Video Language Planning
[llm multimodal deep-learning robot plan This is my reading note for Video Language Planning. This paper proposes to combine a video-language model and text to video generation model for visual planning: video-language models creates a execution plan given an image as current state and a text as the goal; text-to-video generation model generates a video given the plan; finally video-language models validated the plan via the generated videos.
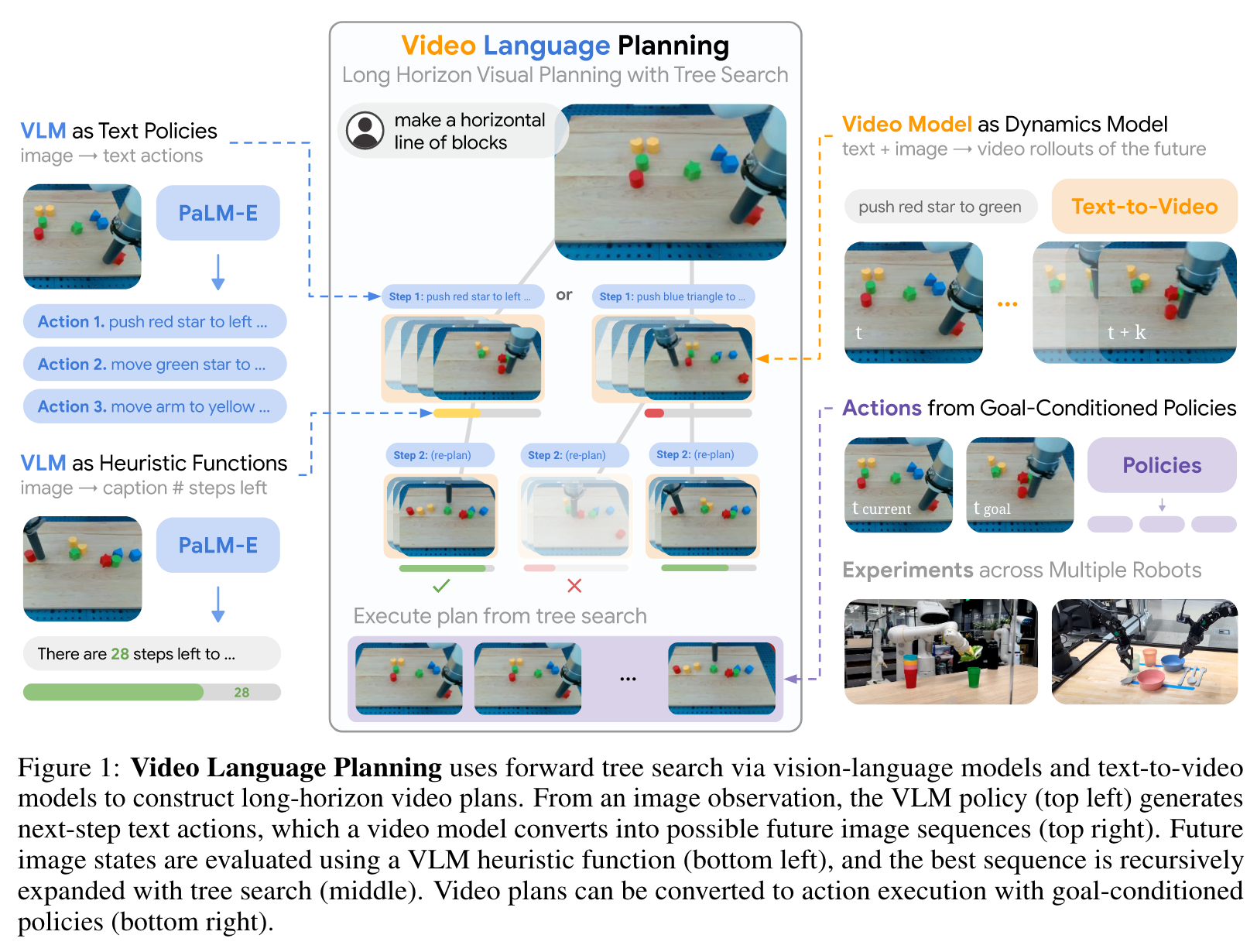
Introduction
To this end, we present video language planning (VLP), an algorithm that consists of a tree search procedure, where we train (i) vision-language models to serve as both policies and value functions, and (ii) text-to-video models as dynamics models. VLP takes as input a long-horizon task instruction and current image observation, and outputs a long video plan that provides detailed multimodal (video and language) specifications that describe how to complete the final task. (p. 1)
Generated video plans can be translated into real robot actions via goal-conditioned policies, conditioned on each intermediate frame of the generated video. (p. 1)
Intelligently interacting with the physical world involves planning over both (i) high-level semantic abstractions of the task (i.e., what to do next), as well as the (ii) low-level underlying dynamics of the world (i.e., how the world works). Factorizing the planning problem into two parts, one driven by task-specific objectives and the other a task-agnostic modeling of state transitions, is an idea that is pervasive and fundamental. (p. 1)
Meanwhile, recent text-to-video models trained on the wealth of videos on the Internet (Villegas et al., 2022; Ho et al., 2022), have demonstrated an ability to learn the dynamics and motions of objects by synthesizing detailed video predictions of the future (Du et al., 2023b) (p. 1)
In this work, we propose to integrate vision-language models and text-to-video models to enable video language planning (VLP), where given the current image observation and a language instruction, the agent uses a VLM to infer high-level text actions, and a video model to predict the low-level outcomes of those actions. Specifically, VLP (illustrated in Fig. 1) synthesizes video plans for long-horizon tasks by iteratively: (i) prompting the VLM as a policy to generate multiple possible next-step text actions, (ii) using the video model as a dynamics model to simulate multiple possible video rollouts for each action, and (iii) using the VLM again but as a heuristic function to assess the favorability of each rollout in contributing task progress, then recursively re-planning with (i). (p. 2)
VLPs exhibit improved grounding in terms of the consistency of scene dynamics in video plans, and when used in conjunction with inverse dynamics models or goal-conditioned policies to infer control trajectories (Du et al., 2023b), can be deployed on robots to perform multi-step tasks – from picking and stowing a variety of objects over countertop settings, to pushing groups of blocks that rearrange them into new formations. (p. 2)
VIDEO LANGUAGE PLANNING

USING VISION-LANGUAGE AND VIDEO MODELS AS PLANNING SUBMODULES
At a high level, we use the multimodal processing power of VLMs to propose abstract text actions ai to execute given goals and images. We then use the dynamics knowledge of video models to accurately synthesize possible future world states xi 1:T when abstract actions are executed. Finally, we use a VLM to process possible future world states xi 1:T and assess which sequence x1:T and associated actions are the most promising to complete a task. (p. 3)
Vision-Language Models as Policies
We implement this policy following Driess et al. (2023) and query the VLM for a natural language action to take given as context the natural language goal and a tokenized embedding of the current image (Fig. 1 Top Left). (p. 3)
In the first, we provide the VLM a set of example text action labels and ask the VLM to predict possible actions to accomplish a goal. In the second, we finetune the PaLM-E model on randomly selected short trajectory snippets x1:S labeled with abstract actions inside a long trajectory x1:H that accomplishes a long horizon goal g. (p. 3)
Video Models as Dynamics Models
We obtain both of these things from a text-to-video model fVM(x, a), which takes an image x and a short horizon text instruction a and outputs a short synthesized video x1:S starting at the image observation x0 (Fig. 1 Top Right) following Du et al. (2023b). We construct this text-to-video model by training on a set of short image trajectory snippets x1:T and associated language labels a. (p. 3)
Vision-Language Models as Heuristic Functions
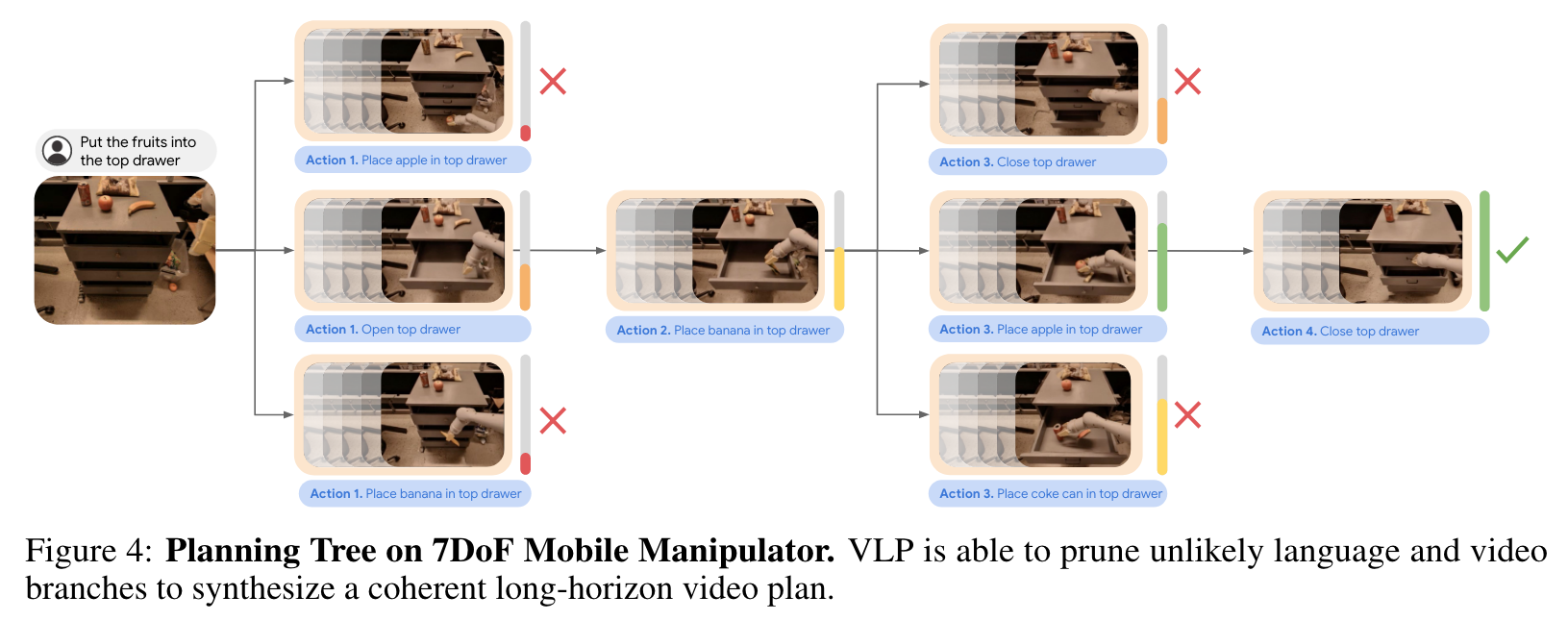
To effectively prune branches in search, we use a VLM to implement a heuristic function HVLM(x, g) which takes as input an image observation x and a natural language goal description g and outputs a scalar “heuristic” predicting the number of actions required to reach a state satisfying goal g from current state x (Fig. 1 Bottom Left). To construct this heuristic function, we finetune a PaLM-E model using long trajectory snippets x1:H which accomplish a long horizon goal g, and train it to predict, given an image in the subtrajectory xt, the number of steps left until the end of the trajectory snippet. (p. 3)
PLANNING WITH VISION-LANGUAGE MODELS AND VIDEO MODELS
directly applying the πVLM to infer text actions a to reach goal g is not sufficient, as πVLM is not able to perform sufficiently accurate long-horizon reasoning to select actions that are helpful in the long run. Instead, we propose to search for a sequence of actions to reach g, corresponding to finding a long-horizon video plan x1:H which optimizes (p. 4)
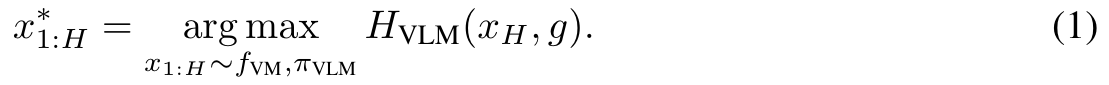
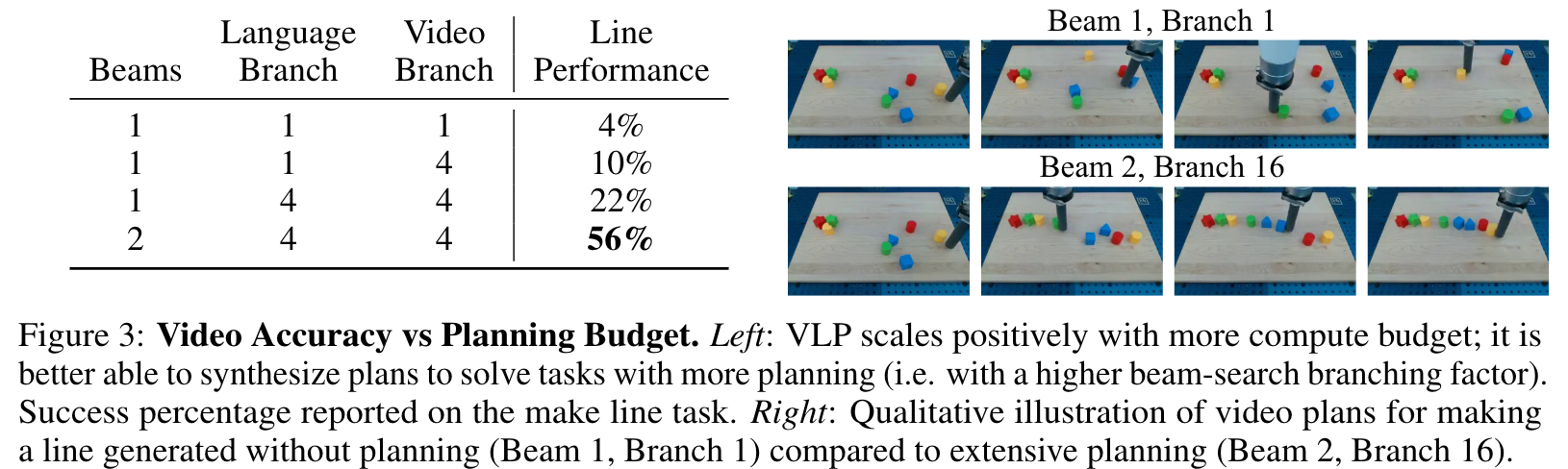
A separate procedure is then used to instantiate control actions u to enact the optimized video plan x∗1:H. To sample long-horizon video plans x1:H, we first synthesize a short horizon video plan x1:S from a starting image x through x1:S = fVM(x, πVLM(x, g)) and autoregressively extend to a full long-horizon video plan by recursively applying fVM(x, πVLM(x, g)) on the final synthesized image state xS. To optimize across video plans in Eqn (1), we use a tree-search procedure based on parallel hill climbing (Selman & Gomes, 2006) (illustrated in Algorithm 1). (p. 4)
Our planning algorithm initializes a set of B parallel video plan beams. At each step of the planning horizon, for each video beam, we first sample a set of A actions using πVLM(x, g), and for each action we synthesize D different videos using fVM(x, a). We then use our heuristic function HVLM(x, g) to select the generated video with the highest heuristic among the A × D generated videos and extend the corresponding video plan beam with this generated video. Over the course of plan generation, certain video plan beams will obtain high heuristic value and be more promising to explore. Therefore, every 5 steps, we discard the beam with the lowest value and replicate its video plan with the beam with the highest value. Our final full long horizon video plan corresponds to the beam with highest heuristic value at the end of planning. (p. 4)
Preventing Exploitative Model Dynamics
For instance, the planning procedure can exploit videos from fVM(x, a) where key objects have teleported to desired locations or where the final image observation obscures undesirable portions of world state. To prevent over-exploitation of HVLM(x, g), during the planning procedure in Algorithm 1, we discard generated videos from fVM(x, a) if they increase the the heuristic estimate HVLM(x, g) above a fixed threshold. (p. 4)
ACTION REGRESSION FROM VIDEO THROUGH GOAL-CONDITIONED POLICIES
For each frame in our video plan x1:H, the goal-conditioned policy is executed for a fixed pre-specified number of timesteps. We train πcontrol using paired image and low level control snippets xi 1:T and ui 1:T , where we sample a random timestep t, a corresponding state xt, and future state xt+h, and train πcontrol(xt, xt+h) to predict ut. (p. 5)
EXPERIMENTAL RESULTS
GENERALIZATION
Generalization to Lighting and Objects
We found that this enables VLP to generalize well, as the video model is able to visually generalize to new images, while the policy is able to generalize well to nearby new visual goals (p. 8)

Generalization to New Tasks

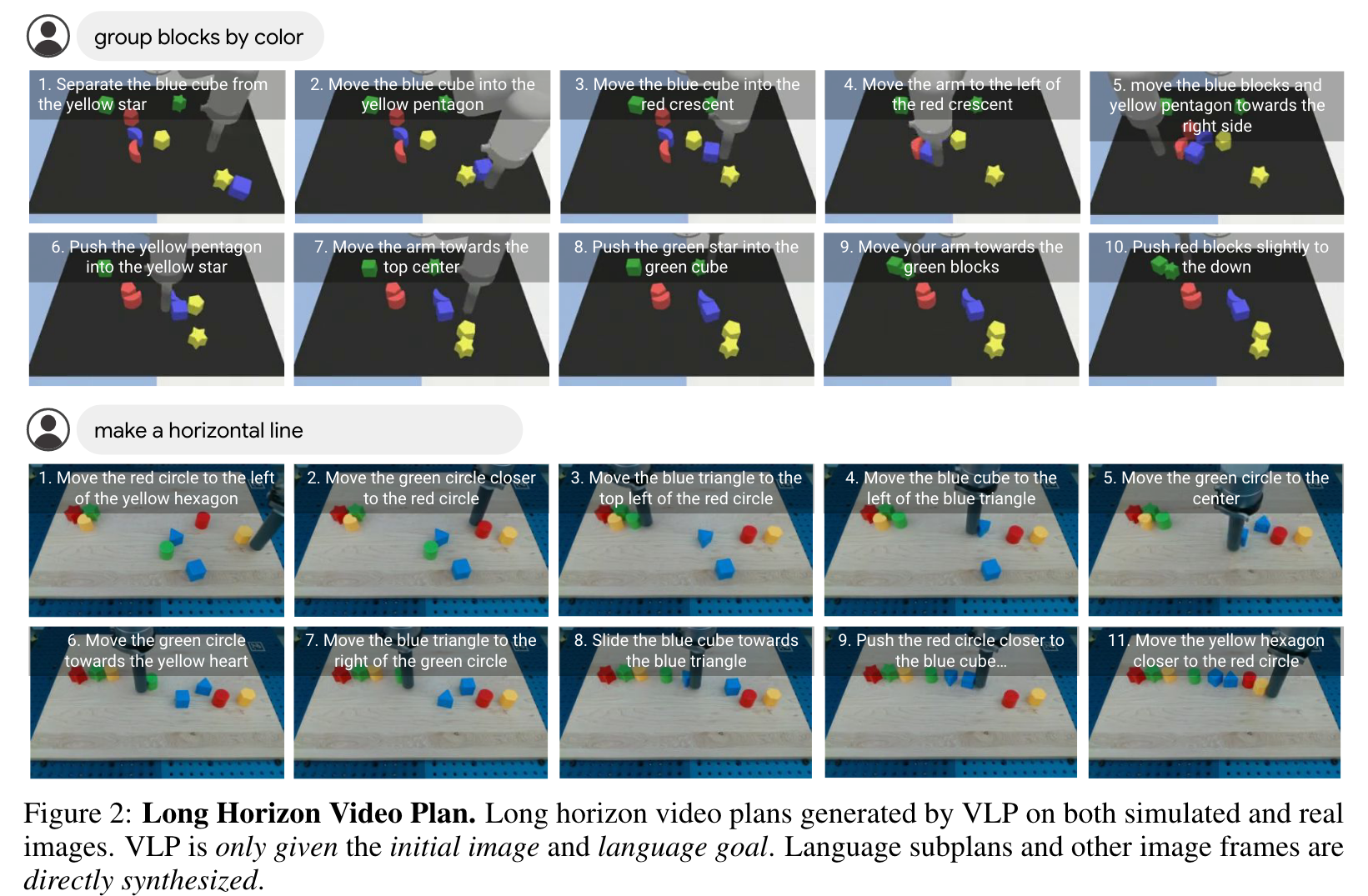
In VLP, both VLM and text-to-video models may be pre-trained on a vast amount of Internet data. In Fig. 10, we train both VLM and text-to-video models on a large mix of datasets and illustrate how it further generalizes and executes new tasks on unseen objects. (p. 9)
LIMITATIONS
In many tasks, this is insufficient as it does not capture the full 3D state and cannot encode latent factors such as physics or mass. Limitations can be partly remedied by generating multi-view videos or by using heuristic function with the full video plan as input. In addition, we observed that our video dynamics model does not always simulate dynamics accurately. In several situations, we observed that synthesized videos would make objects spontaneously appear or teleport to new locations. We believe that larger video models, additional training data or explicit reinforcement learning feedback for physics (Black et al., 2023) could help solve these problems. (p. 10)