Align before Fuse Vision and Language Representation Learning with Momentum Distillation
[bert masked-language-modeling clip multimodal align distill contrast-loss deep-learning image-text-matching transformer oscar uniter albef This is my reading note for Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. The paper proposes a multi modality model which is trained base on contrast loss, mask language modeling and image-text match. To handle noisy pairs of text and image, it track moving average of model and distill to the final model.
Introduction
Because the visual tokens and word tokens are unaligned, it is challenging for the multimodal encoder to learn image-text interactions. In this paper, we introduce a contrastive loss to ALign the image and text representations BEfore Fusing (ALBEF) them through cross-modal attention, which enables more grounded vision and language representation learning. Unlike most existing methods, our method does not require bounding box annotations nor high-resolution images. To improve learning from noisy web data, we propose momentum distillation, a self-training method which learns from pseudo-targets produced by a momentum model. We provide a theoretical analysis of ALBEF from a mutual information maximization perspective, showing that different training tasks can be interpreted as different ways to generate views for an image-text pair (p. 1)
The multimodal encoder is trained to solve tasks that require joint understanding of image and text, such as masked language modeling (MLM) and image-text matching (ITM). While effective, this VLP framework suffers from several key limitations: (1) The image features and the word token embeddings reside in their own spaces, which makes it challenging for the multimodal encoder to learn to model their interactions; (2) The object detector is both annotation-expensive and compute-expensive, because it requires bounding box annotations during pre-training, and high- resolution (e.g. 600×1000) images during inference; (3) The widely used image-text datasets [4, 5] are collected from the web and are inherently noisy, and existing pre-training objectives such as MLM may overfit to the noisy text and degrade the model’s generalization performance. (p. 1)
To improve learning under noisy supervision, we propose Momentum Distillation (MoD), a simple method which enables the model to leverage a larger uncurated web dataset. During training, we keep a momentum version of the model by taking the moving-average of its parameters, and use the momentum model to generate pseudo-targets as additional supervision. With MoD, the model is not penalized for producing other reasonable outputs that are different from the web annotation. We s (p. 2)
Specifically, we show that ITC and MLM maximize a lower bound on the mutual information between different views of an image-text pair, where the views are generated by taking partial information from each pair. From this perspective, our momentum distillation can be interpreted as generating new views with semantically similar samples. Therefore, ALBEF learns vision-language representations that are invariant to semantic-preserving transformations. (p. 2)
Related Work
Vision-Language Representation Learning
Most existing work on vision-language representation learning fall into two categories. The first category focuses on modelling the interactions between image and text features with transformer- based multimodal encoders [10, 11, 12, 13, 1, 14, 15, 2, 3, 16, 8, 17, 18]. Methods in this category achieve superior performance on downstream V+L tasks that require complex reasoning over image and text (e.g. NLVR2 [19], VQA [20]), but most of them require high-resolution input images and pre-trained object detectors. A recent method [21] improves inference speed by removing the object detector, but results in lower performance. The second category focuses on learning separate unimodal encoders for image and text [22, 23, 6, 7]. The recent CLIP [6] and ALIGN [7] perform pre-training on massive noisy web data using a contrastive loss, one of the most effective loss for representation learning [24, 25, 26, 27]. They achieve remarkable performance on image-text retrieval tasks, but lack the ability to model more complex interactions between image and text for other V+L tasks [21]. (p. 2)
Knowledge Distillation
Our momentum distillation can be interpreted as a form of online self-distillation, where a temporal ensemble of the student model is used as the teacher. (p. 2)
ALBEF Pre-training
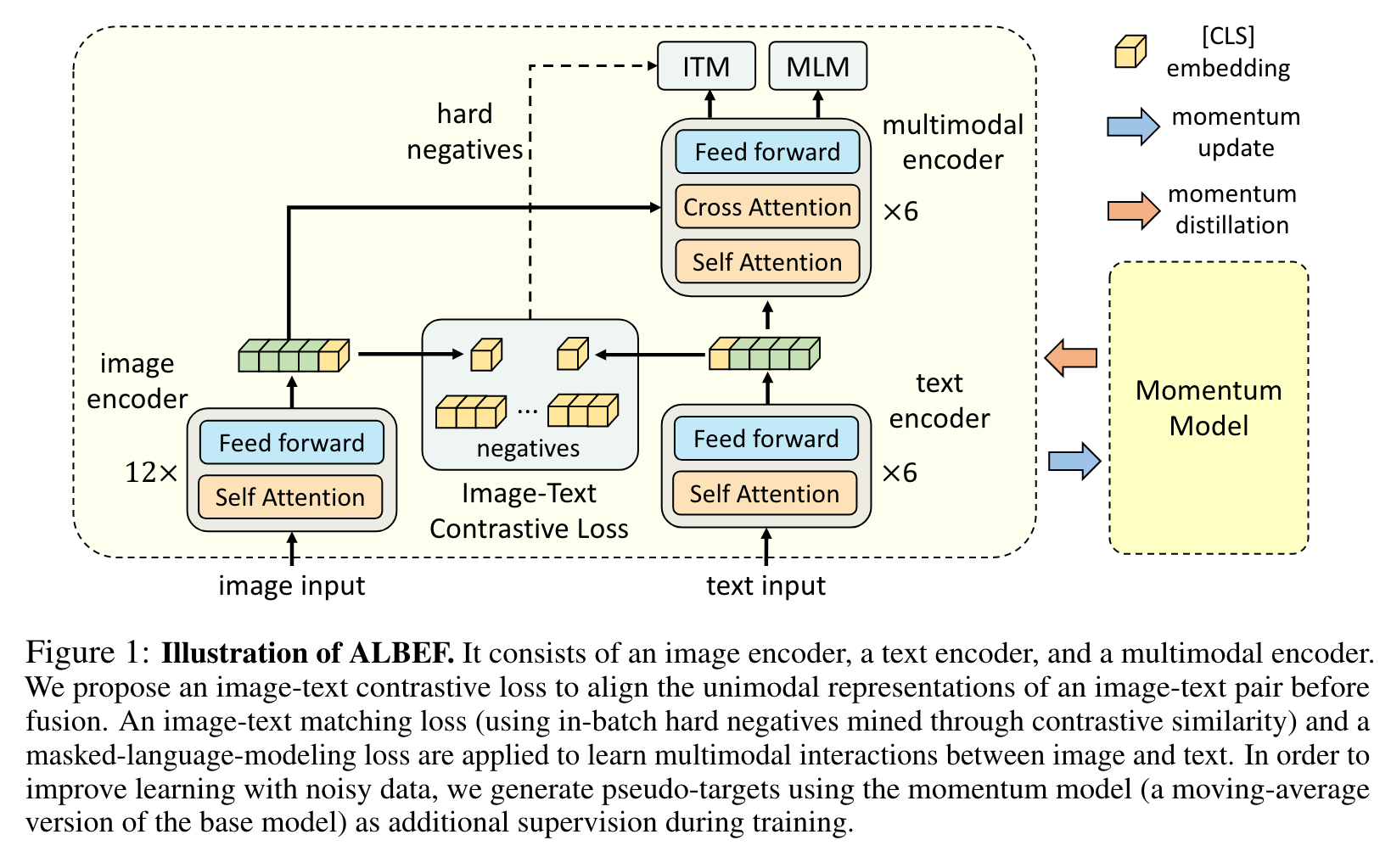
Model Architecture
We use a 12-layer visual transformer ViT-B/16 [38] as the image encoder, and initialize it with weights pre-trained on ImageNet-1k from [31]. We use a 6-layer transformer [39] for both the text encoder and the multimodal encoder. The text encoder is initialized using the first 6 layers of the BERTbase [40] model, and the multimodal encoder is initialized using the last 6 layers of the BERTbase. (p. 3)
Pre-training Objectives
We pre-train ALBEF with three objectives:
- image-text contrastive learning (ITC) on the unimodal encoders,
- masked language modeling (MLM)
- and image-text matching (ITM) on the multimodal encoder. We improve ITM with online contrastive hard negative mining. (p. 3)
Image-Text Matching predicts whether a pair of image and text is positive (matched) or negative (not matched). We use the multimodal encoder’s output embedding of the [CLS] token as the joint representation of the image-text pair, and append a fully-connected (FC) layer followed by softmax to predict a two-class probability pitm. (p. 4)
We propose a strategy to sample hard negatives for the ITM task with zero computational overhead. A negative image-text pair is hard if they share similar semantics but differ in fine-grained details. We use the contrastive similarity from Equation 1 to find in-batch hard negatives. For each image in a mini-batch, we sample one negative text from the same batch following the contrastive similarity distribution, where texts that are more similar to the image have a higher chance to be sampled. Likewise, we also sample one hard negative image for each text. (p. 4)
Momentum Distillation
The image-text pairs used for pre-training are mostly collected from the web and they tend to be noisy. Positive pairs are usually weakly-correlated: the text may contain words that are unrelated to the image, or the image may contain entities that are not described in the text. For ITC learning, negative texts for an image may also match the image’s content. For MLM, there may exist other words different from the annotation that describes the image equally well (or better). However, the one-hot labels for ITC and MLM penalize all negative predictions regardless of their correctness. (p. 4)
To address this, we propose to learn from pseudo-targets generated by the momentum model. The momentum model is a continuously-evolving teacher which consists of exponential-moving-average versions of the unimodal and multimodal encoders. During training, we train the base model such that its predictions match the ones from the momentum model. (p. 4)
We also apply MoD to the downstream tasks. The final loss for each task is a weighted combination of the original task’s loss and the KL-divergence between the model’s prediction and the pseudo-targets. For simplicity, we set the weight α = 0.4 for all pre-training and downstream tasks 2 . (p. 5)
Pre-training Datasets
The total number of unique images is 4.0M, and the number of image-text pairs is 5.1M. To show that our method is scalable with larger-scale web data, we also include the much noisier Conceptual 12M dataset [43], increasing the total number of images to 14.1M 3. (p. 5)
Implementation Details
We pre-train the model for 30 epochs using a batch size of 512 on 8 NVIDIA A100 GPUs. During pre-training, we take random image crops of resolution 256 × 256 as input, and also apply RandAugment4 [45]. During fine-tuning, we increase the image resolution to 384 × 384 and interpolate the positional encoding of image patches following [38]. We linearly ramp-up the distillation weight α from 0 to 0.4 within the 1st epoch. (p. 5)
Downstream V+L Tasks
Visual Entailment (SNLI-VE5 [51]) is a fine-grained visual reasoning task to predict whether the relationship between an image and a text is entailment, neutral, or contradictory. (p. 6)

Natural Language for Visual Reasoning (NLVR2 [19]) requires the model to predict whether a text describes a pair of images. (p. 7)
Visual Grounding aims to localize the region in an image that corresponds to a specific textual description (p. 7)
Experiments
Compared to the baseline pre-training tasks (MLM+ITM), adding ITC substantially improves the pre-trained model’s performance (p. 7)

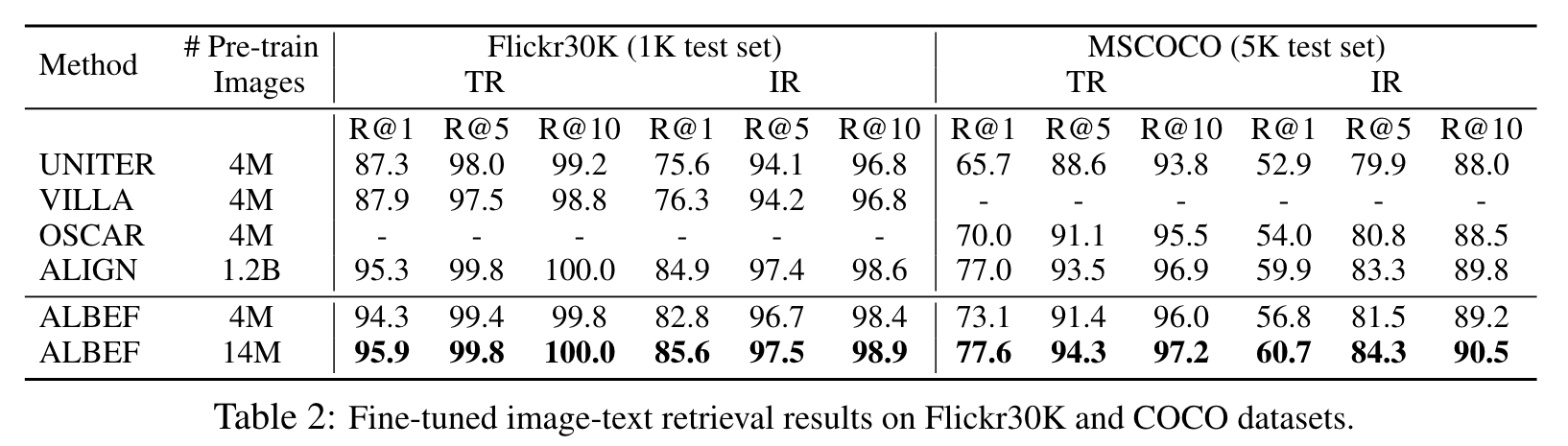
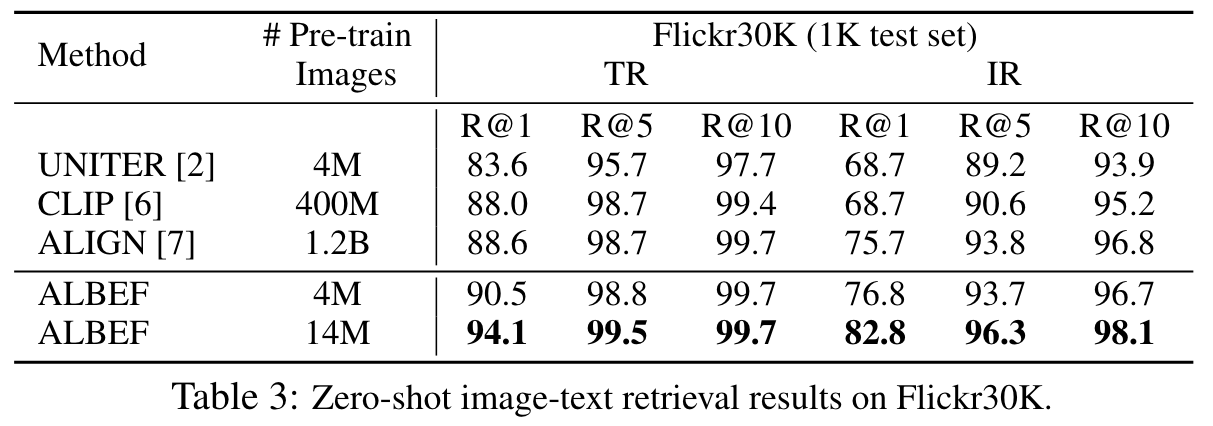

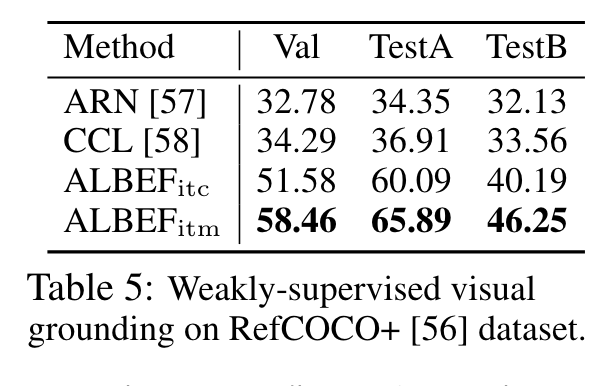

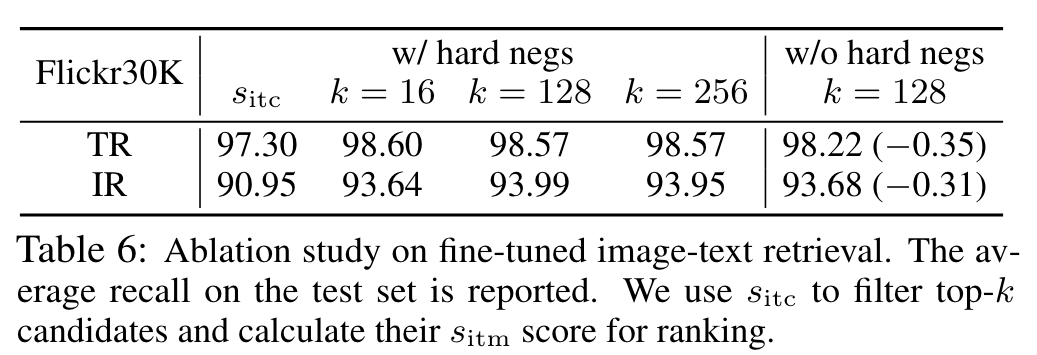
Ablation Study
In general, the ranking result acquired by sitm is not sensitive to changes in k. Without TA, sharing the entire block has better performance. With TA to pre-train the model for image-pair, sharing CA leads to the best performance. (p. 9)