Tool Learning with Foundation Models
[reinforcement llm deep-learning review This is my read note on Tool Learning with Foundation Models This is a nice review paper on how to use LLM with external tool to perform different tasks.
Introduction
They have shown enormous semantic understanding capacity in diverse tasks (p. 4). Additionally, they have demonstrated superior reasoning and decision-making abilities in complex interactive environments (Nakano et al., 2021). By harnessing the extensive world knowledge garnered during pre-training, they can perform grounded actions and interact with the real world. Notably, the emergence of ChatGPT (OpenAI, 2022) highlights the potential of foundation models to understand human intentions, automate intricate processes, and generate natural responses; the advent of GPT-4 (OpenAI, 2023) offers immense potential for multi-modal perception, which is essential to the real-world grounding ability (p. 4)
The whole procedure (§ 3.2) of tool learning starts with a user instruction, and models are required to make an executable plan for tool execution. To bridge user instructions with appropriate tools, models should first learn to understand the user intents underlying the instruction (i.e., intent understanding) and understand the functionalities and usage of tools (i.e., tool understanding). Models should also learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task with the appropriate tools. Regarding the training strategy (§ 3.3) to facilitate models for improved tool utilization, we conclude with two mainstream methods: learning from demonstrations and learning from feedback. (p. 5)
Finally, we discuss the remaining important research topics (§ 5) for applying our general framework to real-world scenarios, including (1) safety and trustworthiness, where we emphasize the potential risks from adversaries, governance, and trustworthiness. We contend that careful considerations are necessary before deploying tool learning models in high-stakes scenarios (§ 5.1); (2) tool learning for large complex systems, where we showcase the unique characters of large complex systems and discuss the challenges in applying tool learning to these systems, such as complicated knowledge and function learning, representative data sampling with privacy concerns, and the strict requirements of efficient tool learning (§ 5.2); (3) tool creation, where we discuss the possibility that AI can also create new tools, challenging the long-held beliefs about what makes humans unique (§ 5.3); (4) personalized tool learning, where models provide tailored assistance to users in tool use. We highlight the challenges of aligning user preference with tool manipulation and introduce the shift from reactive to proactive systems, and the privacy-preserving concerns (§ 5.4); (5) embodied learning, where the intersection of tool learning and embodied agent enables digital embodiment and manipulation of embodied tools (§ 5.5); (6) knowledge conflicts in tool augmentation, where we review how tools can be leveraged to enhance models’ generation and the practical problems of knowledge conflicts, which can lead to inaccurate and unreliable model predictions (§ 5.6); (7) other open problems, such as viewing tool use capability as a measure for machine intelligence and tool learning for scientific discovery (§ 5.7) (p. 5)
Background
Cognitive Origins of Tool Use
cognition as an enactive process that emphasizes interaction with the external world (Engel et al., 2013), and the feedback from observation, communication, and hands-on practice is important for mastering tool use. (p. 6)
For instance, “intoolligence” (Osiurak & Heinke, 2018) divides the tool use behavior into three modes: assistive tool use is usually passive and unaware (e.g., walking in the rain shelter corridor); arbitrary tool use requires active interaction (e.g., driving, using smart phones); free tool use further needs to comprehend and choose appropriate tools for the scenarios (e.g., cooking new dishes). In this framework, the three modes of tool use present a progressive relationship, and the authors assume that the key cognitive process for achieving free tool use is technical reasoning, which allows someone to learn new actions by observing others using, selecting, or making a tool instead of numerous practices. (p. 6)
Cognitive tools can be classified based on the functionalities they provide (Lajoie & Derry, 2013). These include (1) supporting cognitive processes (e.g., documenting intermediate reasoning outcomes), (2) alleviating lower-level cognitive load to free up resources for advanced-level thinking, (3) enabling learners to engage in activities out of their reach and (4) allowing learners to generate and test hypotheses (e.g., simulated diagnoses for medical students). (p. 6)
First, the abilities to manipulate tools are deeply rooted in our cognitive and perceptual systems and have evolved over millions of years. In contrast, foundation models rely primarily on statistical patterns of pre-training data, and significant gaps still exist between the tool-use capabilities of foundation models and their human counterparts. Humans can perceive the properties of tools, understand their functionalities, and identify the appropriate tools for each task. Gaining insights from this, we investigate and discuss how foundation models can learn such a process in § 3.2.1. Second, humans excel at breaking down complex tasks into smaller, manageable subtasks and deftly manipulating tools to accomplish each sub-task. However, foundation models lack the physical embodiment and sensory experience necessary to fully understand and utilize tools. As a result, these models often struggle with tasks that require higher-order reasoning and adaptivity, and they cannot trustfully integrate multiple sources of knowledge and tools effectively. We will discuss how to better make executable plans leveraging models’ reasoning abilities in § 3.2.2. Furthermore, current algorithms for adapting foundation models to learn specific tools generally require huge amounts of supervised data (Nakano et al., 2021; Reed et al., 2022), hindering their generalization and transferability to broader types of tools or novel situations. Hence we first summarize the training strategies for tool learning (§ 3.3.1 and § 3.3.2) and discuss how to facilitate the generalization and transferability of tool learning (§ 3.3.3). (p. 7)
Tool Categorization: A User-Interface Perspective
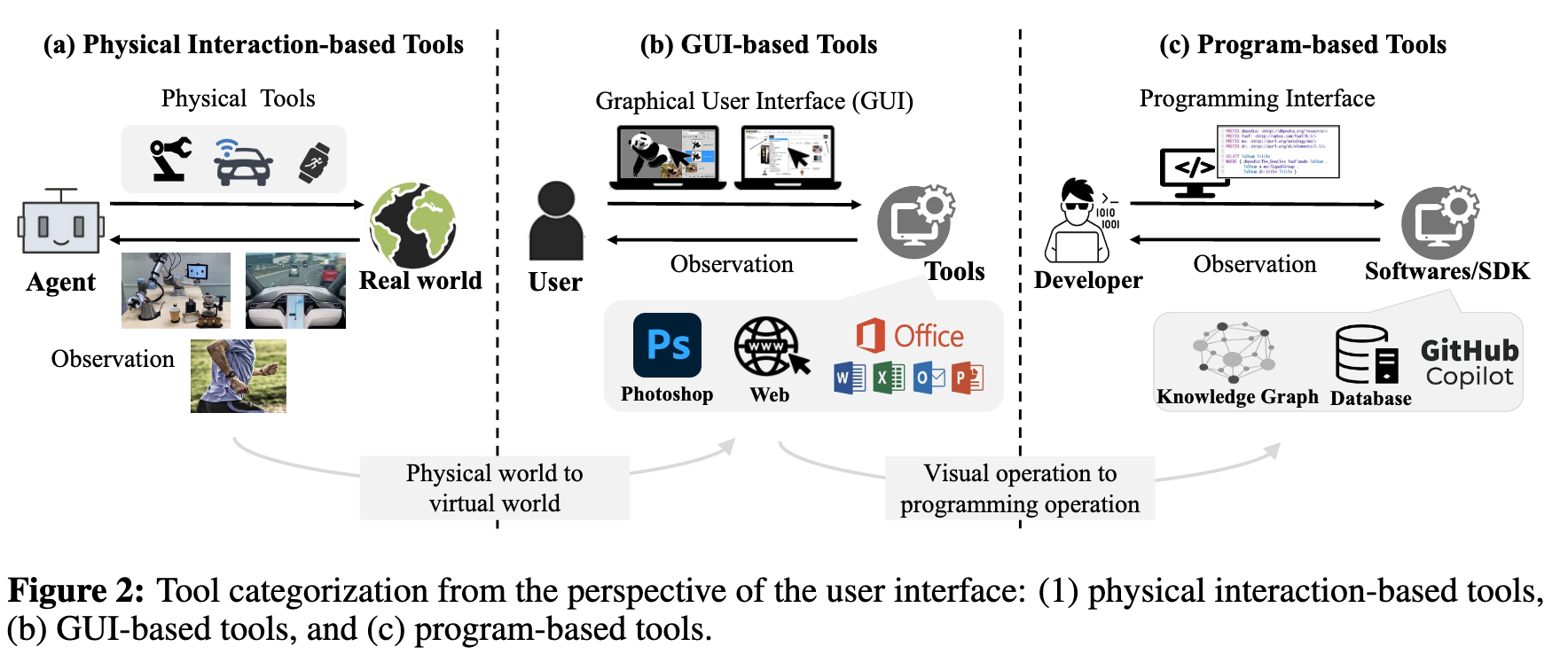
Paradigm Shift of Foundation Models
In recent years, the field of natural language processing (NLP) has undergone a paradigm shift, marked by the advent of pre-trained language models (PLMs) (p. 8) The invention of PLMs changes this paradigm. Building on Transformers (Vaswani et al., 2017), PLMs are trained on massive corpora, from which general linguistic ability and world knowledge are learned. This technique has expedited the unification of NLP tasks, giving rise to the pre-train-then-fine-tune paradigm, which has achieved new state-of-the-art performance on several NLP benchmarks, such as GLUE (Wang et al., 2019b) and SuperGLUE (Wang et al., 2019a). At this stage, each task shares the same starting point and only diverges as the task-specific adaptation proceeds. The fusion of task paradigms is still ongoing. T5 (Raffel et al., 2020) transforms all NLP tasks into a text-to-text format with textual descriptions, while GPT-3 (Brown et al., 2020) has discovered that introducing appropriate textual prompts can yield the desired output for specific tasks. Prompts, essentially serving as a natural language interface, are widely believed to stimulate the knowledge learned by PLMs during pre-training. Prompts can enable downstream tasks to be executed without updating model parameters for big models such as GPT-3. Research even suggests that with appropriate prompt guidance, models can perform complex reasoning tasks (Wei et al., 2022c; Wang et al., 2022a). Also, prompts formulated in a natural language format possess remarkable generalization capabilities (p. 8) models that have undergone fine-tuning using diverse instructions are able to effectively generalize to new, unseen data (Wei et al., 2022a; Sanh et al., 2022). Overall, prompts demonstrate a proof-of-concept that uses PLMs as the underlying infrastructure and natural language as the medium to uniformly perform various tasks. A highly successful example is ChatGPT, where all the natural language understanding and generation processes are accomplished through conversational interactions. (p. 9)
Nevertheless, there exist numerous tasks that transcend the scope of purely natural language. For instance, generating presentation slides2, constructing 3D models via CAD applications, and scheduling meetings through the analysis of team member calendars are examples of complex tasks that have not been defined in traditional artificial intelligence. Fortunately, the strong generalization ability of PLM enables us to use natural language as a medium to accomplish these tasks by manipulating tools (Zeng et al., 2022). Essentially, the key to tool learning is to decompose complex tasks into sub-actions, tokenize actions in the form of natural language and convert them into executable instructions that can be understood by specific tools. Language models serve as “translators”, making complex tasks more accessible to individuals without specialized technical knowledge. The potential applications of tool learning are vast and exciting, ranging from automated customer service and personal assistants to self-driving cars and even space exploration. By enabling machines to understand and interact with human language in a more natural and nuanced way, we can unlock new possibilities for collaboration and problem-solving that were previously impossible. We anticipate that tool learning will prove instrumental in facilitating the integration of diverse tasks through shared tooling. Thus, while natural language interfaces have enabled unification within the realm of language (Hao et al., 2022), the challenges posed by non-linguistic tasks necessitate a more advanced approach to leveraging both natural language and tool learning. By harnessing the power of natural language, we can create systems that are capable of understanding and adapting to the complex and dynamic world around us, opening up new avenues for innovation and discovery. (p. 9)
Complementary Roles of Tools and Foundation Models
Benefits of using tools:
- Mitigation for Memorization. Although foundation models have demonstrated an exceptional ability to memorize (Carlini et al., 2021, 2022, 2023), they are not capable of memorizing every piece of training data (p. 9)
- Enhanced Expertise. Specialized tools are designed to cater to specific domains with functionalities that are not available in foundation models. As a result, they are better suited to address the needs of domain-specific tasks (p. 9)
- Better Interpretability. Foundation models are criticized for lacking transparency in their decision-making process (Linardatos et al., 2020), which can be a significant concern in applications such as healthcare or finance, where interpretability is critical for making informed decisions. (p. 9)
- Improved Robustness. Foundation models are susceptible to adversarial attacks (Wallace et al., 2019; Jin (p. 9) et al., 2020), where slight modifications to the input can flip the model prediction. This is because these models heavily rely on statistical patterns in the training data (p. 10)
Benefits of Foundation Models. Foundation models can provide a solid basis for understanding, planning, reasoning, and generation, which bring several benefits for tool learning as follows:
- Improved Decision- Making and Reasoning Abilities. Foundation models are trained on vast amounts of data, enabling them to acquire world knowledge across a wide range of domains. If properly steered, such knowledge can be wielded to perform decision-making and planning over prolonged time horizons (Huang et al., 2022a). Besides, foundation models have demonstrated remarkable reasoning abilities (Wei et al., 2022c; Wang et al., 2022a), thereby enabling them to extrapolate the consequences of actions and make judicious decisions. These reasoning abilities are particularly useful for tasks requiring a deep understanding of cause-and-effect relations (§ 3.2.2).
- (2) Better User Experience. Benefitting from the powerful intent understanding capability of foundation models, tool learning could revolutionize the way we interact with machines and liberate users from the cognition load, allowing them to engage in higher-order thinking and decision-making processes. This, in turn, fosters a seamless and more natural language-based interaction paradigm that revolutionizes traditional graphical user interfaces (GUIs). The user only needs to provide high-level guidance and direction, and the model will seamlessly comprehend the user’s intent, thereby delivering more personalized and precise responses. In addition, tool learning has the potential to democratize access to complex tools. With the aid of foundation models, even novice users can easily and quickly get started with a new tool, regardless of their prior experience or technical expertise. This not only reduces the barriers to entry for new users but also unlocks a wealth of possibilities for innovation and creativity. However, it should be noted that human-model collaboration in tool use also triggers ethical concerns, which will be discussed in § 5.7. (p. 10)
Tool Learning
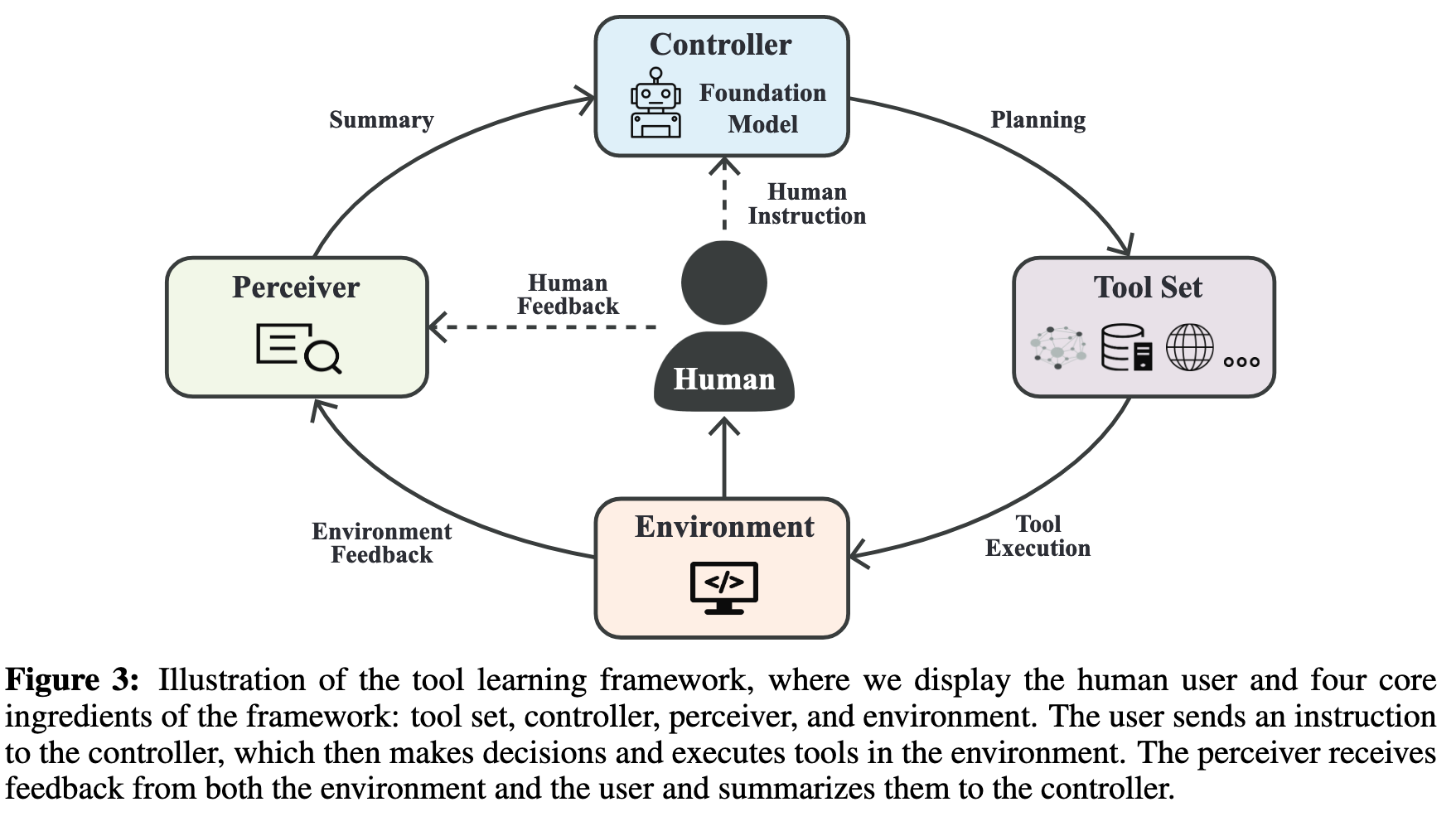
Components of Tool Learning
Controller. The controller C serves as the “brain” for tool learning framework and is typically modeled using a foundation model. The purpose of the controller C is to provide a feasible and precise plan for using tools to fulfill the user’s request. To this end, C should understand user intent as well as the relationship between the intent and available tools, and then develop a plan to select the appropriate tools for tackling tasks, which will be discussed in § 3.2.1. In cases where the query is complex and targets a high-level task, C may need to decompose the task into multiple sub-tasks, which requires foundational models to have powerful planning and reasoning capabilities (§ 3.2.2). (p. 11)
Perceiver. The perceiver P is responsible for processing the user’s and the environment’s feedback and generating a summary for the controller. Simple forms of feedback processing include concatenating the user and environment feedback or formatting the feedback using a pre-defined template. The summarized feedback is then passed to the controller to assist its decision-making. By observing this feedback, the controller can determine whether the generated plan is effective and whether there are anomalies during the execution that need to be addressed. Under more complex scenarios, the perceiver should be able to support multiple modalities, such as text, vision, and audio, to capture the diverse nature of feedback from the user and the environment. (p. 11)
The General Procedure: From Intent to Plan
Understanding Intent and Tools
Challenges of understanding intents:
- Understanding Vague Instructions. (p. 12) One possible solution is to actively interact with users to clarify any ambiguity, such as asking for clarifications about a previous user query (p. 12)
- Generalization to Diverse Instructions (p. 12) In addition, the challenge of personalization arises from the fact that each individual has their own unique way of expressing intentions, (p. 12)

In real-world scenarios, tools are typically accompanied by a manual (or tutorial), which provides sufficient relevant details about their functionalities and usage. Endowed with strong few-shot learning (Brown et al., 2020) and zero-shot learning (Wei et al., 2022a) capabilities, foundation models can be prompted to unravel tools’ functionalities and comprehend how to use them. To this end, we can construct suitable task-specific prompts either through manual design (Vemprala et al., 2023) or retrievial (Zhou et al., 2023). These prompts should describe the API functionalities or exemplify with demonstrations of their usage (p. 13) divided into multiple sub-tasks with proper sequencing, thereby necessitating a process of reasoning. Recent research has revealed that reasoning capabilities can emerge when foundation models are scaled up to a certain size (Wei et al., 2022b). In particular, foundation models with tens or hundreds of billions of parameters can generate intermediate reasoning traces during complex problem-solving, which significantly boosts their zero-shot and few shot.
We categorize two prompting approaches as shown in Figure 4: (1) zero-shot prompting, which describes API functionalities, their input/output formats, possible parameters, etc. This approach allows the model to understand the tasks that each API can tackle; (2) few-shot prompting, which provides concrete tool-use demonstrations to the model. By mimicking human behaviors from these demonstrations, the model can learn how to utilize these tools. We (p. 13) ogy literature (Wason, 1968; Kelley, 2013), the notion of reasoning as applied to foundation models is not clearly defined. However, in general terms, the reasoning ability in the literature of foundation models can be framed as the capacity to decompose a complex problem into sub-problems and solve them First, since the effectiveness of prompting depends a lot on the model, smaller or less capable models cannot understand prompts well. Second, prompting is restricted by input context length. Although foundation models have been shown to learn to use simple tools through prompts (p. 13)
A potential solution is to add an intermediate stage of tool selection, which first retrieves a small set of tools that are most suitable for the task at hand. Another solution is fine-tuning, which optimizes models with concrete tool-use examples to understand tools (p. 14)
Planning with Reasoning
The user query q often implies a complex task that should be divided into multiple sub-tasks with proper sequencing, thereby necessitating a process of reasoning. Recent research has revealed that reasoning capabilities can emerge when foundation models are scaled up to a certain size (Wei et al., 2022b). In particular, foundation models with tens or hundreds of billions of parameters can generate intermediate reasoning traces during complex problem-solving, thereby significantly enhancing their zero-shot and few-shot performances (Nakano (p. 14)
The vanilla few-shot prompt learning (Brown et al., 2020), whereby models are provided with a prompt consisting of several examples for the given task, has been shown to fail when it comes to problems that require complex reasoning (Creswell et al., 2022). To address this issue, Wei et al. (2022c) propose Chain-of-Thought (CoT) prompting. Unlike vanilla few-shot prompt learning, CoT additionally inserts the reasoning trace required to derive the final answer for each example in the prompt. In this way, CoT prompts models to generate their “thoughts” on the necessary intermediate steps before arriving at the final answer. CoT has been proven to significantly boost performance on a wide range of tasks, including arithmetic reasoning, commonsense reasoning, and symbolic reasoning (Wei et al., 2022c). (p. 14)
We categorize relevant research into two streams: introspective reasoning and extrospective reasoning. The former involves generating a static plan of tool use without interacting with the environment E, while the latter generates plans incrementally by iteratively interacting with E and utilizing feedback obtained from previous executions. (p. 14)
introspective reasoning: Another representative work is Program-Aided Language Models (PAL) (Gao et al., 2022), which prompts models to generate Python codes for intermediate reasoning steps. PAL uses the Python program interpreter as the tool, enabling the model to act as a programmer writing detailed comments, and achieving significant improvements in arithmetic, symbolic, and algorithmic reasoning. Notably, the idea of model-as-programmer has also been shown to be successful in embodied agents, as evidenced by ProgPrompt (Singh et al., 2022) and Code-as-Policies (Liang et al., 2022a) (p. 14)
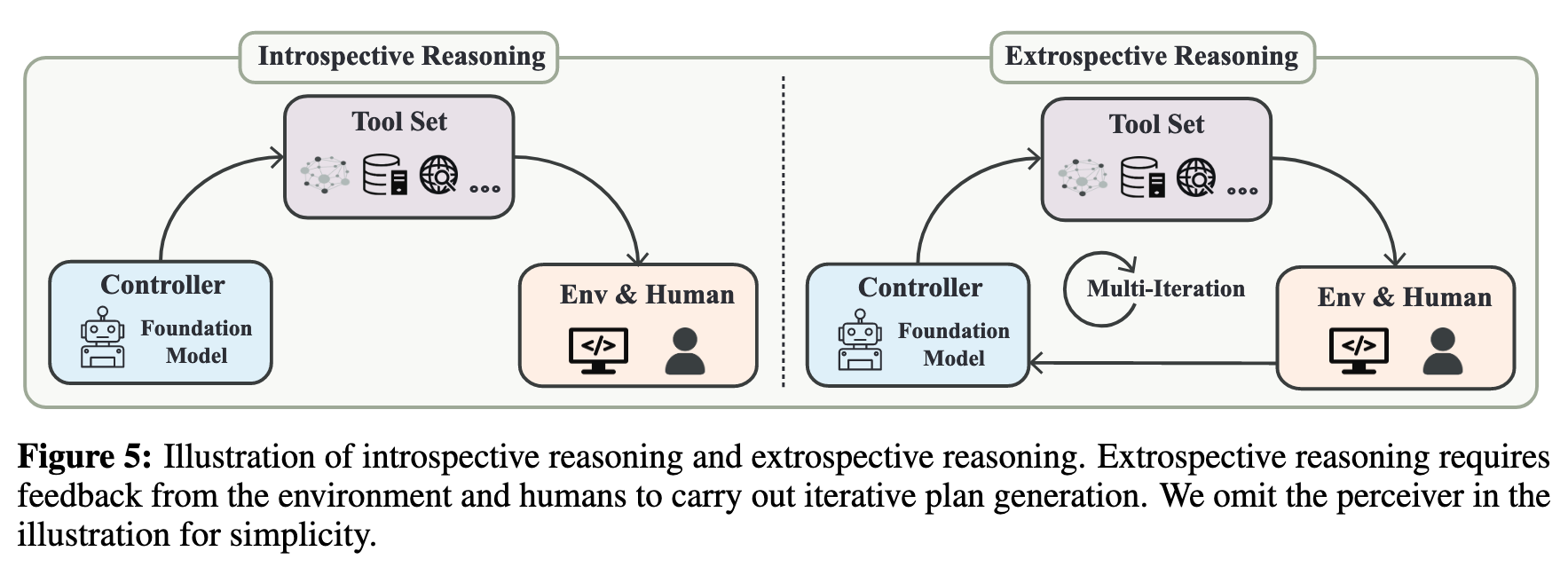
Extrospective Reasoning. Despite its simplicity, introspective reasoning cannot adapt the plan in response to intermediate execution results. A more rational approach to planning is taking the environment E into account, and generating plans incrementally (e.g., one step at a time) with subsequent plans dependent on previous execution results (p. 15)
Challenges in Multi-Step Multi-Tool Scenario:
- Understanding the Interplay among Different Tools. The multi-step multi-tool scenario typically involves complex tasks that require a higher level of intent understanding and reasoning capability. To effectively utilize multiple tools under this scenario, models need to grasp not only the individual functionalities of tools but also their interactions and dependencies. Models should be able to sequence the tools in a logical order so that the subsequent tools can leverage the information generated by the previous tools and effectively complete the task.
- From Sequential Execution to Parallel Execution. Tool executions do not have to be performed sequentially. In certain scenarios, parallel execution is possible for sub-tasks that do not depend on each other, which can potentially improve execution efficiency. For instance, given a user instruction “Generate two codes, one for drawing a rectangle, and one for drawing a circle.”, the two tasks can be assigned to two agents, enabling the codes to be generated simultaneously. Determining the dependencies among different sub-tasks and effectively switching between parallel and sequential execution to optimize the overall process is a promising direction that merits further investigation.
- From Single-agent Problem-Solving to Multi-agent Collaboration. Previous works typically assume that a single agent (controller) is solely responsible for the entire tool learning procedure. However, in practice, complex tasks often demand collaboration among multiple agents, each possessing unique abilities and expertise. Embracing multi-agent collaboration can unlock more effective and efficient problem-solving approaches, necessitating the design of methods for communication, coordination, and negotiation among agents to ensure seamless collaboration and optimal task execution. Notably, recent work like Park et al. (2023) demonstrates that multiple agents modeled with foundation models can simulate human behaviors (e.g., interpersonal communication) in interactive scenarios. This provides promising evidence for the adoption of multiple agents for tool learning (p. 16)
Training Models for Improved Tool Learning
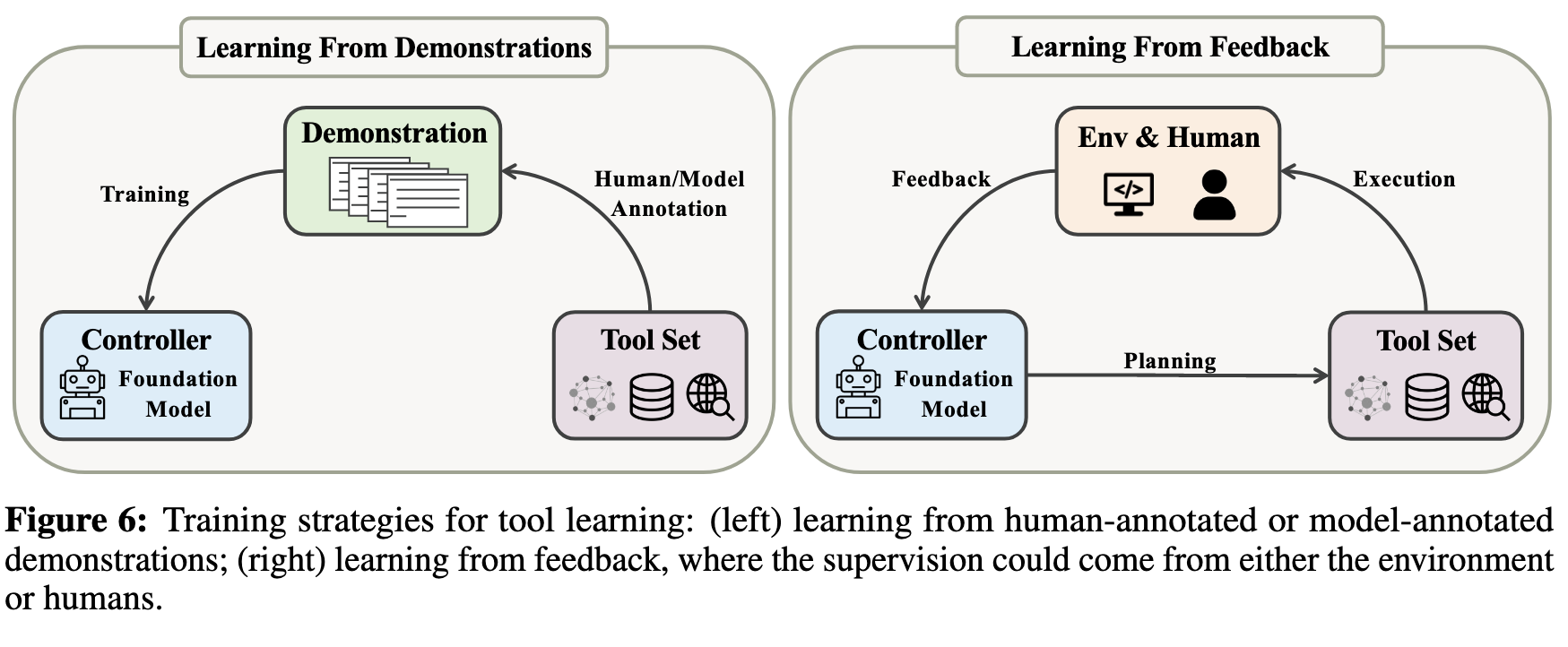
Learning from Demonstrations
The objective of behavioral cloning is to train models to imitate human experts’ actions given certain inputs or conditions, and this approach is commonly adopted when the actions of an expert can be easily recorded and utilized for learning (p. 17)
For instance, with a small amount of seed labeled data, Baker et al. (2022) train a model to predict pseudo-labels of the action taken at each timestep in a Minecraft video game. Learning from these pseudo-labels, a more powerful model can be trained without requiring the rollout of models in a target environment or large-scale gold-standard human behavior annotation. (p. 18)
Besides, the biases in the seed dataset may also be amplified during training, leading to poor generalization performance (p. 18)
Learning from Feedback
Collecting manually annotated tool-use examples, which probably include complete traces of human behaviors and the final answers, is time-consuming and labor-intensive. Moreover, the learned model may not adapt effectively to new environments as it conforms to the recorded human behaviors. Besides, it is impractical to explicitly annotate every possible scenario of environment condition and agent behavior (Codevilla et al., 2019). Alternatively, humans learn from trial and error to correct and rectify their tool-use behaviors (Allen et al., 2019). Similarly, feedback from both the environment and humans can enable the model to understand the consequences of its actions and adapt its behaviors. The supervision from feedback can also enhance the capabilities of an agent trained in a supervised way (Nakano et al., 2021; Baker et al., 2022).
Tool learning can be considered an RL scenario, where the action space is defined by tools, and the agent learns to select the appropriate tool and perform the correct actions that maximize the reward signal. The policy model can be initialized by a foundation model (Schulman et al., 2017). Such initialization brings the policy model abundant prior knowledge, alleviating the need for the RL agent to learn basic skills. With a reward function that quantifies the performance of the agent in achieving the task goal, RL has been successfully used in various tool learning scenarios (p. 18) By optimizing the loss function, the agent learns to reflect on the current state of the environment, select the appropriate tool, and perform the right actions that lead to the highest expected reward. In the following, we introduce two sources of feedback: environment feedback and human feedback, which can be considered sources of reward signals in the context of tool learning. These two feedbacks are complementary and can be combined with each other. (p. 18)
Human Feedback. Humans could give the model rewards and penalties based on its generated plans to regulate its behavior. Human feedback can be explicit, which provides clear and direct insights into the model performance representing human preferences. For example, rating the quality of the model-generated action on a scale of 1 to 5; human feedback can also be implicit, which is not directly specified by the user but can be derived from user behavior and interactions with the model. Examples include users’ comparison (Ouyang et al., 2022), response time, and actions taken after receiving a model’s output (e.g., clicking on a recommended link).
Though human feedback is accurate and stable, it is label-intensive and has high latency. To address this issue, reinforcement learning from human feedback (RLHF) (Christiano et al., 2017) is proposed to finetune a model to imitate humans to give rewards, which are then used to optimize the policy with RL algorithms such as PPO (Schulman et al., 2017). RLHF has yielded exceptional performance in various domains such as text summarization (Ziegler et al., 2019; Stiennon et al., 2020). RLHF can also improve a model’s tool- use capabilities even if it has been trained on sufficient supervised human demonstrations. For instance, WebGPT (Nakano et al., 2021) utilizes human feedback to guide a policy model to align with human preferences, which helps better manipulate search engines to answer long-form questions. Despite its remarkable performance, RLHF still faces challenges: (1) task-specific nature: the corresponding evaluation criteria for specific tasks need to be pre-defined, and the preference data annotated for one task is hard to be transferred to other settings, which limits the applicability of RLHF to a wider range of tasks.
To this end, it is critical to develop a universal reward model that generalizes to various tasks; (2) biases: RL agents optimize towards the pseudo-human reward model, thus can be up-bounded and biased by human preferences. Besides, societal biases or personal experiences may be amplified during RLHF, and it is essential to carefully evaluate the learned reward model for any biases and take measures to mitigate them. (p. 19)
Generalizable Tool Learning
It should be noted that the interface selection should align with the capabilities and limitations of the foundation model. For instance, language foundation models are trained to generate text and may be better suited for the semantic interface. Similarly, a multimodal foundation model that combines visual and textual information may be more appropriate for the GUI interface, as it can understand and generate human-like mouse movements and keyboard inputs. On the other hand, code foundation models may be more suitable for the programming interface, as it is trained to understand code syntax and function calls.
Under certain cases, we may face challenges where the tool’s output is not aligned with model’s input format. A common practice is to compose the functionality of the model and tool in the same modality. For example, Zeng et al. (2022) chain together foundation models of various modalities by converting their outputs into natural languages. This simple method leverages prompting to compose new multimodal capabilities without fine-tuning. In contrast, another solution is to building multimodal foundation models that can perceive general modalities, based on the belief that multimodal foundation models can all be unified through a general-purpose interface (p. 20)
- Meta Tool Learning. (p. 21) In the context of tool learning, metacognition refers to the ability of a model to reflect on its own learning process and adapt new tool-use strategies when necessary. With metacognition, models can identify common underlying principles or patterns in tool-use strategies and transfer them to new tasks or domains (p. 21)
- Curriculum Tool Learning. Another approach to improving model generalization is through curriculum learning (Bengio et al., 2009), which starts with simple tools and gradually introduces the model to more complex tools so that it can build upon its prior knowledge and develop a deeper understanding of the tool. (p. 21)
Applications

Discussion
Safe and Trustworthy Tool Learning
Recent works suggest that large foundation models like ChatGPT are more robust on hard and adversarial examples (Taori et al., 2020; Wang et al., 2023a), which improves their utility in the complicated real world. But the attempt of crafting misleading or even harmful queries will undoubtfully persist as well (Perez & Ribeiro, 2022). Moreover, due to training on massive web data, foundation models are faced with long-lasting training-time security issues in deep learning, such as backdoor attacks (Kurita et al., 2020; Cui et al., 2022) and data poisoning attacks (Wallace et al., 2021) (p. 26)
From General Intelligence to Personalized Intelligence
For example, when a user seeks advice on managing their finances, to provide helpful and relevant suggestions, models should first gain access to the user’s personalized data, such as income, expenses, and investment history, via financial tools. Subsequently, models may look for recent investment trends and relevant news through a search engine. By utilizing personalized information, models can provide more customized advice and offer a more tailored approach to financial management. (p. 29)
These methods utilize external user-specific modules, such as user embeddings and user memory modules (Zhang et al., 2018; Wu et al., 2021), to inject preferences, writing styles, and personal information of different users into the generated content. However, these works are often designed for specific tasks and experimented with limited user information. (p. 29)
Aligning User Preference with Tool Manipulation.
- heteroge- neous user information modeling: in real-world scenarios, personal information can come from numerous heterogeneous sources (p. 29)
- personalized tool planning: different users tend to have different preferences for tool planning and selection (p. 29)
- personalized tool call: adaptively calling tools according to the user’s preference is also an important direction in personalized tool learning (p. 29)
From Reactive Systems to Proactive Systems. Currently, most of the foundation models are designed as reactive systems, which respond to user queries without initiating any actions on their own. A paradigm shift is underway toward proactive systems that can take action on behalf of the user. This shift presents both opportunities and challenges for tool learning. By leveraging the history of user interactions, proactive systems can continually improve their performance and tailor their responses to specific users, which provides a more personalized and seamless user experience. (p. 29)
On the one hand, previous work has shown that training data extraction attacks can be applied to recover sensitive personal privacy from foundation models (Carlini et al., 2021), which is a critical challenge for personalized tool learning. On the other hand, models with high computational costs must be deployed on cloud servers, which require uploading private data to the cloud to enable personalized responses. It is crucial to develop secure and trustworthy mechanisms to access and process user data while protecting user privacy. Addressing these challenges will help unlock the potential of personalized tool learning, enabling more effective and tailored tool manipulation to meet individual user needs. To this end, it is worth exploring model-oriented distributed computing frameworks, such as edge computing and federated learning, in which cloud servers are responsible for hosting computationally intensive models, while edge devices like PCs or smartphones process personalized information to prevent its leakage. (p. 30)
Knowledge Conflicts in Tool Augmentation
We find that ChatGPT is able to correct its own belief given retrieved information and discern the knowledge conflicts from different source (p. 32)