Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency
[cycle-gan multimodal image2image image2text deep-learning cycle-consistency vq-vae text2image sim-vlm clip blip glide vector-quantization dall-e2 self_supervised image-caption muse stable-diffusion cam3leon cobit This is my reading note for Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. The papers proposes a method to train a multi modality model between text and image. Especially, the paper propose cycle consistency loss to leverage unpaired text and image: use image to generate text and use text to recover image and vice verse. It reminds me cycle-GAN paper.
Introduction
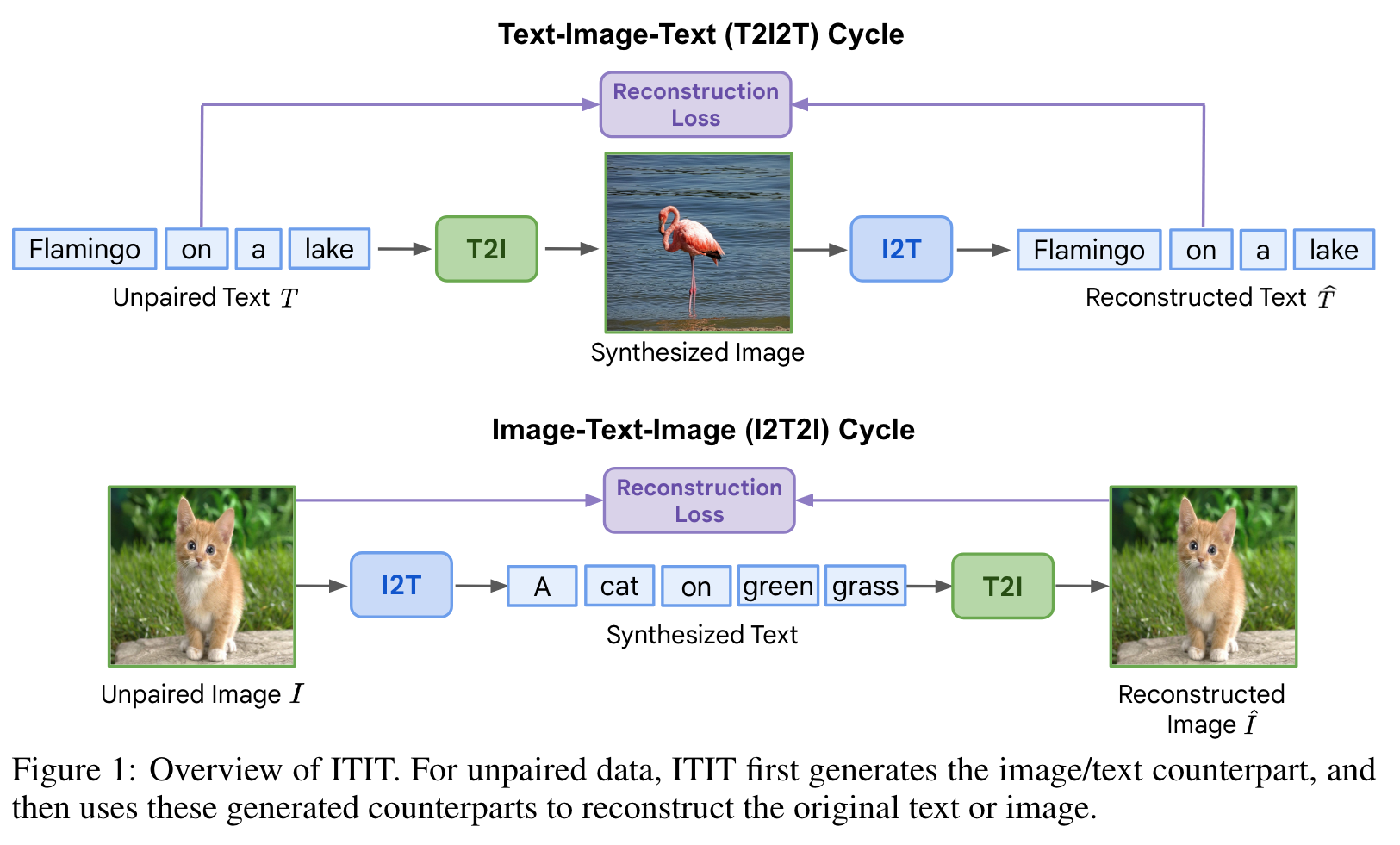
We introduce ITIT (InTegrating Image Text): an innovative training paradigm grounded in the concept of cycle consistency which allows vision-language training on unpaired image and text data. ITIT is comprised of a joint image-text encoder with disjoint image and text decoders that enable bidirectional image-to-text and text-to-image generation in a single framework. During training, ITIT leverages a small set of paired image-text data to ensure its output matches the input reasonably well in both directions. Simultaneously, the model is also trained on much larger datasets containing only images or texts. This is achieved by enforcing cycle consistency between the original unpaired samples and the cycle-generated counterparts. For instance, it generates a caption for a given input image and then uses the caption to create an output image, and enforces similarity between the input and output images. (p. 1)
We consider two kinds of full cycles: T2I2T (starting with an unpaired text sample); and I2T2I (starting with an unpaired image sample). These two types of cycles enable us to leverage both unpaired image and text data to provide informative supervision signals for training. (p. 2)
To enable cycle training, we first unify image-to-text (I2T) and text-to-image (T2I) generation in the same framework, with a bi-directional image-text encoder and disjoint image and text decoders. We tokenize images into discrete visual tokens (Van Den Oord et al., 2017) and combine them with text embeddings from a pre-trained T5 model (Raffel et al., 2020) as input to the joint image-text encoder. For I2T generation, we employ an autoregressive text decoder (Wang et al., 2022a), while for T2I generation we use a non-autoregressive parallel image decoder (Chang et al., 2023), which is an order of magnitude faster than autoregressive image decoders such as Yu et al. (2022b). (p. 2)
To solve this problem, for T2I2T cycle, we first generate the image with parallel decoding. We then back-propagate the gradient through one step of the parallel decoding process. For I2T2I cycle, we first generate the text autoregressively with multiple steps. Then we forward the text decoder once with the generated text as input, and back-propagate the gradient only to this forward step. This significantly reduces the computational overhead of the cycle training, making it feasible to apply in large model settings. (p. 2)
LITERATURE REVIEW
Text-to-Image Generation
Recent works focus on two primary paradigms: diffusion-based models and token-based methods. Token-based strategies transform raw images into image tokens, and predict these tokens either in an autoregressive manner or in parallel Muse (Chang et al., 2023) demonstrates that token-based strategies with parallel decoding can be considerably faster than diffusion-based or autoregressive generative models. Since this speed advantage facilitates text-to-image synthesis during training, we adopt this strategy in our T2I framework. (p. 3)
Unifying Image and Text Generation
COBIT (You et al. (2023)) achieves this by employing distinct image and text unicoders, coupled with a unified cross-modal decoder. Additionally, CM3 (Aghajanyan et al. (2022)) and CM3Leon (Yu et al. (2023)) harness causally masked generative models trained on extensive multi-modal document datasets, and enable the synthesis of both text and images. However, all these works still heavily rely on large-scale paired image-text datasets (p. 3)
Proposed Method
UNIFIED IMAGE-TEXT GENERATION FRAMEWORK
Architecture
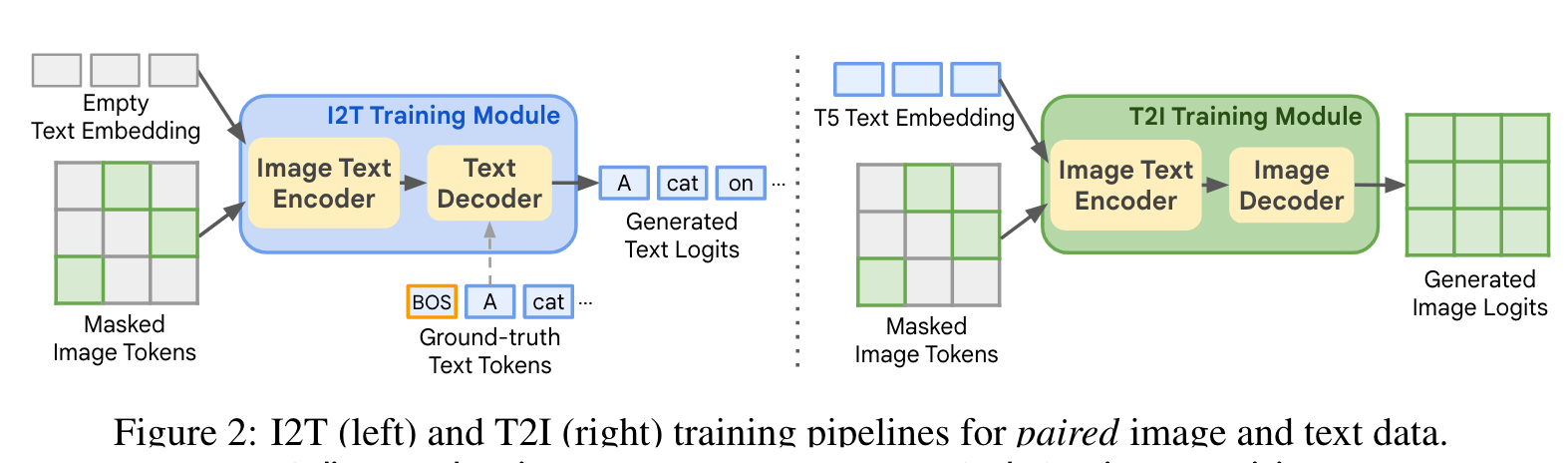
We first obtain text embedding $T=[t_l]{l=1}^L$ from the output of a T5 encoder (Roberts et al., 2019) on the raw text. Similarly, raw images are passed through a pre-trained VQ-tokenizer (Esser et al., 2021) to output image tokens $I=[i_k]{k=1}^K$. L and K are the token sequence lengths for text and image, respectively. The image tokens I are then embedded with an embedding layer and concatenated with the T5 text features T as input to the image-text encoder. Modality-specific decoders then operate on the encoded image-text features to generate either text or image tokens. The text decoder is autoregressive (Wang et al., 2022a), while the image decoder is parallel (Chang et al., 2023). Both encoder and decoders are based on Transformer (Vaswani et al., 2017) layers. (p. 4)
Image-to-Text (I2T) Training
we input masked image tokens along with empty text embedding to the image-text encoder. Masking is used to save computation, similar to MAE (He et al., 2022). We then use the features generated by the image-text encoder, as well as the ground-truth text tokens prepended with [BOS] (begin-of-sentence) token as the input to our text decoder. We use an auto-regressive language modeling (LM) loss to train the encoder and decoder: (p. 4)
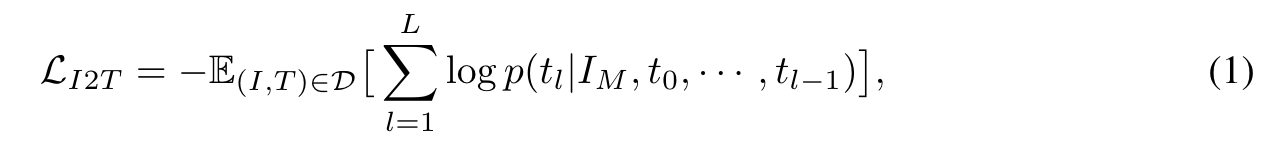
Text-to-Image (T2I) Training
we use masked image modeling for image generation, where the training objective is to reconstruct masked image tokens conditioned on the unmasked image tokens and the paired text features. (p. 4)
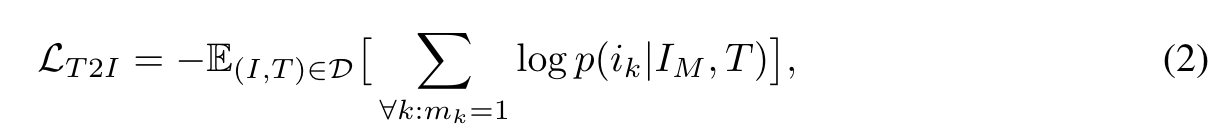
TRAINING WITH CYCLE CONSISTENCY
Our cycle consistency training paradigm allows training with image-only and text-only data. The key idea is to first synthesize the corresponding text/image from the image-only or text-only data, and then use the synthesized data as input to reconstruct the original image/text. This allows us to apply cycle consistency supervision on image-only and text-only data. (p. 4)
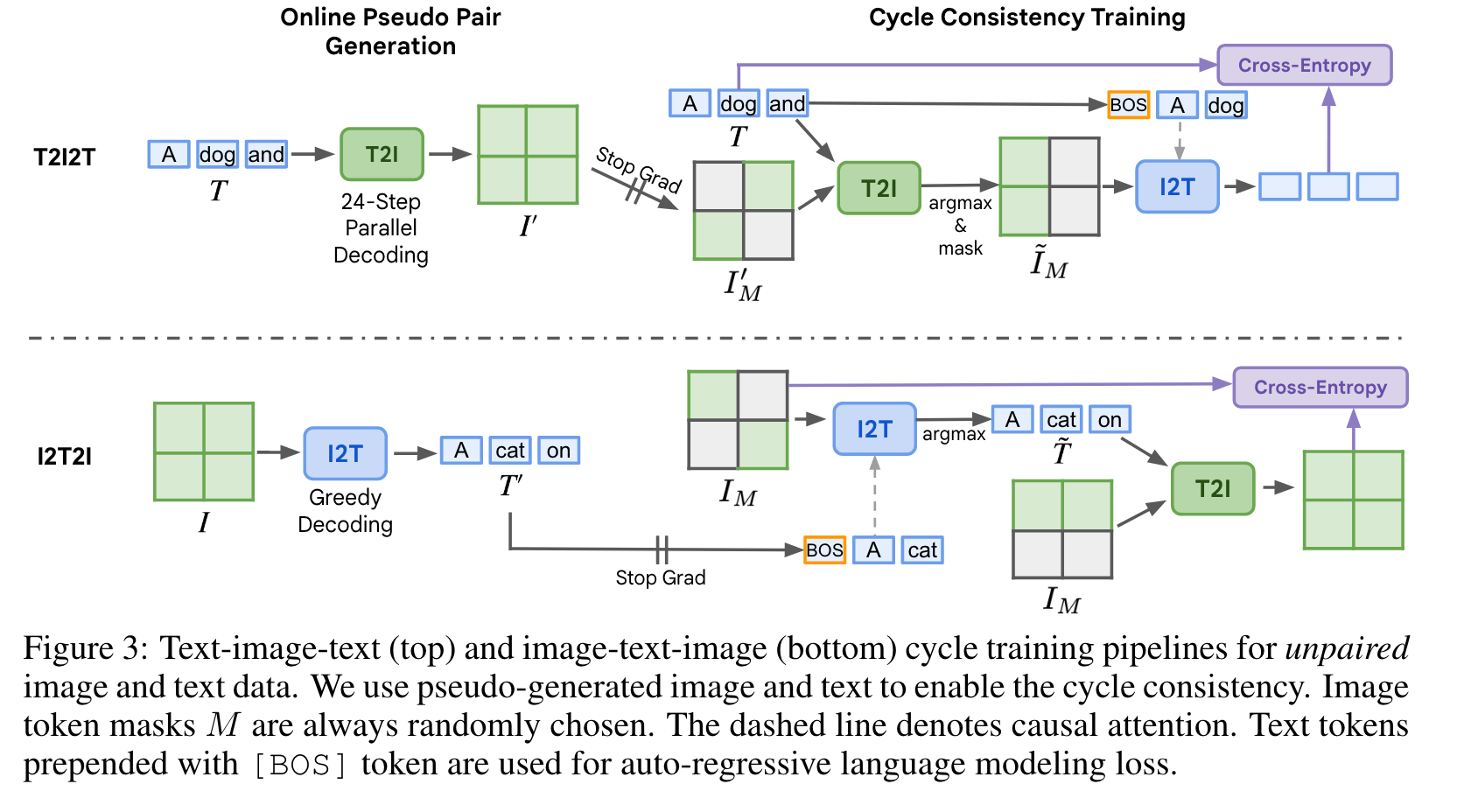
Text-Image-Text (T2I2T) Cycle
At each training iteration, we first synthesize pseudo paired image tokens I′ for input text T = [tl]L l=1 using our T2I inference pipeline. We then apply random mask M to I′, perform reconstruction on I′M with the text T using the T2I pipeline, and obtain the reconstructed synthesized image ˜I. This two-step process allows us to avoid the excessive memory requirements of back-propagating gradients through all 24 steps of parallel decoding, while still training the T2I module. Finally, we randomly mask ˜I and use ˜I_M to generate text using the I2T pipeline. (p. 5)
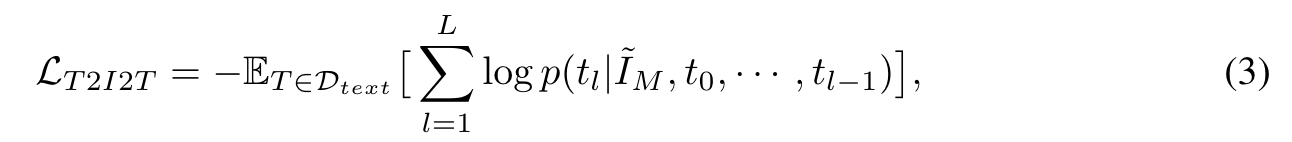
Image-Text-Image (I2T2I) Consistency
Similar to the T2I2T pipeline, we first synthesize pseudo paired text tokens T′ for input image tokens I using our I2T inference pipeline. We then use the I2T training pipeline to predict ˜t_l from t′0, · · · , t′_{l−1} and I_M. As before, this avoids the excessive memory requirements of back-propagating gradients through the auto-regressive greedy decoding. We then mask I, and pass it through the T2I pipeline with the predicted T˜ to reconstruct the masked image tokens. (p. 5)
Gradient Estimation
One challenge in our cycle training is that ˜i_k = arg max(p(i_k|I′M, T) and ˜t_l = arg max p(t_l|I_M, t′_0, · · · , t′{l−1}), which are not differentiable. To solve this, we use a straightthrough estimation on the predicted logits to approximate the gradient. Specifically, we directly copy the gradient on the one-hot prediction to the predicted logits after softmax. (p. 5)
Experiment



Datasets
We use three datasets in our experiments: CC3M (Sharma et al., 2018), WebLI (Chen et al., 2023), and Shutterstock (Shutterstock, 2023). CC3M contains 3.3 million high-quality imagetext pairs. WebLI (Web Language Image) contains 111 million images where the image-text pairing quality is much lower than CC3M. Thus, WebLI is significantly noisier and, as we show, leads to worse performance for I2T. Shutterstock contains 398 million images labeled by human annotators, which incurs significant expense and effort. More dataset details are included in Appendix C. (p. 6)
Training
We set the input image resolution as 256x256 to be consistent with previous literature. After passing through the VQGAN tokenizer, the image token sequence length is 16x16 (256 tokens). The raw text (maximum length of 64) is tokenized by SentencePiece tokenization (SentencePiece, 2023), and embedded using a pre-trained T5 encoder. These embeddings are then concatenated with the image token embeddings as the input to our image-text encoder. (p. 6)
SCALE WITH DATA
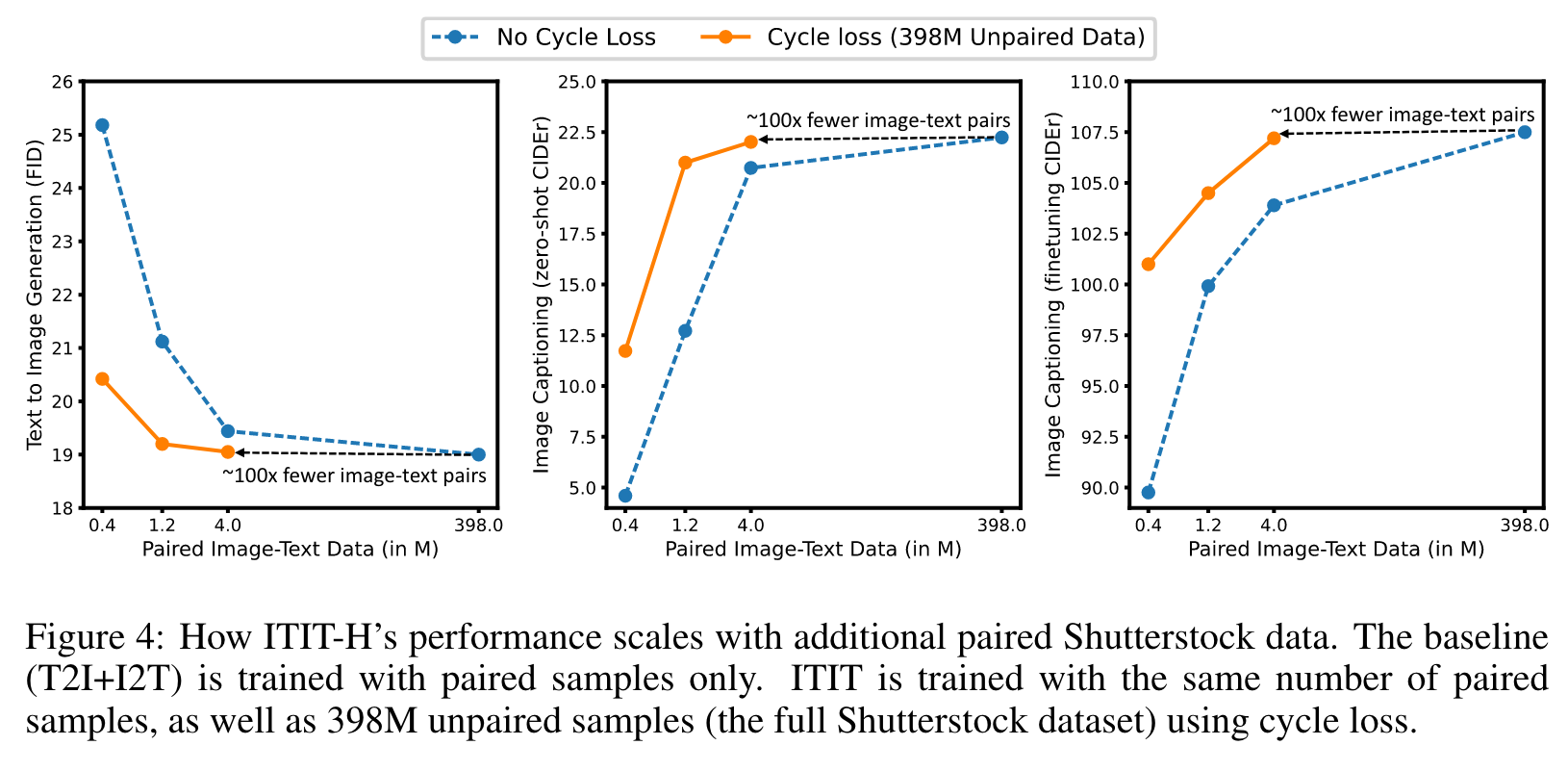
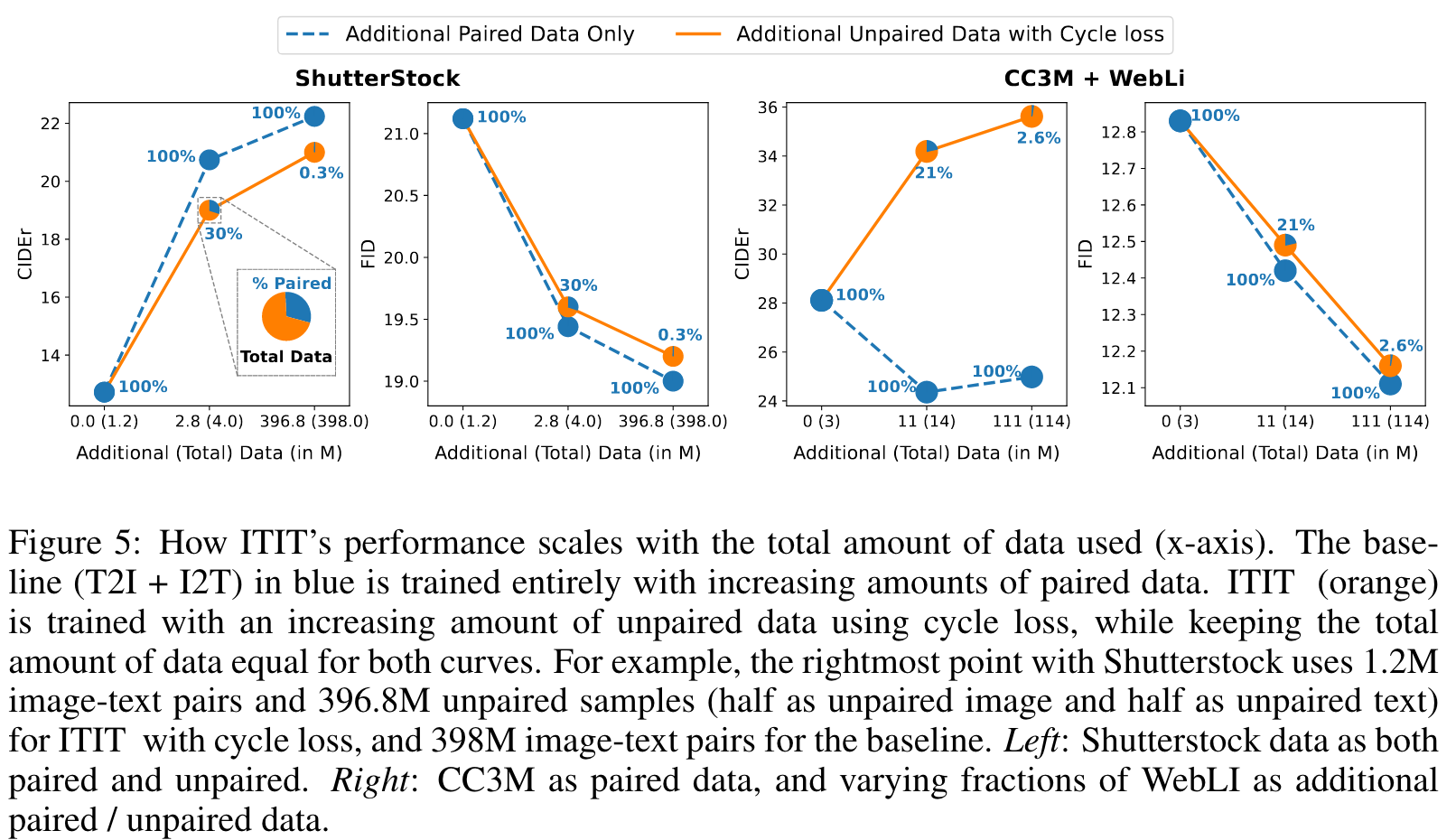
As shown in Figure 5, right pair, adding low-quality image-text pairs harms image captioning performance severely for the fully-paired case. However, the ITIT regime is not affected by this low quality and scales similarly as before. This demonstrates that our method is robust to low data quality in large datasets, and can in fact be used to achieve significantly better performance in settings when paired data is present but of low quality (p. 7)
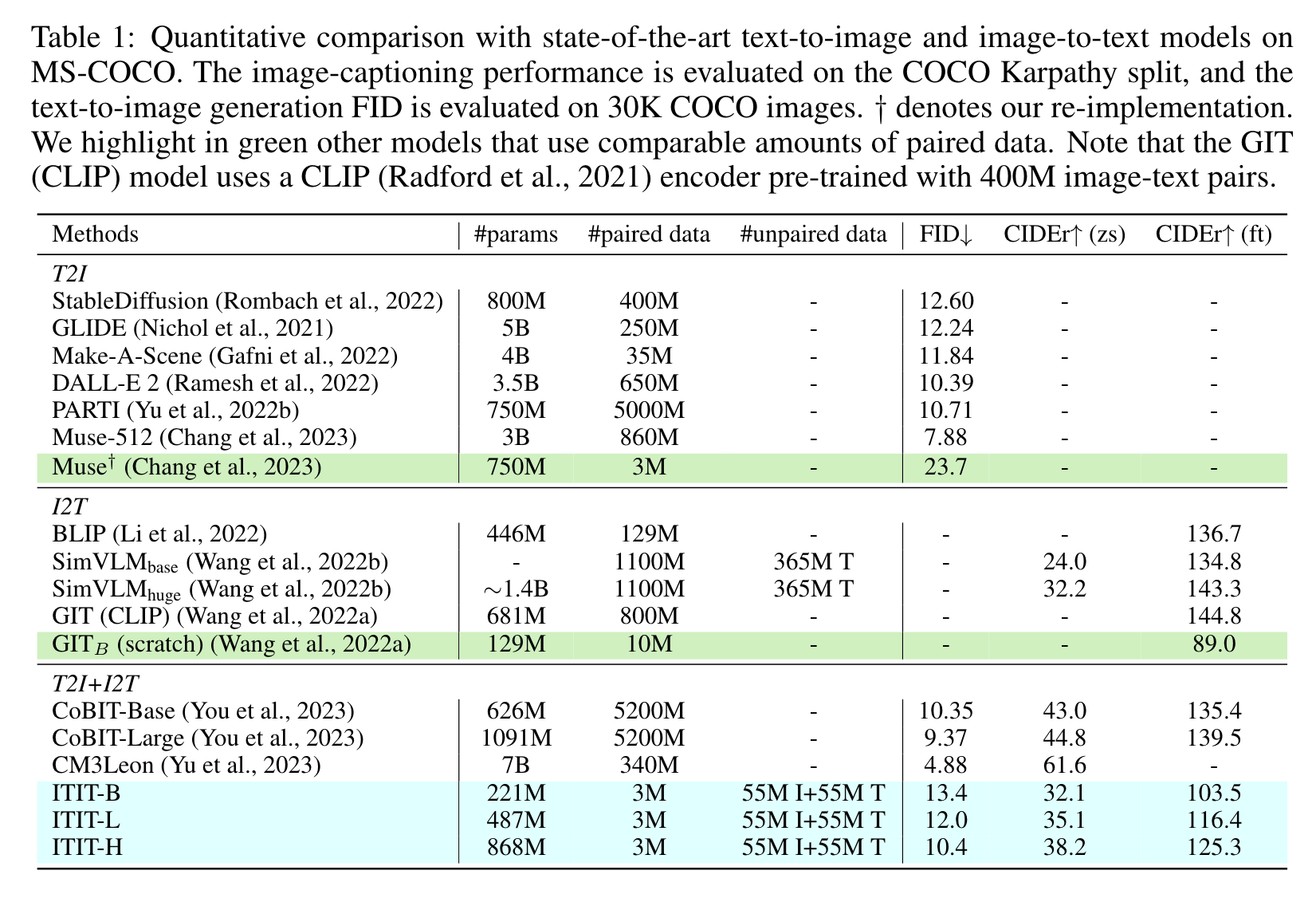
COMPARISON TO PRIOR WORK
ABLATIONS
As shown in rows 1-3, combining T2I and I2T training in our framework already improves image captioning performance. This is likely because the T2I training alleviates the overfitting problem of I2T training, as shown in GIT (Wang et al., 2022a). (p. 8)
As before (Figure 5), we can see in row 4 that combining CC3M and WebLI improves text-to-image generation, but harms image captioning performance. This is because of the lower image-text pairing quality of WebLI compared to CC3M. (p. 8)
We consider an ablation where the gradient of the cycle consistency loss is backpropagated up until the argmax step. Hence, only half of the cycle is trained. In fact, this is equivalent to first synthesizing an image counterpart from unpaired text and then using it as a pseudo image-text pair to train the I2T model (similarly for T2I). Rows 8-10 show that the half-cycle loss achieves much better performance than non-cycle baselines. (p. 8)
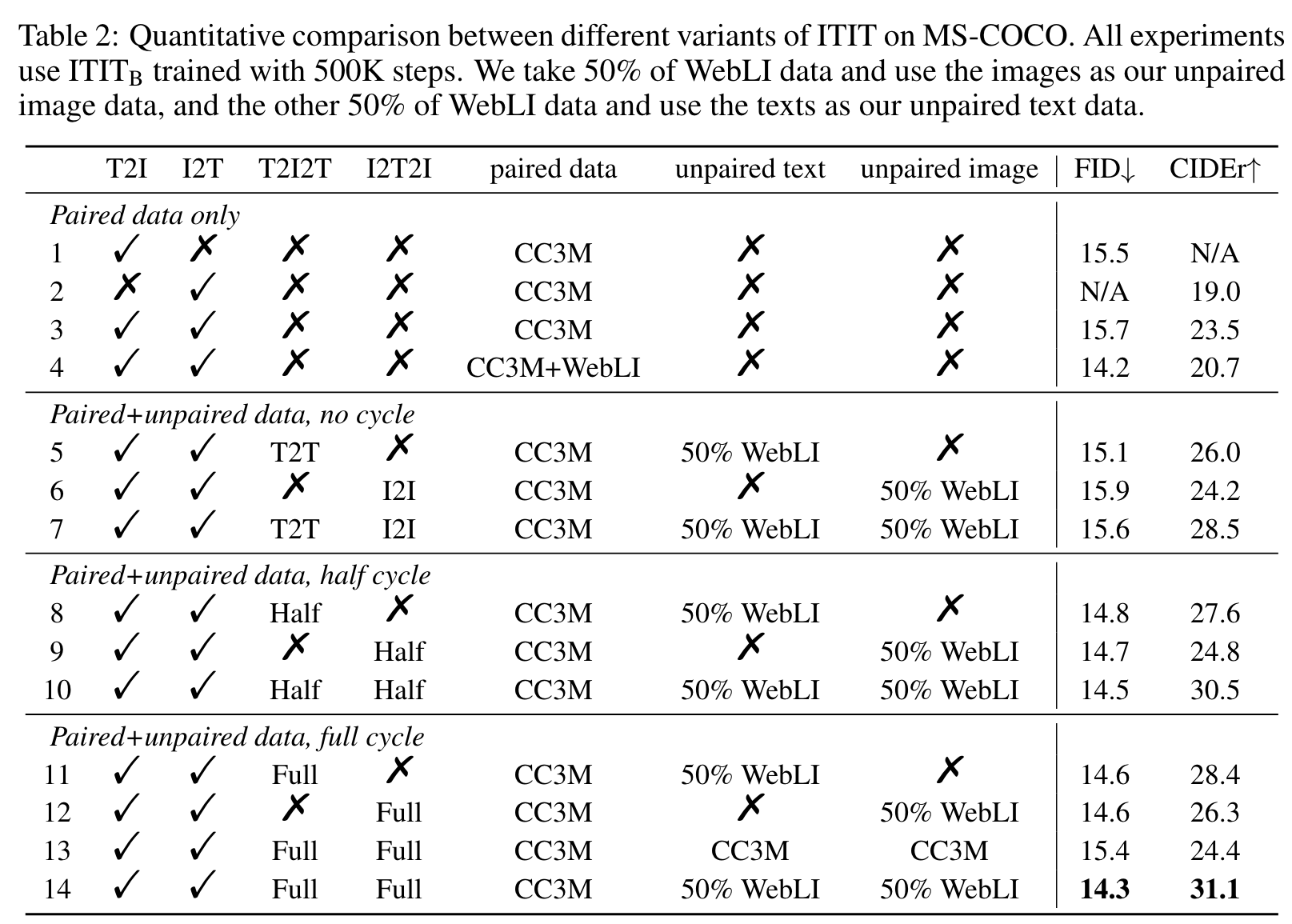
Finally, rows 11-14 show the performance of the full cycle ITIT training. Although T2I2T favors image captioning while I2T2I favors text-to-image generation, they both show significant improvement in text-to-image generation and image captioning. Moreover, row 14 demonstrates that such two cycle losses can be combined to further improve performance. Additionally, we can see that the full cycle loss beats the half-cycle baselines (row 8-10), demonstrating the effectiveness of the gradient estimation step. (p. 9)
Lastly, we find by comparing row 3 and 13 that the cycle consistency loss can slightly improve the performance even without any additional data. We believe this is because it forces better imagetext alignment. However, comparing row 13 and 14 shows that the huge improvements in both text-to-image and image-to-text generation mainly stem from the usage of additional unpaired data. (p. 9)