SeamlessM4T-Massively Multilingual & Multimodal Machine Translation
[multimodal w2v-bert response-ai review quantization segmentation asr voice-activity-detection text2speech seamlessm4t hubert whisper llm language-identification machine-translation speech-recognition audio self_supervised sonar bert tts nllb read transformer vad laser This is my reading note 2/2 on SeamlessM4T-Massively Multilingual & Multimodal Machine Translation. It is end to end multi language translation system supports multimodality (text and audio). This paper also provides a good review on machine translation. This note focus on data preparation part of the paper and please read SeamlessM4T-data for the other part.
SeamlessM4T Models
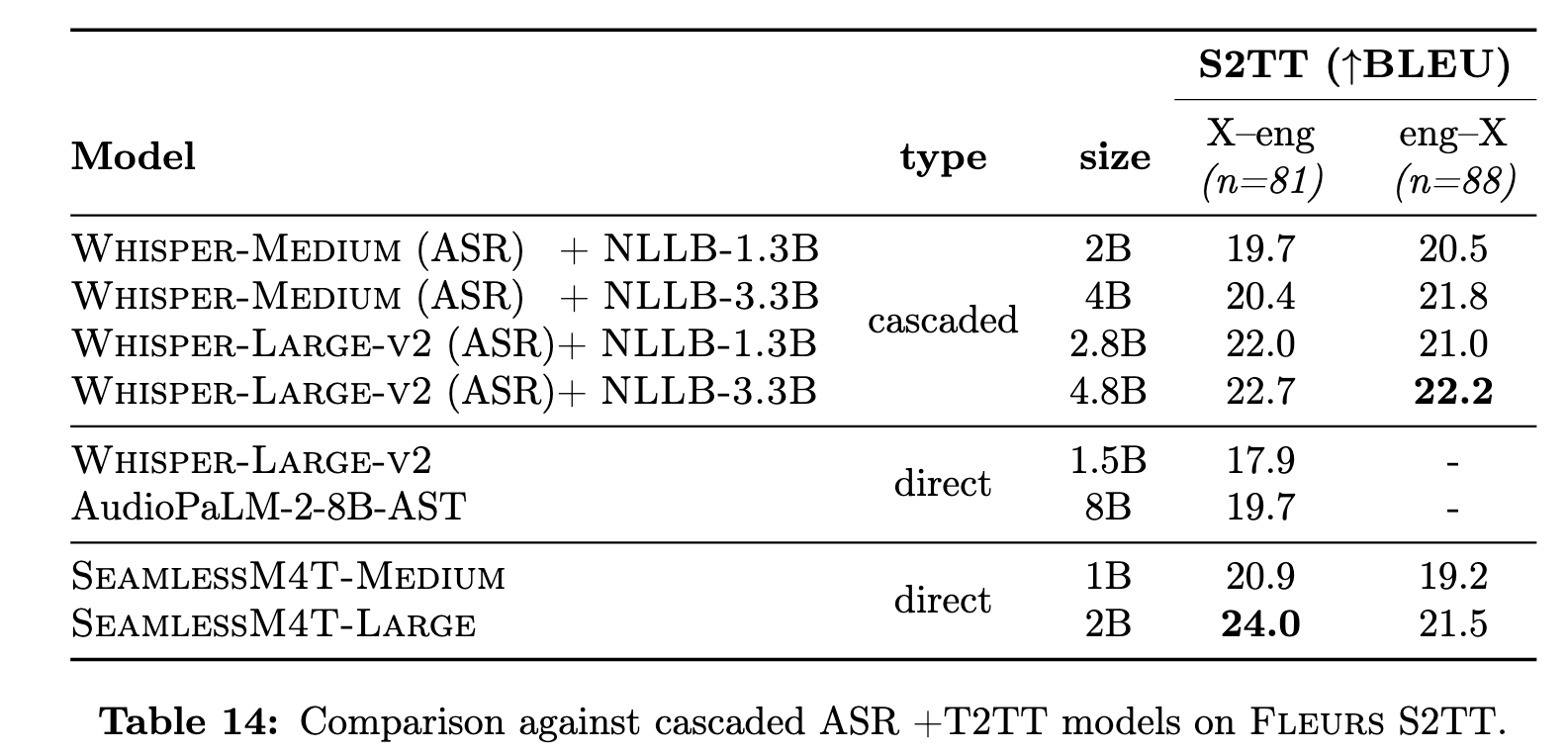
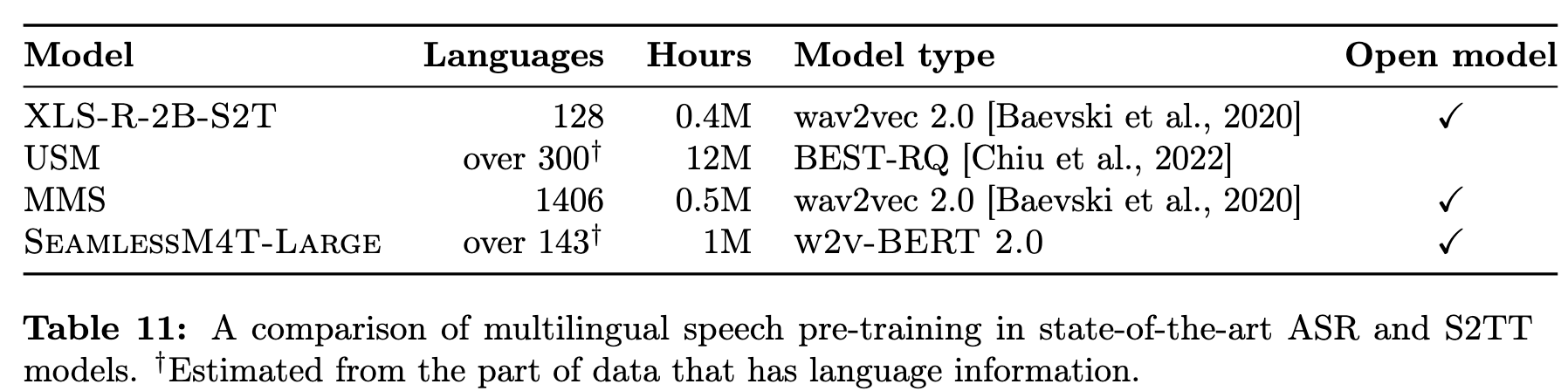
The aforementioned approach alleviates the issue of cascaded error propagation and domain mismatch, while relying on an intermediate semantic representation to mitigate the problem of multi-modal source-target mapping. The vocoders for synthesizing speech are trained separately (see Section 4.3.1). Figure 4 provides an overview of the SeamlessM4T model, including its four building blocks: (1) SeamlessM4T-NLLB a massively multilingual T2TT model, (2) w2v-BERT 2.0, a speech representation learning model that leverages unlabeled speech audio data, (3) T2U, a text-to-unit sequence-to-sequence model, and (4) multilingual HiFi-GAN unit vocoder for synthesizing speech from units. (p. 27)
The SeamlessM4T multitask UnitY model integrates components from the first three building blocks and is fine-tuned in three stages, starting from an X2T model (1,2) with English target only and ending with a full-fledged multitask UnitY (1,2,3) system capable of performing T2TT, S2TT and S2ST, as well as ASR (p. 27)

Unsupervised Speech Pre-training
w2v-BERT 2.0 follows w2v-BERT [Chung et al., 2021] to combine contrastive learning and masked prediction learning, and improves w2v-BERT with additional codebooks in both learning objectives. The contrastive learning module is used to learn Gumbel vector quantization (GVQ) codebooks and contextualized representations that are fed into the subsequent masked prediction learning module. The latter refines the contextualized representations by a different learning task of predicting the GVQ codes directly instead of polarizing the prediction probability of correct and incorrect codes at the masked positions. Instead of using a single GVQ codebook, w2v-BERT 2.0 follows Baevski et al. [2020] to use product quantization with two GVQ codebooks. Its contrastive learning loss Lc is the same as that in w2v-BERT, including a codebook diversity loss to encourage the uniform usage of codes. Following w2v-BERT, we use GVQ codebooks for masked prediction learning and denote the corresponding loss as LmGVQ . We also created an additional masked prediction task using random projection quantizers [Chiu et al., 2022] (RPQ), for which we denote the corresponding loss as LmRPQ . (p. 29)
X2T: Into-Text Translation and Transcription
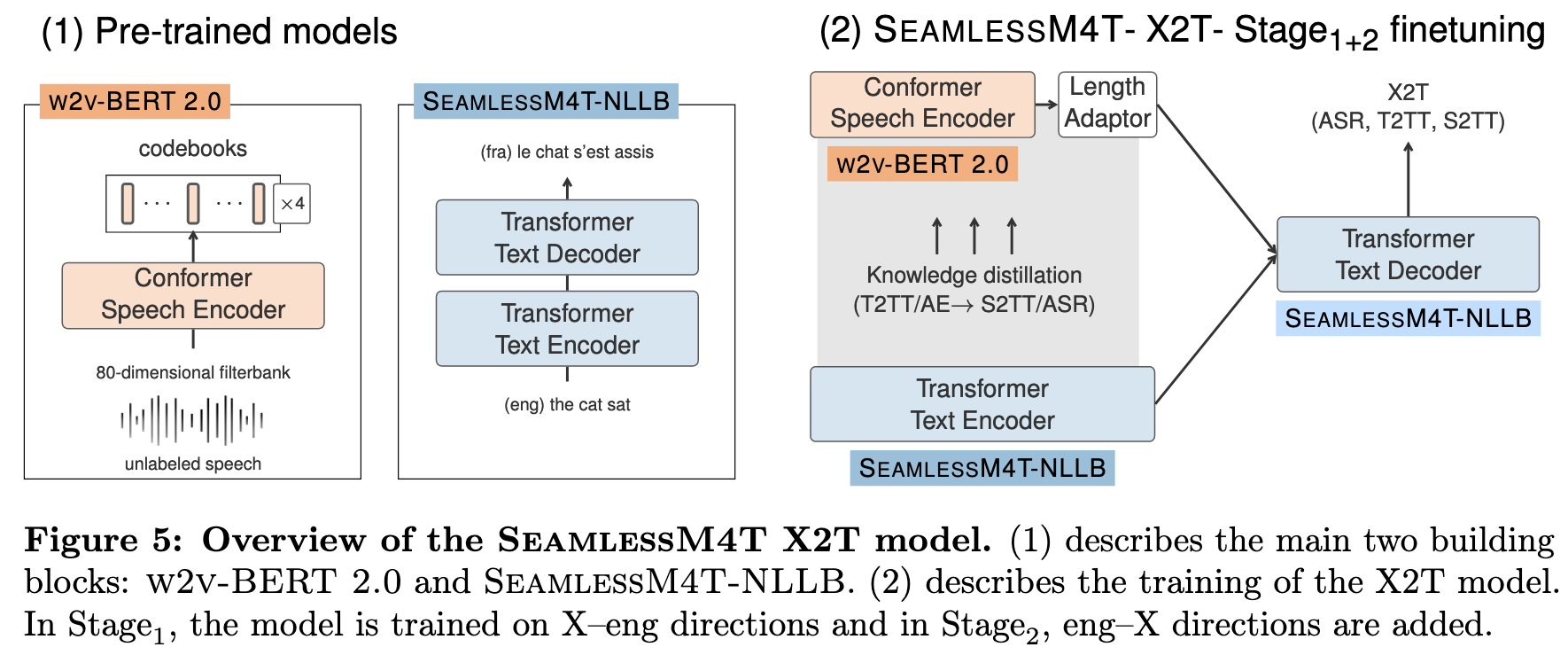
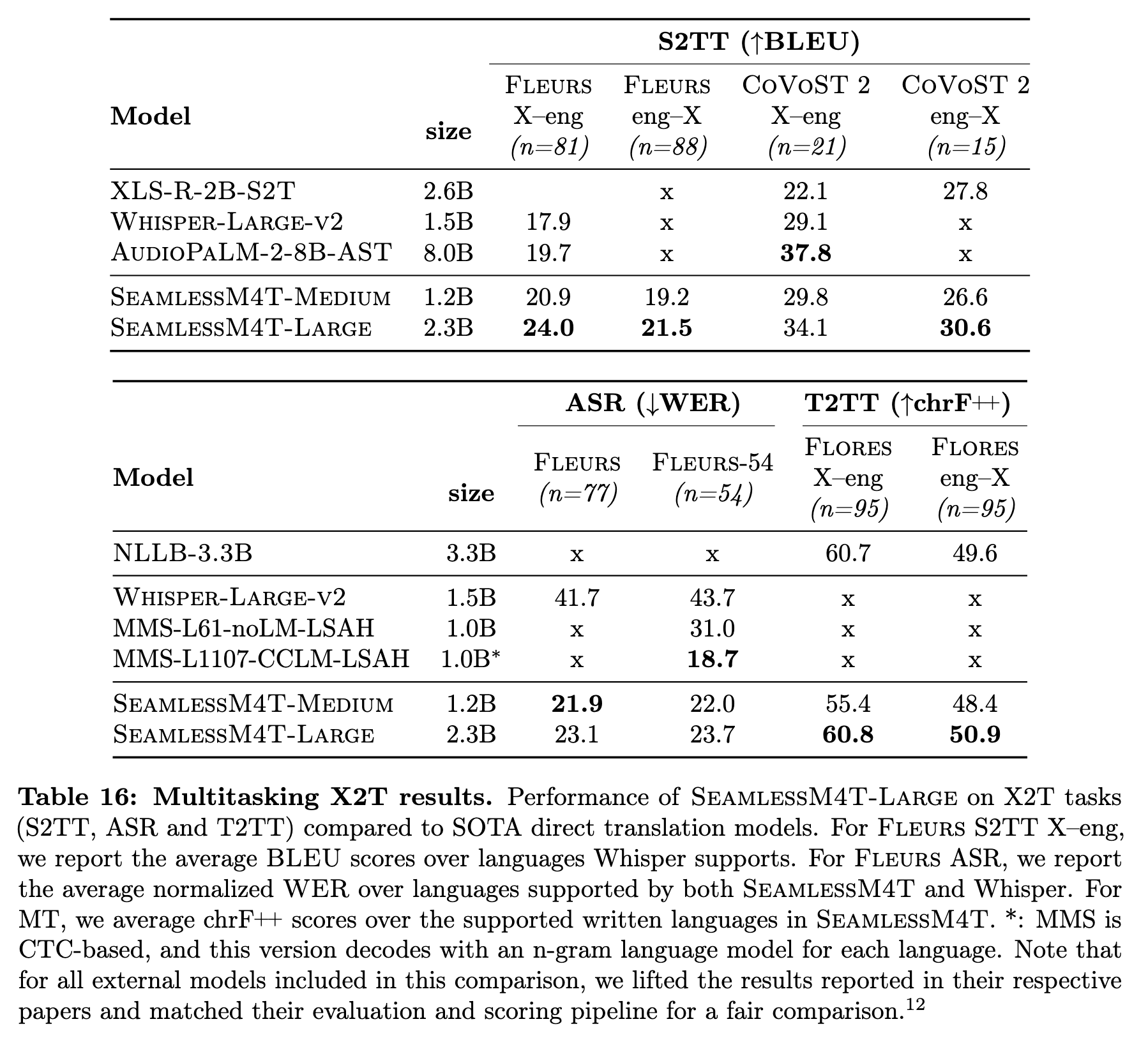
In SeamlessM4T, we leveraged foundational models either pre-trained on unlabeled data (w2v-BERT 2.0 for speech encoder pre-training) or trained on supervised high-resource tasks (NLLB model for T2TT) to improve the quality of transfer tasks (speech-to-text and speech-to-speech). To fuse these pre-trained components and enable meaning transfer through multiple multimodal tasks, we trained an end-to-end model with (a) a speech encoder (w2v-BERT 2.0) postfixed with a length adapter, (b) text encoder (NLLB encoder), and (c) a text decoder (NLLB decoder). For the length adaptor, we used a modified version of M-adaptor [Zhao et al., 2022], where we replaced the 3 independent pooling modules for Q, K, and V with a shared pooling module to improve efficiency. (p. 32)

We additionally optimize an auxiliary objective function in the form of token-level knowledge distillation (LKD), to further transfer knowledge from the strong MT model to the student speech translation task (S2TT) (p. 32)
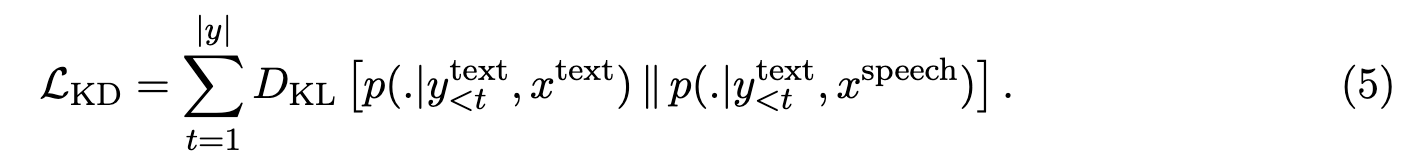
We trained our X2T model in two stages. Stage1 targeted training on supervised English ASR and into English S2TT data. We find that this step is necessary not only for improving the quality of X–eng translations but also eng–X translations. In fact, we hypothesized that allowing the model to focus on one target language while fine-tuning multilingual speech representations shields it from the interference that can propagate back from the target side. In Stage2, we add supervised eng–X S2TT and non-English ASR data to the mix. (p. 33)
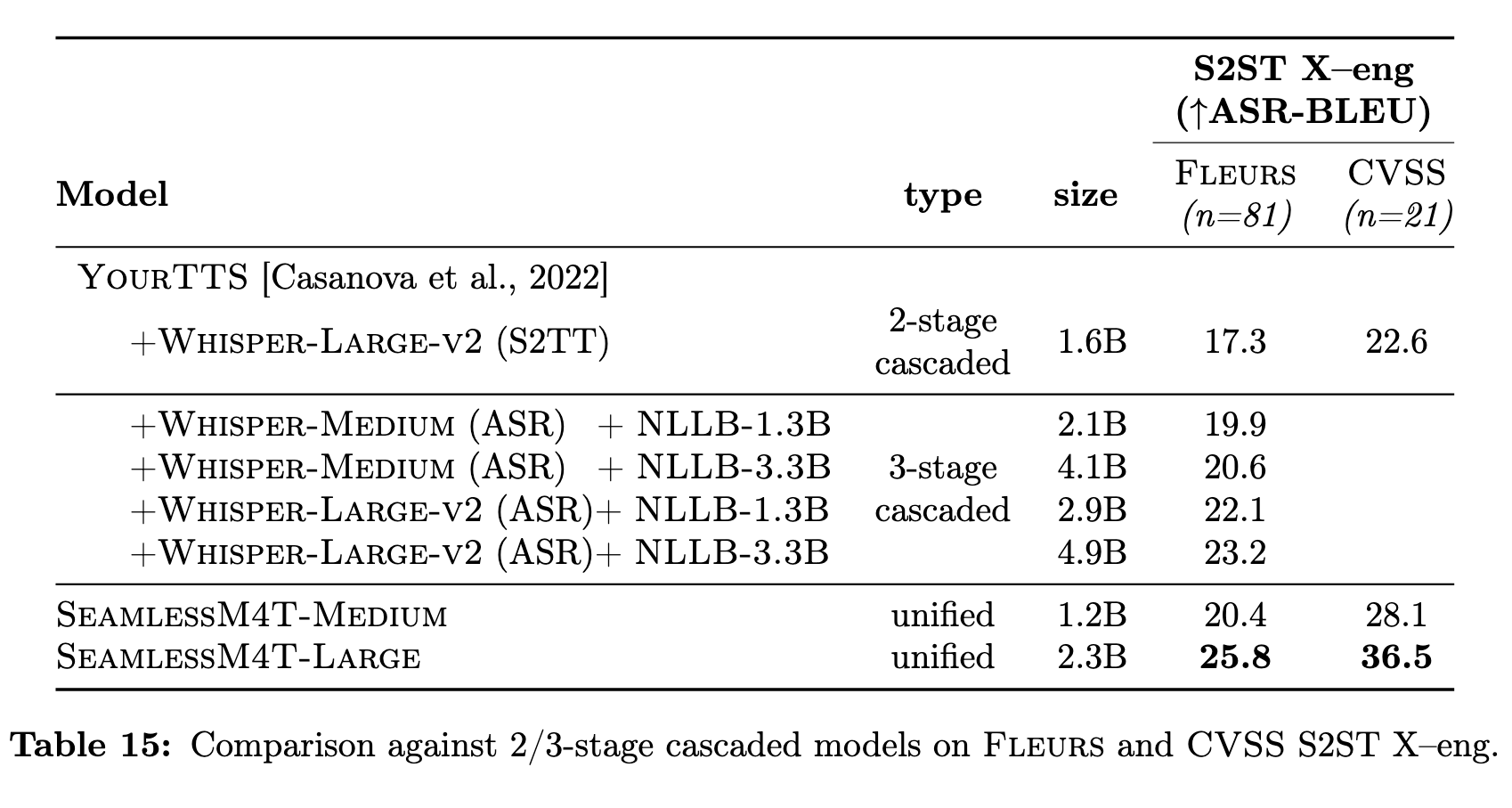
Speech-to-Speech Translation
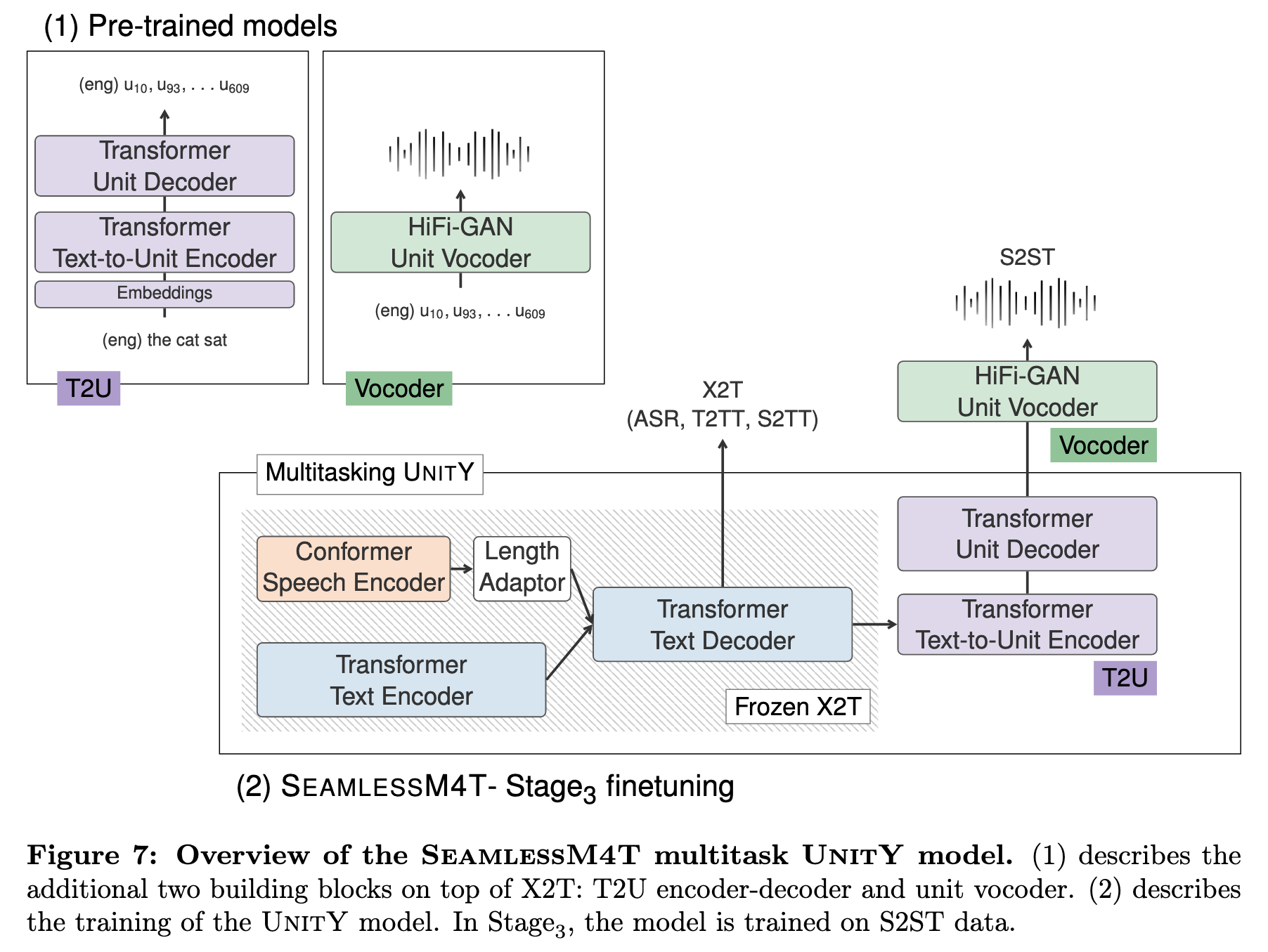
The key to our proposed speech-to-speech translation model is the use of self-supervised discrete acoustic units to represent target speech, thereby decomposing the S2ST problem into a speech-to-unit translation (S2UT) step and a unit-to-speech (U2S) conversion step. (p. 33)
Discrete acoustic units Recent works have achieved SOTA translation performance by using self-supervised discrete acoustic units as targets for building direct speech translation models [Tjandra et al., 2019; Lee et al., 2022a,b; Zhang et al., 2022; Chen et al., 2023c]. (p. 34)
The mapping from XLS-R continuous representation space to discrete categories is required to map target speech into a sequence of discrete tokens. We randomly selected and encoded 10K unlabeled audio samples from each language of the 35 supported target languages. We then applied a k-means algorithm on these representations to estimate K cluster centroids [Lakhotia et al., 2021; Polyak et al., 2021; Lee et al., 2022a]. These centroids resemble a codebook that is used to map a sequence of XLS-R speech representations into a sequence of centroid indices or acoustic units. (p. 34)
Following Gong et al. [2023], we built the multilingual vocoder for speech synthesis from the learned units. The HiFi-GAN vocoder [Kong et al., 2020] is equipped with language embedding to model the languagespecific acoustic information. Moreover, to mitigate cross-lingual interference, language identification is used as an auxiliary loss in multilingual training. (p. 34)
The T2U model is a Transformer-based encoder-decoder model trained on aligned text units from ASR data. (p. 35)
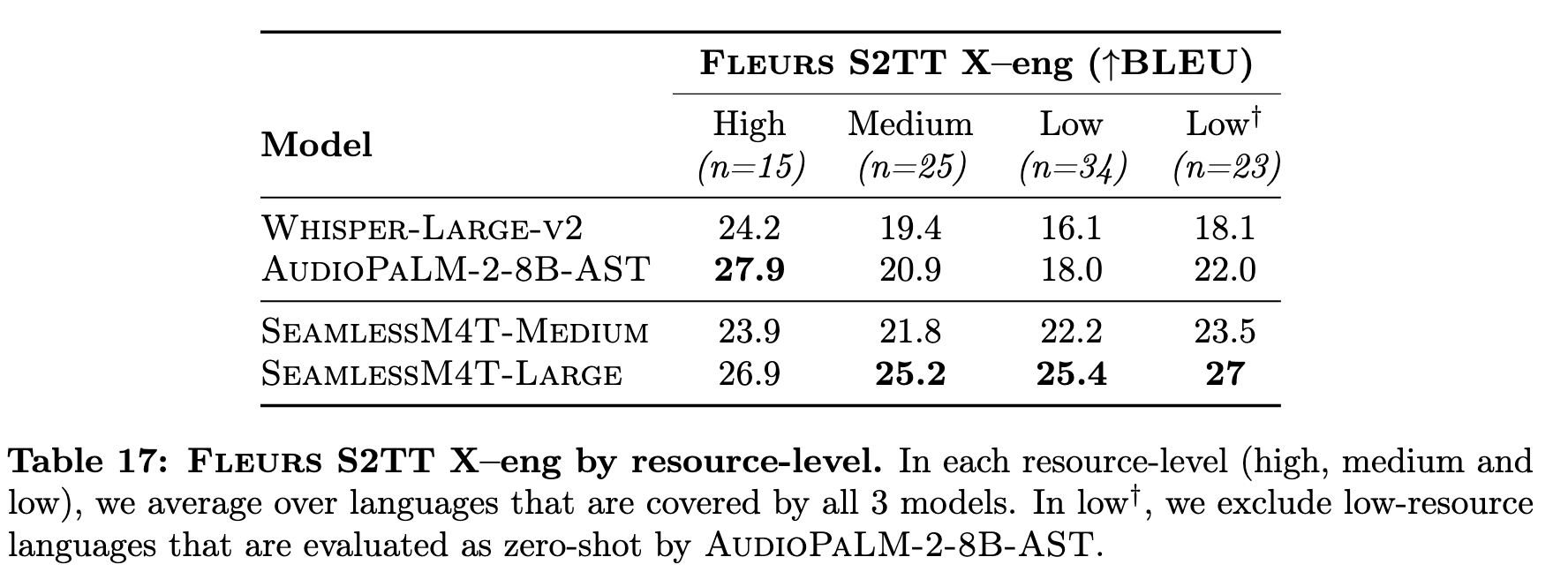
Experiment