TokenFlow Consistent Diffusion Features for Consistent Video Editing
[text2video tokenflow video-editing tune-a-video diffusion text2video-zero text2live deep-learning This is my reading note on TokenFlow Consistent Diffusion Features for Consistent Video Editing, which is diffusion based on video editing method. This paper proposes a method to edit a video given text prompt. To do this, the paper relies on two things. First, it extracts bey lames from video and perform image on those key frames jointly. In addition, the paper found that the feature in diffusion has strong correspondence to the pixels. As a results it propose to propagate the features of edited key frames to other frames, accord to the correspondence in the original video.
Introduction

Specifically, given a source video and a target text-prompt, our method generates a high-quality video that adheres to the target text, while preserving the spatial layout and motion of the input video. Our method is based on a key observation that consistency in the edited video can be obtained by enforcing consistency in the diffusion feature space. We achieve this by explicitly propagating diffusion features based on inter-frame correspondences, readily available in the model. Thus, our framework does not require any training or fine-tuning, and can work in conjunction with any off-the-shelf text-to-image editing method. (p. 1)
However, despite the progress made in this area, existing video models are still in their infancy, being limited in resolution, video length, or the complexity of video dynamics they can represent (p. 1)
The main challenge in leveraging an image diffusion model for video editing is to ensure that the edited content is consistent across all video frames – ideally, each physical point in the 3D world undergoes coherent modifications across time. Existing and concurrent video editing methods that are based on image diffusion models have demonstrated that global appearance coherency across the edited frames can be achieved by extending the self-attention module to include multiple frames (e.g., [53, 19, 5, 34]). Nevertheless, this approach is insufficient for achieving the desired level of temporal consistency, as motion in the video is only (p. 1)
implicitly preserved through the attention module (p. 2)
That is, the level of redundancy and temporal consistency of the frames in the RGB space and in the diffusion feature space are tightly correlated. Based on this observation, the pillar of our approach is to achieve consistent edit by ensuring that the features of the edited video are consistent across frames. Specifically, we enforce that the edited features convey the same inter-frame correspondences and redundancy as the original video features. To do so, we leverage the original inter-frame feature correspondences, which are readily available by the model. This leads to an effective method that directly propagates the edited diffusion features based on the original video dynamics. This approach allows us to harness the generative prior of state-of-the-art image diffusion model without additional training or fine-tuning, and can work in conjunction with an off-the-shelf diffusion-based image editing method (p. 2)
Relation Work
Text to image diffusion models have been extended for text-to-video generation, by extending 2D architectures to the temporal dimension (e.g., using temporal attention [15]) and performing large-scale training on video datasets [13, 46]. Recently, Gen-1 [10] tailored a diffusion model architecture for the (p. 2) task of video editing, by conditioning the network on structure/appearance representations. Nevertheless, due to their extensive computation and memory requirements, existing video diffusion models are still in infancy and are largely restricted to short clips, or exhibit lower visual quality compared to image models. On the other side of the spectrum, a promising recent trend of works leverage a pre-trained image diffusion model for video synthesis tasks, without additional training (p. 2)
A common approach for video stylization involves applying image editing techniques (e.g., style transfer) on a frame-by-frame basis, followed by post-processing to address temporal inconsistencies in the resulting video [21, 25, 24]. Although these methods effectively reduce high-frequency temporal flickering, they are not designed to handle frames that exhibit substantial variations in content, which often occur when applying text-based image editing techniques [34]. Kasten et al. [18] propose to decompose a video into a set of 2D atlases, each provides a unified representation of the background or of a foreground object throughout the video. Edits applied to the 2D atlases are automatically mapped back to the video, thus achieving temporal consistency with minimal effort. However, this method is limited in representation capabilities and requires long training, both limiting the applicability of this technique. Our work is also related to classical works that demonstrated that small patches in a natural video extensively repeat across frames [43, 7], and thus consistent editing can by simplified by editing a subset of keyframes and propagating the edit across the video by establishing patch correspondences (p. 2)
Nevertheless, such propagation methods struggle to handle videos with illumination changes, or with complex dynamics, and can only function as post-processing (p. 2)
Prompt-to-Prompt [12] observed that by manipulating the cross-attention layers, it is possible to control the relation between the spatial layout of the image to each word in the text. Plug-and(p. 2). Play Diffusion (PnP) [51] analyzed the spatial features and the self-attention maps and found that they capture semantic information at high spatial granularity. Tune-A-Video [53] observed that by extending the self-attention module to operate on more then a single frame, it is possible to generate frames that share a common global appearance. Concurrent works [34, 5, 20, 45, 26] leverage this property to achieve globally-coherent video edits. Nevertheless, as demonstrated in Sec. 5, inflating the self-attention module is insufficient for achieving fine-grained temporal consistency. Prior and concurrent works either compromise visual quality, or exhibit limited temporal consistency. (p. 3)
Proposed Method
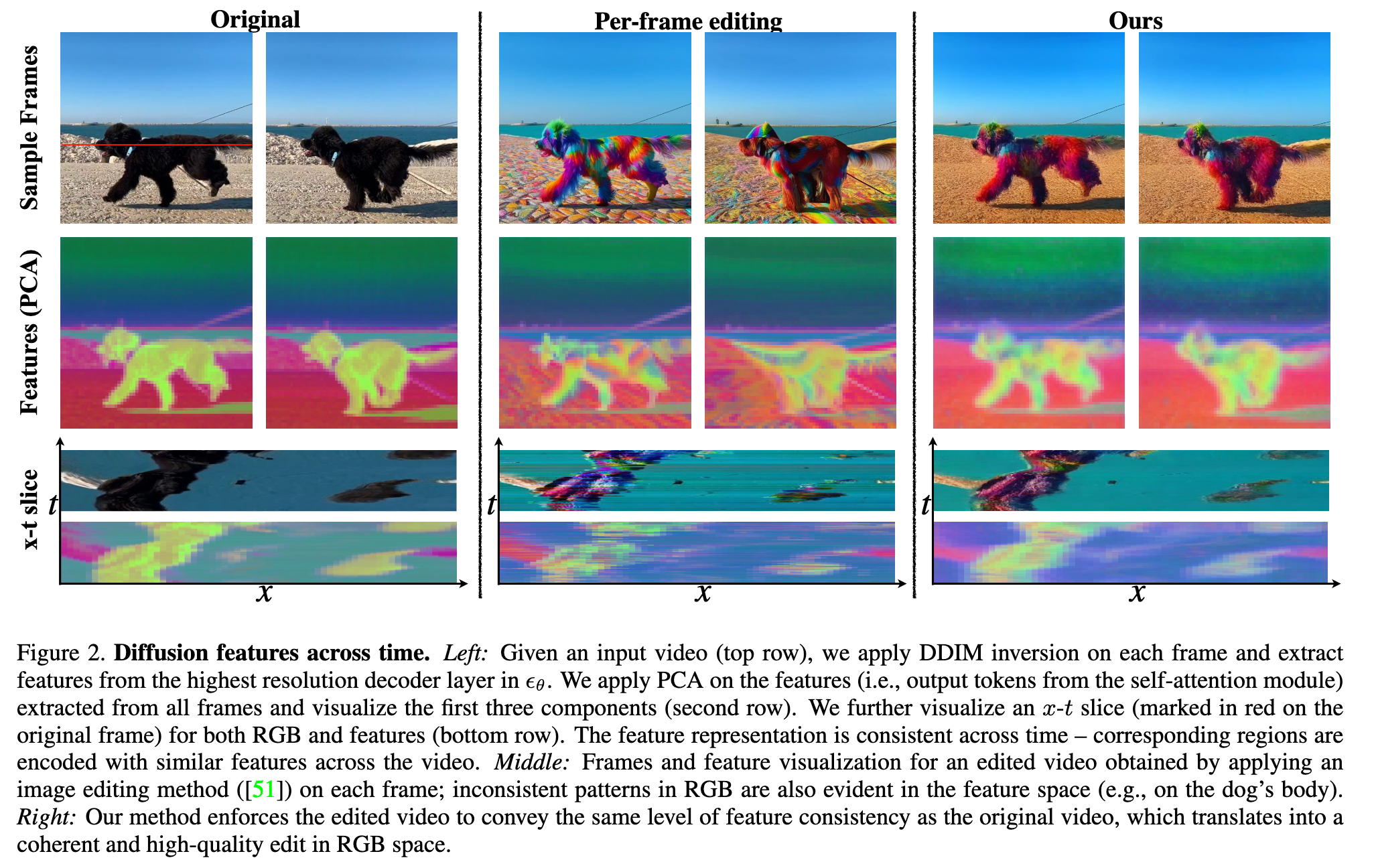

We further observe that the original video features provide fine-grained correspondences between frames, using a simple nearest neighbour search (Fig 3). Moreover, we show (p. 4) that these corresponding features are interchangeable for the diffusion model – we can faithfully synthesize one frame by swapping its features by their corresponding ones in a nearby frame (Fig 3(a)). (p. 4)
As illustrated in Fig. 4, our framework, dubbed TokenFlow, alternates at each generation timestep between two main components: (i) sampling a set of keyframes and jointly editing them according to P; this stage results in shared global appearance across the keyframes, and (ii) propagating the features from the keyframes to all of the frames based on the correspondences provided by the original video features; this stage explicitly preserves the consistency and fine-grained shared representation of the original video features. Both stages are done in combination with an image editing technique ϵˆθ(e.g, [51]). Intuitively, the benefit of alternating between keyframe editing and propagation is twofold: first, sampling random keyframes at each generation step increases the robustness to a particular selection. Second, since each generation step results in more consistent features, the sampled keyframes in the next step will be edited more consistently. (p. 4)
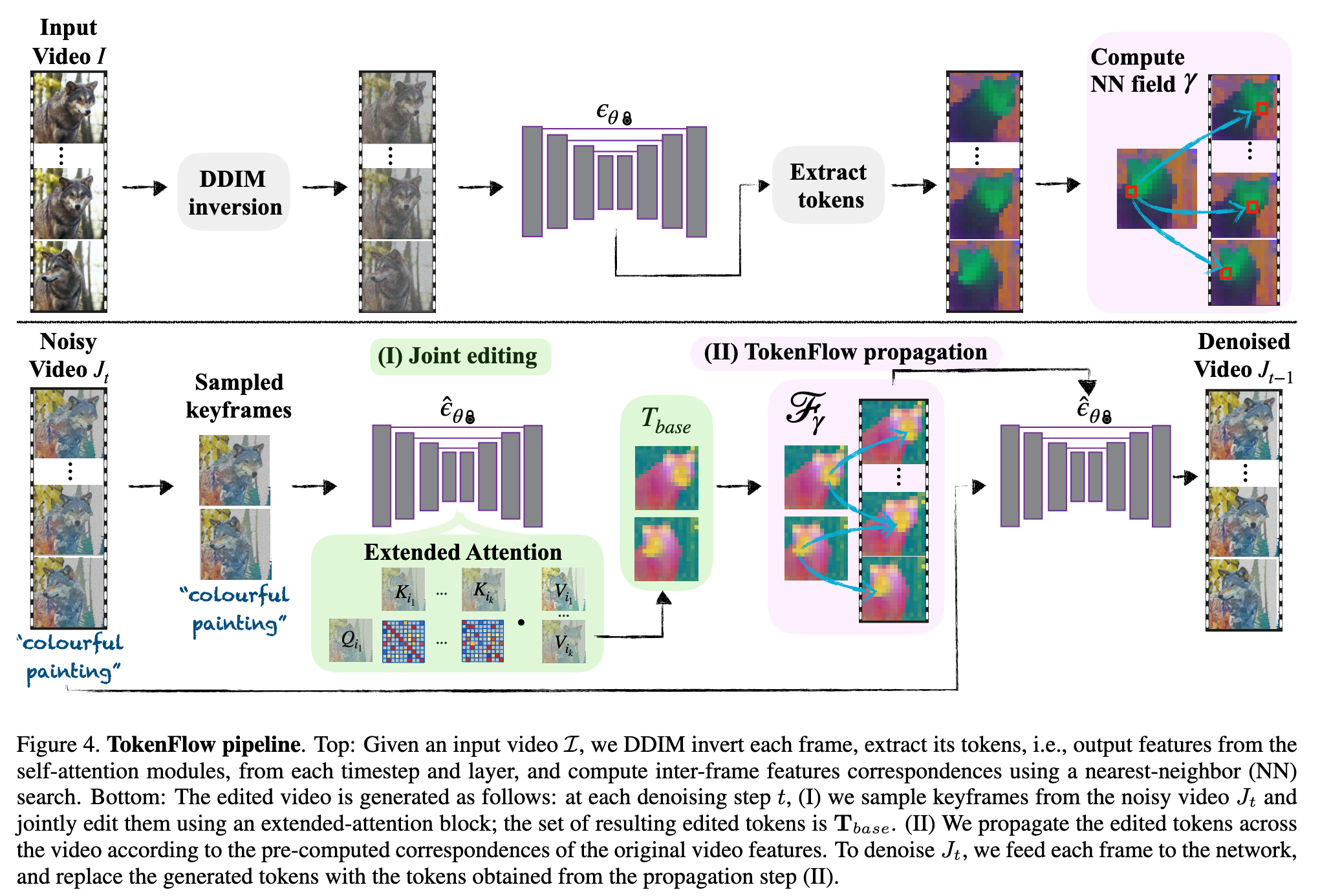
Intuitively, each keyframe queries all other keyframes, and aggregates information from them. This results in a roughly unified appearance in the edited frames [53, 19, 5, 34]. (p. 5)
Once we obtain γ±, we use it to propagate the edited frames’ tokens Tbase to the rest of the video, by linearly combining the tokens in Tbase corresponding to each spatial location p and frame i: (p. 5)
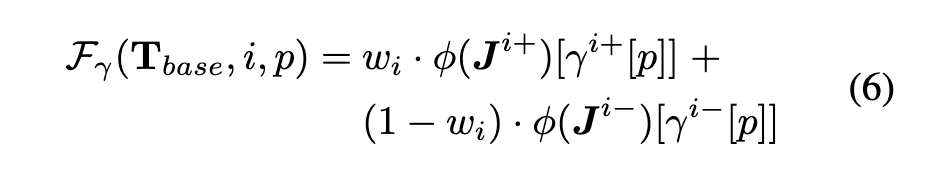
Where $\psi(J^{i±}) \in T_{base}$ and $w_i \in (0, 1)$ is a scalar proportional to the distance between frame i and its adjacent keyframes (see SM), ensuring a smooth transition. (p. 5)

Experiment Results
The spatial resolution of the videos is 384 × 672 or 512×512 pixels, and they consist of 40 to 200 frames. We use various text prompts on each video to obtain diverse editing results (p. 6)
We compare our method to state-of-the-art, and concurrent works: (i) Text2Video-Zero [19] that utilizes ControlNet [56] for video editing using self-attention inflation. (ii) Tune-a-Video [53] that fine-tunes the text-toimage model on the given test video. (iii) Gen-1 [10], a video diffusion model that was trained on a large-scale image and video dataset. (iv) Text2LIVE [1] which utilize a layered video representation (NLA) [18] and perform testtime training using CLIP losses. (p. 7)


As for limitations, our method is tailored to preserve the motion of the original video, and as such, it cannot handle edits that require structural changes (Fig 8.) Moreover, our method is built upon a diffusion-based image editing technique to allow the structure preservation of the original frames. When the image-editing technique fails to preserve the structure, our method enforces correspondences that are meaningless in the edited frames, resulting in visual artifacts. Lastly, the LDM decoder introduces some high frequency flickering [3]. A possible solution for this would be to combine our framework with an improved decoder (e.g., [3], [57]) We note that this minor level of flickering can be easily eliminated with exiting post-process deflickering (see SM). (p. 9)