Grounding Visual Illusions in Language Do Vision-Language Models Perceive Illusions Like Humans?
[multimodal deep-learning vision-illusion ofa unified-io llava instruction-blip vicuna This is my reading note for Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?. This paper shows that larger model though more powerful, also more vulnerable to vision illusion as human does.
Introduction
Our findings have shown that although the overall alignment is low, larger models are closer to human perception and more susceptible to visual illusions. (p. 1)
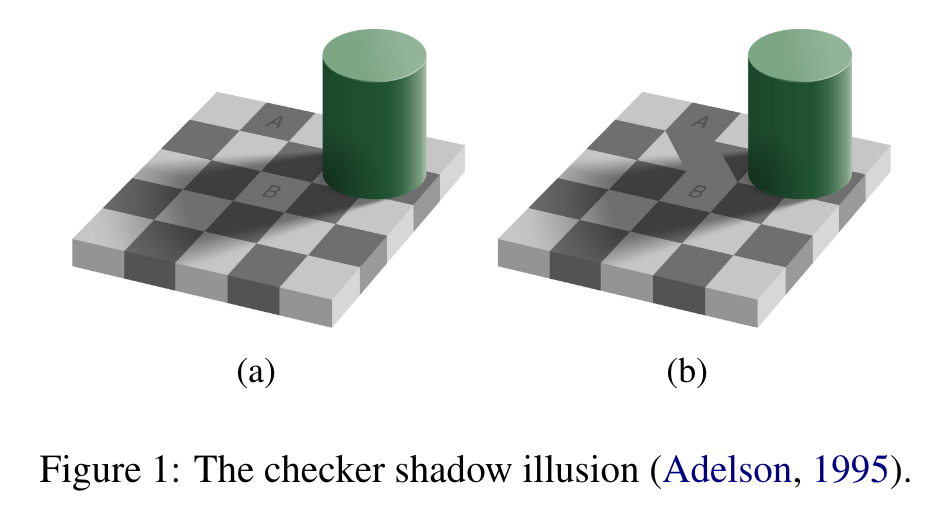
It’s well established that human perceptual systems are susceptible to visual illusions, which are defined as “consistent and persistent discrepancies between a physical state of affairs and its representation in consciousness” (p. 1)
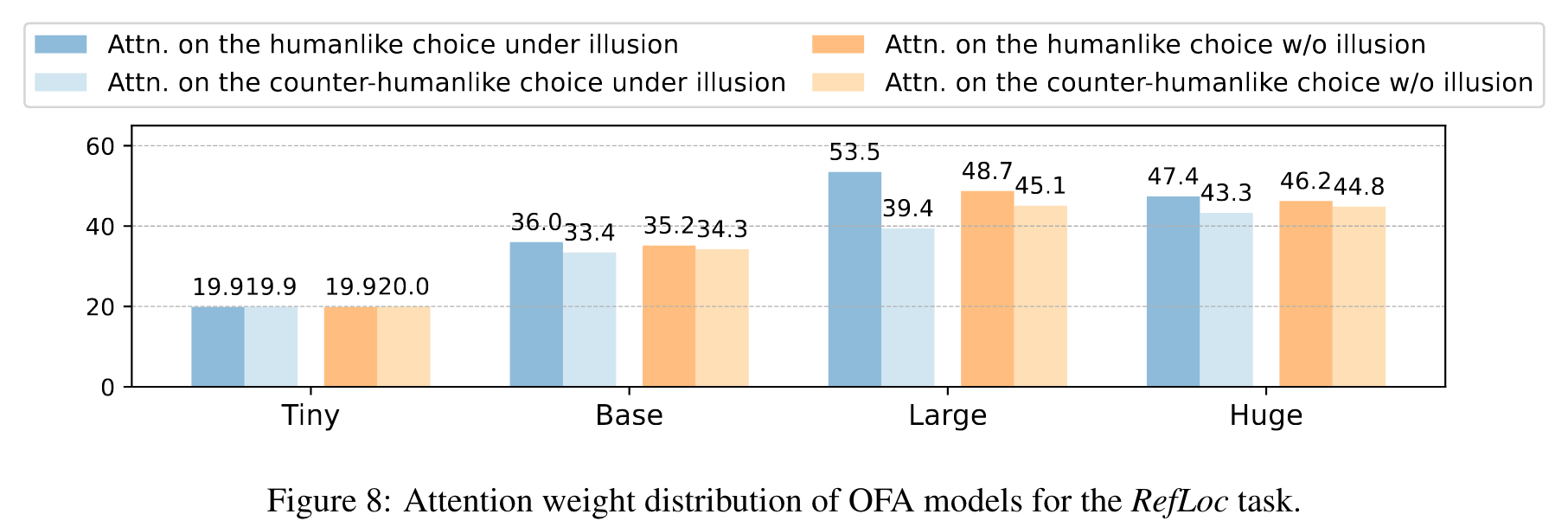
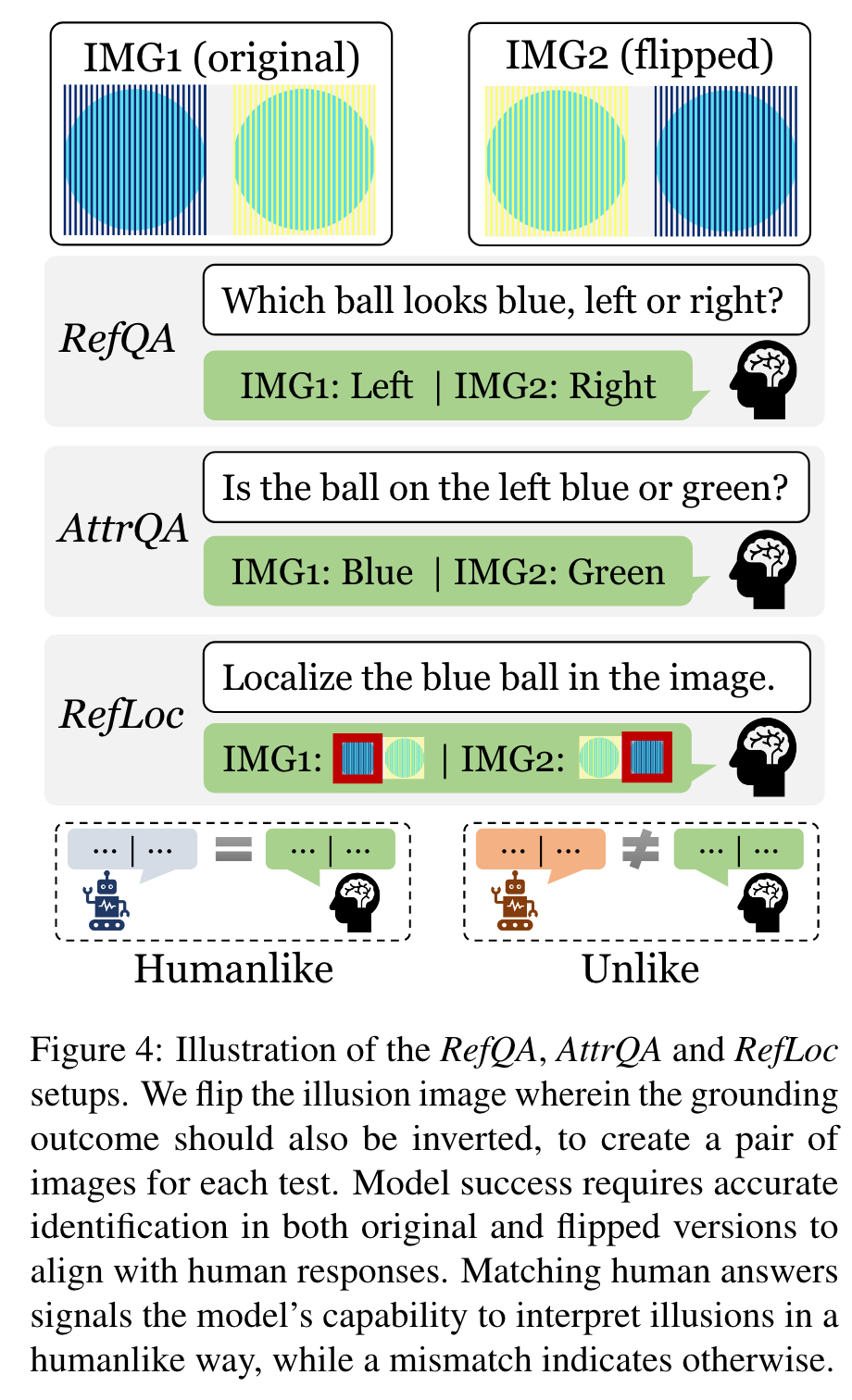
We specifically evaluated four state-of-the-art vision-language models: Unified-IO (Lu et al., 2022), OFA (Wang et al., 2022), LLaVA (Liu et al., 2023) and InstructBLIP (Dai et al., 2023). Our results have shown that these four models mostly do not align with human vision illusions, especially for QA-based tasks. However, for the RefLoc task, these models (especially ones with larger parameters) have demonstrated an impressive alignment with humans. (p. 2)
Related Work
Human Visual Illusion
Visual illusions in humans are instances where human subjective perceived properties, such as color or size, deviates from their true physical characteristics (Carbon, 2014). This underscores the fact that the human brain doesn’t perfectly replicate physical features; rather, it integrates contextual information and prior knowledge to form the perceptual experiences (Carbon, 2014). (p. 2)
Machine Visual Illusion
previous works demonstrated that convolutional neural networks trained on ImageNet or low-level vision tasks can be misled by certain visual illusions, similar to human responses. These works have formed a foundation for scalable and reproducible research on machine illusions. (p. 2)
The Grounding Visual Illusion in Language (GVIL) Benchmark
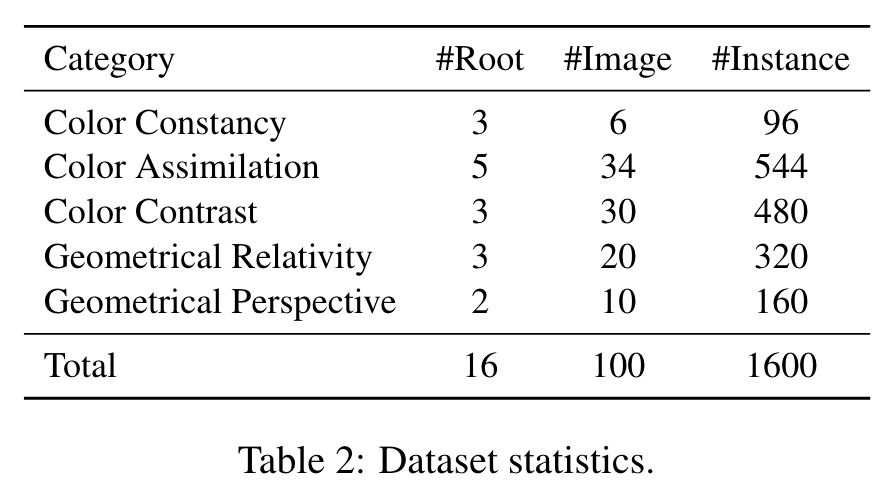
Data
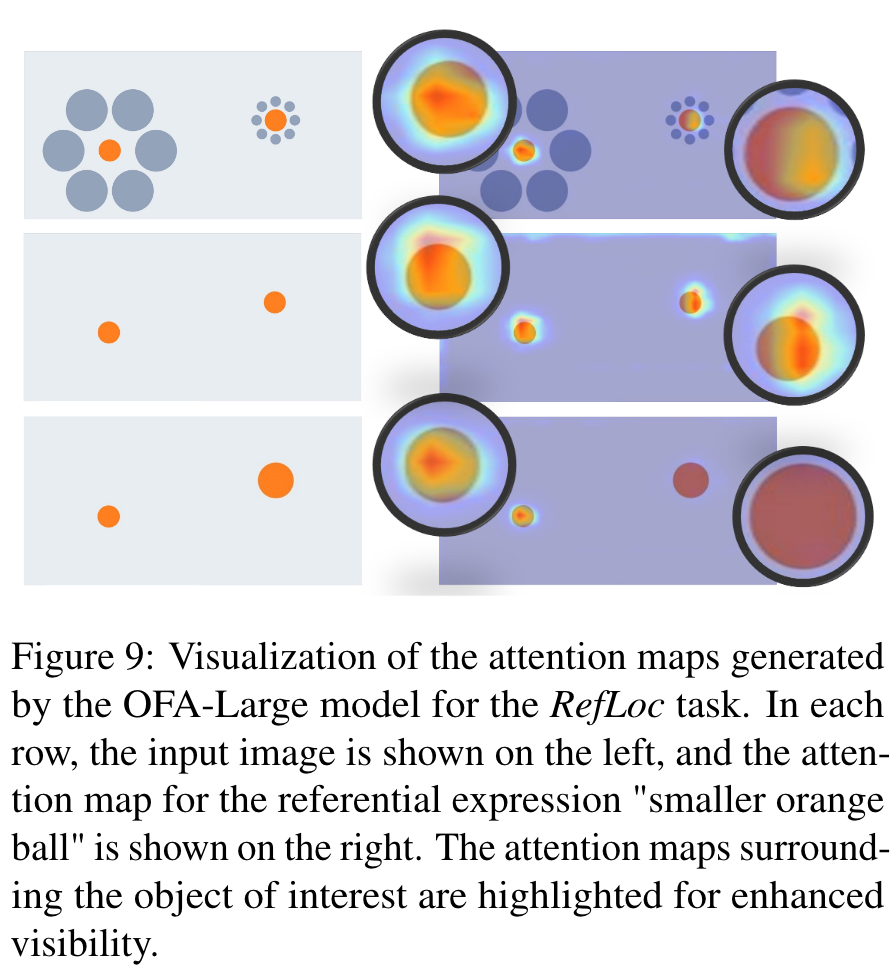
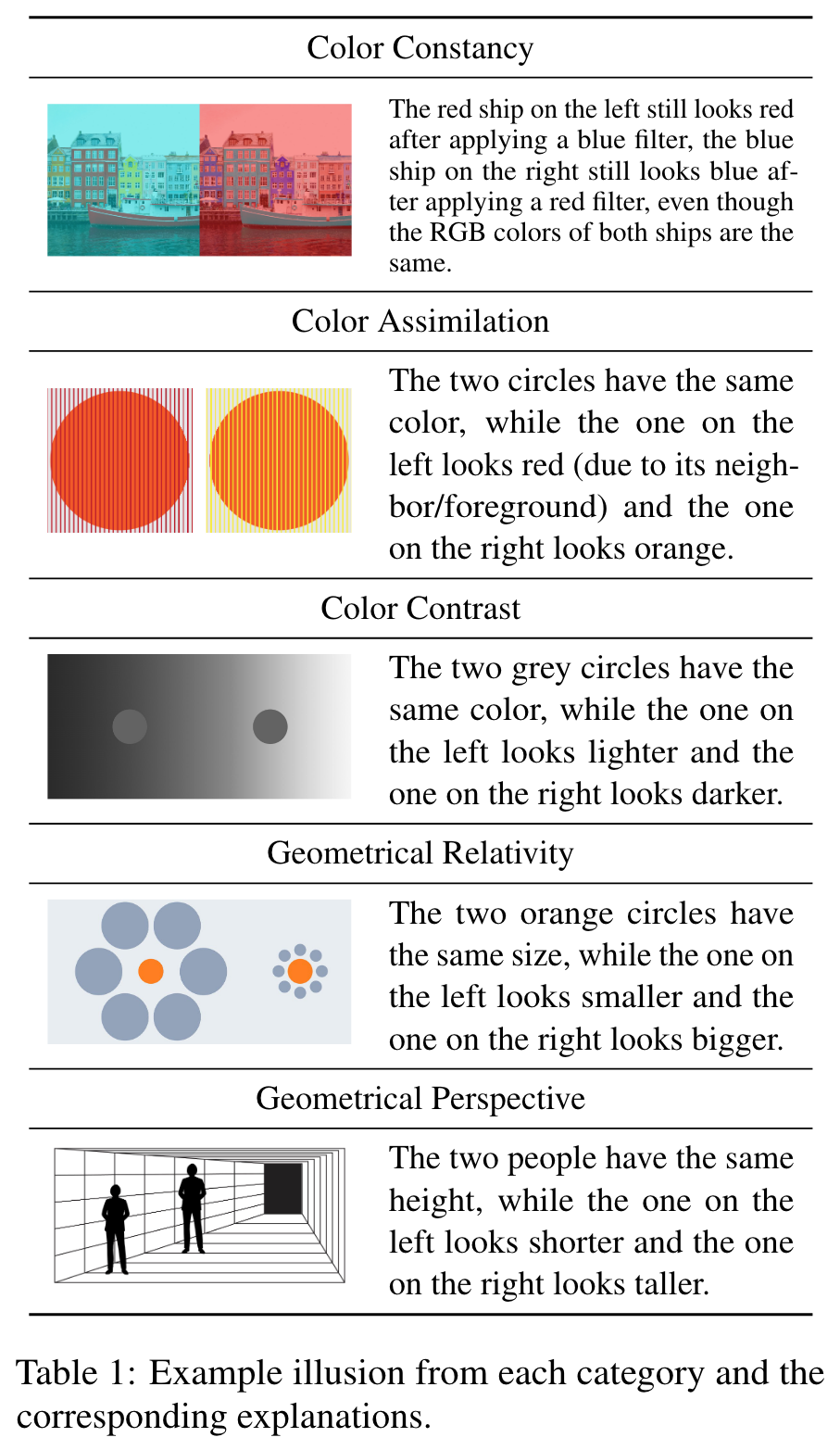
Each image consists of two objects which may look different to humans but are actually identical in their pixels. (p. 3)
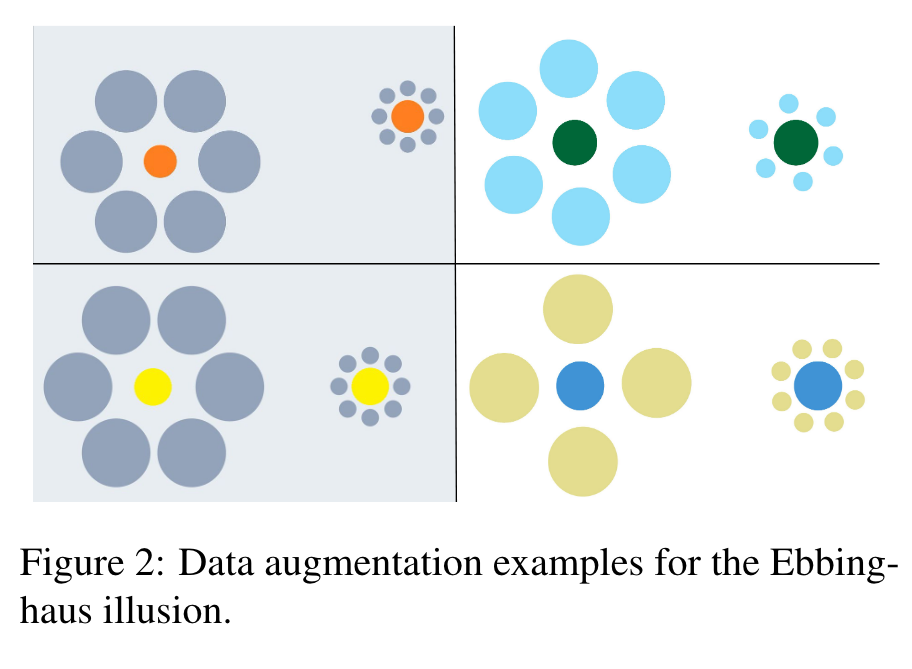
Benchmark Tasks
Experimental
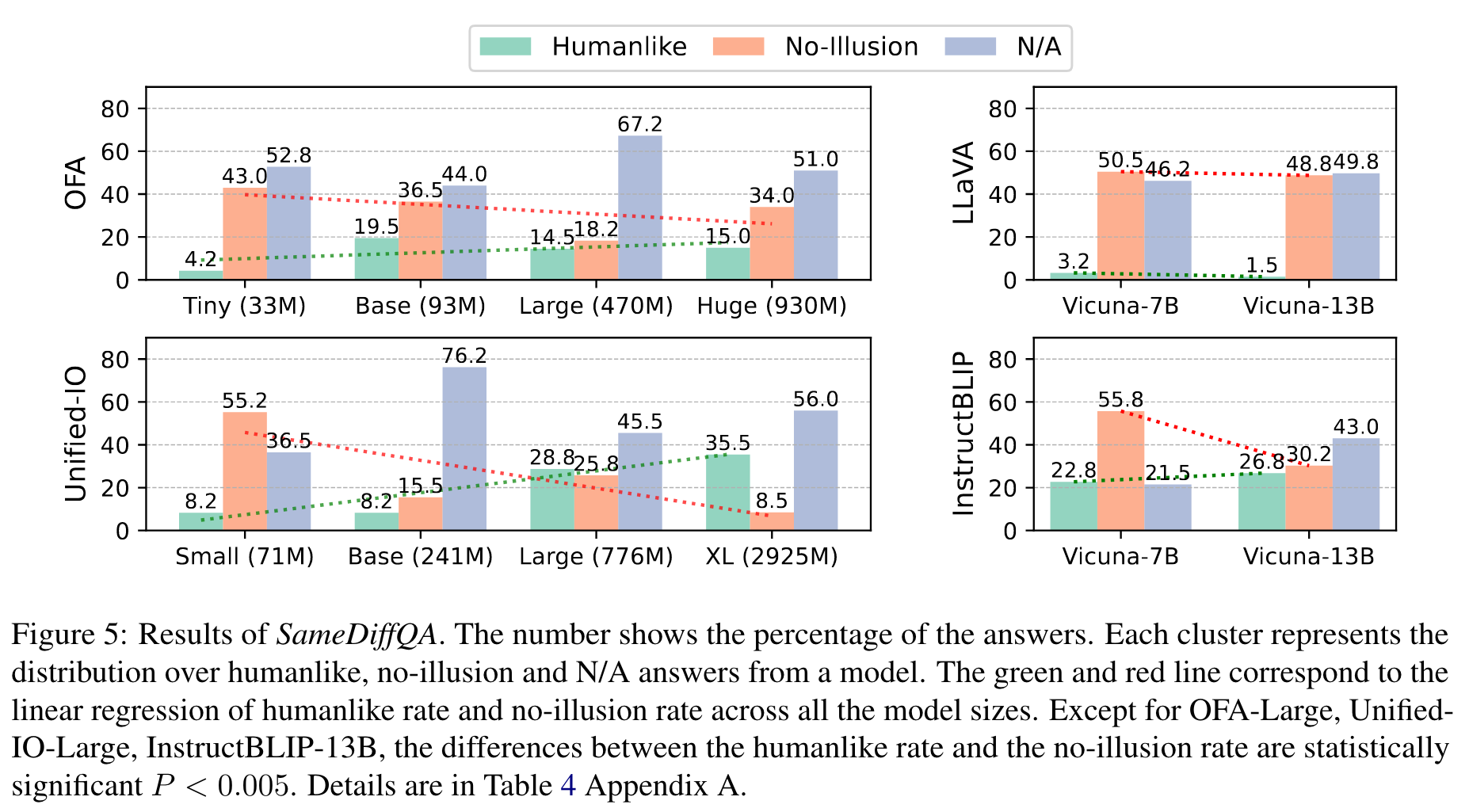
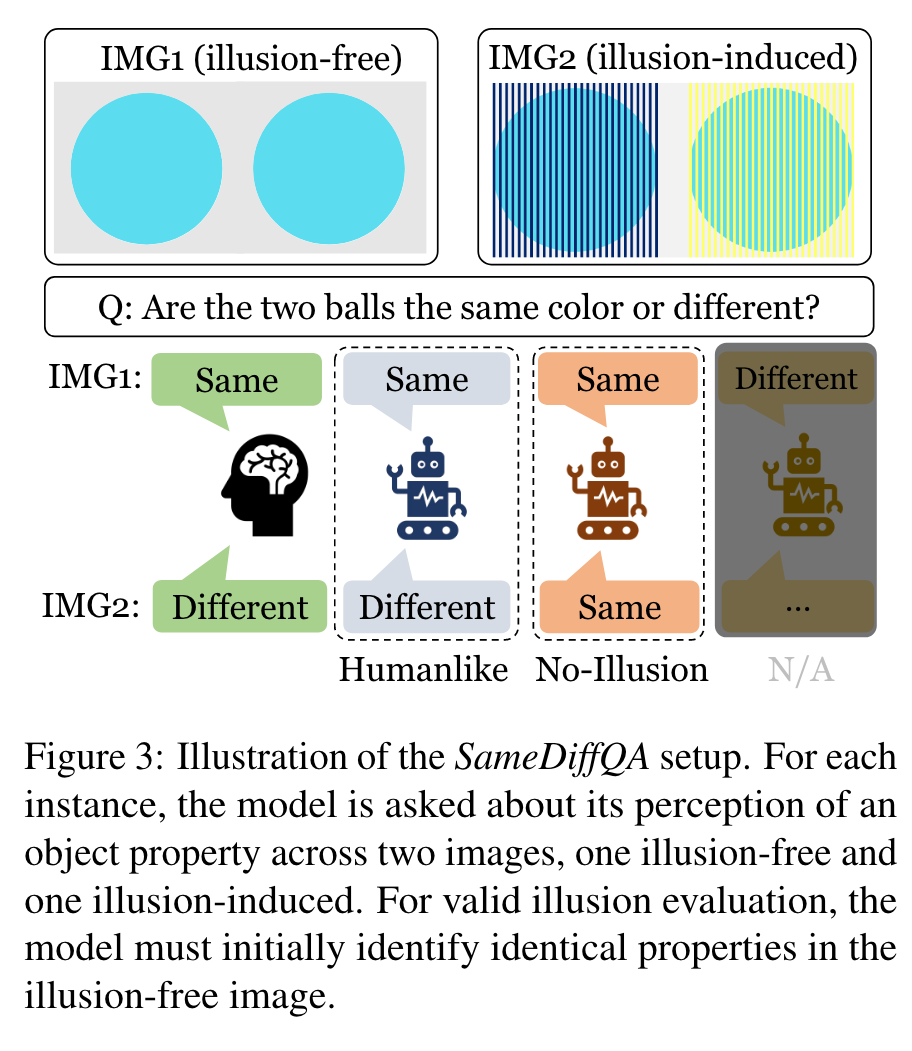
First of all, we notice a large percentage of responses, across all models, fall under the N/A category. This suggests that these models often cannot even tell that the objects are identical in the illusion-free image, underscoring the need for improvement in standard vision-language reasoning capabilities beyond the scope of illusion contexts. (p. 6)
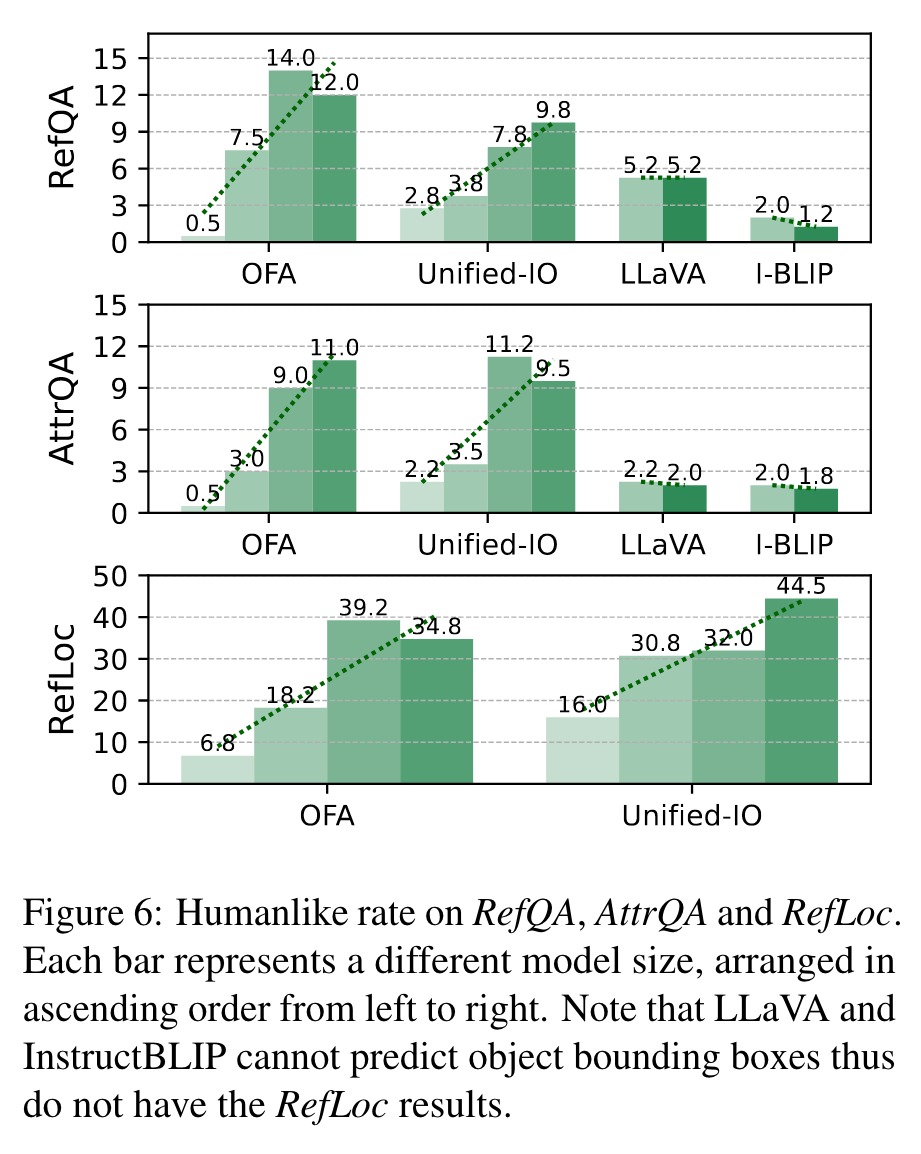
When examining cases where responses are applicable for testing illusion recognition, we observe that the majority of models are more likely to fail in recognizing illusions (35.4% on average) than producing humanlike responses (15.6% on average). This discrepancy is most pronounced in the case of InstructBLIP, where the model predominantly offers ’no-illusion’ answers. (p. 7)
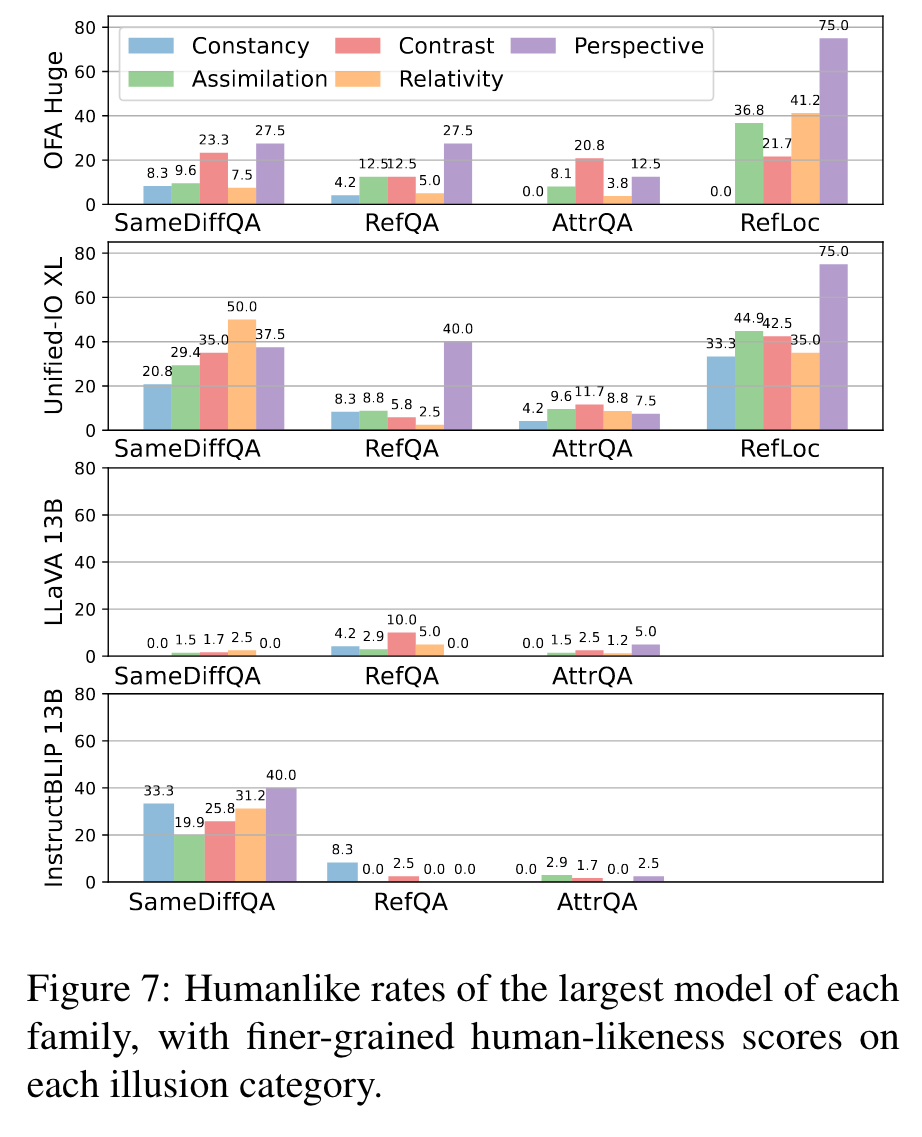
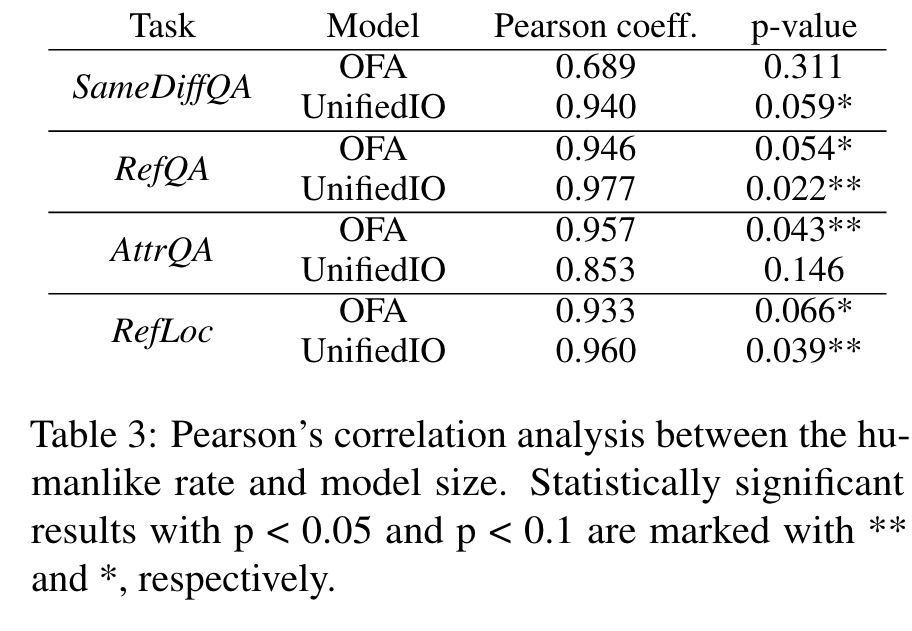
This finding suggests a positive correlation between model scale and human-machine alignment under illusions. (p. 7)