Tag: vq-vae
- TEAL Tokenize and Embed ALL for Multi-modal Large Language Models (06 Nov 2023)
This is my reading note for TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models. This paper proposes a method of adding multi modal input and output capabilities to the existing LLM. To this end, it utilizes VQVAE and whisper to tokenize the image and audio respectively. Only The embedded and projection layer is trained . The result is not SOTA.
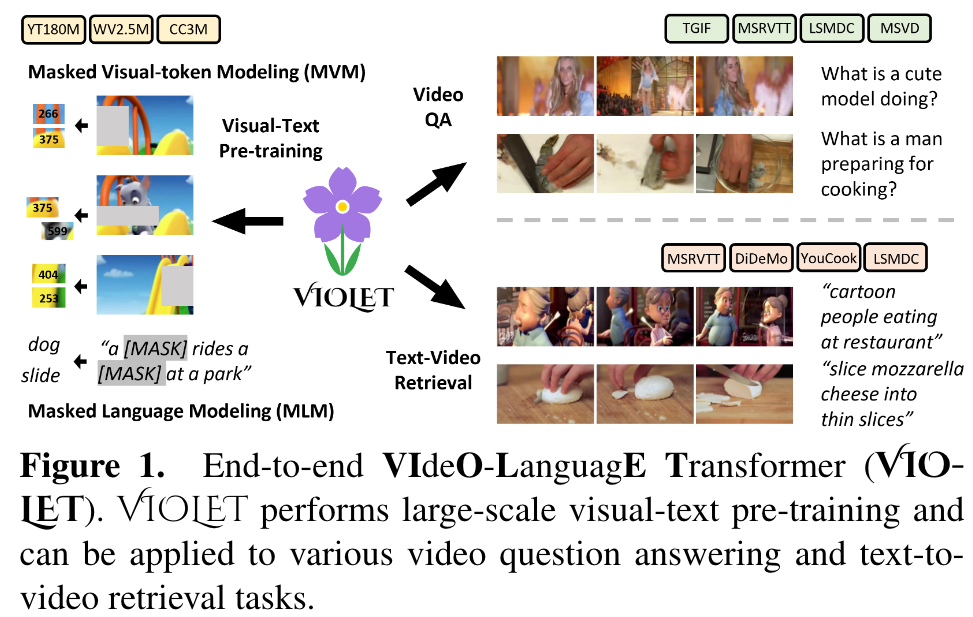
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency (04 Oct 2023)
This is my reading note for Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. The papers proposes a method to train a multi modality model between text and image. Especially, the paper propose cycle consistency loss to leverage unpaired text and image: use image to generate text and use text to recover image and vice verse. It reminds me cycle-GAN paper.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- Jointly Training Large Autoregressive Multimodal Models (28 Jul 2023)
This is my reading note for Jointly Training Large Autoregressive Multimodal Models. This paper proposes a multimodality model for generating images. The paper is not just dilution based method but instead auto regressive method.it argues to initialize the model from the weight of frozen models.
- Make-An-Audio Text-To-Audio Generation with Prompt-Enhanced Diffusion Models (23 Jul 2023)
This is my reading note for Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. This paper proposes a diffusion model for audio, which uses an auto encoder to convert audio signal to a spectrum which could be natively handled by latent diffusion method.
- Scaling Laws for Generative Mixed-Modal Language Models (22 Jun 2023)
This is my reading note for Scaling Laws for Generative Mixed-Modal Language Models. This paper provides a study of scaling raw on dataset size and model size in multimodality settings.