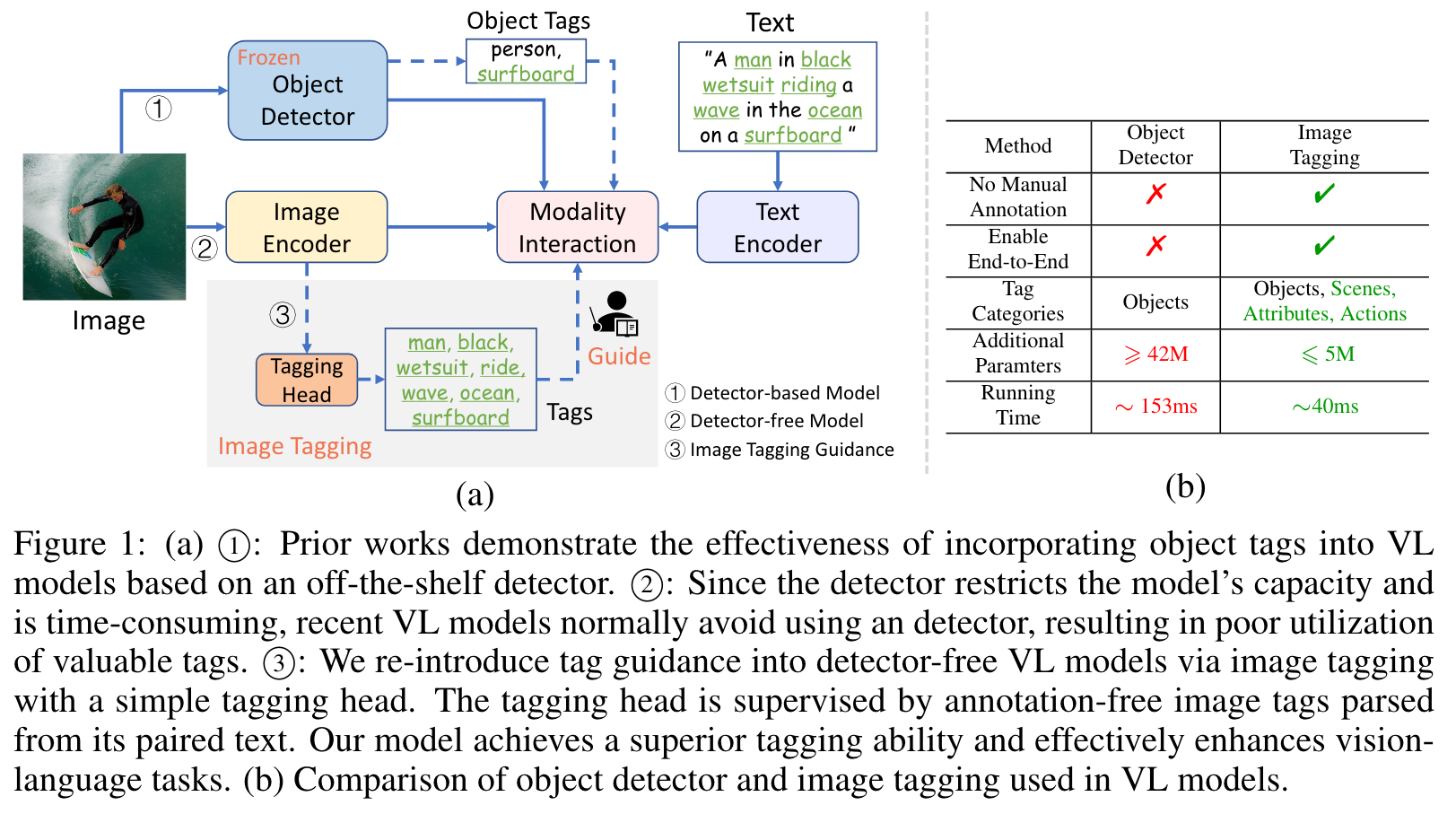
In contrast to prior works which utilize object tags either manually labeled or automatically detected with an off-the-shelf detector with limited performance, our approach explicitly learns an image tagger using tags parsed from image-paired text and thus provides a strong semantic guidance to vision-language models. Moreover, by leveraging the tagging guidance, Tag2Text effectively enhances the performance of visionlanguage models on both generation-based and alignment-based tasks. (p. 1)
Prior approaches (e.g., OSCAR (Li et al., 2020b), VIVO (Hu et al., 2021)) introduce the use of object tags as anchor points to ease the learning of semantic alignments between images and texts. However, these approaches rely on obsolete detector-based VLP frameworks, which employ off-theshelf object detectors (e.g., Faster RCNN (Ren et al., 2015)) to extract image features (as shown in Figure 1 ⃝1 ). (p. 1)
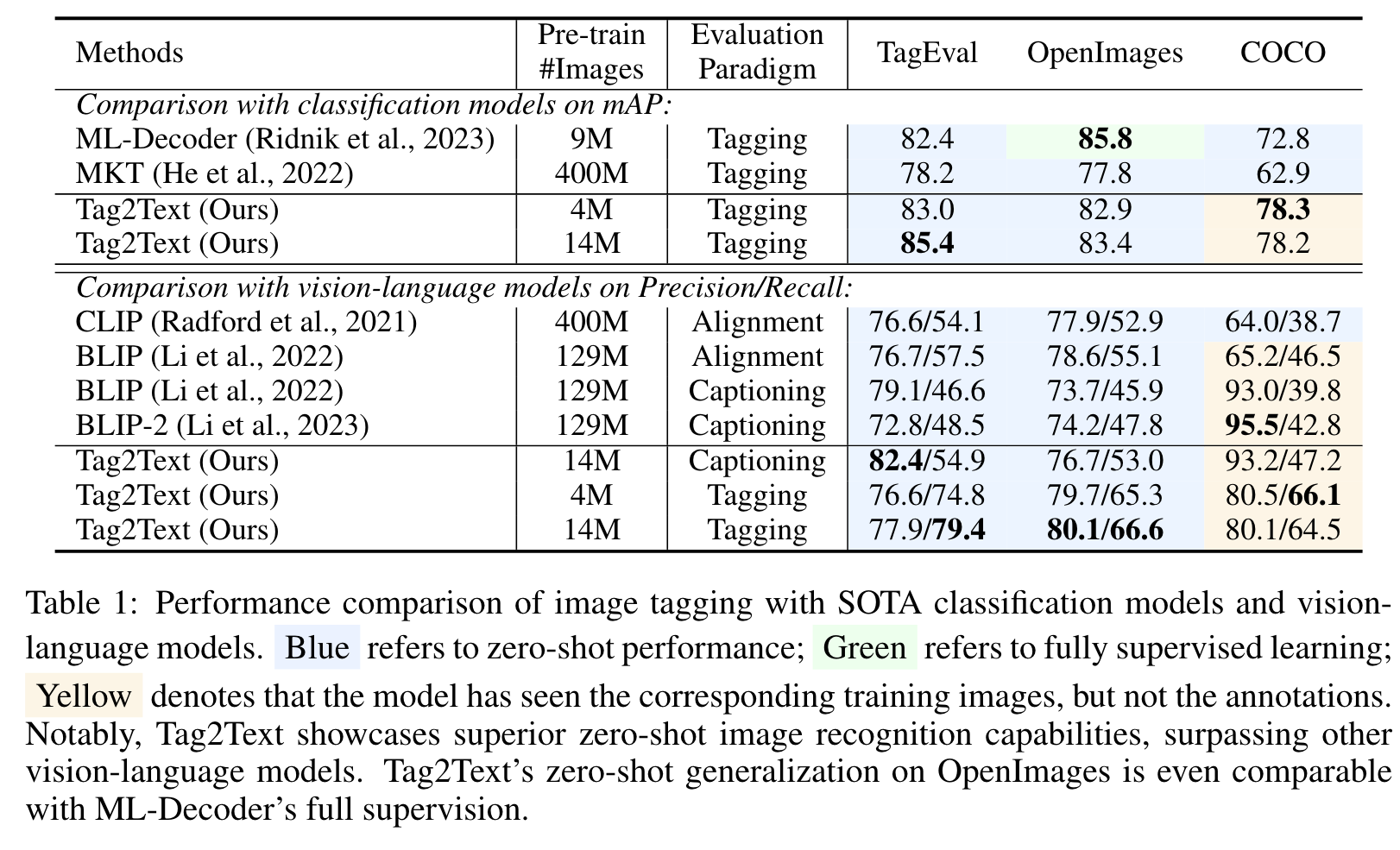
In contrast, Tag2Text utilizes largescale image-text pairs, achieving an exceptional tag recognition capability of 3,429 commonly human-used categories. Remarkably, Tag2Text demonstrates a foundational image tagging capability with superior zero-shot performance, which significantly outperforms other state-of-the-art (SOTA) vision-language models such as CLIP (Radford et al., 2021), BLIP (Li et al., 2022), and BLIP-2 (Li et al., 2023) and is even comparable to fully supervised models (Ridnik et al., 2023). (p. 2)
For generation-based tasks, we design the training task as image-tag-text generation which empowers the model to produce text descriptions based on the image features in accordance with assigned tags. (p. 2)
RELATED WORK
Vision-Language Models
The initial approach of generation-based models relies on a two-stage process of recognizing tags from an image and then using them to compose a caption (Fang et al., 2015). Such an approach endows vision-language models with the capability to generate expressive captions conditioned on visual information. IDEA (Huang et al., 2022) introduces identified tags as additional text supervision only enhancing image classification accuracy (p. 3)
Image Tagging
Traditional approaches rely on a fully connected classifier and Binary Cross-Entropy loss (BCE) for optimization. Most existing multi-label datasets (Lin et al., 2014; Everingham et al., 2015) are based on manual annotations, which are labor-intensive and difficult to scale up (p. 3)
Proposed Method
OVERVIEW FRAMEWORK
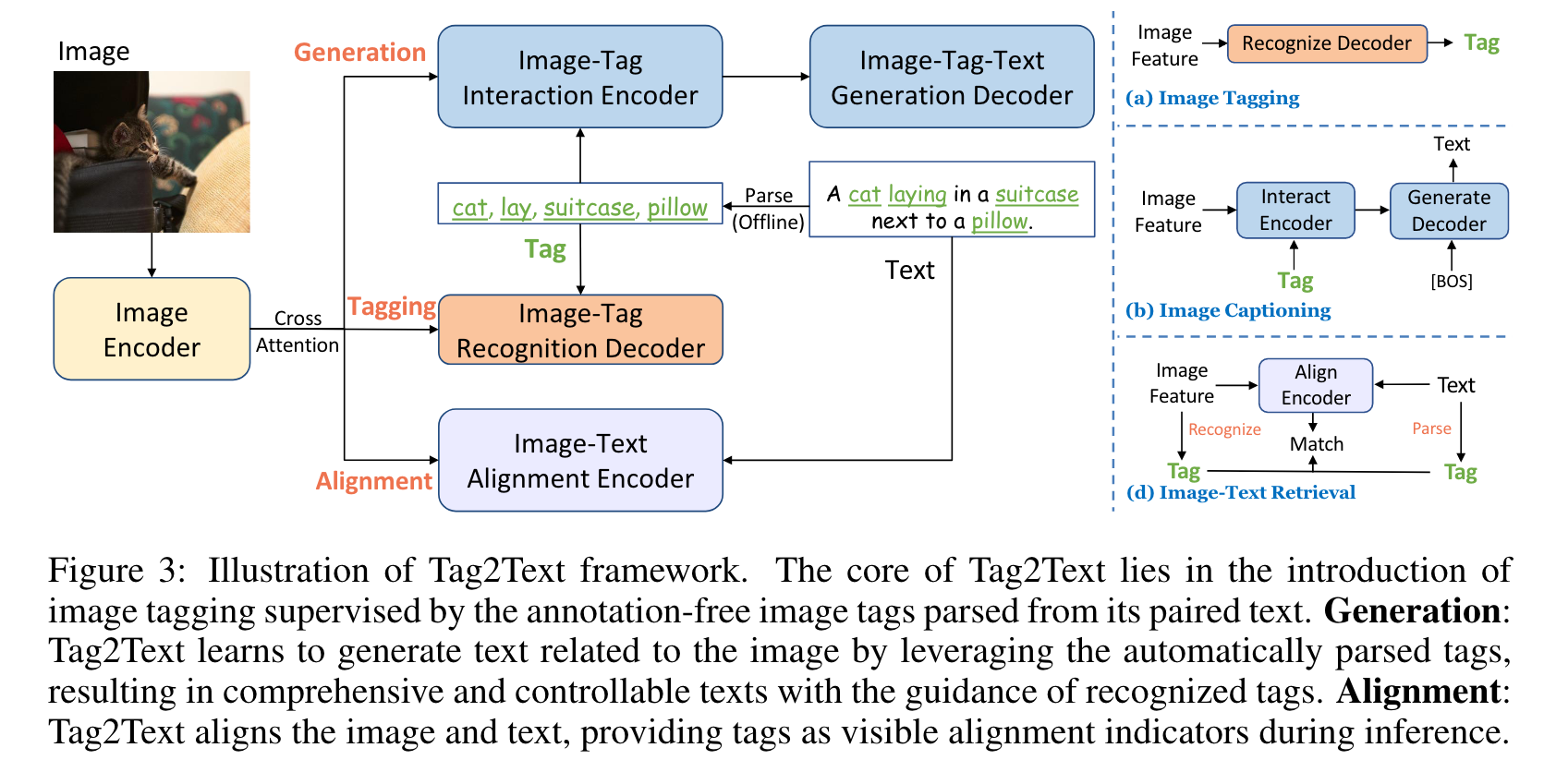
With large-scale image-text pairs, the core of Tag2Text lies in the utilization of image tags from texts. Initially, the image tags are extracted through text semantic parsing, providing a large-scale of tags without expensive manual annotations. Afterward, the parsed tags can serve as ground-truth labels for image tag recognition tasks. (p. 4)
MINING TAGS FROM TEXTS
Text Semantic Parser is adopted to parse text into image tags. The parser (Wu et al., 2019) first identifies entities (= head + modif ier) and relationships from the input sentence based on the rules of the dependency tree. Subsequently, we obtain the tags (including objects, scenes, attributes, and actions) of the image based on the contrast maps from head → object/scene, modif ier → attribute, and relationship → action.
Tag Category System Construction is based on the principle that tags with higher frequency are considered more significant since they reflect common elements in the image descriptions. By employing the semantic parser, we process 4 million open-source image-text pairs and select the 5,000 most frequently occurring tags. Further filtering by human annotation results in the selection of the most commonly human-used 3,429 categories of tags. More statistics and details are presented in Appendix B. (p. 4)
TAG2TEXT PRE-TRAINING
With triplet image-tag-text as inputs, Tag2Text employs a multi-task pre-training approach, which consists of Tagging, Generation, and Alignment. Both generation-based and alignment-based task utilize the guidance from image tagging to improve their performance. (p. 4)
Image Tagging we apply an image-tag recognition decoder (Liu et al., 2021a) to leverage visual spatial features, since tag-related visual concepts often distribute in different regions within an image (p. 5)

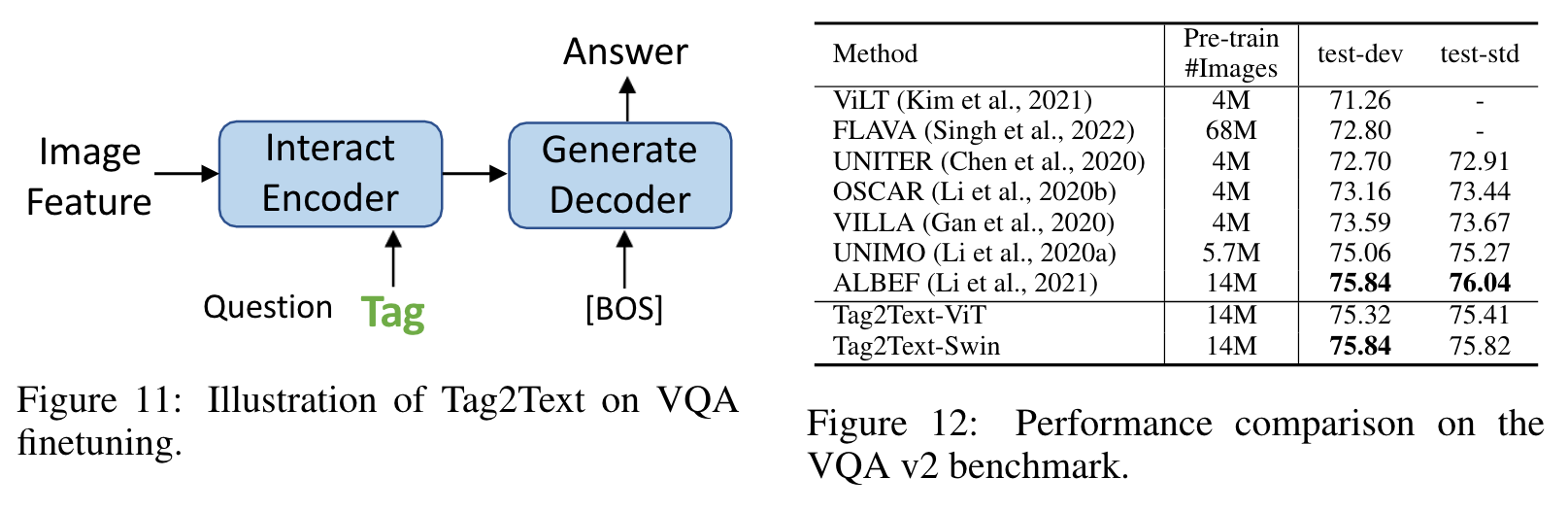
Image-Tag-Text Generation It aims to generate texts based on the image features in accordance with assigned tags. To eliminate positional bias, the image tags are rearranged prior to processing. The pre-training objective is the unidirectional Language Modeling Loss (LM) to maximize the likelihood of the text in an autoregressive manner. Our image-tag-text generation incorporates tags as a bridge to guide image features for text generation in an end-to-end manner. (p. 5)
Image-Text Alignment the text embeddings pass through the encoder and undergo coarse-grained Image-Text Contrastive Loss (ITC) with image features. Subsequently, the text embeddings undergo fine-grained Image-Text Matching Loss (ITM) with image features through cross-attention. The negative samples with higher ITC similarity will be selected for ITM with greater probability for hard mining. (p. 5)
EXPERIMENT

EXPERIMENTAL SETUP
Following Li et al. (2021; 2022), we pre-train our model on two widely used dataset settings, including a 4 million image dataset and a 14 million image dataset, respectively. We adopt two most widely used backbones pre-trained on ImageNet (Deng et al., 2009) as the image encoder: ViTBase (Dosovitskiy et al., 2021) and SwinBase (Liu et al., 2021b). (p. 6)
RESULTs
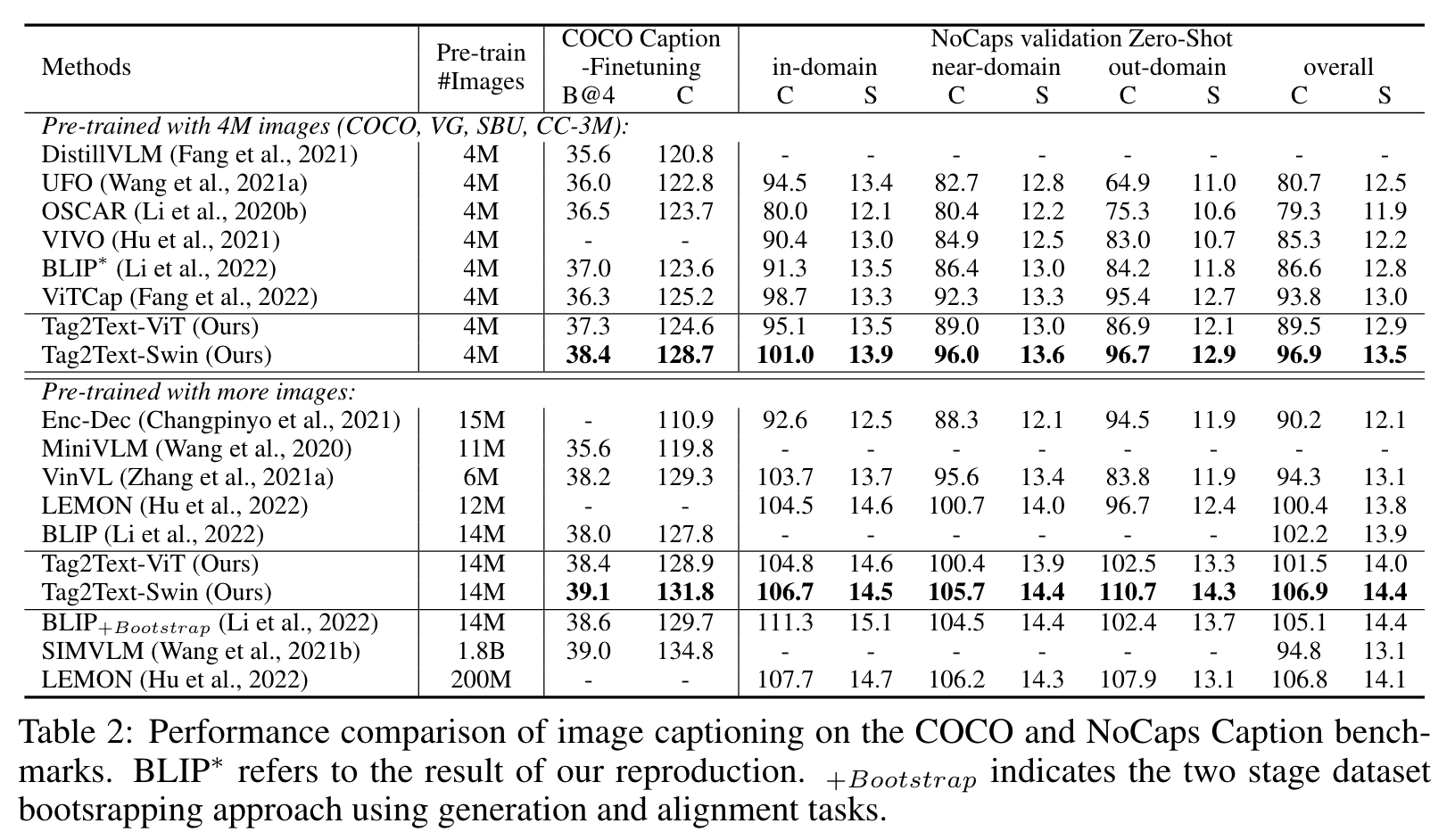
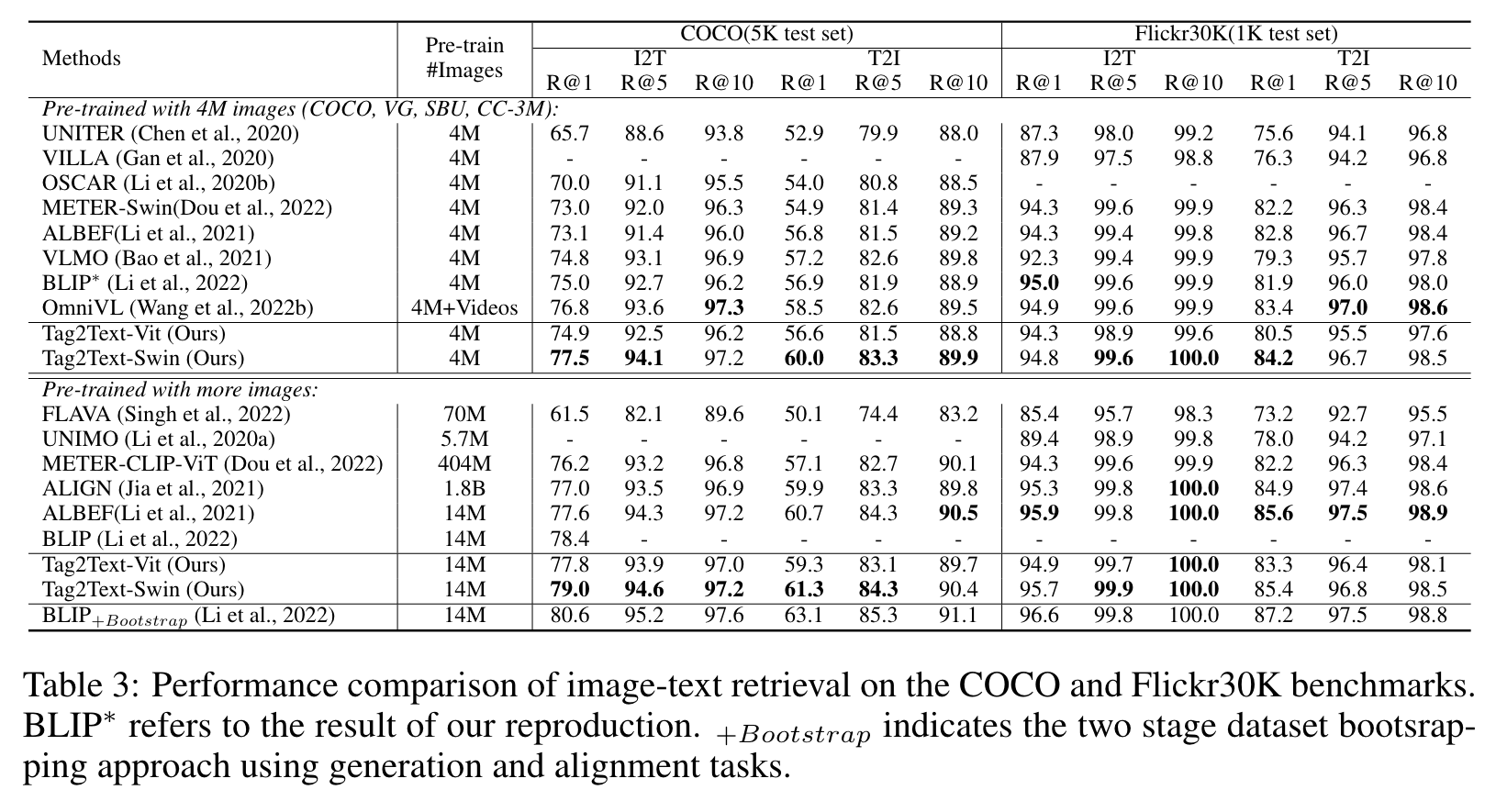
Our model is fine-tuned on the COCO training dataset using texts and tags parsed from the texts provided in COCO caption annotations, since the original COCO multi-label annotations encompass only 80 categories of tags. (p. 6)
Ablation
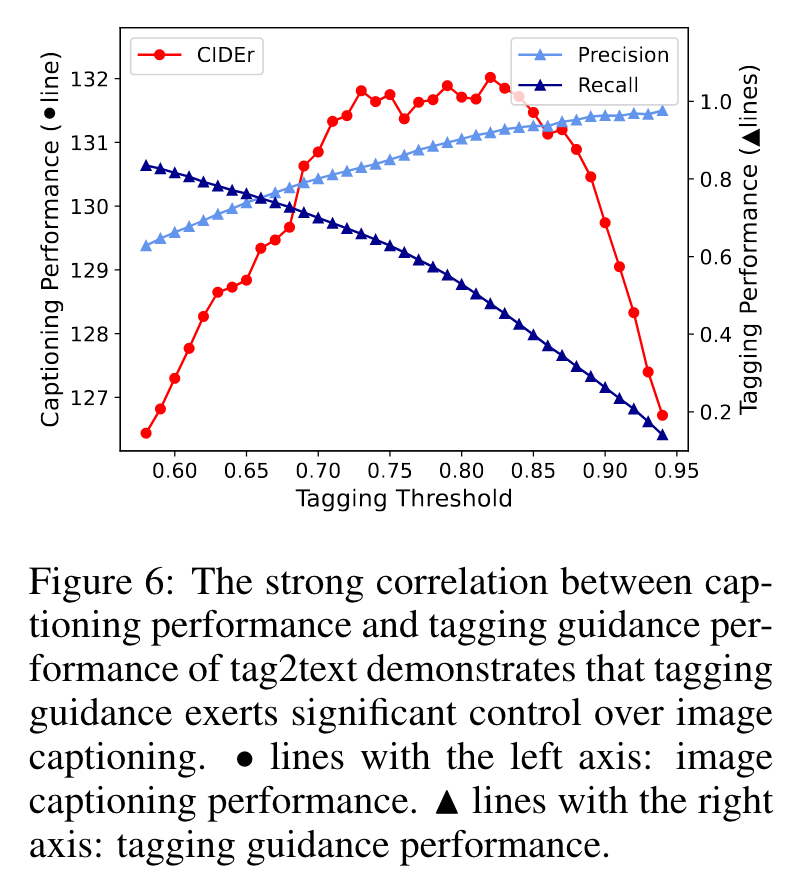
We manipulate the threshold of the tagging head to obtain tagging guidance of varying quality. As depicted in Figure 6, the captioning performance (evaluation on COCO) declines when the precision or recall of tagging (evaluation on OpenImages) is low. (p. 8)
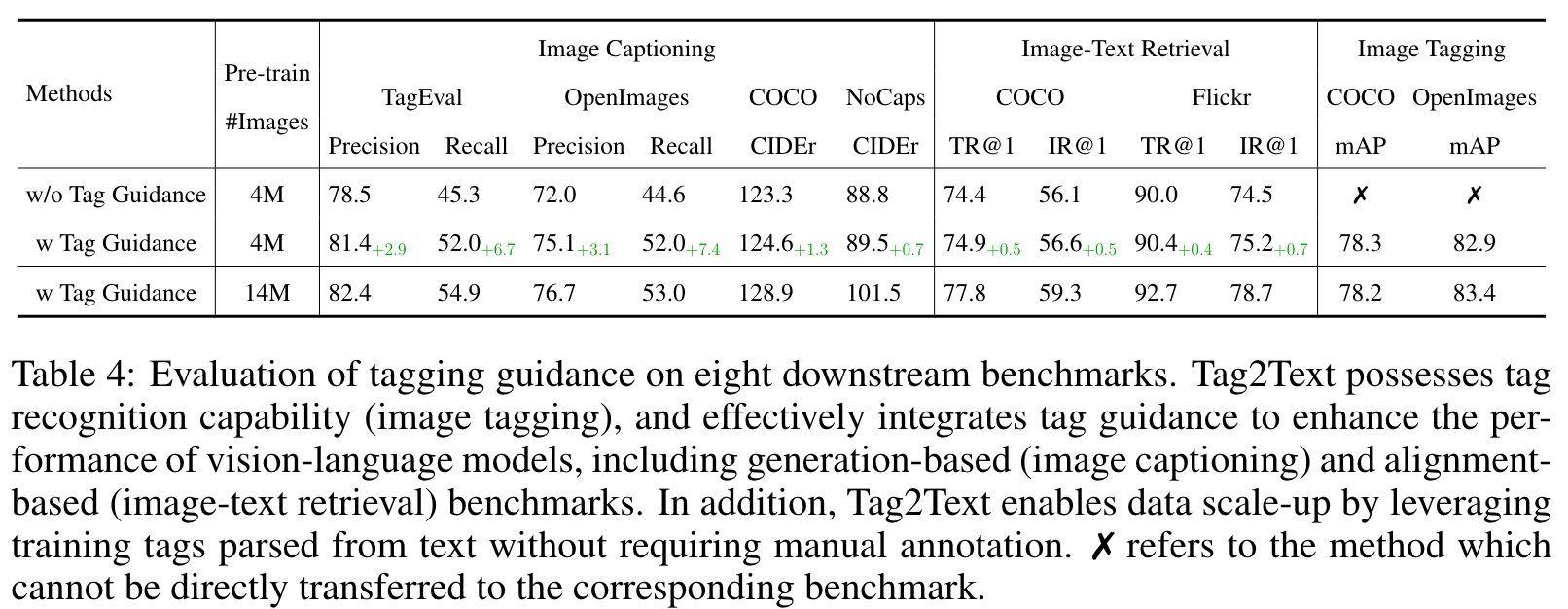


The model, trained solely on the limited COCO dataset, fails to generalize well on the OpenImages dataset, attaining an mAP score of 57.5. However, when pre-trained on a large dataset, our model exhibits remarkable performance, even in the absence of any exposure to the training images from the OpenImages dataset, achieving an mAP score of 83.4, which is comparable to the fully supervised performance of 85.8 mAP. (p. 9)