CoCa Contrastive Captioners are Image-Text Foundation Models
[mask-auto-encoder bert masked-language-modeling image-caption clip simvlm multimodal align contrast-loss deep-learning beit vinvl transformer albef This is my reading note for CoCa: Contrastive Captioners are Image-Text Foundation Models. The paper proposes a multi modality model, especially it models the problem as image caption as well as text alignment problem. The model contains three component: a vision encoder, a text decoder (which generates text embedding ) and a multi modality decoder , which generate caption given image and text embedding.
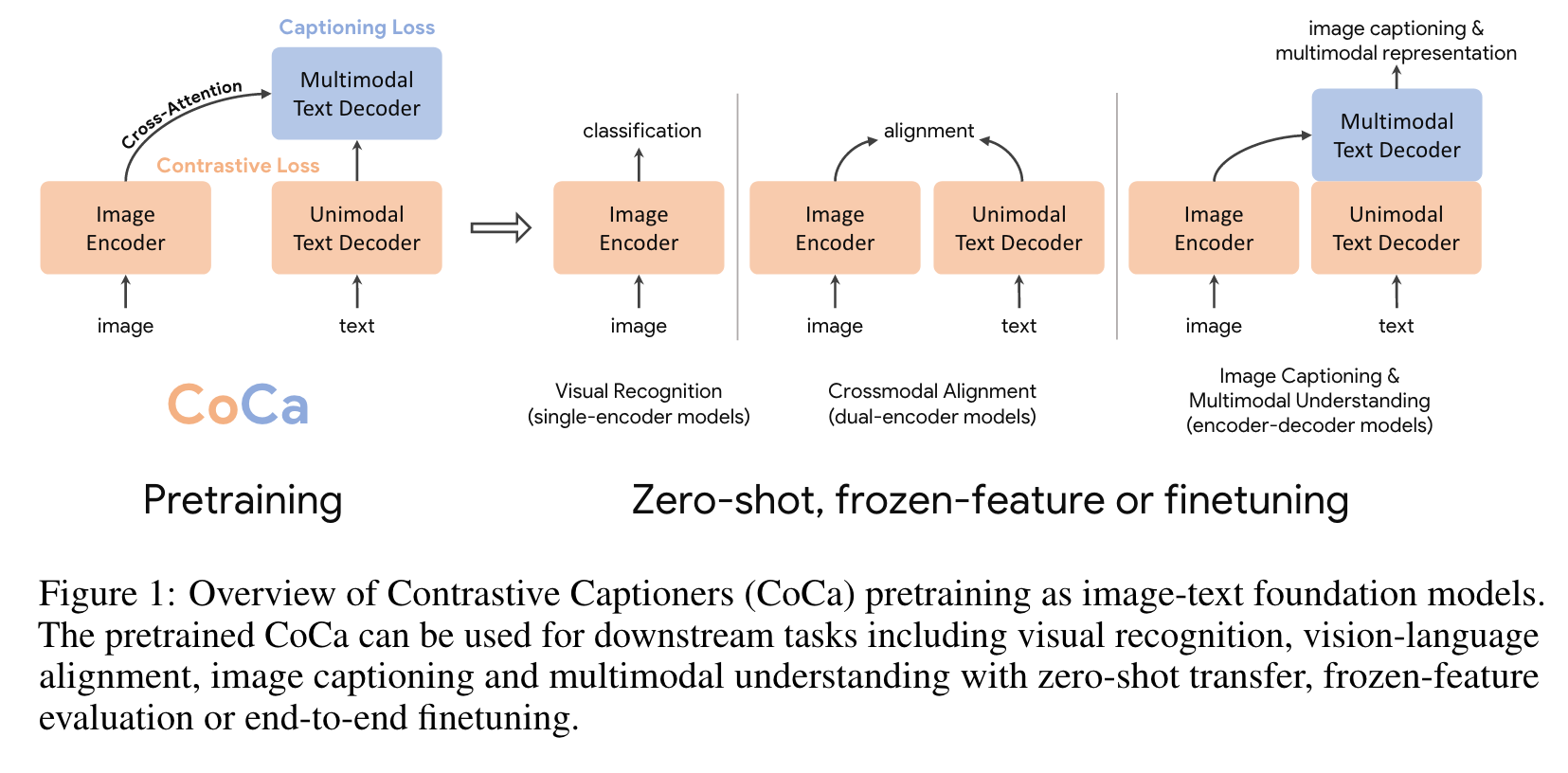
Introduction
This paper presents Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM. In con- trast to standard encoder-decoder transformers where all decoder layers attend to encoder outputs, CoCa omits cross-attention in the first half of decoder layers to encode unimodal text representations, and cascades the remaining decoder layers which cross-attend to the image encoder for multimodal image-text representations. We apply a contrastive loss between unimodal image and text embeddings, in addition to a captioning loss on the multimodal decoder outputs which predicts text tokens autoregressively. By sharing the same computational graph, the two training objectives are computed efficiently with minimal overhead. CoCa is pre- trained end-to-end and from scratch on both web-scale alt-text data and annotated images by treating all labels simply as text, seamlessly unifying natural language supervision for representation learning (p. 1)
Another line of research [15, 16, 17] has explored generative pretraining with encoder-decoder models to learn generic vision and multimodal representations. During pretraining, the model takes images on the encoder side and applies Language Modeling (LM) loss (or PrefixLM [3, 16]) on the decoder outputs. For downstream tasks, the decoder outputs can then be used as joint representations for multimodal understanding tasks. While superior vision-language results [16] have been attained with pretrained encoder-decoder models, they do not produce text-only representations aligned with image embeddings, thereby being less feasible and efficient for crossmodal alignment tasks. (p. 2)
We omit cross-attention in unimodal decoder layers to encode text-only representations, and cascade multimodal decoder layers cross-attending to image encoder outputs to learn multimodal image-text representations. We apply both the contrastive objective between outputs of the image encoder and unimodal text decoder, and the captioning objective at the output of the multimodal decoder. Furthermore, CoCa is trained on both image annotation data and noisy image-text data by treating all labels simply as text. The generative loss on image annotation text provides a fine-grained training signal similar to the single-encoder cross-entropy loss approach, effectively subsuming all three pretraining paradigms into a single unified method. (p. 2)
The design of CoCa leverages contrastive learning for learning global representations and captioning for fine-grained region-level features (p. 2)
Related Work
Vision Pretraining
BEiT [22] proposes a masked image modeling task following BERT [2] in natural language processing, and uses quantized visual token ids as prediction targets. MAE [23] and SimMIM [24] remove the need for an image tokenizer and directly use a light-weight decoder or projection layer to regress pixel values (p. 3)
Vision-Language Pretraining
In recent years, rapid progress has been made in vision-language pretraining (VLP), which aims to jointly encode vision and language in a fusion model. Early work (e.g. LXMERT [25], UNITER [26], VinVL [27]) in this direction relies on pretrained object detection modules such as Fast(er) R-CNN [28] to extract visual representations. Later efforts such as ViLT [29] and VLMo [30] unify vision and language transformers, and train a multimodal transformer from scratch. (p. 3)
Image-Text Foundation Models
CLIP [12] and ALIGN [13] demonstrate that dual-encoder models pretrained with contrastive objectives on noisy image-text pairs can learn strong image and text representations for crossmodal alignment tasks and zero-shot image classification (p. 3)
LiT [32] and BASIC [33] first pretrain model on an large- scale image annotation dataset with cross-entropy and further finetune with contrastive loss on an noisy alt-text image dataset. Another line of research [16, 17, 34] proposes encoder-decoder models trained with generative losses and shows strong results in vision-language benchmarks while the visual encoder still performs competitively on image classification. (p. 3)
While recent works [35, 36, 37] have also explored image-text unification, they require multiple pretraining stages of unimodal and multimodal modules to attain good performance. For example, ALBEF [36] combines contrastive loss with masked language modelling (MLM) with a dual-encoder design. (p. 3)
Proposed Method
Natural Language Supervision
Dual-Encoder Contrastive Learning
the dual-encoder approach exploits noisy web-scale text descriptions and introduces a learnable text tower to encode free-form texts. The two encoders are jointly optimized by contrasting the paired text against others in the sampled batch: (p. 4)
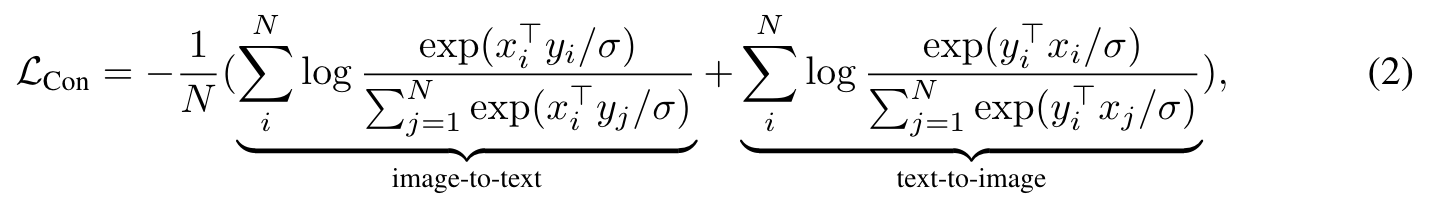
Encoder-Decoder Captioning
While the dual-encoder approach encodes the text as a whole, the generative approach (a.k.a. captioner) aims for detailed granularity and requires the model to predict the exact tokenized texts of y autoregressively. Following a standard encoder-decoder architecture, the image encoder provides latent encoded features (e.g., using a Vision Transformer [39] or ConvNets [40]) and the text decoder learns to maximize the conditional likelihood of the paired text y under the forward autoregressive factorization: (p. 4)
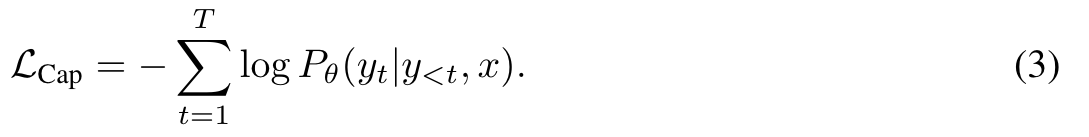
The encoder-decoder is trained with teacher-forcing [41] to parallelize computation and maximize learning efficiency. U (p. 4)
Contrastive Captioners Pretraining
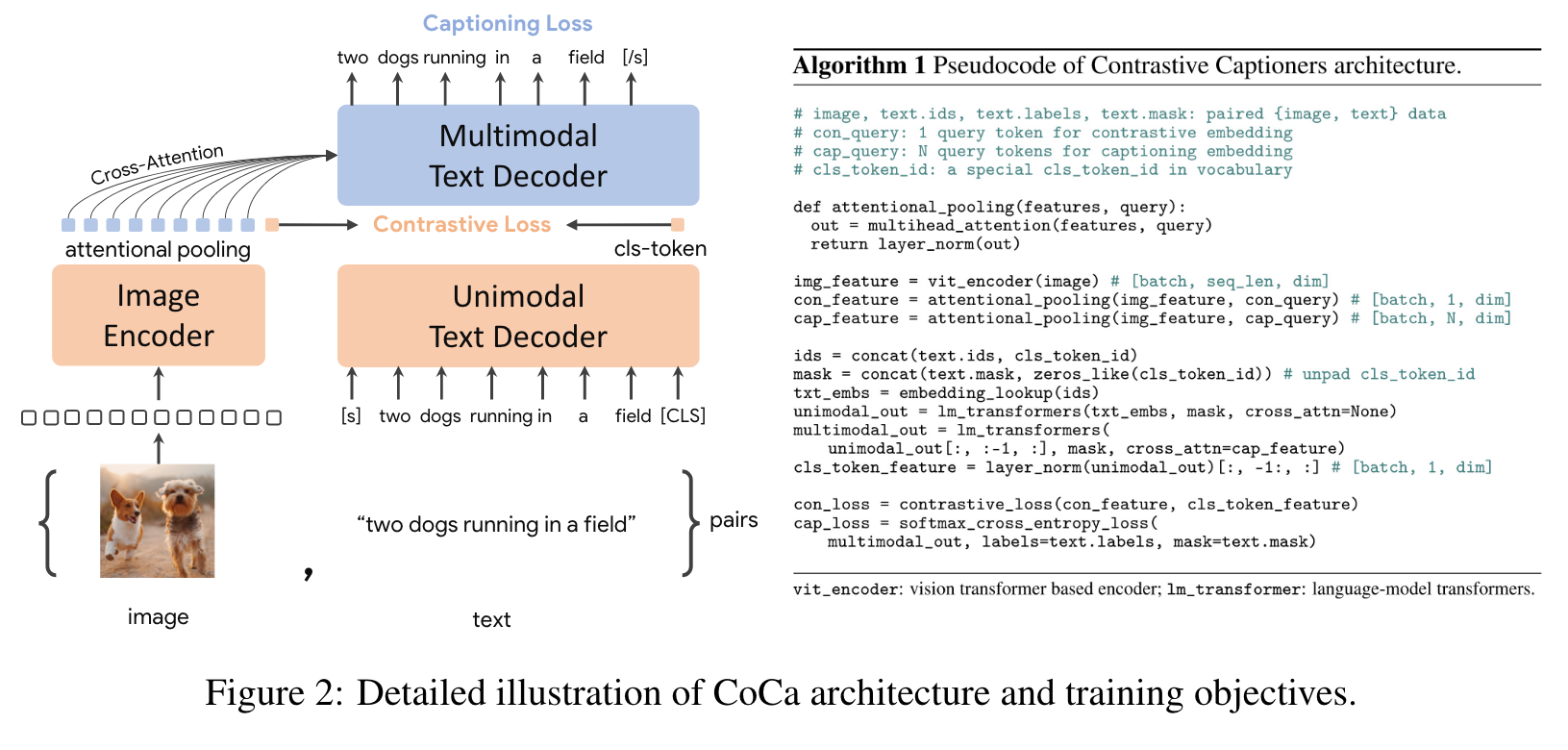
Similar to standard image-text encoder- decoder models, CoCa encodes images to latent representations by a neural network encoder, for example, vision transformer (ViT) [39] (used by default; it can also be other image encoders like ConvNets [40]), and decodes texts with a causal masking transformer decoder. (p. 4)
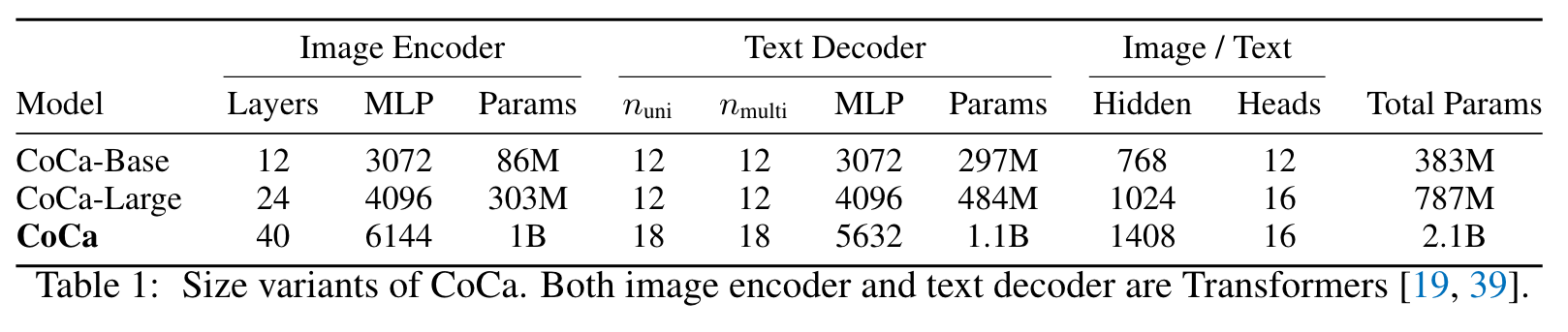
CoCa omits cross-attention in the first half of the decoder layers to encode unimodal text representations, and cascades the rest of the decoder layers, cross-attending to the image encoder for multimodal image-text representations. As a result, the CoCa decoder simultaneously produces both unimodal and multimodal text representations that allow us to apply both contrastive and generative objectives as (p. 5)
Decoupled Text Decoder and CoCa Architecture
All decoder layers prohibit tokens from attending to future tokens, and it is straightforward to use the multimodal text decoder output for the captioning objective LCap. For the contrastive objective LCon, we append a learnable [CLS] token at the end of the input sentence and use its corresponding output of unimodal decoder as the text embedding (p. 5)
Attentional Poolers
It is noteworthy that the contrastive loss uses a single embedding for each image while the decoder usually attends to a sequence of image output tokens in an encoder-decoder captioner [16]. Our preliminary experiments show that a single pooled image embedding helps visual recognition tasks as a global representation, while more visual tokens (thus more fine-grained) are beneficial for multimodal understanding tasks which require region-level features. Hence, CoCa adopts task-specific attentional pooling [42] to customize visual representations to be used for different types of training objectives and downstream tasks. Here, a pooler is a single multi-head attention layer with nquery learnable queries, with the encoder output as both keys and values. Through this, the model can learn to pool embeddings with different lengths for the two training objectives (p. 5)
We use attentional poolers in pretraining for generative loss n_query = 256 and contrastive loss n_query = 1. (p. 5)
Contrastive Captioners for Downstream Tasks
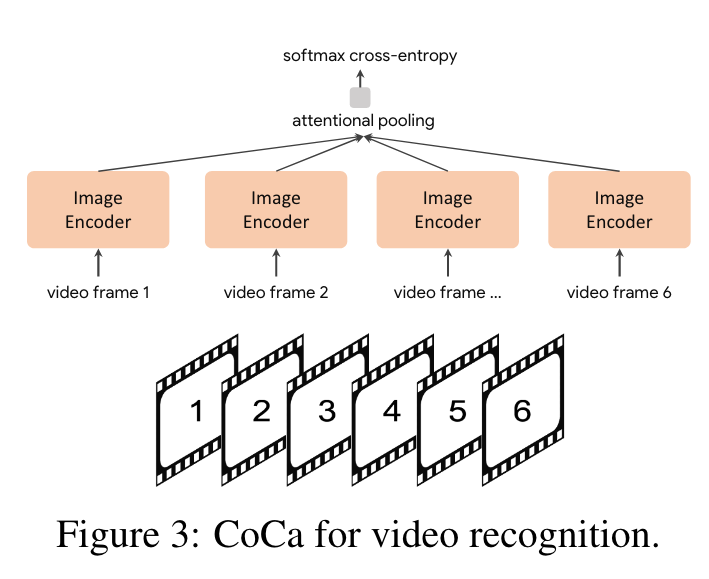
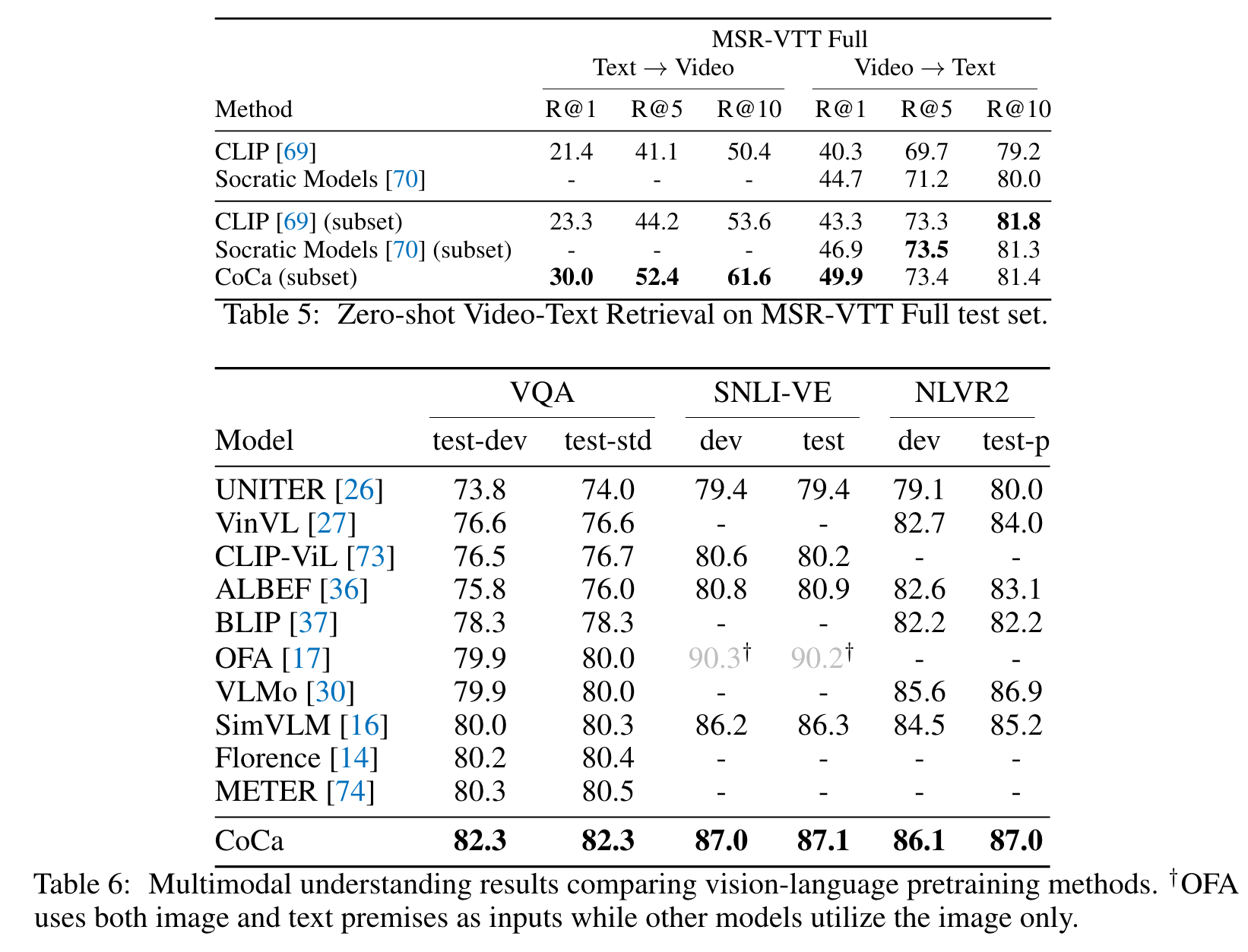
We first take multiple frames of a video and feed each frame into the shared image encoder individually as shown in Figure 3. For frozen- feature evaluation or finetuning, we learn an additional pooler on top of the spatial and temporal feature tokens with a softmax cross-entropy loss. Note the pooler has a single query token thus the computation of pooling over all spatial and temporal tokens is not expensive. For zero-shot video-text retrieval, we use an even sim- pler approach by computing the mean embedding of 16 frames of the video (frames are uniformly sampled from a video). We also encode the captions of each video as target embeddings when computing retrieval metrics. (p. 6)
Experiments
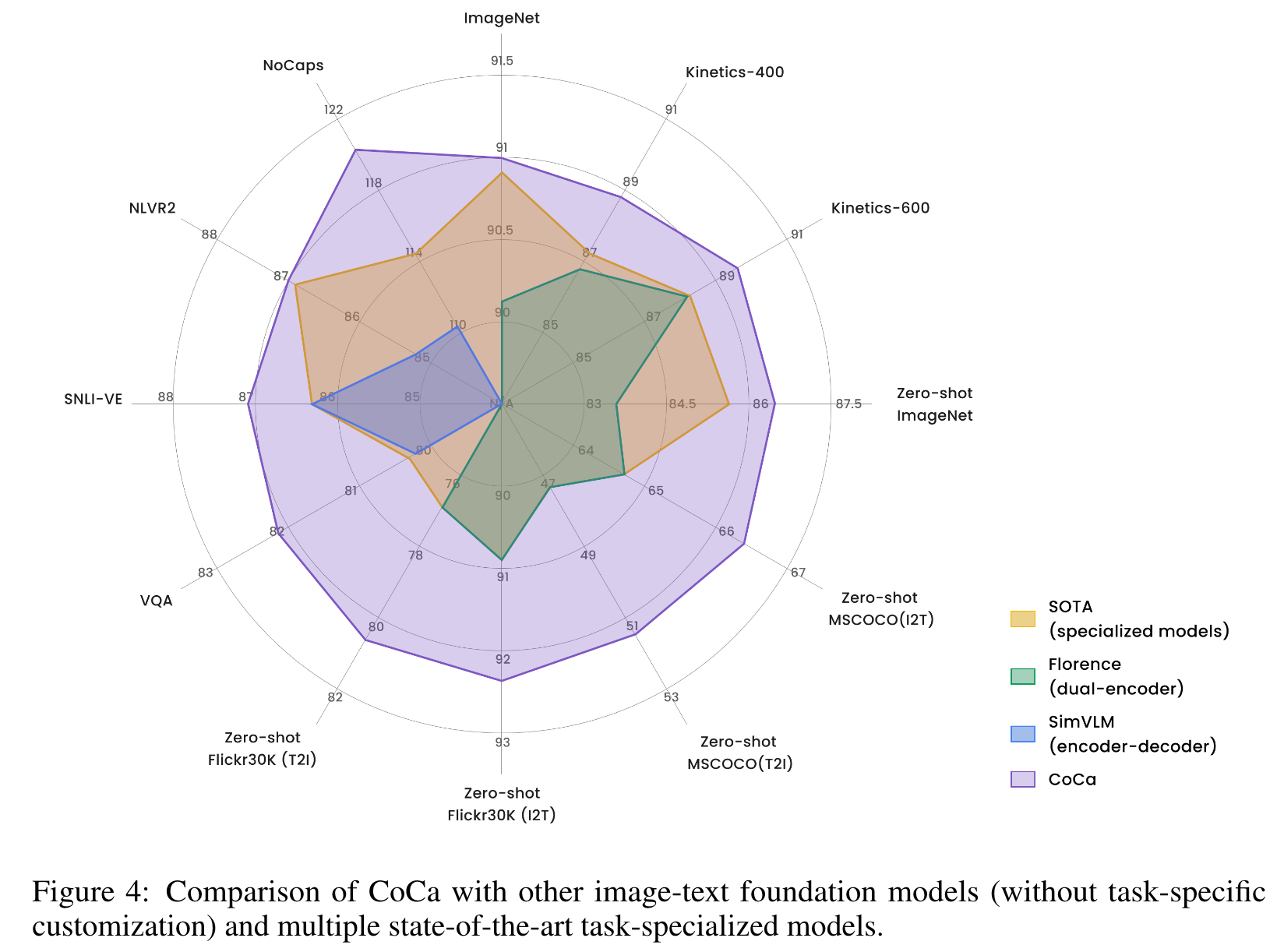
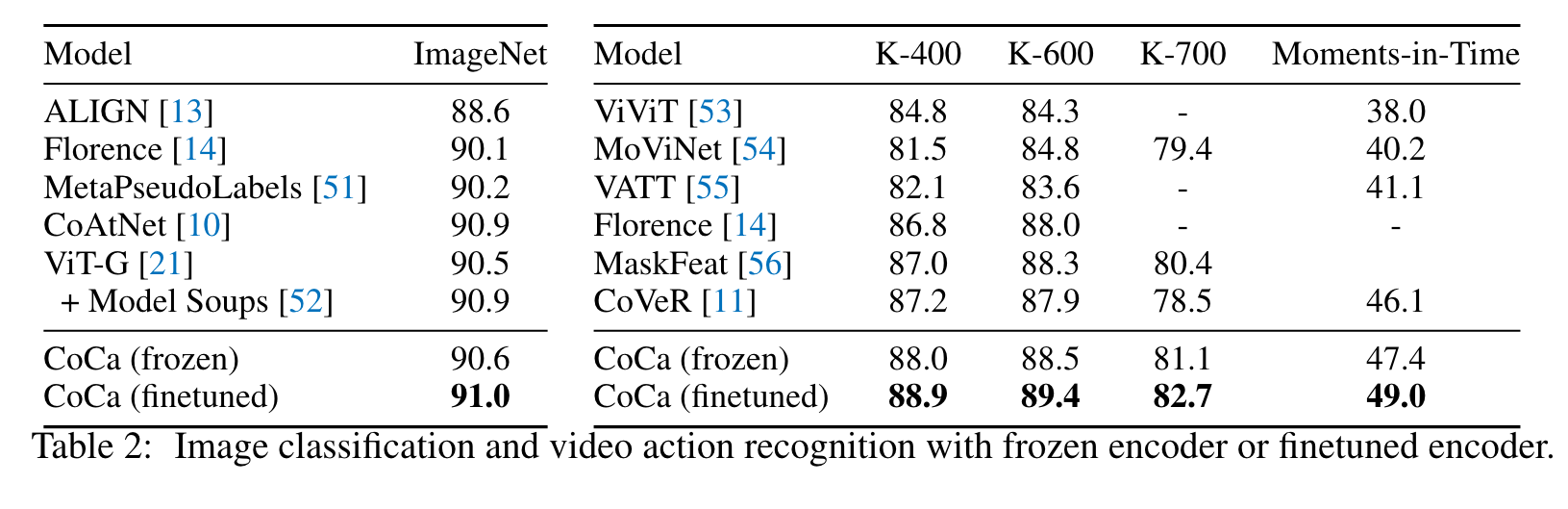


Ablation
Captioning vs. Classification
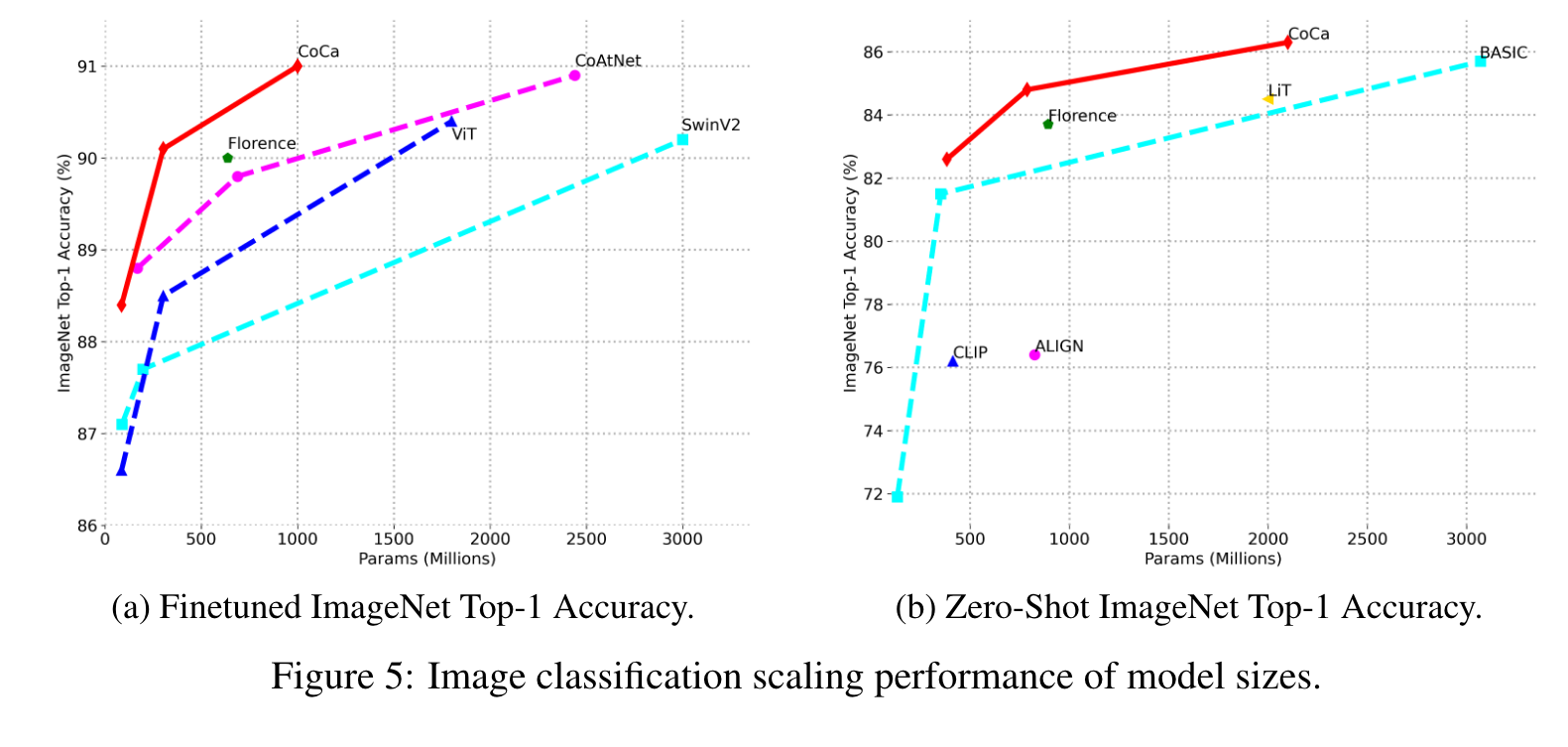
We find encoder-decoder models to perform on par with single-encoder pretraining on both linear evaluation and finetuned results. This suggests that the generative pretraining subsumes classification pretraining, consistent with our intuition that LCls is a special case of LCap when text vocabulary is the set of all possible class names. Thus, our CoCa model can be interpreted as an effective unification of the three paradigms. This explains why CoCa does not need a pretrained visual encoder to perform well. (p. 11)
Training Objectives

Compared to the contrastive-only model, CoCa significantly improves both zero-shot alignment and VQA (notice that the contrastive-only model requires ad- ditional fusion for VQA). CoCa performs on par with the captioning-only model on VQA while it additionally enables retrieval-style tasks such as zero-shot classification. (p. 11)
Unimodal and Multimodal Decoders
Intuitively, fewer unimodal text layers leads to worse zero-shot classification due to lack of capacity for good unimodal text understanding, while fewer multimodal layers reduces the model’s power to reason over multimodal inputs such as VQA. Overall, we find decoupling the decoder in half maintains a good balance. One possibility is that global text representation for retrieval doesn’t require deep modules [33] while early fusion for shallow layers may also be unnecessary for multimodal understanding. Next, we explore various options to extract unimodal text embeddings. In particular, we experiment with the number of learnable [CLS] tokens as well as the aggregation design. For the later, we aggregate over either the [CLS] tokens only or the concatenation of [CLS] and the original input sentence. Interestingly, in Table 8e we find training a single [CLS] token without the original input is preferred for both vision-only and crossmodal retrieval tasks. This indicates that learning an additional simple sentence representation mitigates interference between contrastive and captioning loss, and is powerful enough for strong generalization (p. 12)
Attentional Poolers
Empirically, we find at small scale the “cascade” version (contrastive pooler on top of the generative pooler) performs better and is used by default in all CoCa models. We also study the effect of number of queries where n_query = 0 means no generative pooler is used (thus all ViT output tokens are used for decoder cross-attention). Results show that both tasks prefer longer sequences of detailed image tokens at a cost of slightly more computation and parameters. As a result, we use a generative pooler of length 256 to improve multimodal understanding benchmarks while still maintaining the strong frozen-feature capability. (p. 12)