Teach LLMs to Personalize -An Approach inspired by Writing Education
[llm personalize deep-learning bad This is my reading note on Teach LLMs to Personalize -An Approach inspired by Writing Education. The paper proposes a method to generate personalized answer given a question. The method is based on finds relevant sentences from user’s previous documents given the question.
Introduction
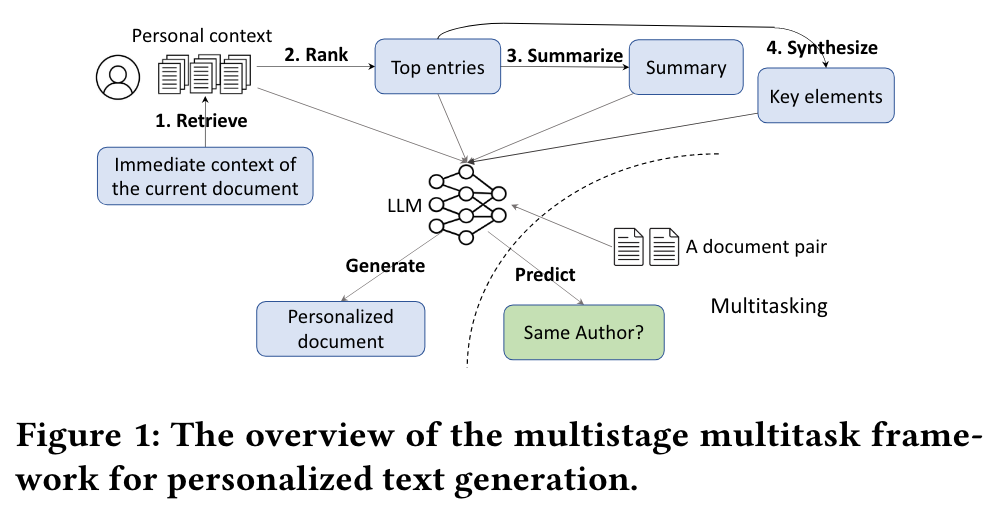
In this work, we propose a general approach for personalized text generation using large language models (LLMs). Inspired by the practice of writing education, we develop a multistage and multitask framework to teach LLMs for personalized generation. In writing instruction, the task of writing from sources is often decomposed into multiple steps that involve finding, evaluating, summarizing, synthesizing, and integrating information. Analogously, our approach to personalized text generation consists of multiple stages: retrieval, ranking, summarization, synthesis, and generation. In addition, we introduce a multitask setting that helps the model improve its generation ability further, which is inspired by the observation in education that a student’s reading proficiency and writing ability are often correlated (p. 1)
Specifically, given the immediate context, such as the title and the starting sentence of a document a user is writing, we formulate a query and retrieve relevant information from an auxiliary repository of personal contexts, such as documents the user has authored in the past. We then rank the retrieved results based on their relevance and importance, followed by summarizing the ranked results. We also synthesize the retrieved information into key elements, and finally feed the retrieved results, summary and synthesized information into the large language model for generating the new document. (p. 2)
In language education, it is often observed that the proficiency of one’s writing skills is highly correlated with that of their reading skills [4]. Furthermore, studies show that author recognition tasks can be used to measure the amount and level of reading by an individual [18], which correlates with their reading proficiency. Inspired by these two observations, we create a multitask setting that aims to improve the reading ability of the large language model, where we introduce an auxiliary task charging the model to attribute the authorship of a given text. We anticipate that this task will help the model better understand (i.e., read) the given text and in turn generate (i.e., write) better and more personalized content. (p. 2)
Related Work
Personalized text generation. Some studies focus on improving personalized generation for a particular domain by utilizing domain specific features or knowledge (p. 2)
There are investigations on using predefined attributes and topics for personalization. A personalized sentence generation method is proposed [40] based on generative adversarial networks (GANs). Frequently used function words and content words are used as input and as sentence structure constraints for model training (p. 2)
A less explored area is how to utilize large language models for personalized generation across different domains without relying on domain-specific or user-defined features. LaMP [29] is the work (p. 2)
They deploy an approach that retrieves text from user profiles. The generation tasks provided in LaMP are at the sentence-level. We instead consider generating longer text of passage-length, which is more challenging. Method-wise, the retrieval based approach in LaMP can be viewed as an instantiation of a single component of the multi-stage framework we proposed (p. 2)
Controlled text generation. Controlled text generation aims to generate text with a predefined list of attributes, which could be stylistic or semantic. To reduce the cost of finetuning, recent work of controlled text generation resorts to decoding-time methods, directly making pre-trained models generate texts towards desired attributes during inference. These methods include PPLM [5], GeDi [11], FUDGE [39], and DEXPERTS [16]. (p. 2)
Text style transfer. A task related to controlled text generation is text style transfer. Its goal is to transform a piece of text by controlling certain attributes of the generated text while preserving the content. There are two paradigms: supervised learning using parallel corpora, and unsupervised methods using non-parallel corpora. With parallel data, standard sequence-to-sequence models can be directly employed [27]. There are three approaches when only nonparallel corpora are available. The first approach is to disentangle text into content and attributes for generative modeling [33]. The second approach, called prototype editing [12], extracts a sentence template and attribute markers for generation. The third approach constructs pseudo-parallel corpora to train the model [42]. (p. 2)
PROBLEM FORMULATION
We consider the setting where a user is writing a document, which we call the current document. Given the immediate context and the user’s personal context, the goal of the personalized model is to complete the document so that the generated document is close to the real current document as if the user finishes writing. (p. 2)
For simplicity and generality, we use the title and a short start of the current document as the immediate context. The user’s personal context is defined as the documents they have written in the past at the time of writing the current document (p. 2)
Proposed Method
The personalized generation model G generates the current document 𝑑′ 𝑡 = G(𝑥𝑡, Su(𝑥𝑡, E𝑡), Sy(𝑥𝑡, E𝑡), E𝑡) and is trained against the ground-truth current document 𝑑𝑡. (p. 3)
We additionally consider an auxiliary task, called author distinction, to help the model better understand the user context and generate better personalized content. Given a document 𝑑𝑢𝑖 written by a user 𝑢, we randomly sample another document 𝑑𝑣𝑗 to form a document pair. The model G is then trained on a set of tuples {(𝑑𝑢𝑖, 𝑑𝑣𝑗), 𝑦}, where the label 𝑦 = 𝑡𝑟𝑢𝑒 if 𝑣 = 𝑢, otherwise 𝑦 = 𝑓 𝑎𝑙𝑠𝑒. Note that we use text {𝑡𝑟𝑢𝑒, 𝑓 𝑎𝑙𝑠𝑒} instead of numerical labels for 𝑦 since G is a sequence-to-sequence model. (p. 3)
PERSONALIZED TEXT GENERATION
Retrieval
BM25 [28] as the sparse retriever. We use a T5X Retrieval model [19, 21], GTR-Large, as our dense retriever. We do not choose models of larger sizes since they demonstrate similar performance but much worse effectiveness-latency trade-offs on benchmark datasets [21]. For dense retrieval, we experiment with two levels of granularity when indexing personal document entries: a document level and a snippet level. We do not choose a sentence level since many sentences are too short to offer enough context information. We create a snippet in this way: we keep appending sentences from the same document until we reach 250 characters or we reach the end of the document. (p. 3)
Rank
During analysis, we find that issues exist for both RankDocDense and RankSnippet. The retrieved results via RankDocDense can be less relevant since embeddings are less effective when the documents to encode are long. While for RankSnippet, many similar snippets are retrieved, providing insufficient information for generation (p. 3)
At the ranking stage, instead of directly ranking snippets, we rank documents that contain the retrieved snippets, to mitigate lack of diversity in snippets retrieved via RankSnippet. Specifically for each document 𝑑𝑖, we compute the embedding similarity score between each retrieved snippet 𝑠𝑖𝑗 ∈ 𝑑𝑖 and the immediate context 𝑥𝑡, and use the max score as the document score for ranking. That is, 𝑠𝑐𝑜𝑟𝑒 (𝑑𝑖, 𝑥𝑡) = max𝑠𝑖 𝑗 ∈𝑑𝑖 (𝑠𝑐𝑜𝑟𝑒 (𝑠𝑖𝑗, 𝑥𝑡)). To make all the ranking strategies comparable, we concatenate ranked entries into a string and truncate it to 2, 500 characters (p. 3)
Summary
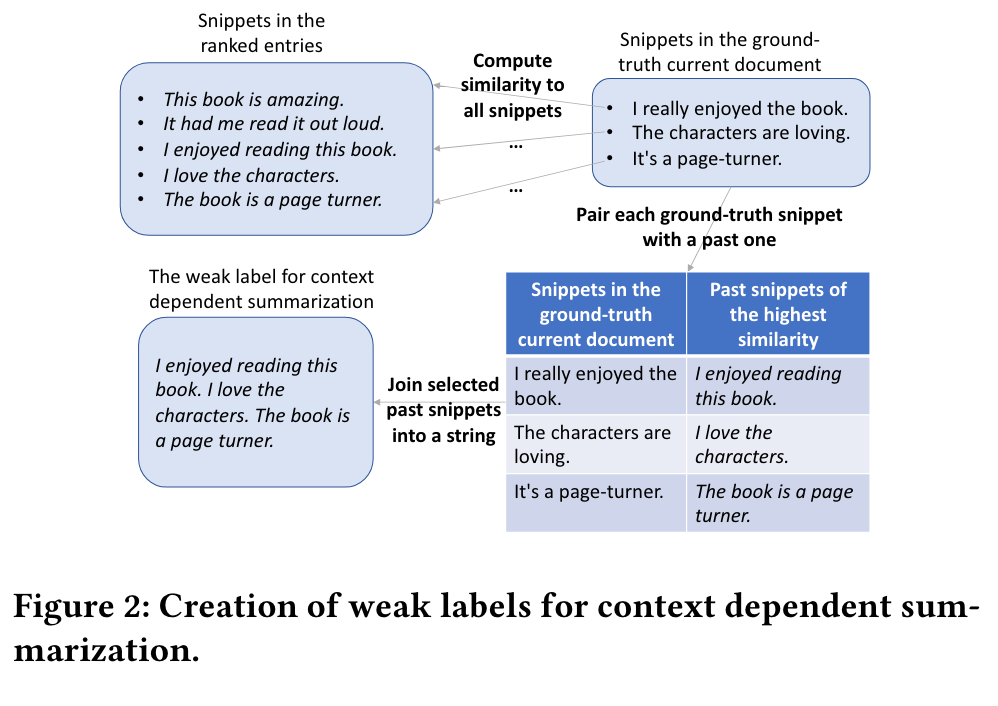
Context independent summarization. We choose a straightforward implementation of context independent summarization – we finetune an independent LLM, T5-11B [26], on publicly available summarization datasets, and directly use the finetuned model on our ranked entries for inference. (p. 4)
The weak labels are created by 𝐽𝑜𝑖𝑛(L𝑡), which joins the snippets in the candidate list into one string (p. 4)
Synthesis
The synthesis step aims to find key elements that are common in the top retrieved entries for an overall understanding of the current writing task. We experiment with extracting keywords as the synthesis step in this paper. More sophisticated approaches to synthesis are worth exploration and are left as future work. (p. 4)
- Context independent synthesis. We extract keywords by finding frequent terms from the past documents D𝑡 (p. 4)
- Context dependent synthesis. Our idea of creating weak labels for context dependent synthesis is very similar to how we create weak labels for context dependent summarization – we aim to find important words from the retrieved results that are likely to be used in the generation of the current document. (p. 4)
Personalized Generation
the personalized generation model G(𝑥𝑡, Su(𝑥𝑡, E𝑡), Sy(𝑥𝑡, E𝑡), E𝑡) is trained using the ground-truth current document 𝑑𝑡 as the label to minimize the cross-entropy loss (p. 5)
Experiment Result