CogVLM Visual Expert for Pretrained Language Models
[multimodal deep-learning cog-vlm blip2 mplug-owl2 frozen llm attention sft supervised-finetuning ofa clip pali qwen-vl unified-io flamingo coca simvlm beit git instruct-blip This is my reading note for CogVLM: Visual Expert for Pretrained Language Models. This paper proposes a vision language model similarly to mPLUG-OWL2. To avoid impacting the performance of LLM, it proposes a visual adapter which adds visual specific projection layer to each attention and feed forward layer.

Introduction
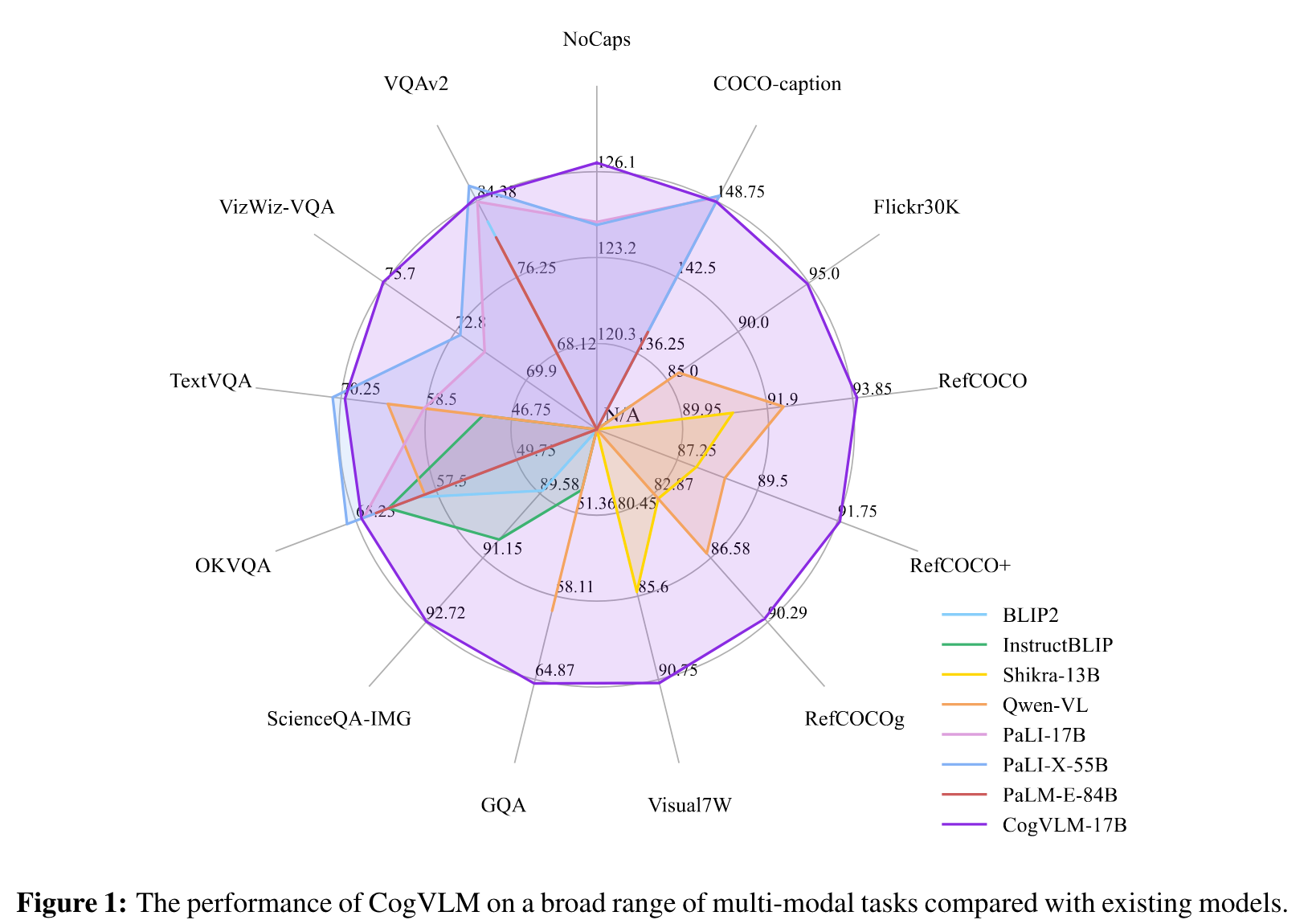
CogVLM bridges the gap between the frozen pretrained language model and image encoder by a trainable visual expert module in the attention and FFN layers. As a result, CogVLM enables deep fusion of vision language features without sacrificing any perfor- mance on NLP tasks (p. 1)
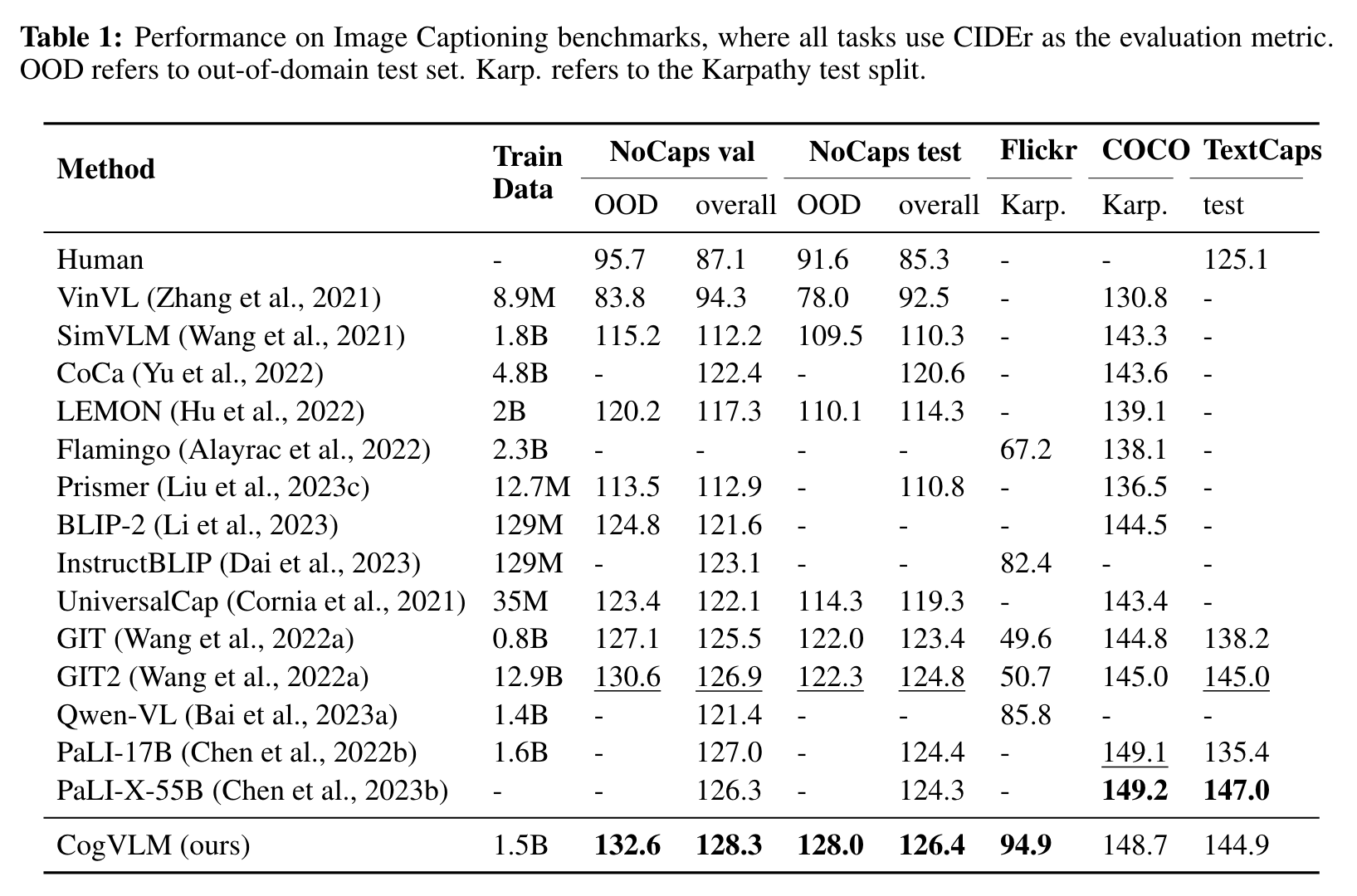
The popular shallow alignment methods represented by BLIP-2 (Li et al., 2023) connect a frozen pretrained vision encoder and language model via a trainable Q-Former or a linear layer, mapping the image features into the input embedding space of the language model. This method converges fast, but the performance (BLIP-2 NoCaps CIDEr 121.6) is not as good as jointly training the vision and language modules, e.g., PaLI-X (NoCaps CIDEr 126.3). (p. 3)
In our opinion, the root cause of the inferior performance of shallow alignment methods lies in the lack of deep fusion between vision and language information. This inspiration arises from the comparison between p-tuning (Liu et al., 2023e) and LoRA (Hu et al., 2021) in efficient finetuning, where p-tuning learns a task prefix embedding in the input while LoRA adapts the model weights in each layer via a low-rank matrix. As a result, LoRA performs better and more stable. (p. 3)
- The frozen weights in the language model are trained for text tokens. Visual features do not have a perfect counterpart in the input text space. Therefore, after multi-layer transfor- mations, the visual features might no longer match the input distribution of the weights in the deep layers.
- During pretraining, the prior of the image captioning task, for example, the writing style and caption length, can only be encoded into the visual features in the shallow alignment methods. It weakens the consistency between visual features and content. (p. 3)
According to PaLM-E (Driess et al., 2023), making the language model trainable during VLM pretraining will lead to catastrophic forgetting, and drop 87.3% NLG performance for 8B language model. (p. 3)
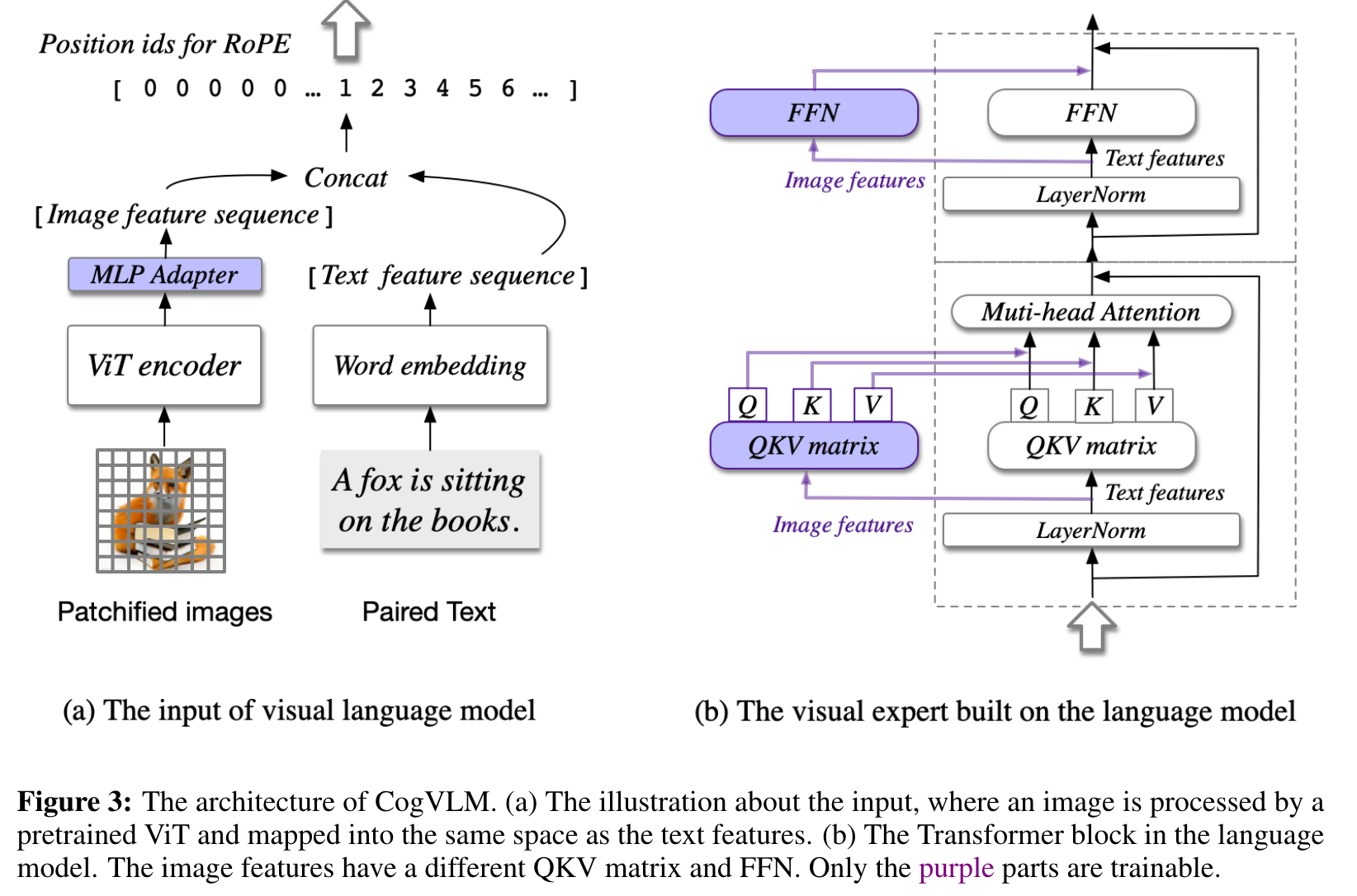
CogVLM instead adds a trainable visual expert to the language model. In each layer, the image features in the sequence use a new different QKV matrix and MLP layer with the text features. Visual expert doubles the number of parameters while keeping the FLOPs the same. (p. 3)
Method
ARCHITECTURE
CogVLM model comprises four fundamental components: a vision transformer (ViT) encoder, an MLP adapter, a pretrained large language model (GPT), and a visual expert module. (p. 4)
Specifically, the visual expert module in each layer consists of a QKV matrix and an MLP in each layer. The shapes of the QKV matrix and MLP are identical to those in the pretrained language model and initialized from them. The motivation is that each attention head in the language model captures a certain aspect of semantic information, while a trainable visual expert can transform the image features to align with the different heads, therefore enabling deep fusion. (p. 4)
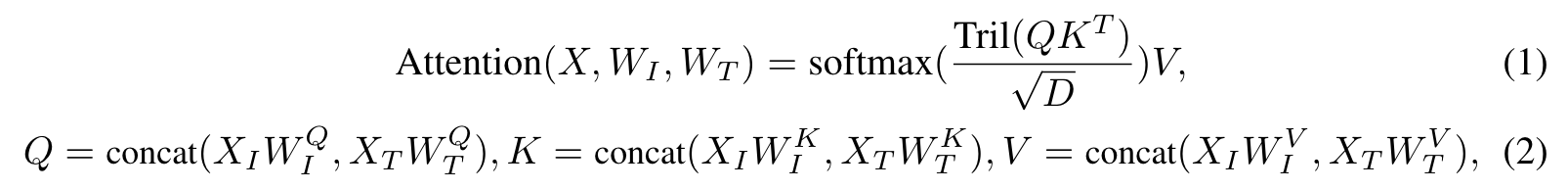
PRETRAINING
1.5B images are left for pretraining. We also crafted a visual grounding dataset of 40M images. Each noun in the image caption is associated with bounding boxes to indicate the positions in the image. (p. 5)
Training. The first stage of pretraining is for image captioning loss, i.e. next token prediction in the text part. We train the CogVLM-17B model on the 1.5B image-text pairs introduced above for 120,000 iterations with a batch size of 8,192. The second stage of pretraining is a mixture of image captioning and Referring Expression Comprehension (REC). REC is a task to predict the bounding box in the image given the text description of an object, which is trained in the form of VQA, i.e., “Question: Where is the object?” and “Answer: [[x0, y0, x1, y1]]”. (p. 5)
ALIGNMENT
Data. The high-quality data for supervised finetuning (SFT) is collected from LLaVA-Instruct (Liu et al., 2023b), LRV-Instruction (Liu et al., 2023a), LLaVAR Zhang et al. (2023) and an in-house dataset, with a total of about 500,000 VQA pairs. (p. 5)
SFT. For supervised finetuning, we train 8,000 iterations with a batch size of 640, a learning rate of 10−5 and 50 warm-up iterations. (p. 5)
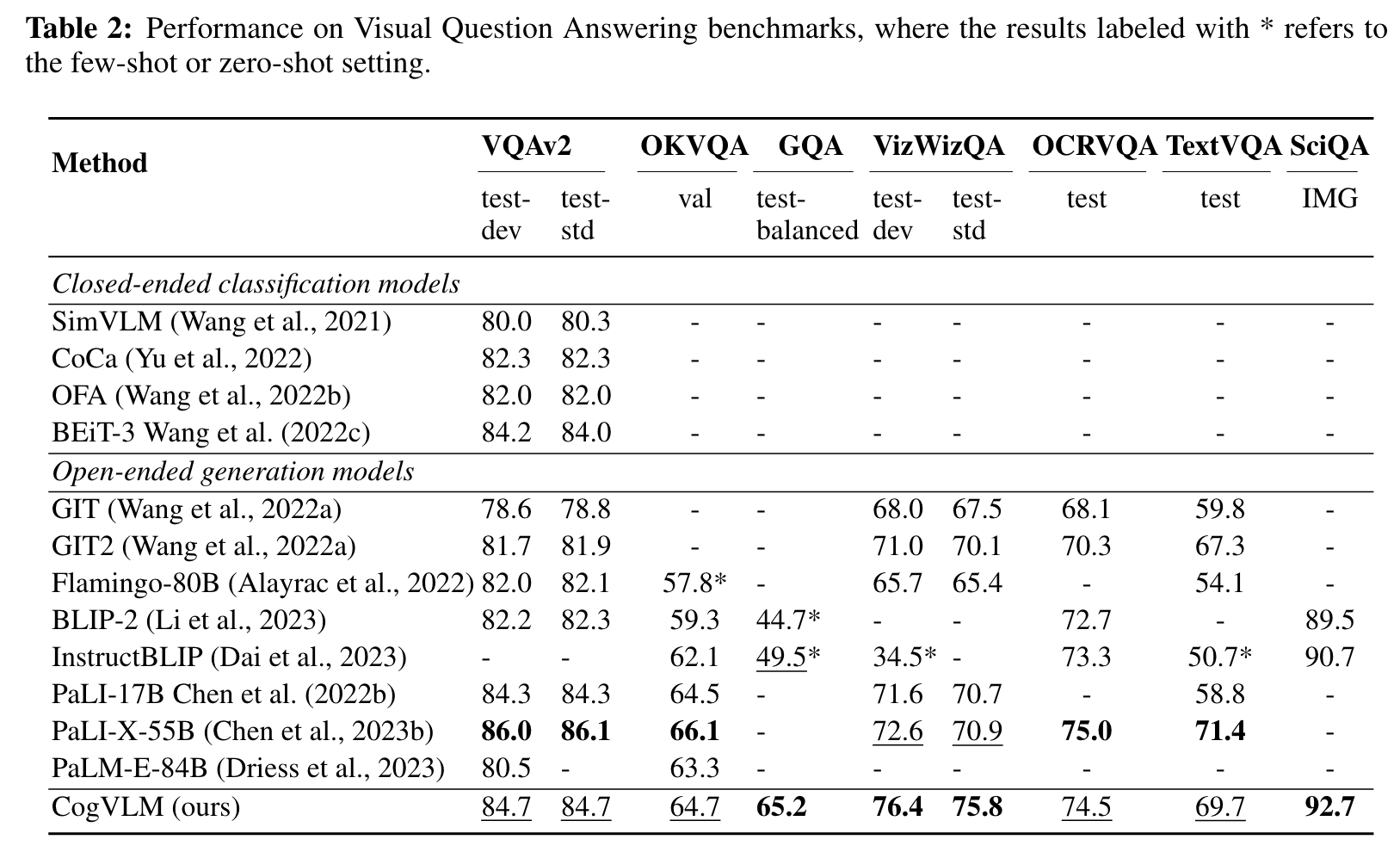
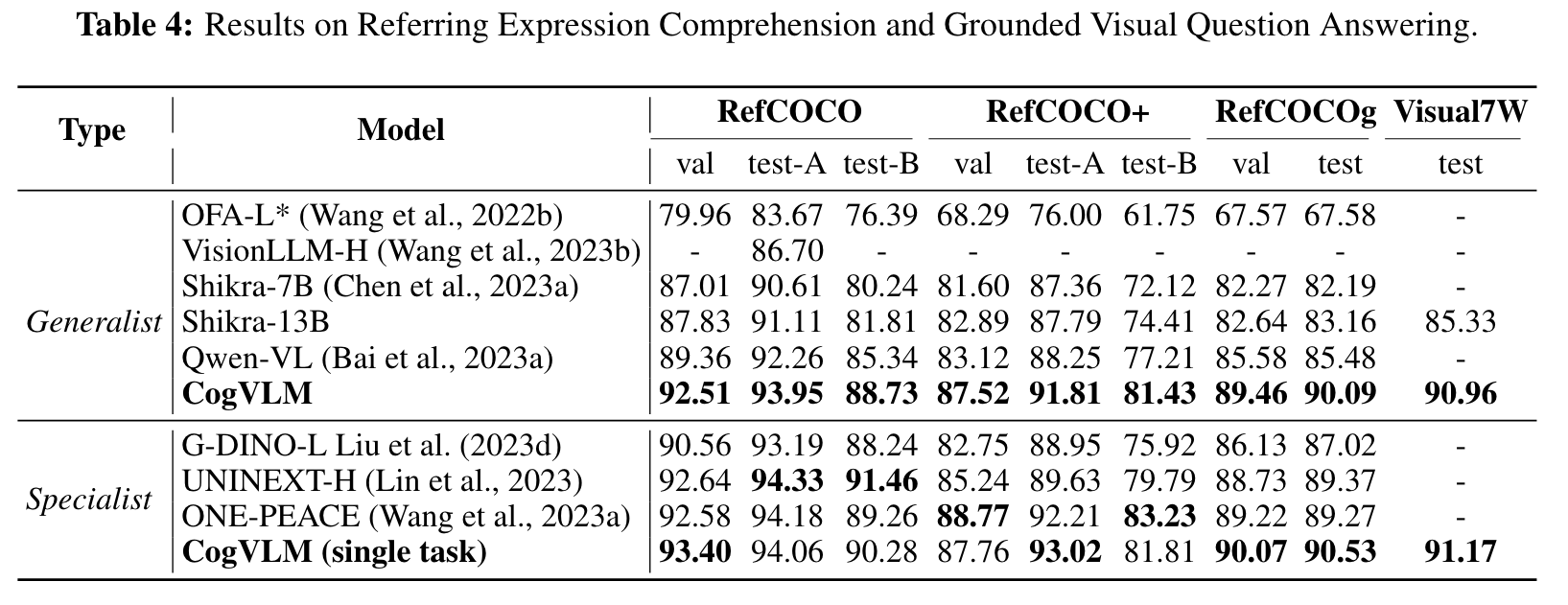
EXPERIMENTS


ABLATION STUDY
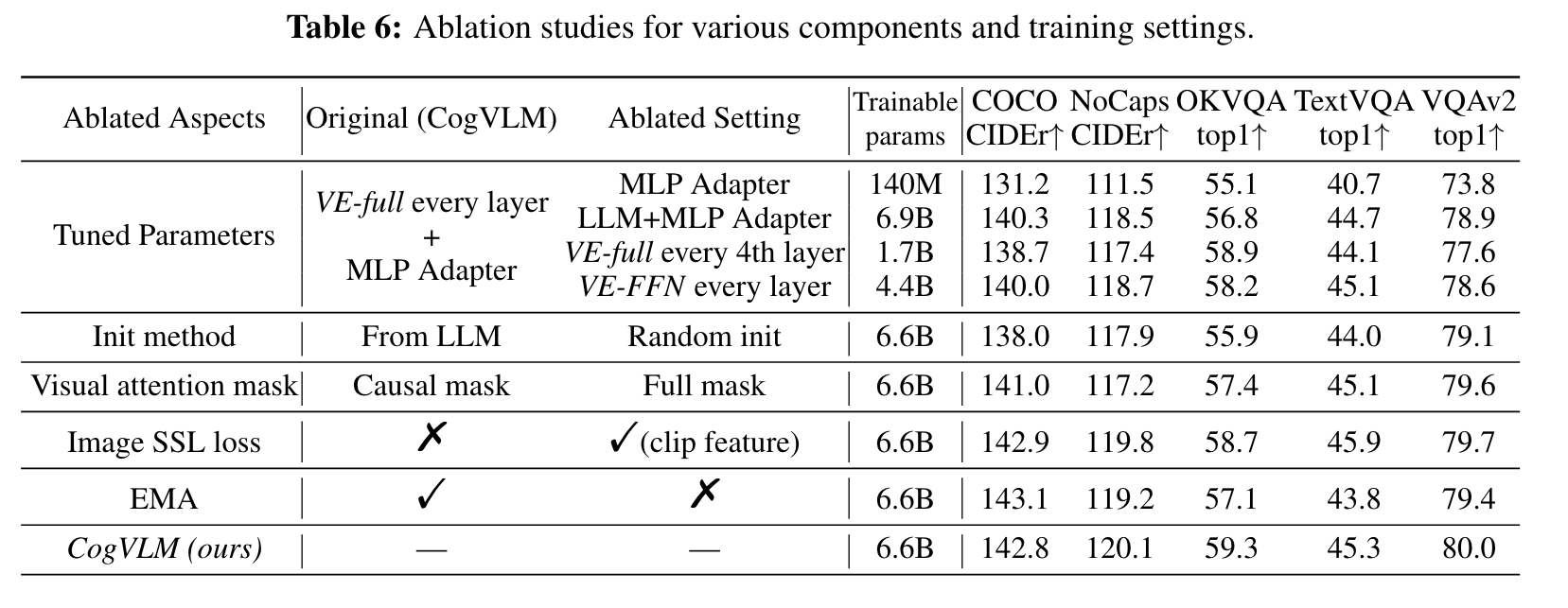
Model structure and tuned parameters
From the results we can see that only tuning the adapter layer (e.g., BLIP2) may result in a shallow alignment with significantly inferior performance, and decreasing either the number of VE layers or the VE parameters at each LLM layer suffers a prominent degradation. (p. 9)
Visual Attention Mask
We empirically find that using a causal mask on visual tokens will yield a better result in comparison with a full mask. We hypothesize the possible explanation for this phenomenon is that the causal mask better fits the inherent structure of LLM. (p. 10)
Image SSL Loss
We also investigated the self-supervised learning loss on image features, where each visual feature predicts the CLIP feature of the next position for visual self-supervision. Align with the observation from PaLI-X (Chen et al., 2023b), we find it brings no improvement on down- stream tasks, although we indeed observed improvements in small models in our early experiments. (p. 10)