VectorFusion Text-to-SVG by Abstracting Pixel-Based Diffusion Models
[dream-booth vector-fusion diffusion style-clip-draw score-distillation-sampling deep-learning vector-graph sds live diffvg sktech-rnn text2image svg clip-draw vector-ascent This is my reading note for VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models. This paper utilized the differential rendering for vector graph to train a diffusion model to generate vector graph for a given text.

Introduction
We do so without access to large datasets of captioned SVGs. By optimizing a differentiable vector graphics rasterizer, our method, VectorFusion, distills abstract semantic knowledge out of a pretrained diffusion model. Inspired by recent text-to-3D work, we learn an SVG consistent with a caption using Score Distillation Sampling. To accelerate generation and improve fidelity, VectorFusion also initializes from an image sample. Ex (p. 1)
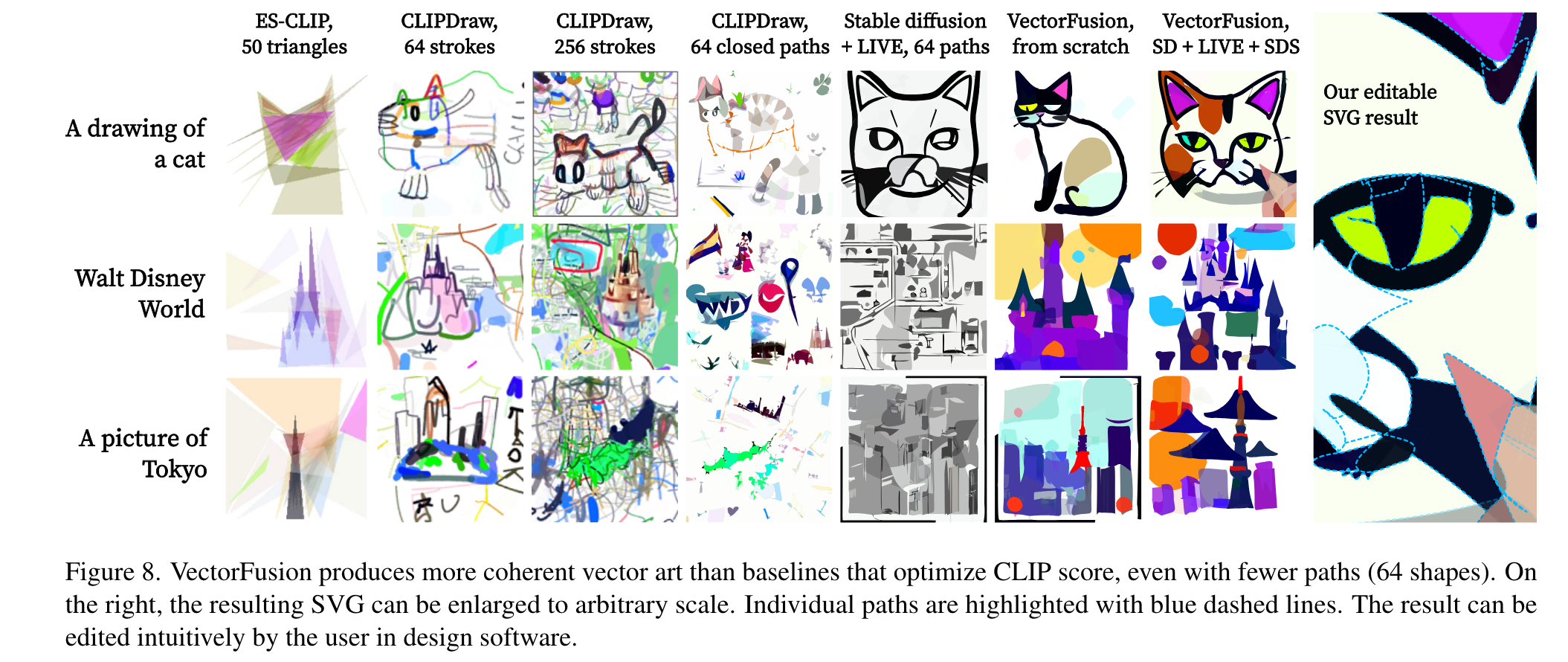
Unfortunately, we find that text-to-image diffusion models frequently produce complex images that are hard to represent with simple vectors, or are incoherent with the caption (Fig 1, Stable Diffusion + LIVE). Even with a good pixel sample, automated conversion loses details. (p. 3)
Related Work
VectorAscent [11] and CLIPDraw [4] optimize CLIP’s image-text similarity metric [27] to generate vector graphics from text prompts, with a procedure similar to DeepDream [23] and CLIP feature visualization [5]. StyleCLIPDraw [35] extends CLIPDraw to condition on images with an auxiliary style loss with a pretrained VGG16 [36] model. (p. 3)
Background
Vector representation and rendering pipeline
Vector graphics are composed of primitives. For our work, we use paths of segments delineated by control points. We configure the control point positions, shape fill color, stroke width and stroke color. Most of our experiments use closed Bezier curves´ (p. 3)
We use DiffVG [16], a differentiable rasterizer that can compute the gradient of the rendered image with respect to the parameters of the SVG paths. Many works, such as LIVE [19], use DiffVG to vectorize images, though such transformations are lossy. (p. 3)
Score distillation sampling
DreamFusion [26] proposed an approach to use a pretrained pixel-space text-to-image diffusion model as a loss function. Their proposed Score Distillation Sampling (SDS) loss provides a way to assess the similarity between an image and a caption: (p. 4)
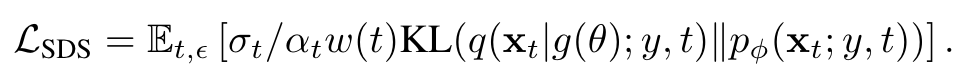
Method: VectorFusion
A baseline: text-to-image-to-vector
Naively, the diffusion model generates photographic styles and details that are very difficult to express with a few constant color SVG paths. To encourage image generations with an abstract, flat vector style, we append a suffix to the text: “minimal flat 2d vector icon. lineal color. on a white background. trending on artstation”. (p. 5)
Because samples can be inconsistent with captions, we sample K images and select the Stable Diffusion sample that is most consistent with the caption according to CLIP ViTB/16 [27]. CLIP reranking was originally proposed by [29]. We choose K=4. (p. 5)
Next, we automatically trace the raster sample to convert it to an SVG using the off-the-shelf Layer-wise Image Vectorization program (LIVE) (p. 5)
Sampling vector graphics by optimization
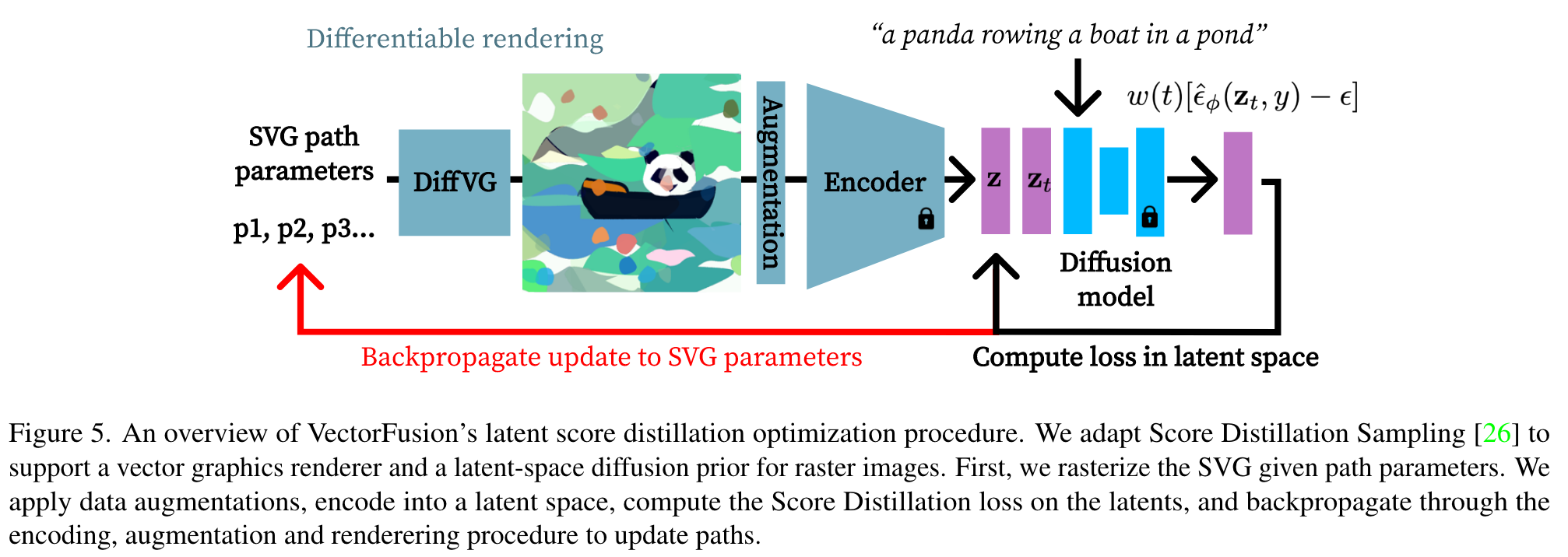
For VectorFusion, we adapt Score Distillation Sampling to support latent diffusion models (LDM) like the open source Stable Diffusion. We initialize an SVG with a set of paths θ = {p_1, p_2, . . . p_k}. Every iteration, DiffVG renders a 600 × 600 image x. Like CLIPDraw [4], we augment with perspective transform and random crop to get a 512×512 image x_aug. Then, we propose to compute the SDS loss in latent space using the LDM encoder E_φ, predicting z = E_φ(x_aug). For each iteration of optimization, we diffuse the latents with random noise z_t = α_t z + σ_t , denoise with the teacher model ˆφ(z_t, y), and optimize the SDS loss using a latentspace modification of Equation 4: (p. 5)
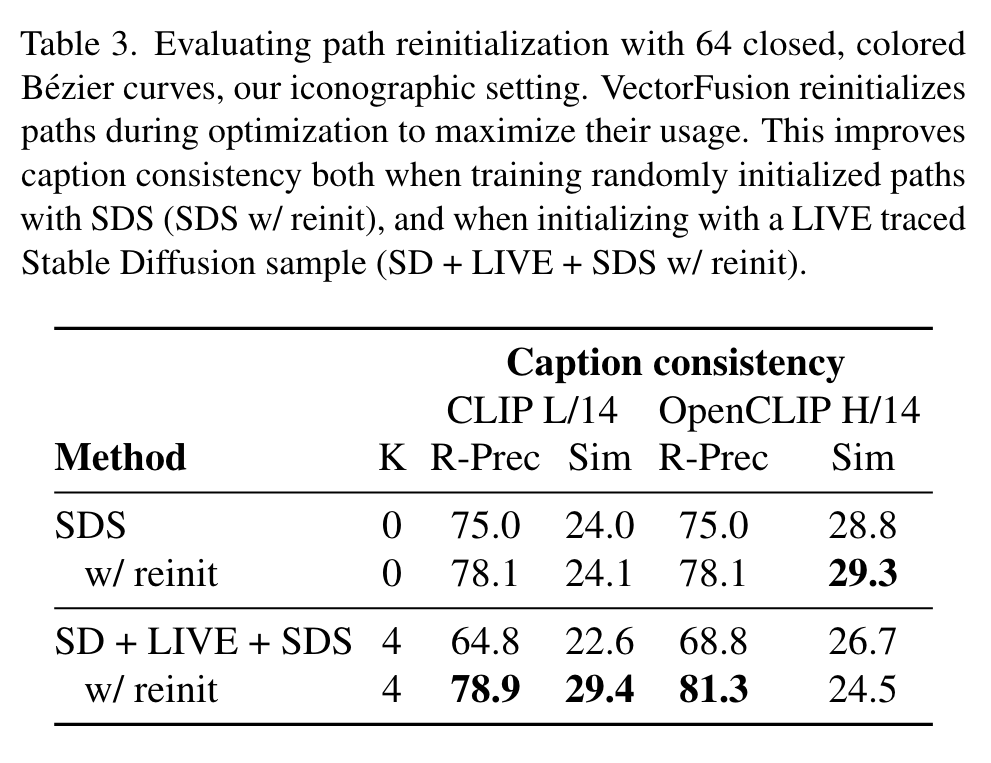
Reinitializing paths
the course of optimization, many paths learn low opacity or shrink to a small area and are unused. To encourage usage of paths and therefore more diverse and detailed images, we periodically reinitialize paths with fill-color opacity or area below a threshold. Reinitialized paths are removed from optimization and the SVG, and recreated as a randomly located and colored circle on top of existing paths (p. 6)
Stylizing by constraining vector representation
In addition to the SDS loss, we additionally penalize an L2 loss on the image scaled between -1 and 1 to combat oversaturation, detailed in the supplement. We use 32 × 32 pixel grids (p. 6)
Past work includes directly training a model to output strokes like Sketch-RNN [7], or optimizing sketches to match a reference image in CLIP feature space [42]. As a highly constrained representation, we optimize only the control point coordinates of a set of fixed width, solid black Bezier curves. We use 16 strokes, each 6 pixels wide with 5 segments, randomly initialized and trained from scratch, since the diffusion model inconsistently generates minimal sketches. (p. 7)
Experiments
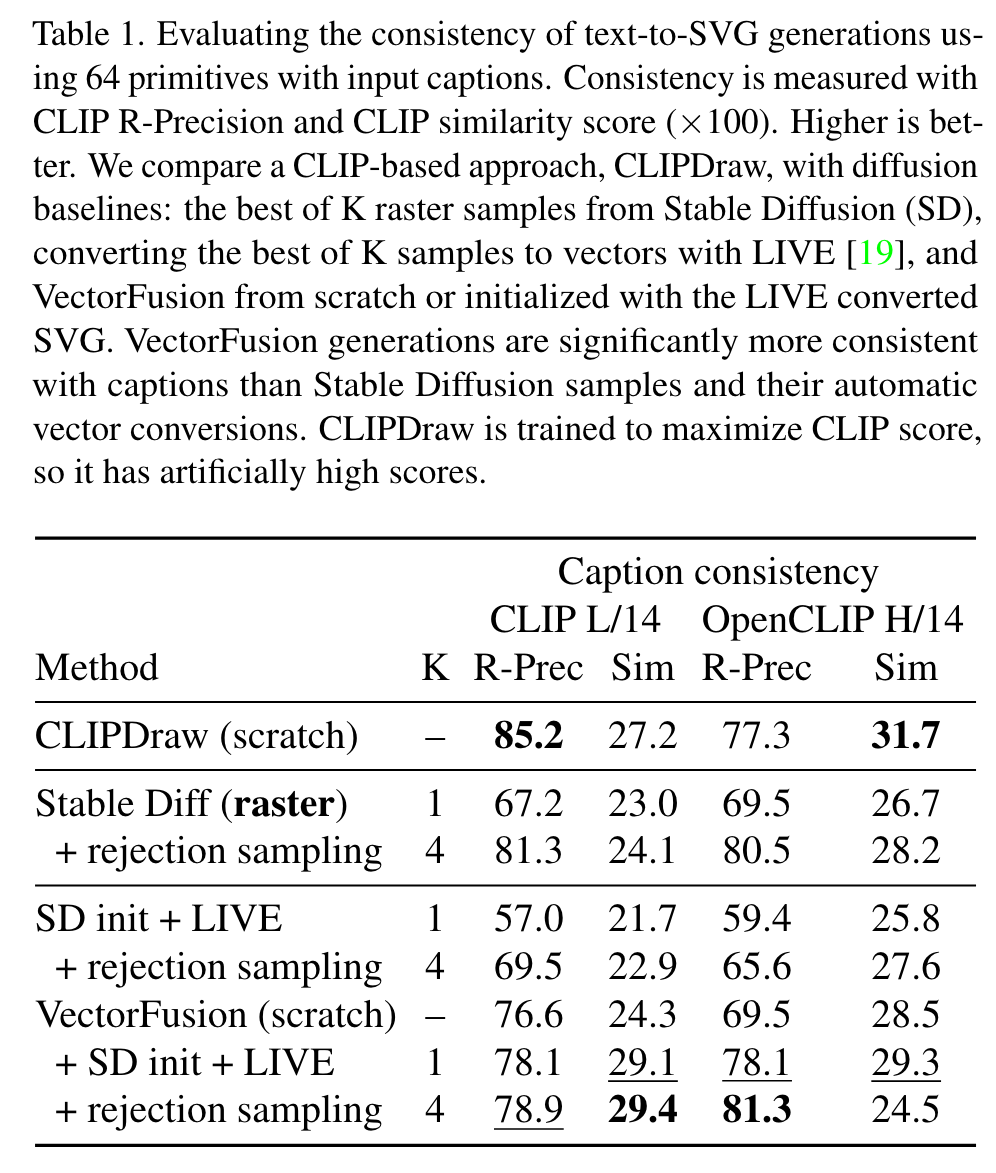

Ablation
Reinitializing paths
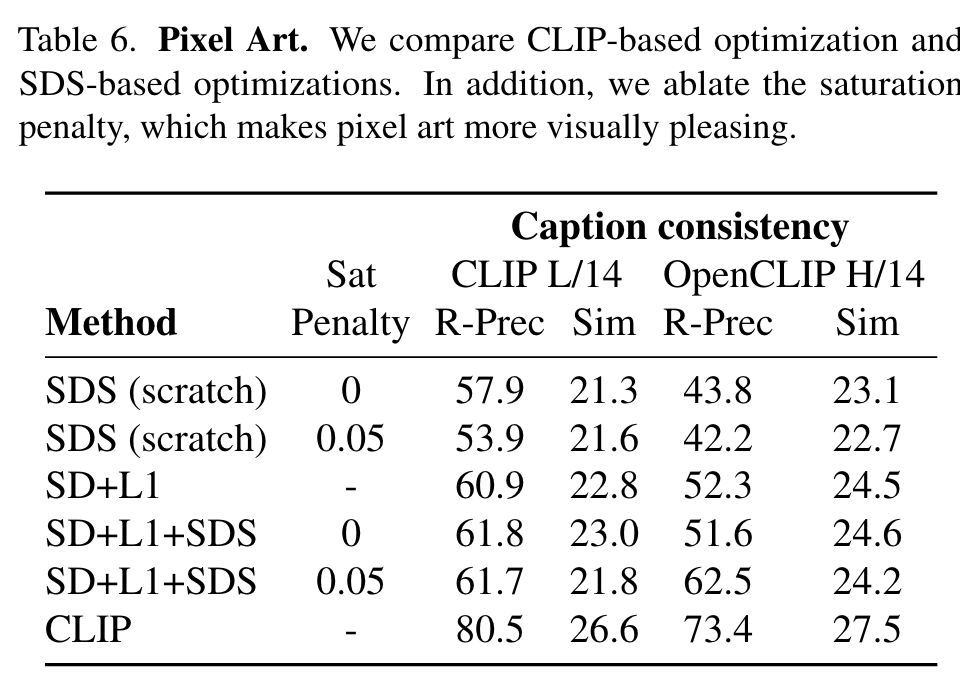
Table 3 ablates the use of reinitialization. When optimizing random paths with SDS, reinitialization gives an absolute +3.0% increase in R-Precision according to OpenCLIP H/14 evaluation. When initialized from a LIVE traced sample, reinitialization is quite helpful (+12.5% R-Prec). (p. 11)
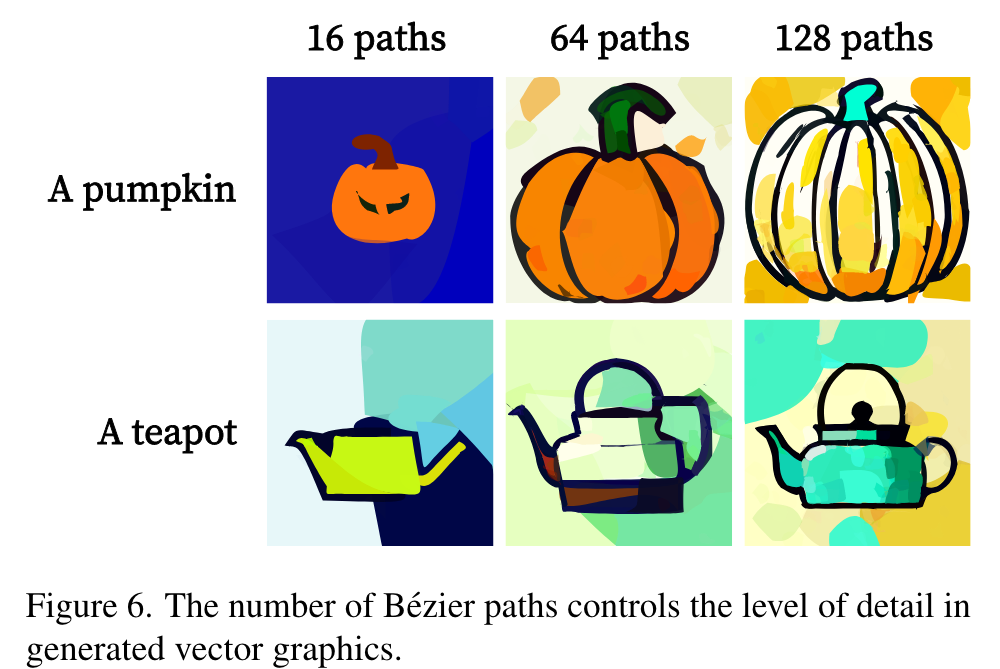
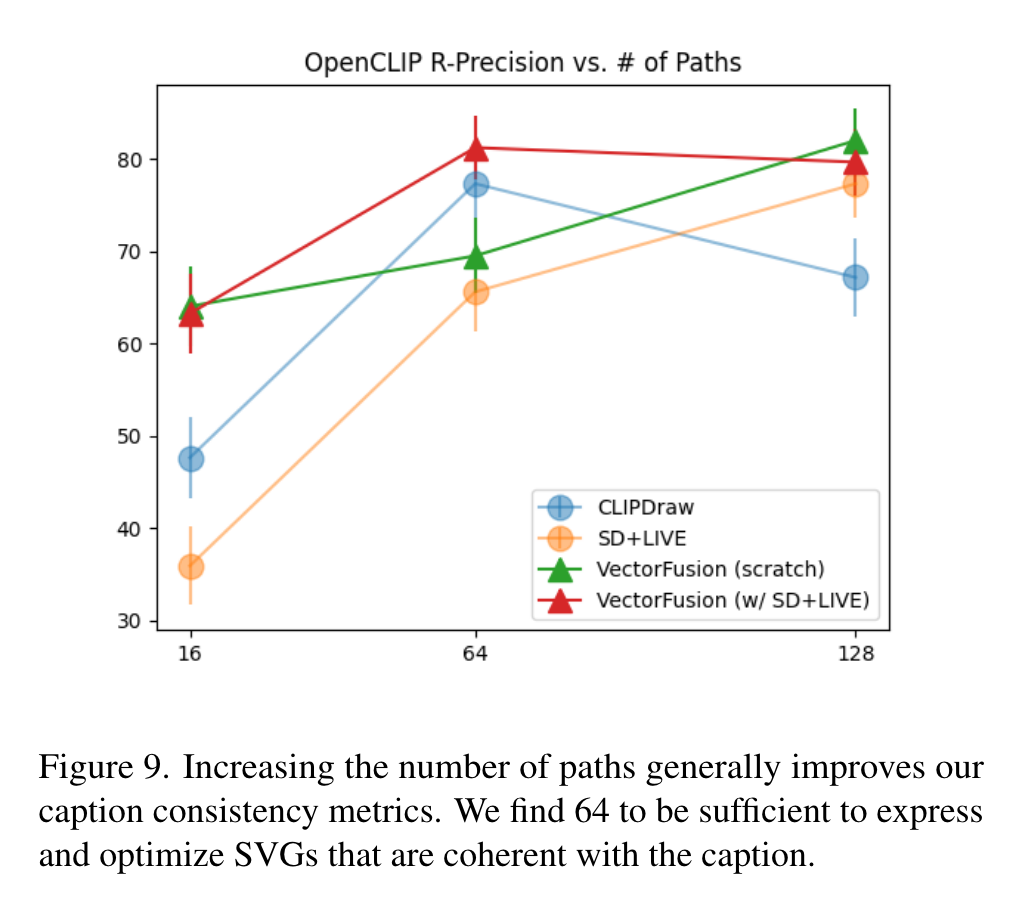
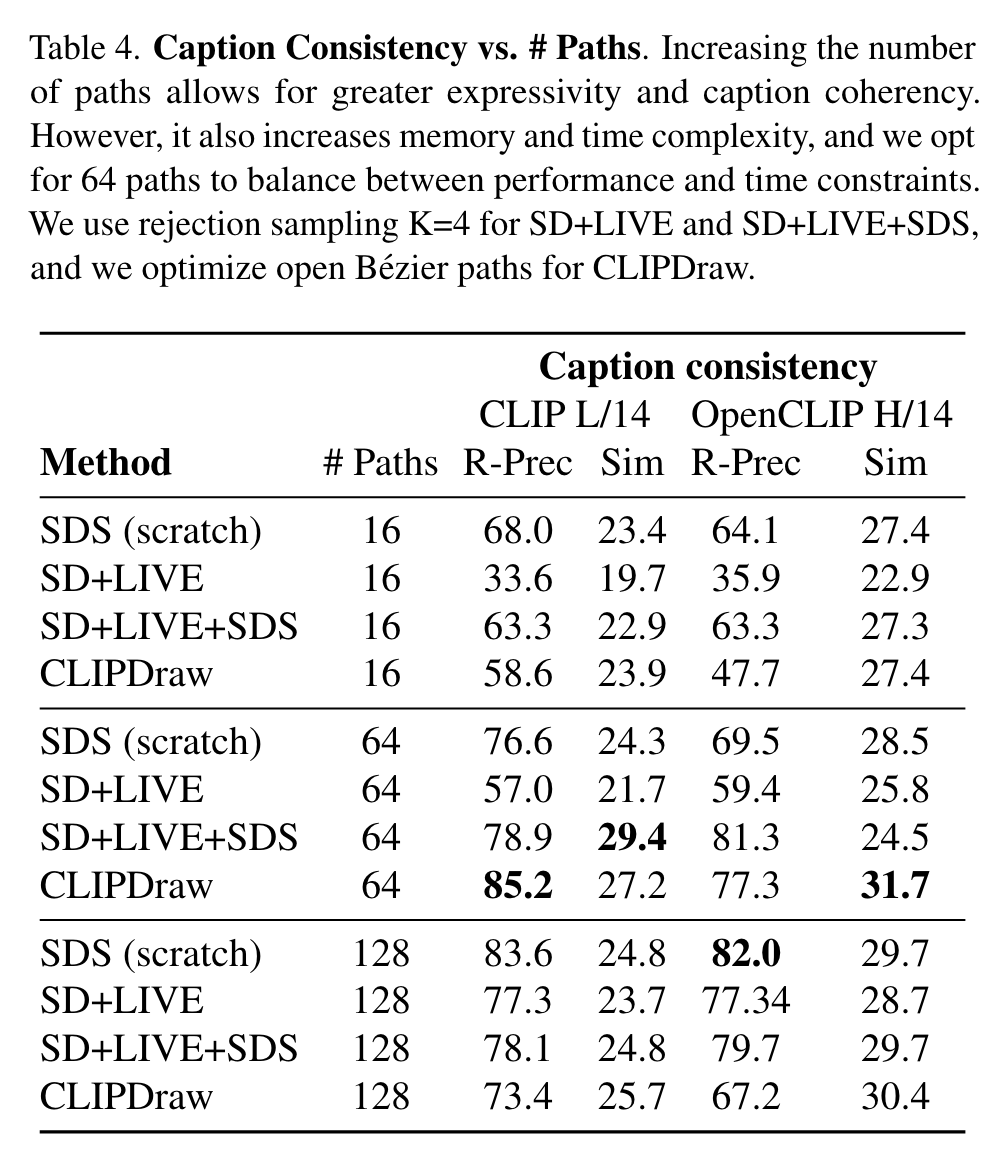
Number of paths
Consistency improves with more paths, but there are diminishing returns. (p. 11)
Number of rejection samples
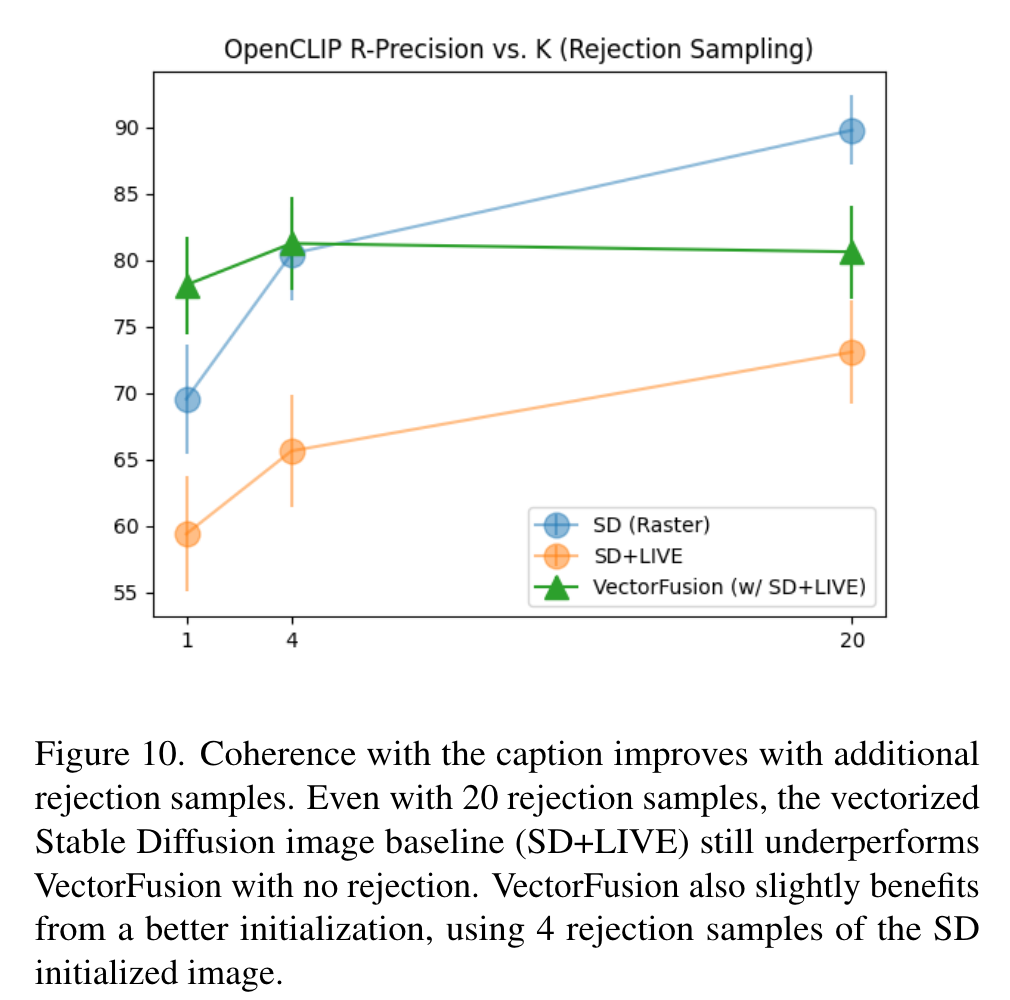
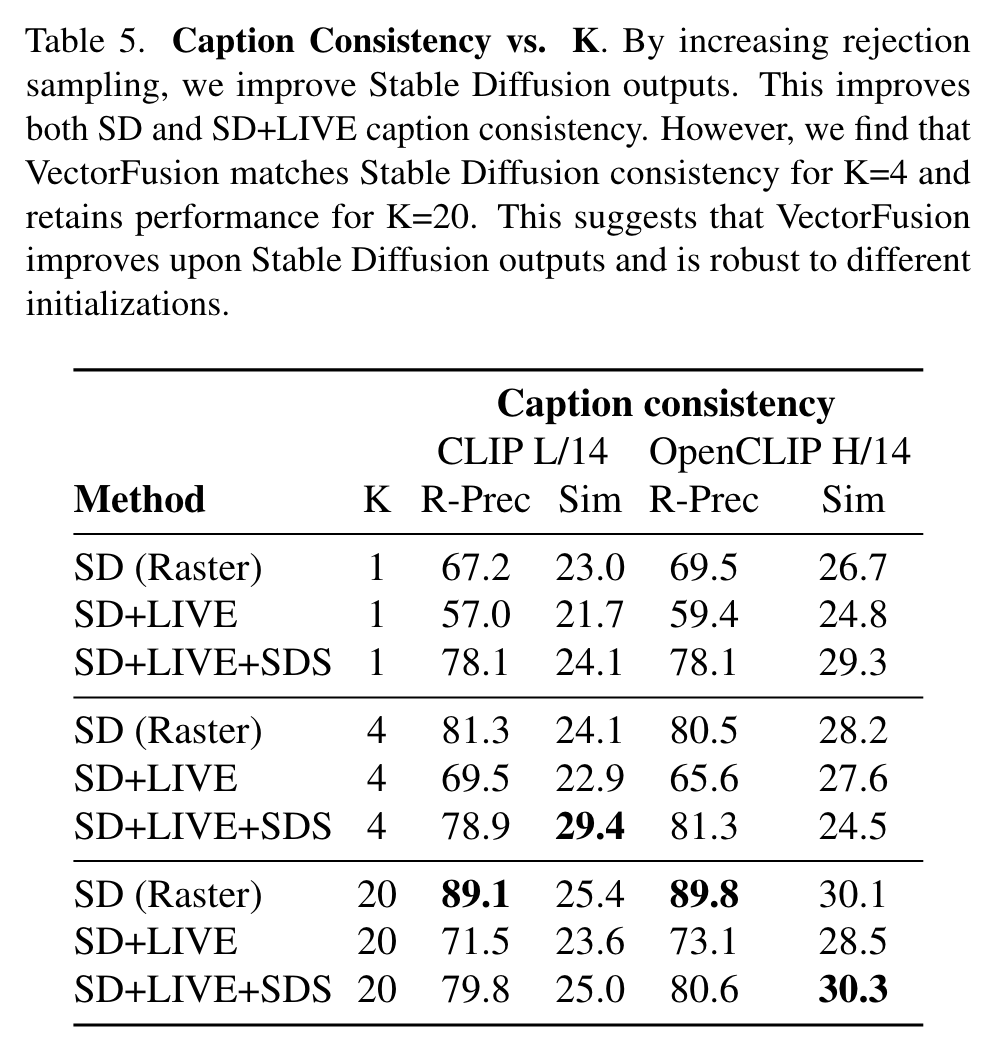
Rejection sampling greatly improves coherence of Stable Diffusion raster samples with the caption, since rejection explicitly maximizes a CLIP image-text similarity score. In contrast, VectorFusion is robust to the number of rejection samples. Initializing with the vectorized result after 1-4 Stable Diffusion samples is sufficient for high SVG-caption coherence. (p. 11)
Pixel Art Results
Simply pixelating the best of K Stable Diffusion samples (SD+L1) is a straightforward way of generating pixel art, but results are often unrealistic and not as characteristic of pixel art. For example, pixelation results in blurry results since the SD sample does not use completely regular pixel grids. Finetuning the result of pixelation with an SDS loss, and an additional L2 saturation penalty, improves OpenCLIP’s RPrecision +10.2%. Direct CLIP optimization achieves high performance on CLIP R-Precision and CLIP Similarity, but we note that like our iconographic results, CLIP optimization often yields suboptimal samples. (p. 12)